| 完成网站应用的部署之后,在这一步中,我们体验一下通过ACK Serverless可以如何对应用容器集群进行基本的运维和管理。
查看应用集群
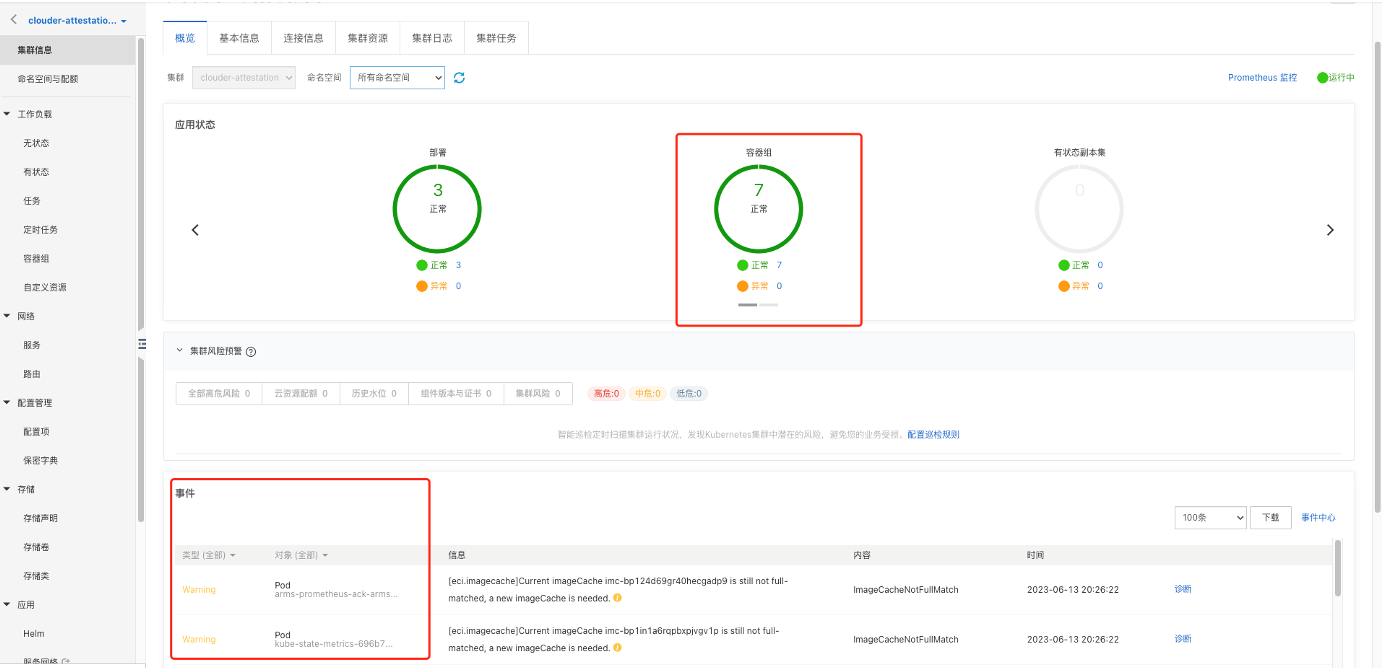
在ACK Serverless控制台点击集群名称,可以查看容器集群信息、无状态应用信息、服务信息、容器组信息等。
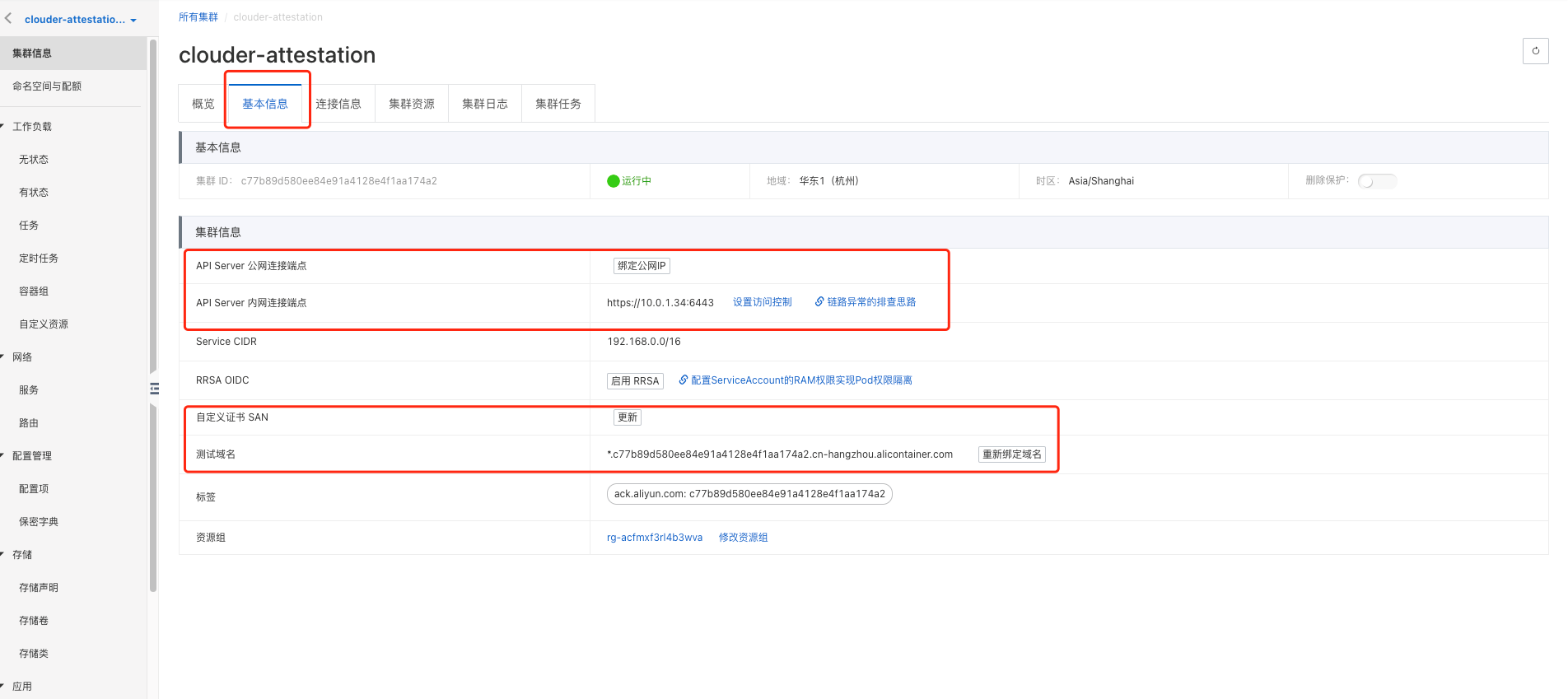
查看集群的基本信息,我们还可以查看连接信息、集群资源、集群日志、集群任务等信息。如下图:
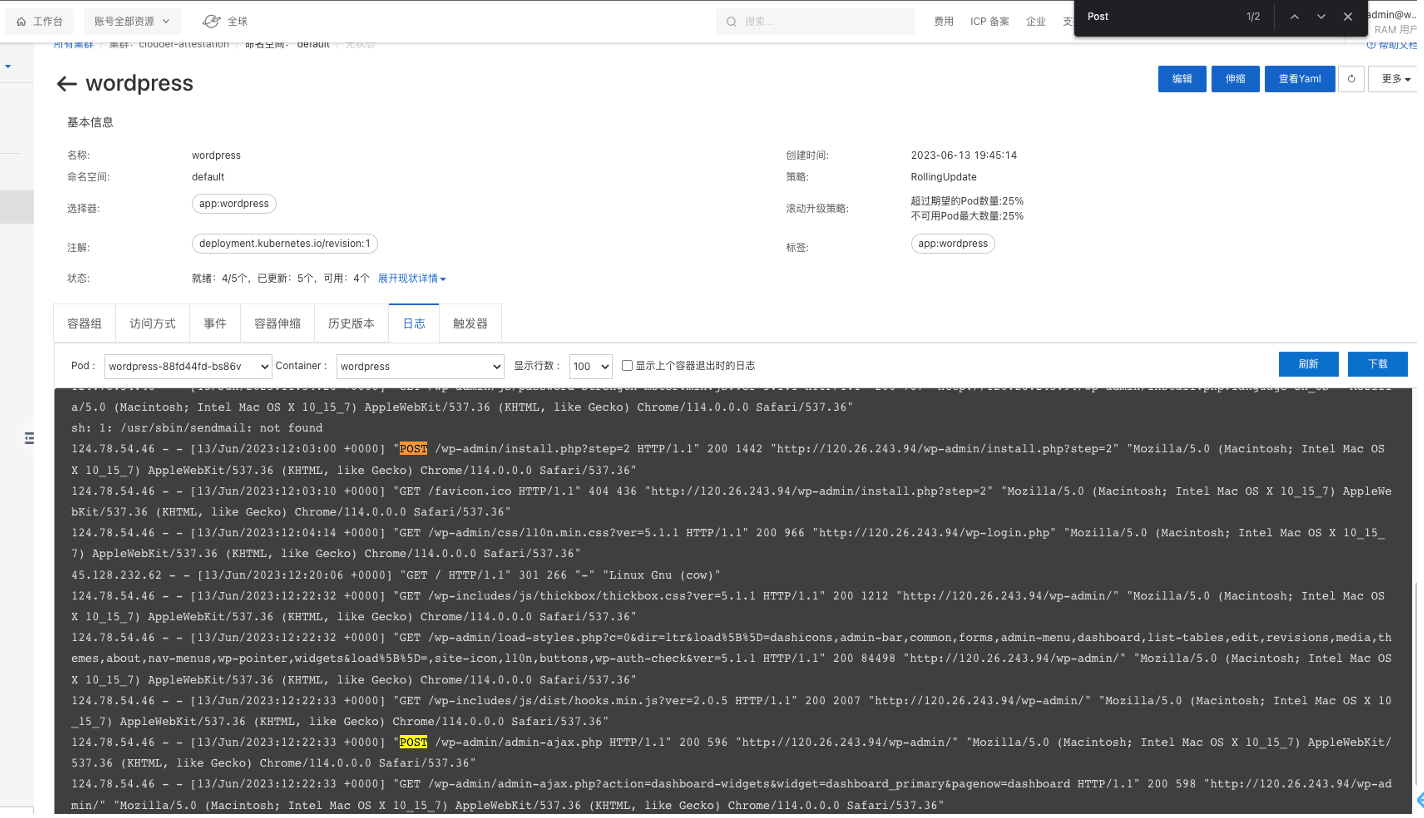
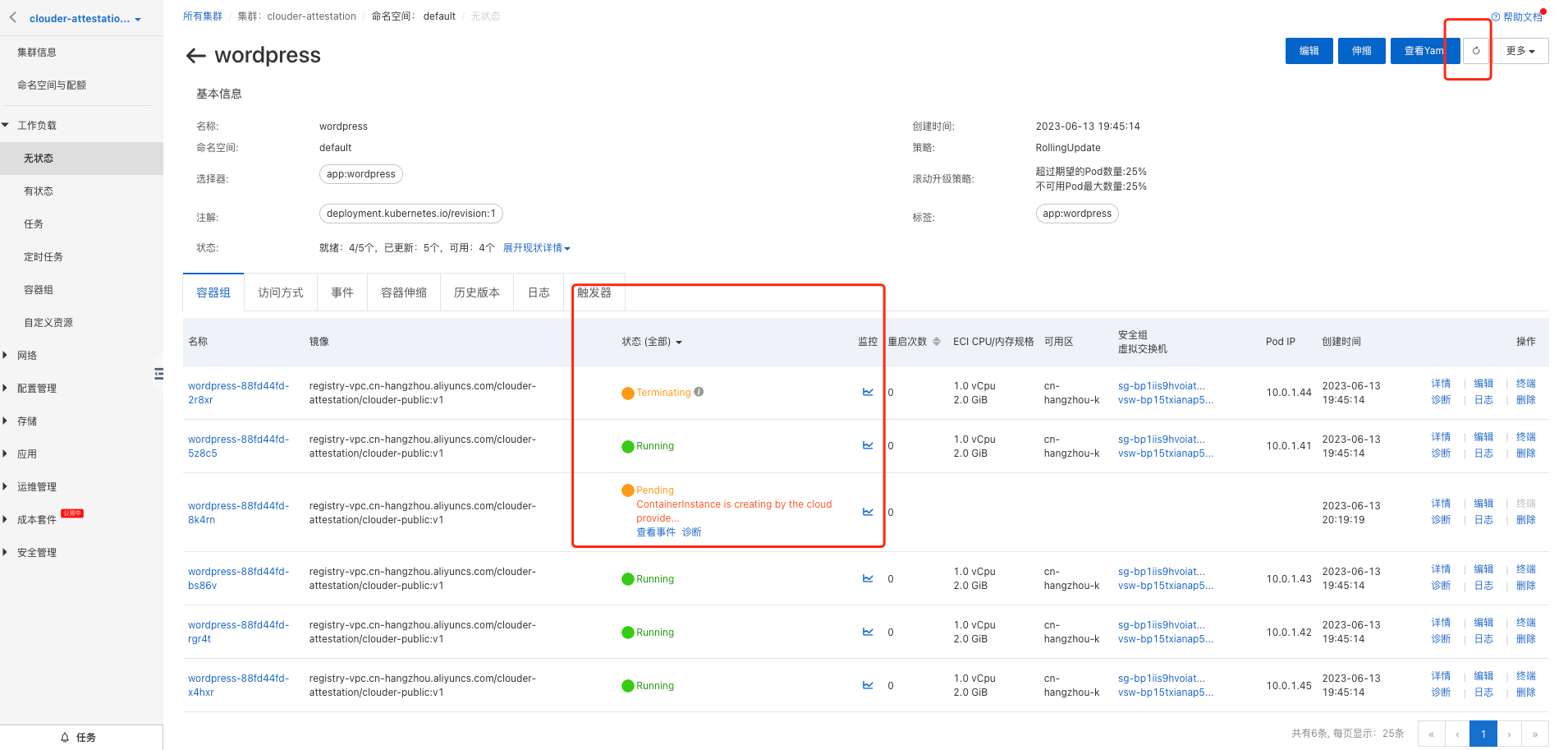
可以查看工作负载无状态的情况。我们还可以查看容器组(Pod)、访问方式、事件、容器伸缩、历史版本、日志、触发器等信息。如下图:
可以在ACK Serverless控制台观察容器的日志信息,并可根据关键字检索日志信息。
集群管理与监控
Prometheus是一个开源的系统监控和报警系统,在kubernetes中常常会搭配Prometheus进行监控,Prometheus性能足够支撑上万台规模的集群。ACK Serverless中集成了Prometheus服务,可以安装Prometheus,完成对ACK Serverless集群的监控。
查看Prometheus的情况,可查看监控概况、核心组件监控、应用监控等其他监控。
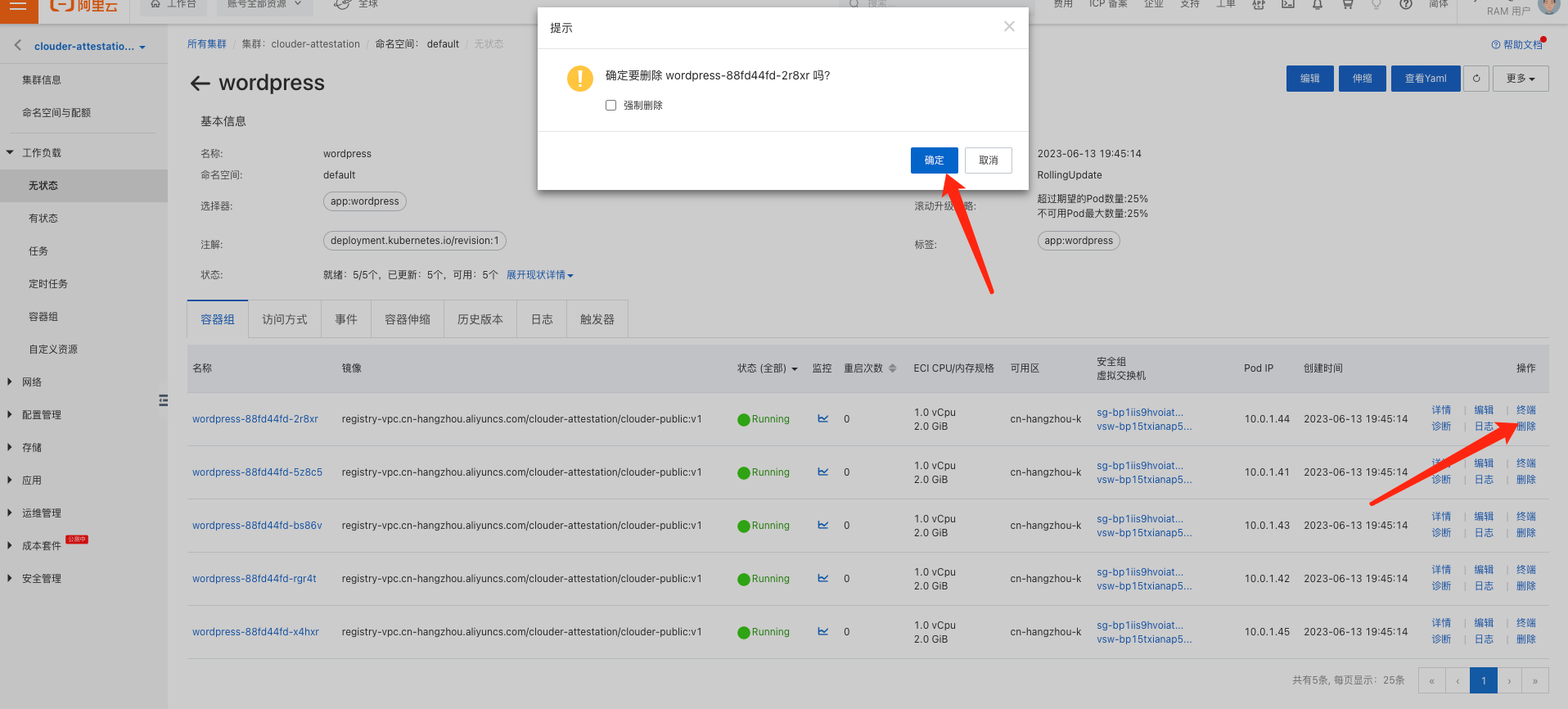
通过手动删除Pod,模拟一个Pod上的应用异常下线的情形,体验ACK Serverless的自动恢复功能,并观察Pod恢复过程中的状态变化。
删除一个Pod后,容器组会自动自愈,下图是观察ACK Serverless恢复过程的情况。 删除一个Pod后,容器组会自动自愈,下图是观察ACK Serverless恢复过程的情况。
至此,我们通过ACK Serverless完成了企业网站应用的创建和部署,并了解ACK Serverless对于容器集群的基础管理和运维监控能力。 |
