开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq,@鲍勃
01 有话题的技术
1、小红书开源 FireRedASR 语音识别模型,取得中文语音识别新突破

近日,小红书 FireRed 团队开源了基于大模型的语音识别模型 FireRedASR,该模型在中文普通话语音识别领域取得了新的 SOTA(State of the Art,最佳性能)。FireRedASR 包含两种核心结构:FireRedASR-LLM 和 FireRedASR-AED,分别针对极致精度和高效推理需求设计。其中,FireRedASR-LLM(8.3B 参数)在公开测试集上取得了 3.05%的字错误率(CER),成为新的 SOTA,相比此前的 SOTA 模型 Seed-ASR(12B+参数)降低了 8.4%的错误率;FireRedASR-AED(1.1B 参数)则在保持高准确率的同时,显著提升了推理效率,其 CER 为 3.18%。
此外,FireRedASR 在中文方言、英语以及歌词识别等场景中也展现了卓越的性能,显著优于此前的开源 SOTA 模型。FireRed 团队已开源模型和代码,旨在推动语音识别技术的发展和应用。(@机器之心)
2、Meta AI 推脑机接口模型 Brain2Qwerty:可通过脑电波解码打字内容
Meta AI 最新推出的 Brain2Qwerty 模型为脑机接口(BCI)技术带来了新的希望。该模型旨在通过非侵入性方式,从脑电图(EEG)或脑磁共振成像(MEG)捕捉到的脑活动中解码出参与者输入的句子。在研究中,参与者在 QWERTY 键盘上输入短暂记忆的句子,同时其脑活动被实时记录。与传统方法相比,Brain2Qwerty 利用自然的打字运动,提供了一种更直观的脑电波解读方法。
Brain2Qwerty 的架构分为三个主要模块:
-
卷积模块 :提取 EEG 或 MEG 信号中的时间和空间特征。
-
变换器模块 :处理输入的序列,优化理解和表达。
-
语言模型模块 :预训练的字符级语言模型,用于修正和提升解码结果的准确性。
在性能评估中,基于 EEG 的解码字符错误率(CER)为 67%,而使用 MEG 的解码效果显著改善,CER 降低至 32%。在实验中,表现最好的参与者达到了 19%的 CER,显示出该模型在理想条件下的潜力。
尽管 Brain2Qwerty 在非侵入性 BCI 领域展现了积极的前景,但仍面临几项挑战。首先,当前模型需要处理完整句子,而不是逐个按键进行实时解码。其次,虽然 MEG 的性能优于 EEG,但其设备尚不便携且普及性不足。最后,本研究主要在健康参与者中进行,未来需要深入探讨其对运动或言语障碍者的适用性。(@ AIbase 基地)
3、豆包大模型团队开源 VideoWorld:无需语言模型即可认知世界的视频生成模型
2025 年 2 月 10 日,豆包大模型团队联合北京交通大学和中国科学技术大学发布了 VideoWorld,这是一种创新的视频生成模型,能够仅通过视觉信息学习复杂知识。VideoWorld 的推出标志着在无需依赖语言模型的情况下,AI 可以通过观察视频数据掌握推理、规划和决策等能力。
VideoWorld 模型通过潜在动态模型(Latent Dynamics Model, LDM)高效压缩视频帧间变化信息,显著提升了知识学习效率和效果。在只有 300M 参数量的情况下,VideoWorld 已展现出可观的性能,达到了专业 5 段的 9x9 围棋水平,并能在多种环境中执行机器人任务。
下图为模型架构概览,左侧为整体架构,右侧为潜在动态模型。
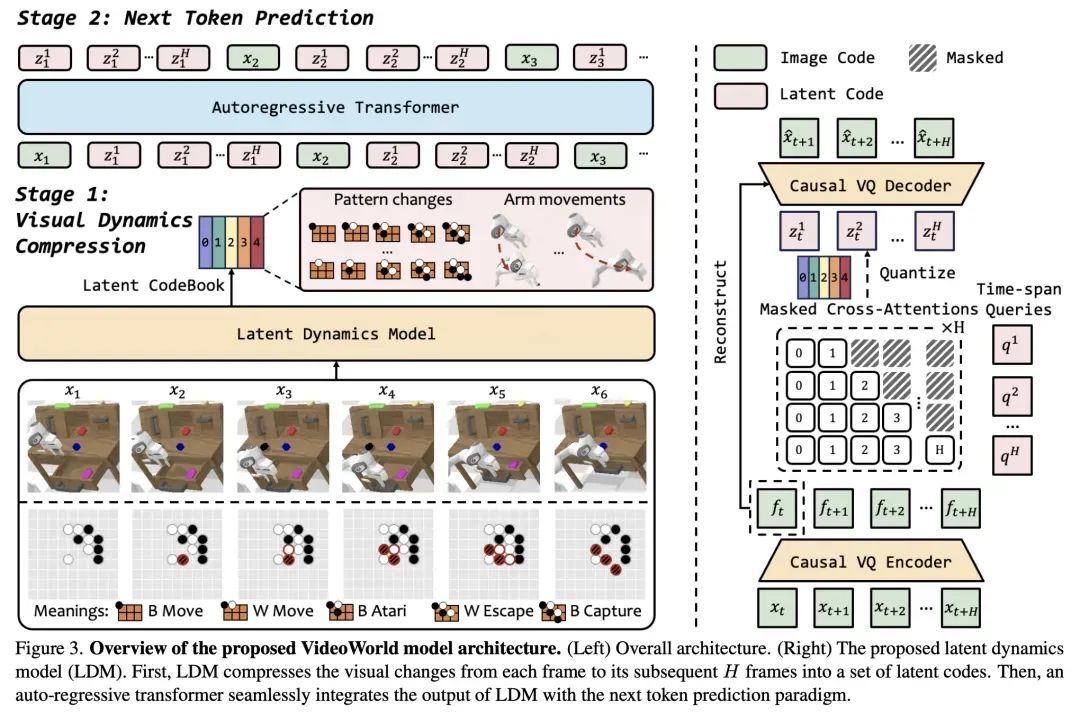
