引言
多智能体的架构演进过程:
第一阶段:B商城工单自动回复,LLM和RAG结合知识库应答,无法解决工具调用。
第二阶段:京东招商站,单一Agent处理知识库问答和工具调用,准确率低 & LLM模型幻觉,场景区分度差。
第三阶段:京麦智能助手,引入multi-agent架构,master + subagents协同工作模式,把问题分而治之,显著提升准确率。
商家助手的算法底座是基于大语言模型(LLM)构建的Multi-agent系统,模拟的是现实中电商商家团队的经营协作方式。商家只需使用他们最熟悉的自然语言,与京麦平台上的这个助手进行沟通,就可以获得7*24小时的经营代理服务。本文档将从模拟的现实商家经营空间映射到Multi-agent算法空间,逐步解析电商平台业务场景下商家助手的业务动机、算法技术架构以及关键技术。
商家助手Multi-agent是一个通用&开放的商家经营服务多种能力(比如销量预测,营销投放,定价,商机词推荐等)接入的宿主,可随着建设的不同阶段友好的面向其他能力提供方的Tools,包括Agent、API等形式。
Multi-Agent系统架构的设计动机来自于“Agent模拟的是现实世界的人的解决问题过程”的本质。首先介绍现实世界商家和他的团队是怎么经营的,以及他们和AI世界怎么进行角色映射。
QCon_京东商家智能助手.mp4
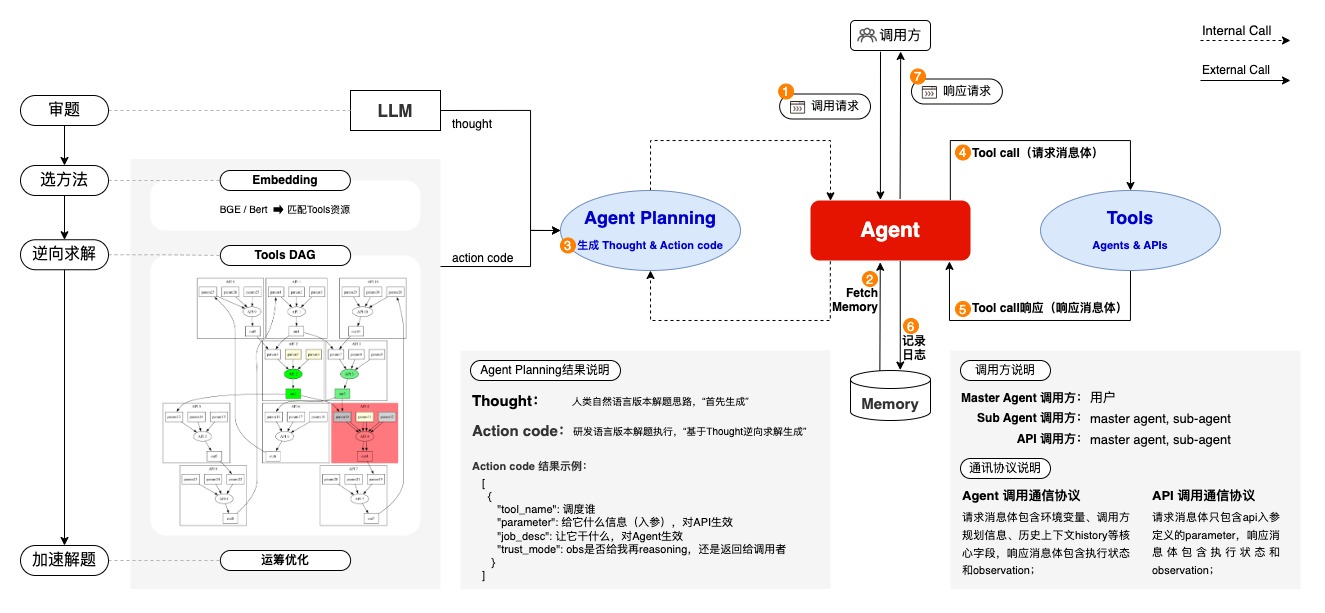
2、Multi-Agent Planning关键技术:
2.1 Agent构建技术:ReAct范式的多模型集成
1. Agent构建集成四类模型,实现了Agent大脑的智能化逆向规划能力:
2. ReAct规划动态更新
动态规划更新:在规划正向执行中,ReAct范式实现每一步根据执行结果的动态规划更新。
3.技术挑战和收益:
2.2 Multi-Agent Online Inference
2.2.1 技术特色
1. 任务分层动态规划与分布式协作:基于ReAct范式,通过Master Agent和Sub Agents在不同层级进行任务动态规划和动态调度,支持分布式协作。
2. Agent协作基于标准通信协议:
通过标准通信协议确保Muti-agent高效协同工作,支持多步联动和全局思维链规划。
2.2.2 Multi-Agent Online Inference 演示:
为了展示multi-agent的协同在线推理流程,录制了一个视频。结合京麦前台的助手产品形态,同步展示后台multi-agent的后台算法推理服务,方便大家理解。干货见以下视频:
H-MAP_4k.mp4
2.2.3 架构小结
特色:
推理难度低:将超大模型的全链路多步计划的生成任务,转化成next task prediction
成本低:多个小型模型的协同更容易落地,训练、部署成本低
迭代快:问题定位迅速,模型快速迭代
待解决:
响应时间长:面对复杂问题,用户更长的等待耗时,需要在产品上做引导