|
|
课程的关键知识点总结:
通过本课程,我们基于ACK Serverless构建了公司网站的容器集群,完成了网站应用的上线。但如果要进一步运营好公司网站,仍然面临网站应用升级等一系列实际使用的问题,比如:
|
|
|
课程延伸学习内容,对Kubernetes的设计思想、核心概念和机制进行介绍,以便帮助您更好的理解容器集群与编排技术。 Kubernetes 设计思想Kubernetes 基于API管理一切的思想,采用声明式即“面向结果”的API,围绕 etcd(分布式存储与协调数据库) 构建出来的一套 “面向终态” 的编排体系。 当用户向 Kubernetes 提交了一个 API 对象(Kubernetes Object)的期望状态(Spec)之后,Kubernetes 会负责保证整个集群里各项资源的当前状态(Status),都与 API 对象描述的需求相一致。更重要的是,这个保证是一项 “无条件的”、“没有期限” 的承诺:对于每个保存在 etcd 里的 API 对象,Kubernetes 都通过启动一种叫做 “控制器模式”(Controller Pattern)的无限循环,不断对 etcd 里的 API 对象的变化进行监视(Watch),然后执行控制器(Controller)里定义的编排动作的响应逻辑,进行调谐,最后确保整个集群的状态与 API 对象的描述一致。
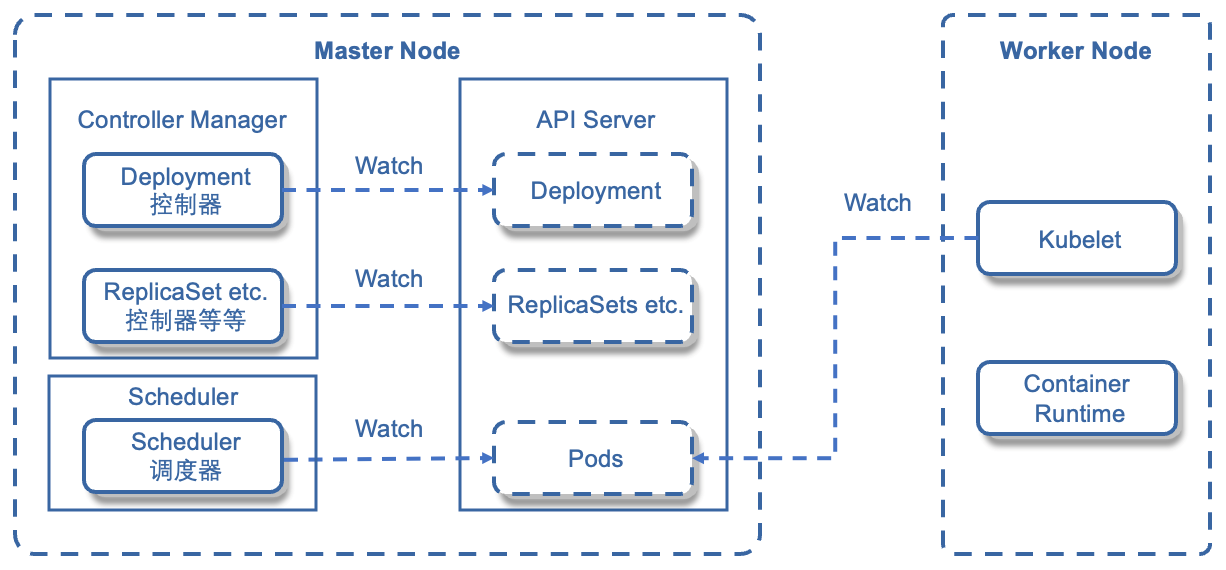
为了实现“面向终态”的管理,支持自动化部署、扩缩和管理容器应用,Kubernetes采用了控制平面和计算平面分离的架构。控制平面是整个集群的大脑,负责控制、调度集群资源;计算平面负责运行容器化应用,是控制平面调度的对象,通过增加或减少工作节点实现容器集群处理能力的扩缩。控制平面由至少一个管理节点(Master节点)组成,通常会采用三个管理节点组成高可用集群(一个管理节点提供服务,剩下两个管理节点为备用节点,当管理节点不可用时,从备用节点中自动选举一个出来成为管理节点)。计算平面则由多个工作节点(Node节点)组成。
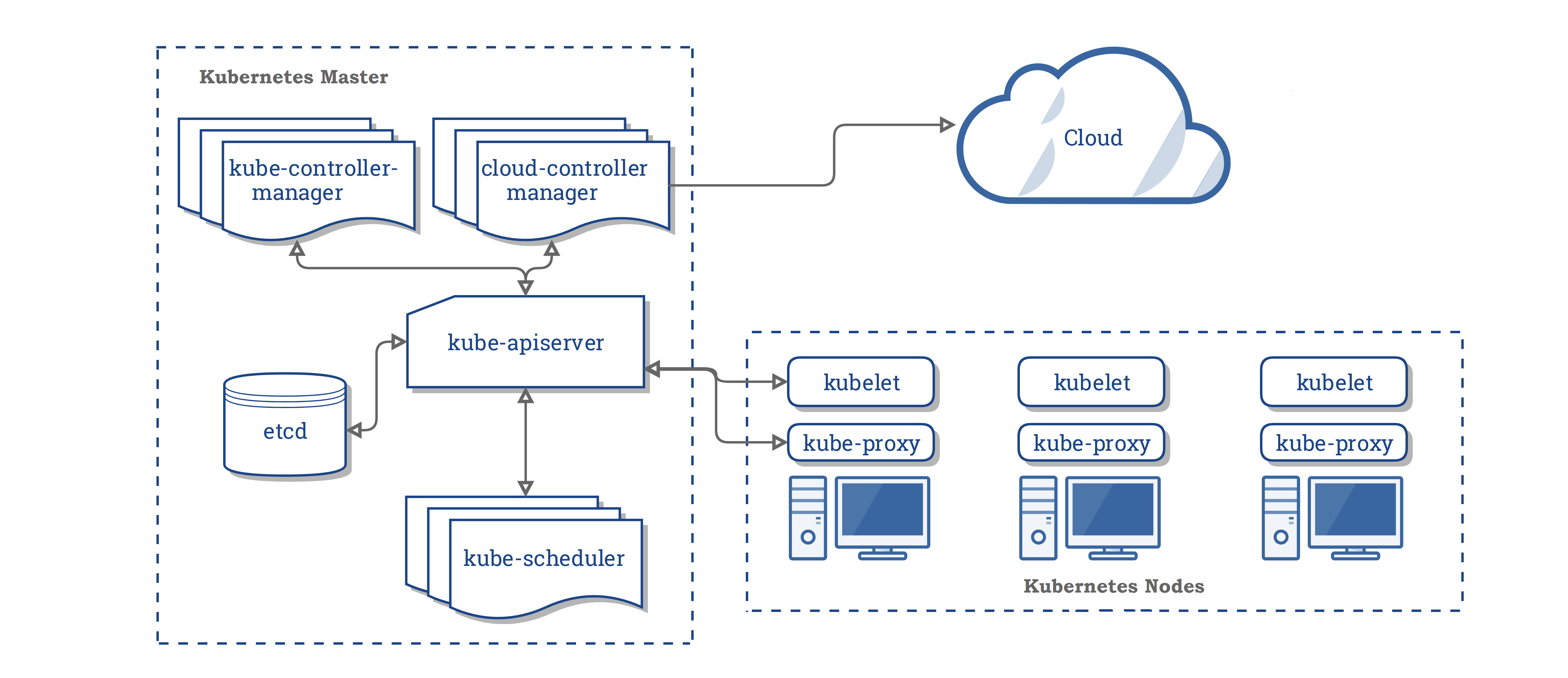