目前,VideoWorld 的项目代码与模型已经开源,供公众体验和交流。
论文链接为:https://arxiv.org/abs/2501.09781
代码链接为:https://github.com/bytedance/VideoWorld
项目主页为:
https://maverickren.github.io/VideoWorld.github.io。(@豆包大模型团队)
4、智元机器人在深圳成立新「灵犀」产品线
智元机器人近日宣布在深圳成立新的「灵犀」产品线,作为公司三大事业部之一,目前正处于招聘阶段。智元机器人此前进行了组织架构调整,新设立了远征、灵犀和 Genie 三大产品线,分别位于上海、深圳和北京。灵犀产品线目前由稚晖君暂代,正在寻找合适的一号位人选。灵犀系列产品主要面向养老方向的消费者市场。智元机器人自成立以来一直致力于全栈自研,包括软件、硬件、大脑、小脑和云系统等,并提出了具身智能 G1 到 G5 的演进路径和技术框架,目前正处于 G2 和 G3 阶段。2024 年 12 月,智元机器人宣布开启机器人量产工作,并于 2025 年 1 月 6 日下线了第 1000 台通用具身机器人。(@ AI 科技评论)
5、Meta 推出 VideoJAM 框架:大幅提升视频生成中的运动一致性

2025 年 2 月 10 日,Meta GenAI 团队发布了 VideoJAM 框架,旨在解决视频生成中的运动一致性问题。该框架基于 DiT 路线,通过引入联合外观-运动表示,显著提升了视频生成中的运动连贯性和视觉质量。
VideoJAM 框架的关键特点包括:
-
联合外观-运动表示:在训练阶段,VideoJAM不仅预测视频的像素,还预测视频的运动信息,通过将视频和运动信息合并为一个联合表示,模型能够同时学习外观和运动。
-
动态引导机制:在推理阶段,VideoJAM 利用模型自身不断演化的运动预测作为动态引导信号,确保生成的视频在运动上更加合理和连贯。
-
通用性和适配性:VideoJAM 可以无缝集成到任何视频生成模型中,无需修改训练数据或扩大模型规模。
VideoJAM 在多个复杂运动场景中表现出色,例如倒立动作的流畅生成、双人舞的完美同步、吹灭蜡烛时火苗的晃动及熄灭过程、书法中毛笔的运动及笔迹同步、杂技表演中抛物线轨迹的精准呈现等。(@量子位)
6、DreamTech 发布 Neural4D 2.0:3D 生成技术取得重大突破
2025 年 2 月 10 日,由牛津大学和南京大学研究者组成的 AI 团队 DreamTech 宣布推出 Neural4D 2.0,这是一款创新的 3D 生成平台,通过全新的 3D Assembly Generation 算法和高效的模型架构,显著提升了 3D 内容生成的效率和质量。
Neural4D 2.0 的核心亮点包括:
-
算力需求降低 80% :通过专有的三维数据处理链路和强化学习策略,优化了 Transformer 结构,大幅减少了算法的时间和空间复杂度,算力需求仅为同类型算法模型的 1/5 左右。
-
分部件可装配生成 :采用分部件生成思路,模拟真实世界的 3D 拓扑结构,将复杂的 3D 内容分解为多个部件,解决了复杂、高精细、可交互 3D 内容生成的质量瓶颈。
-
AnimeArt 功能: 基于 Neural4D 2.0 推出 AnimeArt 功能,这是业内首款成熟的二次元 3D AIGC 平台,支持实时生成与驱动头发、服装、手指动作和面部表情,可用于数字人直播和 MMD 动画制作等应用。
-
开源推动行业发展 :DreamTech 已开源其前期研究成果 Neural4D 1.0(原 Direct3D),代码和论文均面向公众开放。
