· 连续学习是指智能系统能够在其生命周期内逐步获取、更新、积累和利用知识的能力。
· 主要挑战是灾难性遗忘,即学习新任务时旧任务性能急剧下降。
· CL 的目标包括平衡稳定性和可塑性、任务内与任务间的泛化能力以及资源效率。
2.2节对连续学习不同的种类进行了分类
包括不同任务相同的分布和不同的分布,是否拥有相同的标签。
对于连续联邦推荐系统,重点可能是第一个分类:IIL:
Instance-Incremental Learning (IIL): All training sam ples belong to the same task and arrive in batches.
2.3是对连续学习进行评估:
目前所学习任务的整体表现、旧任务的记忆稳定性和新任务的学习可塑性。这些评估指标公式是基于分类任务,(对于推荐任务是否需要重新设计评估指标)。
总体表现(overall performance)——average accuracy(AA),average incremental accuracy(AIA)
AA和AIA计算的是每次训练到第K个任务后,对前K个任务中任意的第j个任务准确率的评估。

记忆稳定性——forgetting measure(FM),backward transfer(BWT)
fj,k : 对于第j个任务来说,从学习第一个任务到当前第k个任务期间,其最大性能(即过去最好的测试准确率)与当前性能的差值:
平均遗忘量 FMk:
后向迁移(BWT, Backward Transfer)
后向迁移表示学习新任务对旧任务的平均影响:

学习可塑性——instransience measure(IM),forward transfer(FWT)

不适应性测量(IM, Intransience Measure) 和 前向迁移(FWT, Forward Transfer) 两种指标来衡量.
IM不适应性描述了模型在增量学习中无法有效学习新任务的程度。
●ak∗ :第 kkk 个任务在联合训练(joint training)下的分类准确率(使用所有任务数据 训练的随机初始化参考模型)。
●ak:模型在连续学习(continual learning)中完成第 k个任务后的分类准确率。
含义:
●IM_k越小,说明模型对新任务的学习能力越强。
●高IM_k值可能表明灾难性遗忘或新任务适应困难。
FWT前向迁移评估旧任务对当前任务学习的正面影响。
公式:
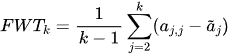
:在连续学习中完成第j个任务后的准确率。
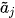 :第j个任务在单独训练(仅用 Dj数据训练的随机初始化参考模型)下的分类准确率。
:第j个任务在单独训练(仅用 Dj数据训练的随机初始化参考模型)下的分类准确率。
含义:
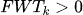 :表明旧任务对新任务的学习有正向帮助(知识迁移)。
:表明旧任务对新任务的学习有正向帮助(知识迁移)。
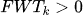 :表明旧任务干扰了新任务的学习(负迁移)。
:表明旧任务干扰了新任务的学习(负迁移)。
3节介绍关于稳定性-可塑性权衡和普遍性分析的持续学习的理论基础,并将它们与各种持续学习方法的动机联系起来。对于连续联邦推荐的动机应该可以用这里面使用到的理论依据。(都有Non-IID的推导),
对于CL需要设计出一个增量任务的训练集,假设它们的测试集遵循相似的分布,并且候选解决方案具有相似的通用性。
1.推荐任务的增量如何设计2.是否要有相同的分布
一个理想的持续学习解决方案应该提供适当的稳定性-可塑性权衡和适当的任务内/任务间的普遍性
CL中使用的方法有:
一、正则化方法:
1)权重正则化
通过正则化项限制网络参数的变化,根据参数对旧任务的重要性,防止遗忘。
2)功能正则化
函数正则化,针对预测函数的中间或最终输出。这种策略通常采用以前学习过的模型作为老师,当前训练过的模型作为学生,同时实施知识蒸馏(Knowledge Distallation,KD)以减轻灾难性遗忘。理想情况下,知识蒸馏的目标应该是所有旧的训练样本,而这些样本在持续学习中是不可用的。
二、回放方法:
1)经验回放
通过保存部分旧任务样本在内存缓冲区中,结合新任务样本进行训练,从而缓解灾难性遗忘。
2)生成回放
通常需要训练一个额外的生成模型来重放生成的数据。用于生成重放的生成模型有多种类型,如生成对抗网络(GAN)和变分自动编码器(VAE)等。
3)特征回放(Feature Replay)
· 特征蒸馏:在新旧模型间执行特征蒸馏以对齐表示(如 GFR 和 DSR)。
· 统计恢复:存储旧特征的统计信息(如均值、协方差),并基于经验回放恢复特征分布(如 IL2M 和 SNCL)。
· 固定特征提取器:
·REMIND 和 ACAE-REMIND 固定特征提取器的早期层,减少更新对旧特征的干扰。
·FeTrIL 在初始任务中学习固定的特征提取器,随后仅回放生成的特征。
挑战:表征漂移(Representation Shift):特征提取器在连续更新中可能发生变化,导致特征遗忘。
三、优化方法
这个都会和经验回放相结合
1)梯度投影
结合正交空间、经验回放
通过约束当前任务的梯度更新,使其与旧任务的梯度或输入空间保持特定关系,避免遗忘。
GEM 和 A-GEM:将参数更新限制在不增加旧任务损失的方向。
2)元学习(Meta-Learning)
MER利用元学习对经验回放样本的梯度进行对齐。
3)损失景观优化(Loss Landscape Optimization)
从优化过程的全局特性出发,改进模型在损失平面的收敛特性,寻求稳定性和泛化能力的最佳结合。
四、表示方法
重点在于创建和利用鲁棒的表征,以应对灾难性遗忘,同时提高任务间的知识迁移和泛化能力。
1)自监督学习(Self-Supervised Learning)
概念:通过对比损失等自监督技术训练模型表征,这些表征对灾难性遗忘具有更强的鲁棒性。(这个很像跨域学习的方式,跨域小样本学习)
2)预训练(Pre-Training)
3)连续预训练与元训练
(Continual Pre-Training and Meta-Training, CPT)在增量收集的大规模数据上执行上游连续学习,以改进下游任务性能。
五、架构方法
上述策略基本上都是通过共享一组参数(即单一模型和单一参数空间)来学习所有增量心理任务,这是造成任务间干扰的主要原因。相比之下,构建特定任务参数可以明确解决这一问题。以往的研究通常根据网络架构是否固定,将其分为参数隔离和动态架构两类。重点放在特定任务参数的实现方式上,并将上述概念扩展到参数分配、模型分解和模块化网络。
重点通过构建任务特定的参数或自适应架构
参数分配的特点是在整个网络中为每个任务专用一个独立的参数子空间,该架构的大小可以是固定的,也可以是动态的;
模型分解将模型明确分为任务共享组件和任务特定组件,其中任务特定组件通常是可扩展的;
模块化网络利用并行子网络或子模块,以差异化方式学习增量任务,而无需预先定义任务共享或特定任务组件