风险积累:多agents链式推理有错误累计风险。 解决方案研究中,如多智能体联合学习
多Agent架构与单Agent及LLM-MoE架构对比,多Agent架构在同等大模型能力下具有更强的稳定性,能更好支持复杂业务场景和任务的协作与扩展,但需要更多的工程开发量和更复杂的推理链路。
技术方案调研
2.3 Agent全链路ReAct评估技术
1.Agent全链路ReAct效能综合评估
2.多样化Reward Model
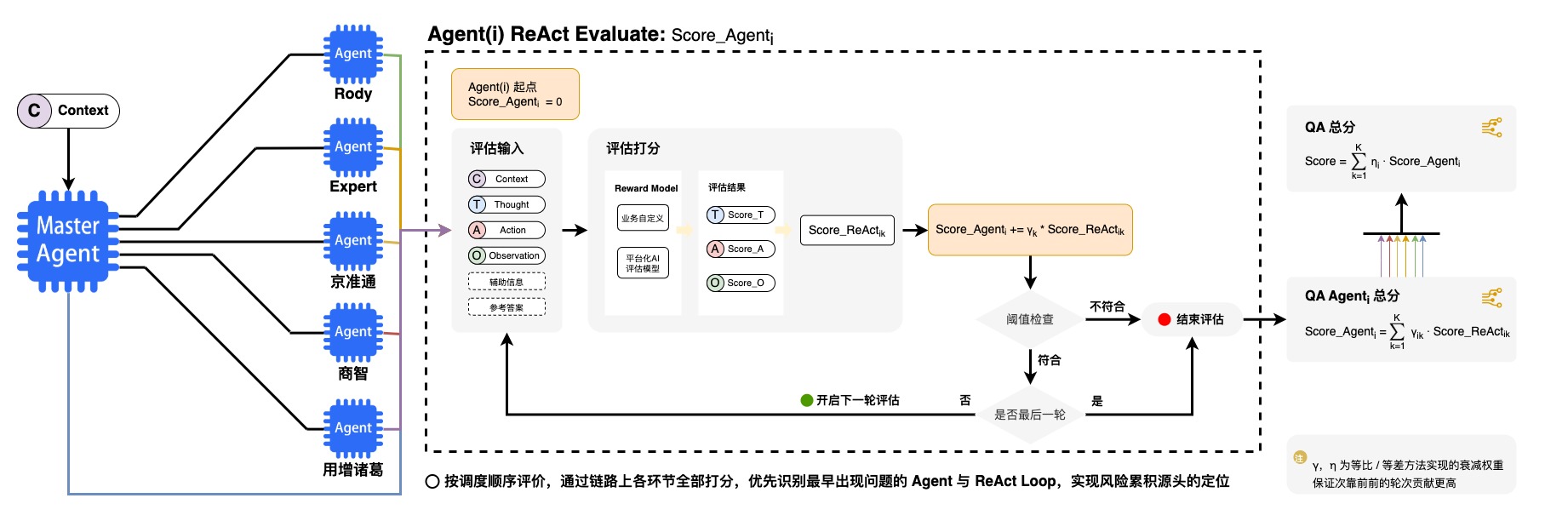
Reward Model-平台化AI评估模型案例说明:
输入总结模型的目标是针对用户历史的会话记录与本轮的提问分析其具体意图,作为Master Agent的思考的核心环节,需要对其意图总结效果进行评价。1、自动化评价方案:
1.评价方法:以高阶模型(例如:GPT-4o)作为裁判模型,结合用户当前轮次提问与历史的会话记录,对线上推理的准确性进行评价。
2.自动化评分指令(简化):
你是一个擅长问题意图理解的专家。现在需要你评估一个电商平台AI助手对于商家用户提问的意图理解质量,并要求你从以下维度对回答进行评估,评分为0-10分,分数必须是整数:1.正确性:意图是否正确表达出用户当前的问题;2.关联性:当前问题的意图可能和历史对话强关联,也可能无关,判断助手理解的意图是否正确关联历史对话。
我们会给你提供用户本轮提问、历史与AI助手的对话,和需要你评估的AI助手答案。有可能为你提供一个参考答案,当给出参考答案时,你需要判断AI助手总结的意图和给出的参考意图的相似度,该维度名为“和人工理解相似程度”。
按照以下字典格式(包括括号)返回你所有的打分结果:{{'维度一': 打分, '维度二': 打分, ..., '综合得分': 打分}}。例如:{{'正确性': 6, '关联性': 9, ..., '综合得分': 7}}。
输入数据格式如下:
用户本轮提问: {question}\n
[历史对话开始]\n{history_conv}\n[历史对话结束]
[参考意图开始]\n{reference}\n[参考意图结束]\n
[助手意图理解开始]\n{intention}\n[助手理解意图结束]\n2、待评估案例:
假设用户本轮提问、历史对话、助手意图理解分别如下:
1.用户本轮提问:
我这个是京东小店的
2.历史对话:
【顾客】:什么类目的标题可以不带品牌的名字
【客服】:都需要带上品牌的
3.助手意图理解:
说明店铺类型为某平台小店3、不同标注场景下的打分结果:
1.存在人工标注:此时人工标注即为指令中的“参考意图”
参考意图:
询问京东小店的商品标题是否需要带品牌名字