1.Master节点 Master节点(管理节点)主要负责管理和控制整个Kubernetes集群,对集群做出全局性决策,相当于整个集群的“大脑”。集群所执行的所有控制命令都由Master节点接收并处理。它在集群中主要负责如下任务:
一个管理节点包含四个主要组件:API Server、Controller Manager、Scheduler 及 etcd。 2.Node节点 Node节点(工作节点)是Kubernetes集群中的工作节点,Node节点上的工作由Master节点进行分配,比如当某个Node节点宕机时,Master节点会将其上面的工作转移到其他Node节点上。Node节点在集群中主要负责如下任务:
一个Node节点主要包含三个组件:kubelet、kube-proxy、Container Runtime。
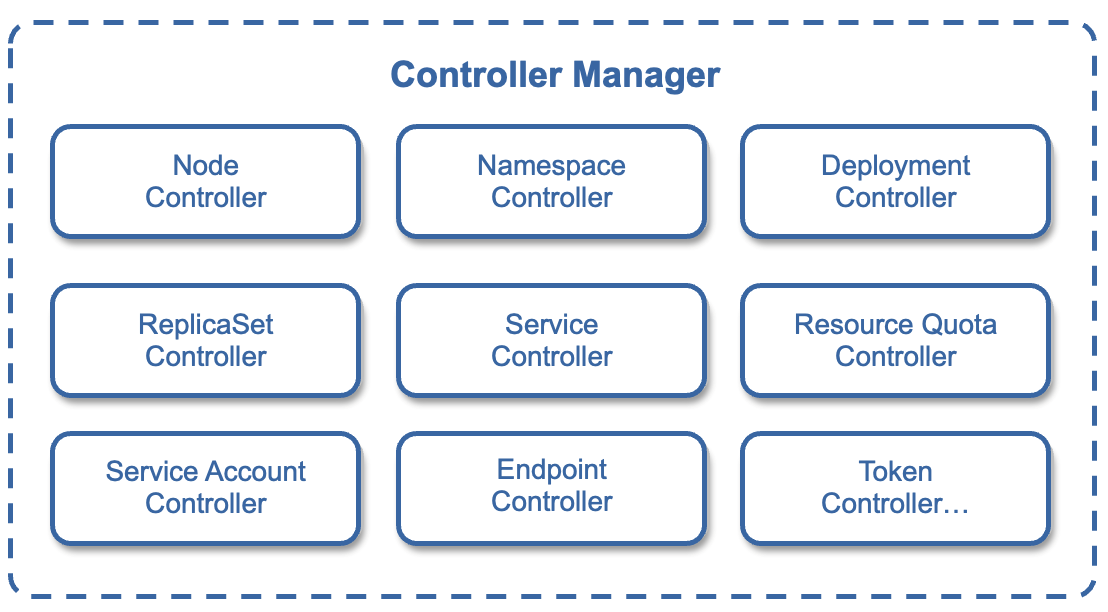
Controller是什么?工作负载是一种Controller,在Kubernetes中还有Node Controller等其他多种控制器。每种控制器都是一个智能系统,通过API Server提供的(List-Watch)接口实时监控集群中资源对象的变化,当资源对象因某些原因发生状态变化时,Controller会执行相应逻辑使其最终状态调整到期望状态。比如:某个Node意外宕机时,Node Controller会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。 每种Controller都负责一种特定的资源控制器,Controller Manager是Kubernetes中各种Controller的管理者,是集群内部的管理控制中心,也是Kubernetes自动化功能核心。