Neural4D 2.0 的推出标志着 3D 生成技术在效率、精细度和应用范围上的重大突破,有望在游戏开发、动画制作、虚拟现实体验等多个领域带来深远影响。(@ Z Potentials)
02 有亮点的产品
1、昆仑万维天工 AI:上线 DeepSeek R1+联网搜索功能
2 月 8 日,昆仑万维集团旗下的天工 AI 正式上线了「DeepSeek R1+ 联网搜索」功能,为用户带来了一次重大更新。这一升级不仅解决了 DeepSeek 联网功能无法使用的问题,还优化了 R1 版本偶尔崩溃的困扰,极大地提升了 AI 的稳定性和用户体验。
自 2025 年 1 月下旬发布以来,DeepSeek R1 模型迅速在全球 AI 领域引起关注。然而,其联网搜索功能的缺失一直是用户关注的焦点。此前,DeepSeek R1 只能根据 2024 年 10 月前的信息进行思考,且「深度思考」模式时常出现服务器繁忙的问题。如今,天工 AI 的 PC 端网页为用户提供了无缝的联网搜索体验,实时获取最新信息,进一步增强了 AI 在复杂场景下的推理和思考能力。
用户现在可以在天工 AI 的 PC 端网页上,通过勾选「深度思考 R1」按钮,轻松调用联网搜索功能,获得更加精准和全面的结果。无论是学术研究、商业分析、文章写作,还是日常问题的搜索和解答,天工 AI 都能提供强大的支持。
在实际应用中,天工 AI 的「深度思考 R1」模式展现了强大的联网搜索能力。例如,当被问及《哪吒 2》的最终票房时,天工 AI 通过联网搜索,捕捉到截至 2 月 7 日的票房数据,并合理预测其全球总票房将突破 100 亿人民币。在问答领域,天工 AI 也能够以诙谐幽默且带有讽刺意味的口吻回答问题,展现出 DeepSeek R1 模型的独特风格。(@ AIbase 基地)
2、OpenAI 新项目 Sora 内测图像生成器,或将推出 DALL-E 4
OpenAI 最近宣布其内部测试项目 Sora 正在研发图像生成功能,用户可以在视频和图像生成之间快速切换。新功能旨在简化用户操作,提升内容生成的相关性和质量。此外,Sora 还对视频推送进行了重新分类,推出了「Best」和「Top」类别,以便用户更好地筛选内容。
亮点提要:
-
Sora 将推出图像生成功能,用户可快速切换视频与图像生成。
-
新的视频推送分类「Best」和「Top」将优化内容筛选。
-
Sora 的图像生成器代号为「papaya」,或将引入 DALL-E4。(@ AIbase 基地)
03 有态度的观点
1、OpenAI CEO 山姆·奥特曼发布对 AGI 的三项观察
2025 年 2 月 10 日,OpenAI 首席执行官山姆·奥特曼在其博客中发表文章《Three Observations》,分享了他对人工智能(AI)和通用人工智能(AGI)的三项观察。
奥特曼指出,AGI 是一种能够在多个领域以人类水平解决复杂问题的系统。他提出了以下三点观察:
-
AI 能力与资源投入的对数关系: AI模型的智能水平大致与用于训练和运行的资源总量的对数成正比。这些资源主要包括训练算力、数据和推理算力。通过持续投入资源,AI能力可以实现可预测的增长。
-
AI 使用成本的指数级下降: 使用 AI 的成本每 12 个月大约降低 10 倍。例如,从 2023 年初的 GPT-4 到 2024 年中的 GPT-4o,单词的价格下降了约 150 倍。这种成本下降速度远超摩尔定律。
-
AI 的社会经济价值呈超级指数增长: 随着智能水平的线性增长,AI 的社会经济价值呈超级指数增长。因此,未来几年内对 AI 的指数级投资没有理由停止。