评分结果:1.正确性: 助手理解的意图并没有准确表达出用户当前的问题。用户当前的问题是询问京东小店的商品标题是否需要带品牌名字,而助手理解的意图只是说明了店铺类型为某平台小店,未能准确捕捉用户的真实意图。2.关联性: 助手理解的意图与历史对话没有正确关联。历史对话中用户询问的是商品标题是否需要带品牌名字,而助手理解的意图并未涉及这一点。3.和人工理解相似程度: 助手理解的意图与人工意图有明显差异。人工意图准确捕捉了用户的问题,而助手理解的意图只是说明了店铺类型,未能反映用户的真实需求。综合评价:助手理解的意图未能准确表达用户的真实意图,也未能正确关联历史对话,与人工意图差异较大,因此综合评分较低。综合来说:{{'正确性': 3, '关联性': 2, '和人工理解相似程度':2, '综合得分':2}}
2.不存在人工标注:此时指令中的“参考意图”为“无”
评分结果:1.正确性: 助手理解的意图与用户当前提问的主要内容不符。用户想了解的是京东小店的商品标题中是否需要说明品牌名称,助手理解的用户意图为说明自身为京东小店,意图理解错误。2.关联性: 助手理解的意图与历史对话未正确关联。在之前的会话中,用户询问的目的是商品标题携带品牌名的必要性,助手未理解该意图。综合评价:助手理解的意图在正确性和关联性上均有不足,因此综合评分较低。综合来说:{{'正确性': 3, '关联性': 2, '综合得分':3}}工具调度类模型需要针对用户提问、结合可用API的具体描述,进行API选择与相关的参数解析,因此需要对模型解析出的action code进行准确度评价。1、自动化评价方案:
1.评价方法:以高阶模型(例如:GPT-4o)作为裁判模型,结合用户提问、API资料库,对线上推理的准确性进行评价。
2.自动化评分指令(简化):
你是一个擅长评价API使用合理性的助手。现在需要你评估一个电商平台AI助手要解决商家用户提问时,所调用的API是否正确;如果正确选择了API,需要进一步判断对该API的参数解析是否正确。请注意:你只需要评价API选择以及参数解析的正确与否,不需要生成正确的调用方法。
我们会给你提供用户的提问、API,和需要你评估的AI助手答案。可能为你提供用户提问的对应参考答案,当存在参考答案时,准确性评价必须与参考答案对比得出;不存在参考答案时,仅需要根据助手答案自身展开评价。
按照以下字典格式(包括括号)返回你所有的评价结果:{{'API选择': 正确或错误, '参数解析': 当API选择错误时,结果为“无”;当API选择正确时,结果为正确或错误}}。例如:{{'API选择': '错误', '参数解析': '无'}};{{'API选择': '正确', '参数解析': '正确'}}。
输入数据格式如下:
用户本轮提问: {question}\n
[API信息开始]\n{retrivals}\n[API信息结束]\n
[参考解析结果开始]\n{reference}\n[参考解析结果结束]\n
[助手解析结果开始]\n{answer}\n[助手解析结果结束]\n 2、待评估案例:
假设用户本轮提问、API信息、助手解析结果分别如下:
1.用户本轮提问:
我有多少订单是王萍萍买的?