Kubernetes中如何实现多个环境的隔离?在Kubernetes容器集群中,同一类型的资源名称是唯一的。在实际中,我们往往需要将不同业务、不同的项目、不同的环境进行隔离管理,这就需要通过命名空间Namespace进行分区管理。 Namespace 是用来做集群内部的逻辑隔离的,它包括鉴权、资源管理等。Kubernetes 的每个资源,比如 Pod、Deployment、Service,都属于一个 Namespace,同一个 Namespace 中的资源命名唯一,不同的 Namespace 中的资源可以重名。在一个Kubernetes集群中可以拥有多个命名空间,它们在逻辑上彼此隔离。 不过,Kubernetes也有一些资源隶属于集群级别的,如Node、Namespace和Persistent Volume等,不属于任何名称空间,所以这些资源对象的名称必须全局唯一。
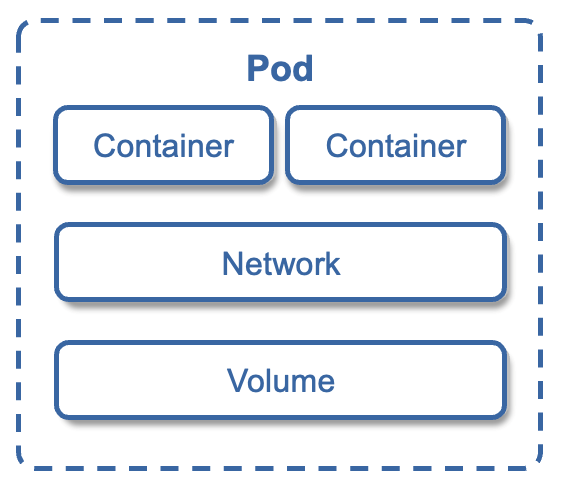
Kubernetes的原子调度单位Pod在操作系统中,进程不是"孤苦伶仃"的运行,而是以进程组的方式,"有原则的"组织到一起运行。一个进程组内的进程可以共享文件和资源。Kubernetes借鉴了操作系统的"进程组" 的概念,并抽象出一个逻辑概念Pod。由于Pod是一组紧密关联的容器集合,也叫它容器组。Pod是Kubernetes中操作的基本单元。为了便于理解,我们可以做个类比,Kubernetes就是一个操作系统,就像Linux;Pod就是一个进程组,就像Linux线程组;容器就是一个进程,就像Linux线程。
Kubernetes把Pod作为原子调度单位,主要有两个原因:
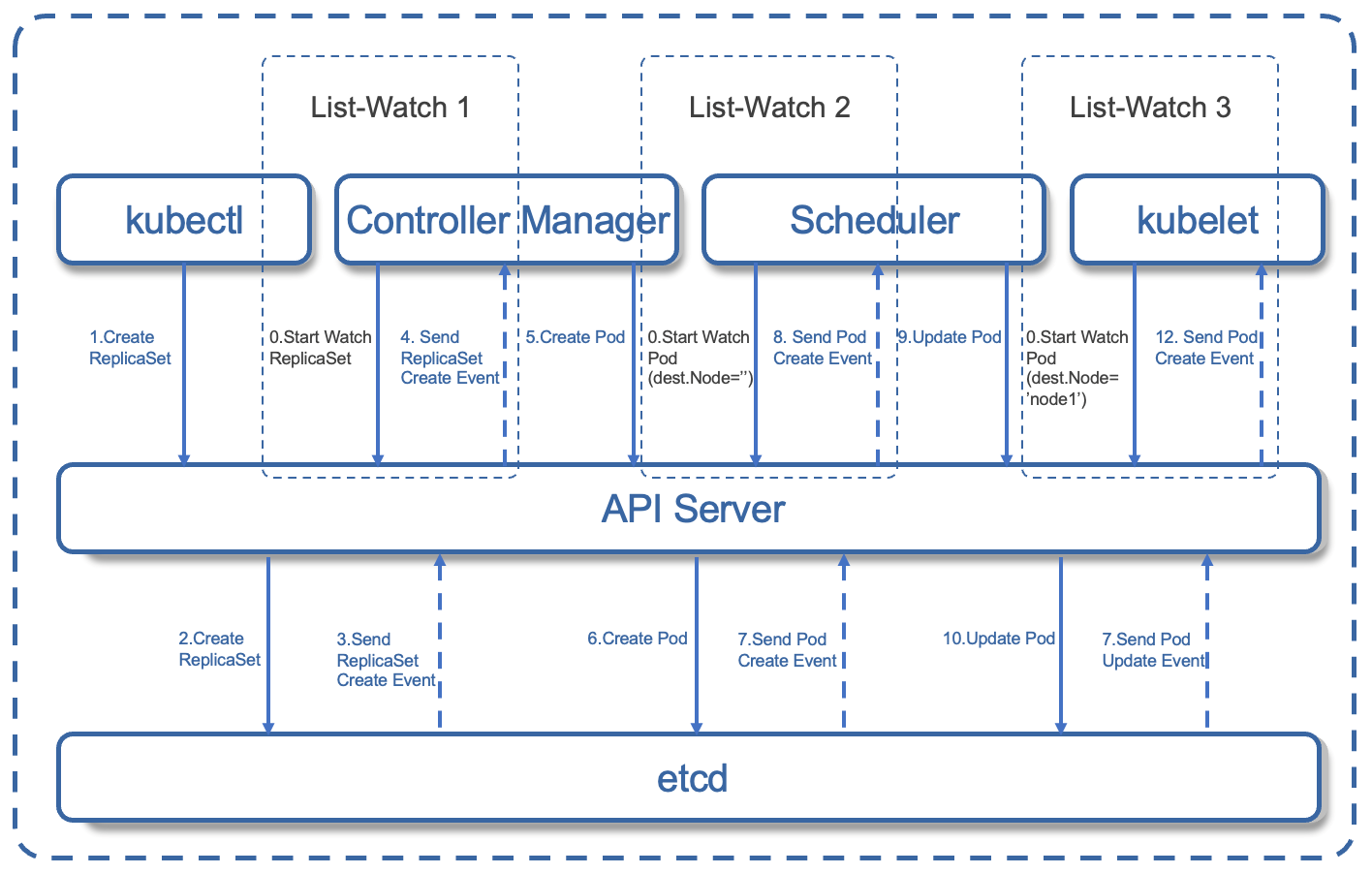
在创建无状态工作负载过程中,Kubernetes都做了哪些事情呢? 延伸阅读:无状态Pod的创建流程我们知道无状态工作负载Deployment创建容器组,是通过控制ReplicaSet来实现的,下面我们了解下ReplicaSet创建Pod 的详细流程。
图中有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。它们在进程一启动就会监听(Watch)API Server 发出来的事件。我们来看下创建的12个步骤。