奥特曼还提到,AI 代理(Agent)最终将像虚拟同事一样与人类协作,例如软件工程 Agent 可以完成大多数顶尖公司中有几年经验的工程师能够完成的任务。未来,这样的 Agent 可能会在各个工作领域普及。
尽管短期内(如 2025 年)人类的生活方式不会发生显著变化,但长期来看,AI 将带来不可忽视的变革。AGI 的影响将是不均衡的,科学进步的速度可能会大幅加快,而商品价格可能会大幅下降,稀缺资源的价格可能会显著上升。
奥特曼强调,确保 AGI 的益处能够广泛分布是至关重要的,这可能需要新的政策和理念来实现。到 2035 年,每个人都应该能够调动相当于 2025 年所有人智慧总和的能力,这将极大地释放人类的创造力,为社会带来巨大的福祉。(@量子位)
2、李飞飞:AI 政策必须基于「科学而不是科幻小说」
在即将于巴黎举行的 AI 行动峰会前夕,斯坦福大学计算机科学家李飞飞就 AI 政策制定发表了重要观点。李飞飞强调,AI 政策的制定必须建立在科学基础之上,而非科幻小说。 她指出,决策者应当关注 AI 的现实发展状况,避免陷入过于理想化或末日论的未来设想。特别是在理解当前的聊天机器人和 AI 助手程序时,需要明确认识到它们并不具备主观意图、自由意志或意识,这样才能使政策制定更加务实,聚焦于当前亟待解决的实际挑战。

在政策取向方面,李飞飞主张采取务实而非意识形态化的方针,既要防范可能出现的负面影响,又要为创新发展提供激励。同时,她特别强调了开放获取的重要性,认为政策制定应当为包括开源社区和学术界在内的整个 AI 生态系统赋能。她表示,如果限制对 AI 模型和计算工具的访问,将会阻碍创新发展,尤其会对资源相对匮乏的学术机构和研究人员造成不利影响。(@ APPSO)
04 有看点的活动
1、APPLE 生态爱好者集合,「LET’S VISION 2025」将在 3 月 1 日 -2 日上海开启

Apple 生态爱好者们,LET'S VISION 2025 大会即将回归,将于「 2025 年 3 月 1 日至 2 日」在「上海浦东鲜花港」举行。本次大会将聚焦技术前沿、创意实践、资源共享和未来展望,为参与者提供与行业领袖深入交流的机会。大会内容丰富,包括信号发射台、创意实操舱、共享空间站和未来展映台等环节,涵盖从技术趋势到商业模式的多角度探讨。
购票信息可通过关注小红书官方账号@XReality.Zone 或访问官网:https://letsvisionos.swiftgg.team/
工作坊预约对 BASIC、PRO、PREMIUM 用户开放,全程免费,但席位有限,建议尽早预约。更多嘉宾阵容及演讲专题内容将陆续公布,敬请期待。

更多 Voice Agent 学习笔记:
对话式 AI 硬件开发者都关心什么?低延迟语音、视觉理解、Always-on、端侧智能、低功耗……丨 RTE Meetup 回顾
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布
对话谷歌 Project Astra 研究主管:打造通用 AI 助理,主动视频交互和全双工对话是未来重点
这家语音 AI 公司新融资 2700 万美元,并预测了 2025 年语音技术趋势
语音即入口:AI 语音交互如何重塑下一代智能应用
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨Voice Agent 学习笔记
市场规模超 60 亿美元,语音如何改变对话式 AI?
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+客户
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