2.API信息:
【1】{"name": "check_shop_qualifications","description": "当用户提出有关经营过程中资质要求(如上传材料、营业执照、行业资质等)相关的问题时,需要调用此工具查询具体资质要求的相关信息,然后根据查询到的信息回答用户问题。","parameters": {"type": "object","properties": {"keyword": {"description": "用户经营的主要类目、商品类型或者商品品牌,例如:洋酒、玩具、阿迪达斯等。如果没有提供该类信息,必须反问用户要求其提供"},"shop_body": {"description": "店铺主体,只能是以下三种:企业、个人和个体工商。"},"shop_type": {"description": "店铺类型,只能是以下六种:旗舰店、专卖店、专营店、卖场店、普通企业店和小店。"}},"required": ["keyword"]}
}
【2】{"name": "search_order_code","description": "该工具用于根据用户提供的信息(如订单编号、下单时间、下单账号等)查询订单的详细信息,包括商品详情与订单详情。","parameters": {"type": "object","properties": {"order_id": {"description": "订单编号:12位纯数字,用于记录订单的唯一标识"},"consumer_name": {"description": "客户姓名:用户姓名、买家姓名、收件人、收货人、顾客、客户等"},"user_pin": {"description": "下单账号:下单账户、买家pin,买家、顾客、用户等,通常由客户姓名+数字或纯英文组成"},"sku_id": {"description": "商品编号:14位纯数字信息,"},"sku_name": {"description": "商品名称:商品信息的描述,可能携带品牌信息或商品具体属性"},"consumer_mobile_phone": {"description": "客户电话:用户手机号码,11位纯数字信息,可能会以区号+86,400等开头。"},"search_keys": {"description": "用户希望查询的目标,枚举值只能从[商品、订单]中选择。若用户希望查询的是订单中的商品id、商品名称、商品详情等,枚举值为商品;若用户希望查询的目标是订单编号、订单数量等,枚举值为订单。"}},"required": []}
}
3.助手解析结果:
{"action_code": {"api_name": "search_order_code","parameter": {"consumer_name": ["王萍萍"],"search_keys": ["商品"]},}
}3、不同标注场景下的打分结果:
1.存在人工标注:此时人工标注即为指令中的“参考解析结果”
参考解析结果:
{"action_code": {"api_name": "search_order_code","parameter": {"consumer_name": ["王萍萍"],"search_keys": ["订单"]},}
}