注意:在完成Pod的创建之后,kubelet 还会一直保持监听,为什么?原因很简单,客户可能有新的请求,如kubectl 发出命令要求扩充 Pod 副本数量,那么上面的流程又会触发一遍,kubelet 会根据最新的 Pod 的部署情况调整 Node 的资源。又或者 Pod 副本数量没有发生变化,但是其中的镜像文件升级了,kubelet 也会自动获取最新的镜像文件并且加载。 Pod内如何实现数据共享?Volume是Pod中能够被多个容器访问的共享目录,通过Volume可以让容器的数据写到宿主机上或者写文件到网络存储中。
Kubernetes中的Volume与Docker的Volume相似,但不完全相同。
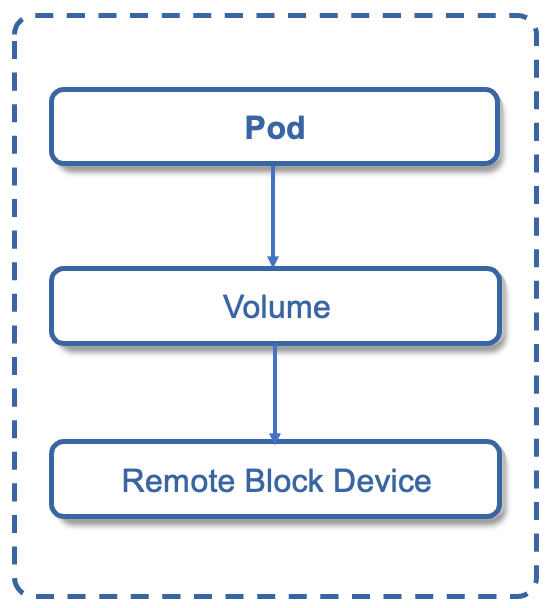
Kubernetes的Volume使用方法,是先在Pod上声明一个Volume,然后容器引用该Volume并Mount到容器的某个目录。 Volume有emptyDir和hostPath两种类型。emptyDir是在Pod分配到Node时创建,初始内容为空,无须指定宿主机上对应的目录文件,由Kubernetes自动分配一个目录,当Pod被删除时,对应的emptyDir数据会永久删除。hostPath则是在Pod上挂载宿主机上的文件或目录,与Pod的销毁无关。
Kubernetes的数据如何持久存储? Kubernetes是通过PV和PVC来实现集群数据的持久化的。
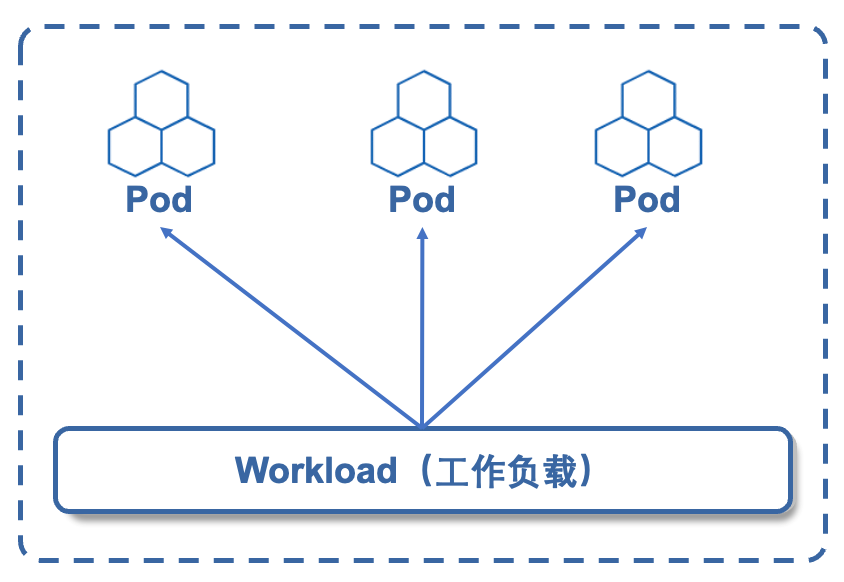
工作负载(Workload)是什么?为了减轻用户的使用负担,通常不需要用户直接管理每个 Pod。 而是使用工作负载资源来替用户管理一组Pod,比如启动指定数量的Pod或实现容器应用的滚动升级。工作负载是在 Kubernetes 上运行的应用程序,是一种控制器。
工作负载是管理Pod的中间层,使用了工作负载之后,只需要告诉它,想要多少个、什么样的Pod就可以了,它就会创建出满足条件的Pod,并确保每一个Pod处于用户期望的状态,如果Pod在运行中出现故障,控制器会基于指定策略重启或者重建Pod。
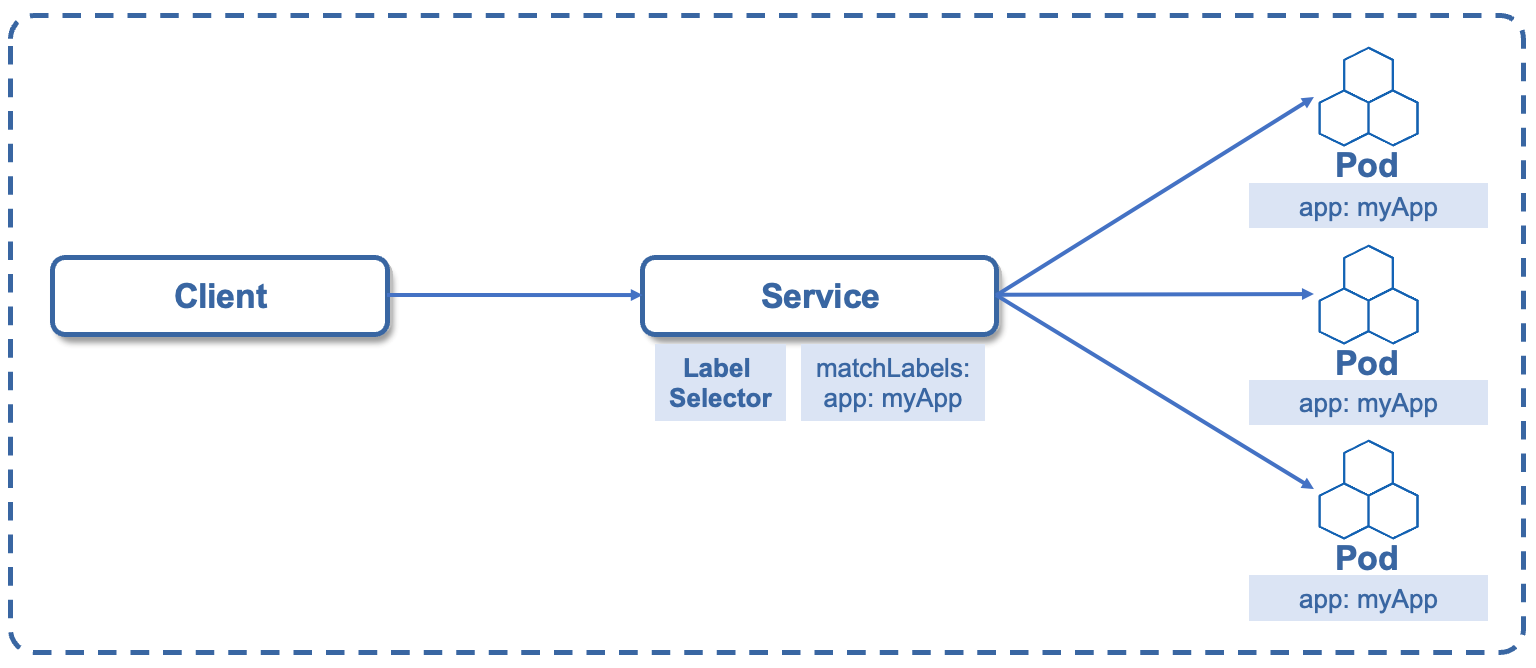