评分结果:1.API选择:AI助手的答案中选择调用search_order_code,与参考答案一致,API调用正确。2.参数解析:AI助手的答案中search_keys为商品,但参考答案中search_keys为订单,因此参数解析错误。综合来说:{{'API选择': '正确', '参数解析': '错误'}}
2.不存在人工标注:此时指令中的“参考答案”为“无”
评分结果:1.API选择:用户希望查询顾客王萍萍的订单,AI助手的答案中选择调用search_order_code,该工具可以进行订单详情查询,因此API调用正确。2.参数解析:API助手解析的参数中,查询目标为商品,但用户希望查询的内容是订单,因此参数解析结果与用户提问意图不符,解析错误。综合来说:{{'API选择': '正确', '参数解析': '错误'}}输出总结模型需要针对用户提问与召回的语料进行总结回答,因此需要对模型最终的总结效果进行评价。1、自动化评价方案:
1.评价方法:以高阶模型(例如:GPT-4o)作为裁判模型,结合用户提问与召回的语料得到线上推理的回答评分。针对有人工标注和无人工标注两种情况,构造出一套通用的打分指令,兼容不同场景。
2.自动化评分指令(简化):
你是一个擅长评价文本质量的助手。现在需要你评估一个电商平台AI助手对于商家用户提问的回答的质量,并要求你从以下维度对回答进行评估,评分为0-10分,分数必须是整数:1.满足用户需求:回答内容是否解决用户提问;2.事实正确性:回答是否从参考语料中得到,不允许过度推断得到的回答;3.回答完备性:仅针对要回答的问题,是否完整地提取了语料中的全部信息。
我们会给你提供用户的提问、需参考的核心语料,和需要你评估的AI助手答案。可能为你提供用户提问的对应参考答案,当存在参考答案时,评分需要对比参考答案得出;不存在参考答案时,仅需要根据助手答案自身展开评价。
按照以下字典格式(包括括号)返回你所有的打分结果:{{'维度一': 打分, '维度二': 打分, ..., '综合得分': 打分}}。例如:{{'满足用户需求': 6, '事实正确性': 9, ..., '综合得分': 7}}。
输入数据格式如下:
用户本轮提问: {question}\n
[核心语料开始]\n{retrivals}\n[核心语料结束]\n
[参考总结结果开始]\n{reference}\n[参考总结结果结束]\n
[助手总结结果开始]\n{answer}\n[助手总结结果结束]\n 2、待评估案例:
假设用户本轮提问、核心语料、助手总结结果分别如下:
1.用户本轮提问:
偏远地区发出了又不要了,运费谁承担
2.核心语料:
【1】[售后-交易纠纷] 京东开放平台运费问题纠纷处理标准链接:https://rule.jd.com/rule/ruleDetail.action?ruleId=3727&type=0&btype=1
【2】[售后-交易纠纷] 当买卖双方根据运费发生纠纷时,京东根据“谁过错,谁承担”的原则处理,但买卖双方协商一致的除外。
【3】[售后-交易纠纷] 《运费问题的纠纷处理规则》判定运费纠纷责任:第十条 若买卖双方就如上运费问题产生纠纷,申请京东介入的,京东将根据本标准内容进行判定,如商家违反运费要求或举证内容无效,将判定商家责任。
3.助手总结结果:
当买卖双方根据运费发生纠纷时,京东根据“谁过错,谁承担”的原则处理,但买卖双方协商一致的除外。具体处理标准您可参考以下链接:[京东开放平台运费问题纠纷处理标准链接](https://rule.jd.com/rule/ruleDetail.action?ruleId=3727&type=0&btype=1)3、不同标注场景下的打分结果:
1.存在人工标注:此时人工标注即为指令中的“参考总结结果”
参考总结结果:
京东根据“谁过错,谁承担”的原则处理,但买卖双方协商一致的除外:若消费者无正当理由拒绝签收,发货运费由消费者承担;消费者有理由拒绝签收(商品有质量问题、少货等),发货运费由商家承担。\n详细内容请参考[京东开放平台运费问题纠纷处理标准链接](https://rule.jd.com/rule/ruleDetail.action?ruleId=3727&type=0&btype=1)
评分结果:1. 满足用户需求:AI助手的答案部分解决了用户的提问,提到了“谁过错,谁承担”的原则,但没有具体说明在偏远地区发货后又不要了的情况下,运费由谁承担。相比之下,参考答案更详细地解释了不同情况下的运费承担方。因此,AI助手的回答在满足用户需求方面不够全面。2. 事实正确性:AI助手的答案内容来自核心语料,引用了“谁过错,谁承担”的原则,并提供了相关链接。这部分内容是准确的。3. 回答完备性:AI助手的答案没有完全提取核心语料中的全部信息,尤其是缺少了关于消费者无正当理由拒绝签收和有理由拒绝签收的具体情况的解释。相比之下,参考答案更为详细和完备。综合评价:AI助手的回答在事实正确性方面表现良好,但在满足用户需求和回答完备性方面有所欠缺。总体来说,回答质量中等。综合评分如下:{{'满足用户需求': 5, '事实正确性': 10, '回答完备性': 4, '综合得分': 6}}
2.不存在人工标注:此时指令中的“参考答案”为“无”
评分结果:1. 满足用户需求:AI助手的答案部分解决了用户的提问。用户询问的是偏远地区发货后又取消订单的情况下运费由谁承担,AI助手回答了京东处理运费纠纷的原则是“谁过错,谁承担”,并提供了一个链接供用户参考。然而,AI助手没有明确回答在偏远地区发货后取消订单的具体情况,是否由买家或卖家承担运费。因此,AI助手的回答不完全满足用户需求。2. 事实正确性:AI助手的答案是从核心语料中提取的,引用了“谁过错,谁承担”的原则,并提供了相关链接。这些信息都准确无误,符合核心语料的内容。3. 回答完备性:AI助手的回答虽然引用了核心语料中的信息,但没有完全提取所有相关信息。例如,核心语料中提到的“买卖双方协商一致的除外”以及“京东将根据本标准内容进行判定,如商家违反运费要求或举证内容无效,将判定商家责任”这些内容没有被提及。这些信息对于用户理解运费纠纷的处理方式是有帮助的。综合评价:AI助手的回答在事实正确性方面表现良好,但在满足用户需求和回答完备性方面还有提升空间。总体来说,回答质量中等。综合评分如下:{{'满足用户需求': 6, '事实正确性': 10, '回答完备性': 6, '综合得分': 7}}
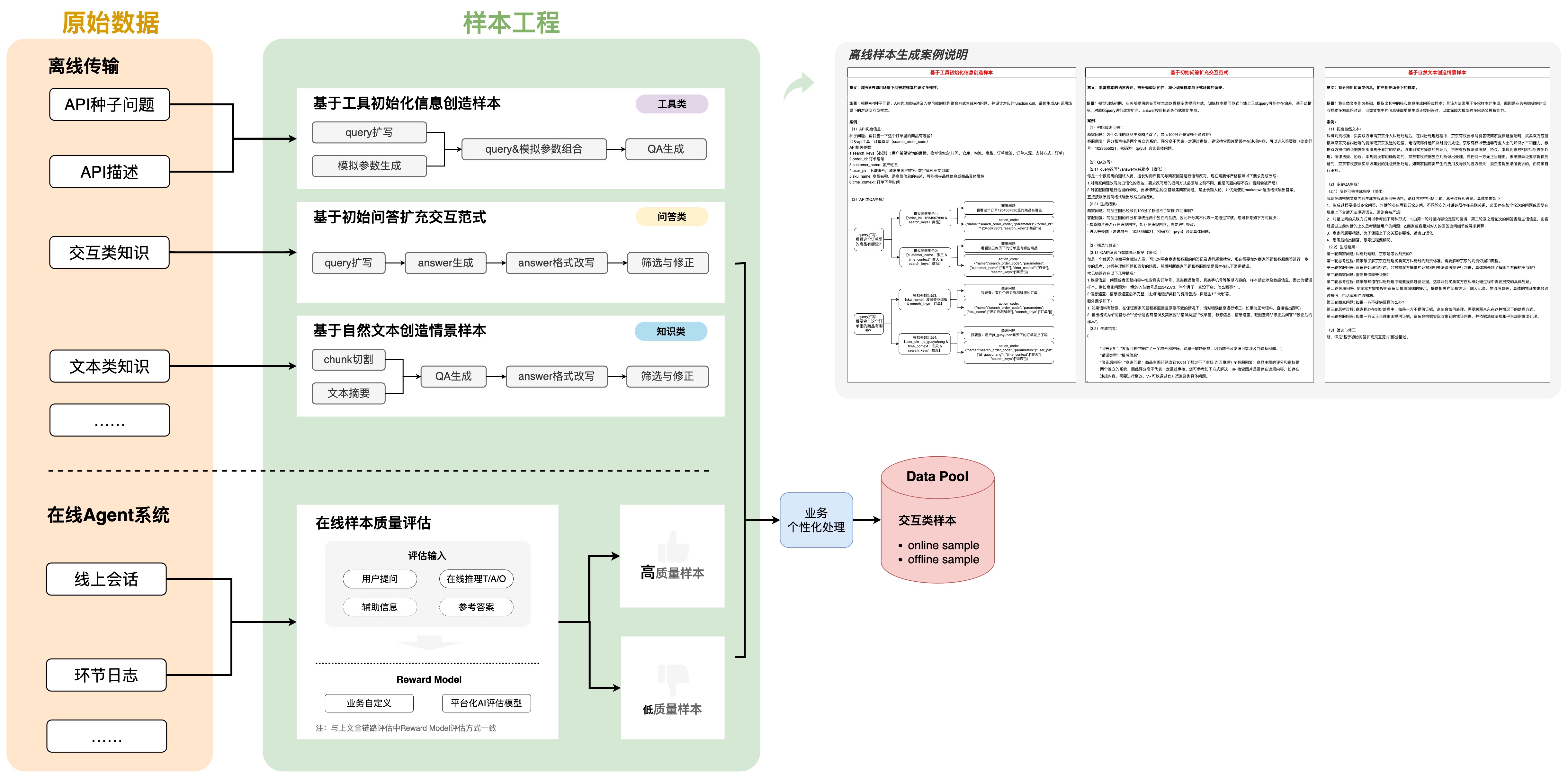
2.4 LLM离在线样本增强技术
1. 自动化离线样本生成与扩展
2. 自动化在线推理标注与样本积累
=============
References
H-MAP planning:Multi-Agent通信协议