Kubernetes集群应用的访问通过工作负载我们创建了一组Pod出来,由于Pod会被销毁后重启,或者会增加新的Pod。用户怎么能访问这些Pod呢? Pod地址是变化的,不能直接访问。能否提供一个固定的访问Pod的入口,不用关心Pod地址的变化呢? Kubernetes通过Service为一组功能相同的pod提供稳定的访问地址,Service是一个抽象的概念,它定义了Pod的逻辑分组和一种可以访问它们的策略,这组Pod能被Service访问。Service是如何识别这些Pod的呢?通过选择器Selector来识别成员Pod。需要注意的是,Service后端不一定是Pod,可能是Kubernetes集群外的物理机,如MySQL数据库。
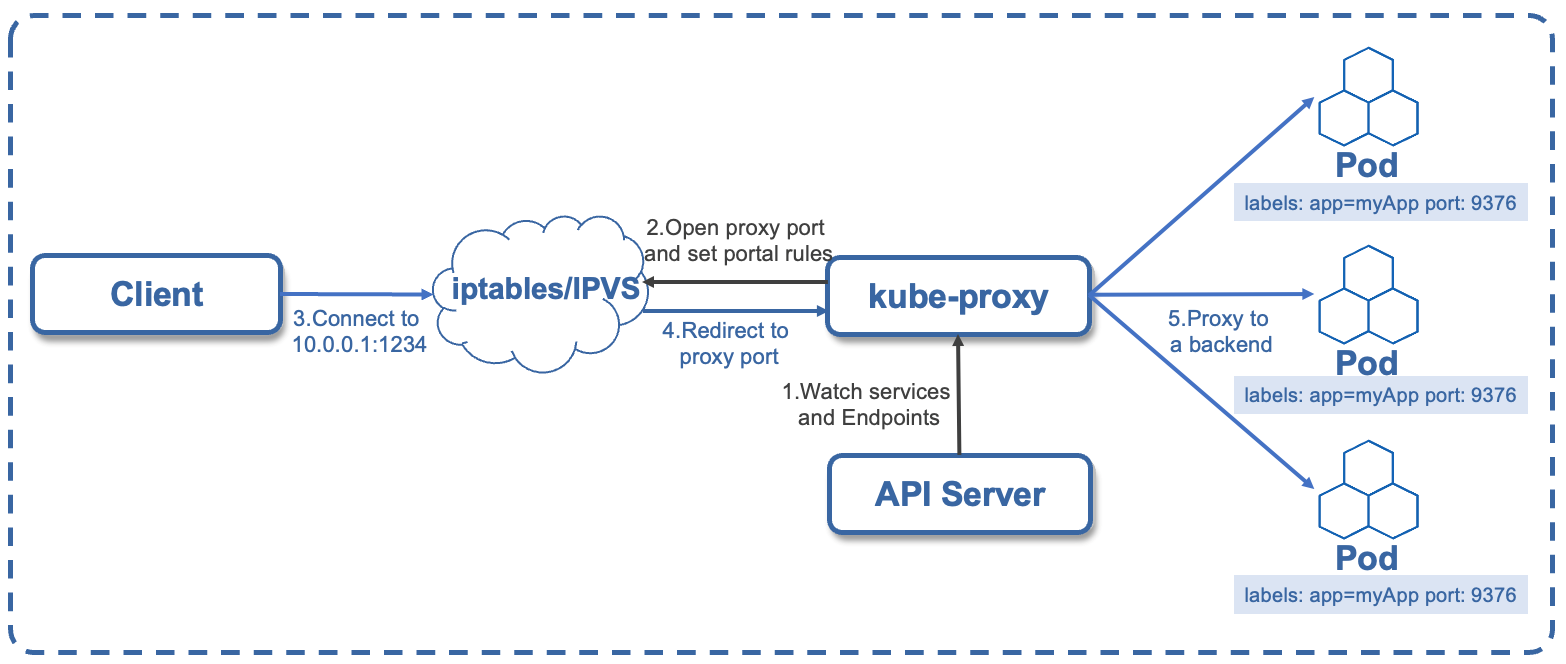
Service是通过Selector选择的一组Pods的服务抽象,提供了服务的负载均衡和反向代理的能力。实现 Service 负载均衡和反向代理功能,是通过kube-proxy实现的。kube-proxy 运行在每个节点上,监听 API Server 中服务对象的变化,通过管理 iptables 来实现网络的转发。
Service的负载均衡实现的过程共分为五步,如下:
Service的访问方式Service的访问方式有多种,如下:
由于Service只提供了四层服务,若要通过Http/Https的七层访问方式访问服务,则需要通过LoadBalancer的方式,将访问流量转发到Service上来实现。
|
|
容器应用与集群管理ACK Serverless




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/881700.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
selenium框架使用最佳实践
安装chromdriver插件
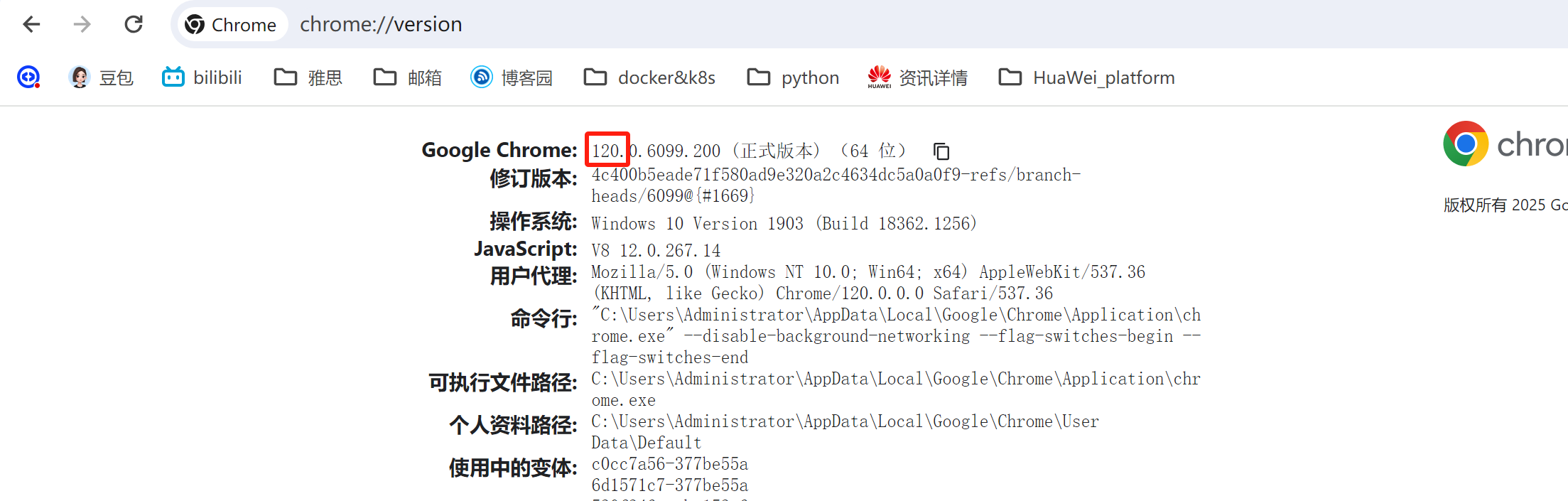