Step 1. 调用方发起调用请求。Master Agent的调用方只能是用户,领域Agent的调用方可以是Master Agent或其他领域Agent。请求的消息内容和格式见4.2中的请求消息体。Step 2. Agent进行Planning/Reasoning。Agent应用接收到消息请求后,调用内部的Memory管理系统获取会话历史信息;Step 3.Reasoning,即生成Thought和Action Code; Thought和Action Code具体含义如下:thought:text. 是指用人类自然语言形式表达的解题决策过程,即任务的大目标和解决问题需要执行的tasks的文字描述。比如:这是一个xxx问题,可以通过先xxx、再xxx来解决。action_code:list of tasks. 是根据thought生成可供应用系统进行调度执行的研发语言,即tasks的结构化描述,支持包含多个tasks的list结构,通常使用采用一个task(即执行完一个拿到observation再执行下一个)。一个task包含4个核心要素:(1)tool_name: 调度对象唯一标识,领域agent或者待调用的api的注册名称"name";(2)parameter:工具调用所需要传递的参数;(3)job_desc:调用工具的任务描述,即需要工具来干什么,只对调用Agent生效,api通常只会使用parameters;(4)trust_mode:对tool调用完成后,tool输出observation的处理方式,1代表agent不基于observation进行下一轮ReAct、直接进入下一个task(通常出现在len(list of tasks) > 1),0表示需要基于observation更新ReAct。Step 4. Agent执行工具调用Tools call。应用解析 Thought和Action code生成请求消息体。如果Action code中包含工具调用,则执行,否则跳过此步。如果要调用的tool是Agent,调用时传递的请求消息体同上面1;如果要调用的工具是API,调用时传递的请求消息体见“4.3 API调用协议”中的请求消息体。Step 5. 被调用工具返回结果。若在上一步没有执行工具调用,则跳过此步。工具调用执行完成后,需要把执行结果返回给调用方。如果被调用的工具是Agent,那么需要返回的关键信息包含调用状态status和结果Observation;如果被调用的工具是API,那么需要返回的关键信息包含调用状态status、observation,具体消息内容和格式见“4.3 API调用协议”中的响应消息体。Step 6. Agent本轮ReAct信息写入Memory,并同步计入日志系统 。Agent完成一轮ReAct后必须把内部reasoning生成的如Thought、Action code、tools call、出入参、调用时间等关键信息通过日志接口写入助手日志系统。见4.4日志系统接口。Step 7. Agent响应调用请求。Agent在完成step 2-6后,根据step 2生成的trust mode,判定是否向调用方返回响应结果。若trust mode值为1,则可以把observation返回给调用方,具体响应消息内容和格式见4.2的响应消息体;若rust mode值为0,则继续进行下一轮ReAct,重复 step 2-6。