selenium框架使用需要下载chromdriver插件,版本需要和chrome浏览器的大版本一致,查看浏览器版本方法:chrome://version/ChromeDriver的主版本号(即120)与Chrome浏览器主版本号匹配就可以了,不需要小版本号完全一致。
chromdriver的官方下载页面:htt…
004 字符串的扩展
1、字符串Unicode表示法ES6加强了对Unicode的支持,允许采用\uxxx形式表示一个字符,其中xxxx表示字符的Unicode码点。
Unicode统一吗(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而…
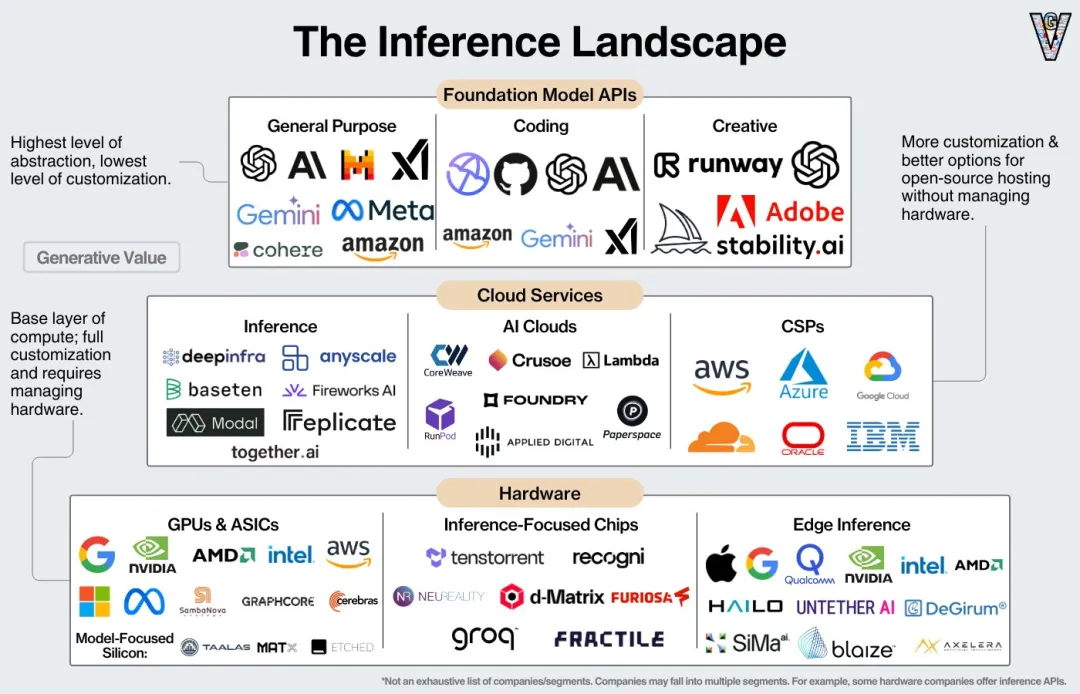
大模型推理服务全景图
推理性能的提升涉及底层硬件、模型层,以及其他各个软件中间件层的相互协同,因此了解大模型技术架构的全局视角,有助于我们对推理性能的优化方案进行评估和选型。作者:望宸
随着 DeepSeek R1 和 Qwen2.5-Max 的发布,国内大模型推理需求激增,性能提升的主战场将从训练转移到…

三菱变频器与西门子PLC的高效通讯之道:EtherNet/IP 转 ModbusTCP配置实战
三菱变频器与西门子PLC的高效通讯之道:EtherNet/IP 转 ModbusTCP配置实战一、案例背景
某汽车制造公司拥有一条高度自动化的生产线,该生产线集成了来自不同品牌的机器人、传感器和检测设备。这些设备分别采用MODBUS TCP和EtherNet/IP协议进行通信,但由于协议不兼容,导致数据…
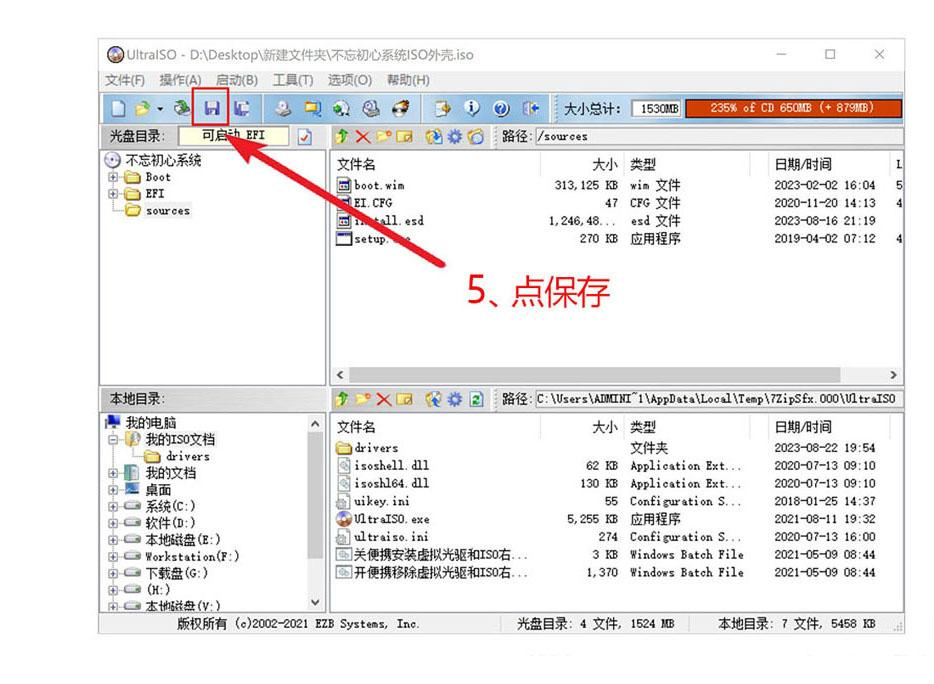
windows镜像esd转iso
背景
经常在三方网站下载到精简系统,但是这些系统的格式不仅仅是iso,还有可能是esd。
虽然两者几乎等价,但是有些平台 比如虚拟机、mac转换助理不能识别esd格式的镜像。
windows下转换
准备工作
首先要先下载所需的ISO外壳和Ultraiso软碟通软件。
把你要安装的ESD系统改名,…
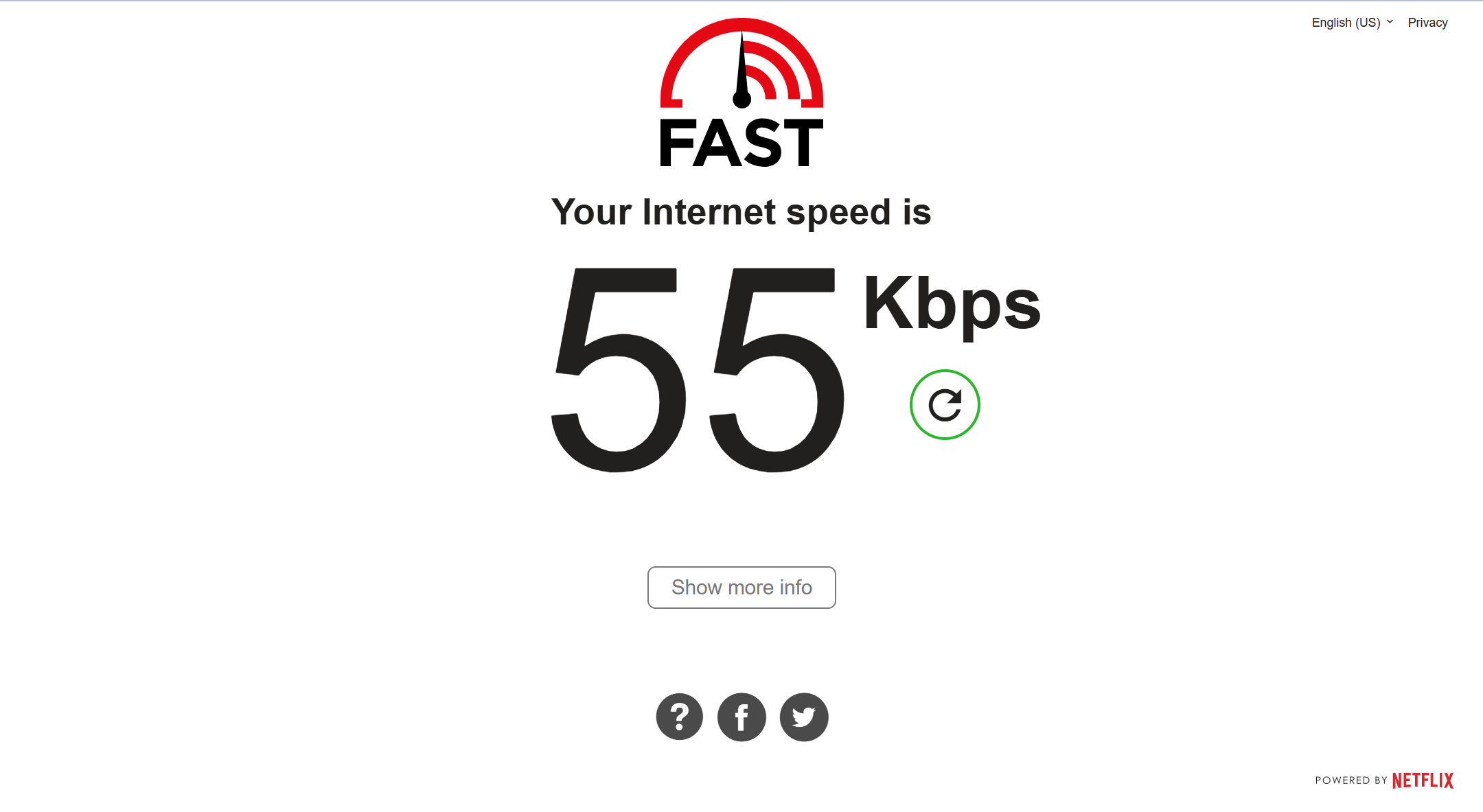
alice.ws的VPS怎么样?
这是是香港 1美元的机器,延迟可以,但速度他标1Gbps,但我广东移动网络,测的速度, 垃圾地离谱,怀疑是限制速度,是我见过最垃圾的,其它VPS节点是正常的50Mbps左右,不是我网络有问题。
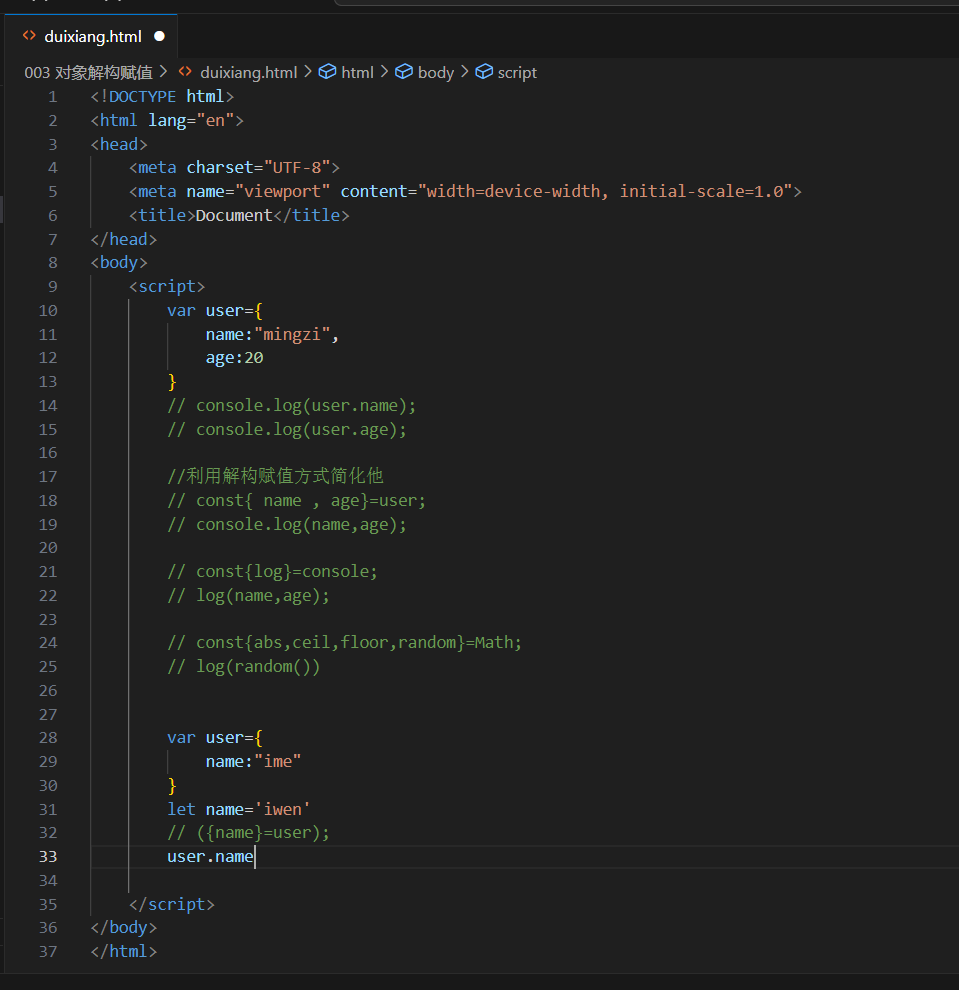
003 对象解构赋值
解构可以用于对象
let{name,age}={name:"iwen",age:20};
温馨提示:对象的属性没有次序,变量必须与属性同名,才能取到正确的值
let {age,name}={name:"mingzi",age:20};
age//20
let{sex,age,name}={name:"mingzi",age:20};
sex//undefind
对…
【EasyExcel】 easyExcel 3.2.1 生成多sheet的xlsx文件
pom依赖:<dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.2.1</version></dependency>
核心util写法:import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWrit…
CVE-2024-41592 of DrayTek vigor3910 复现
getcgi接口存在堆栈溢出CVE-2024-41592 of DrayTek vigor3910 复现
漏洞简介DrayTek Vigor3910 devices through 4.3.2.6 have a stack-based overflow when processing query string parameters because GetCGI mishandles extraneous ampersand characters and long key-valu…


spring项目启动后,直接停止
在启动一个新的项目后,项目启动了,但是直接停止了。
这是该项目的application目录 没有原始的application.yml文件。所以项目没有查找到对应的配置文件,启动直接停止了。
本地启动中可以在IDEA中配置选择程序实参指定读取哪个配置文件
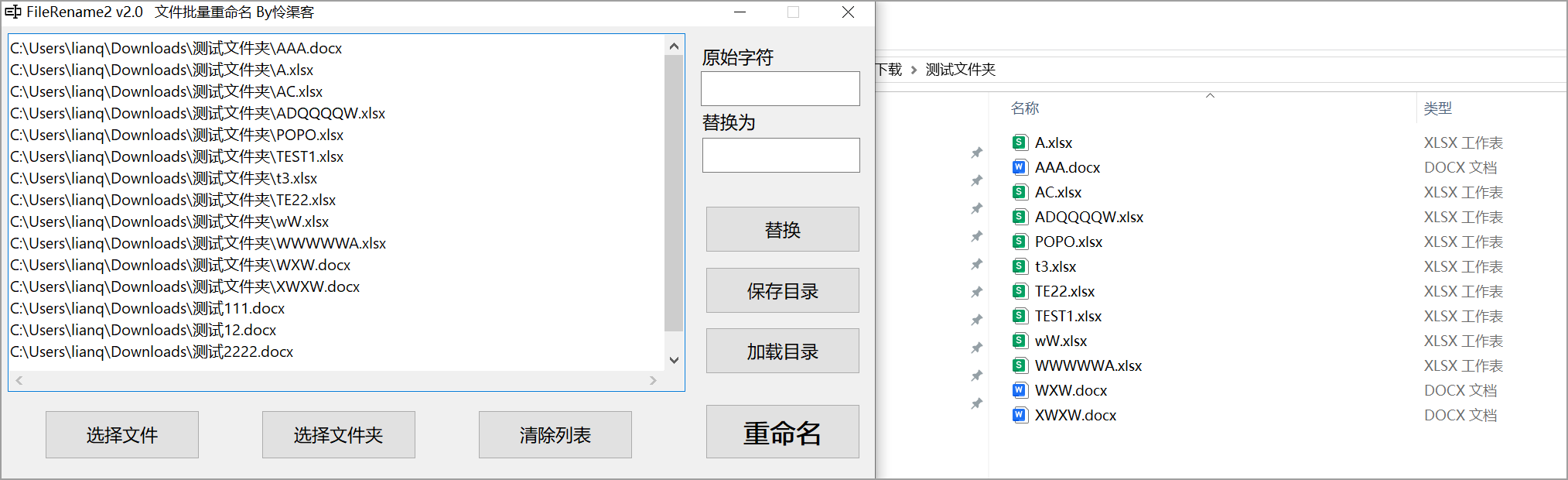
【原创工具】文件批量重命名 FileRename2 By怜渠客
【原创工具】文件批量重命名 FileRename2
半年前写过一个重命名小工具,但是有不少问题和局限,这次进行一个比较大的改进:支持导出当前文件名列表到文本文件,修改后一键导入重命名
减小软件体积(本就是小工具,超过2MB是不行滴)
更换编程语言为FreePascal、编译器为FPC使用…