1. 前言
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
2. 正文
2.1
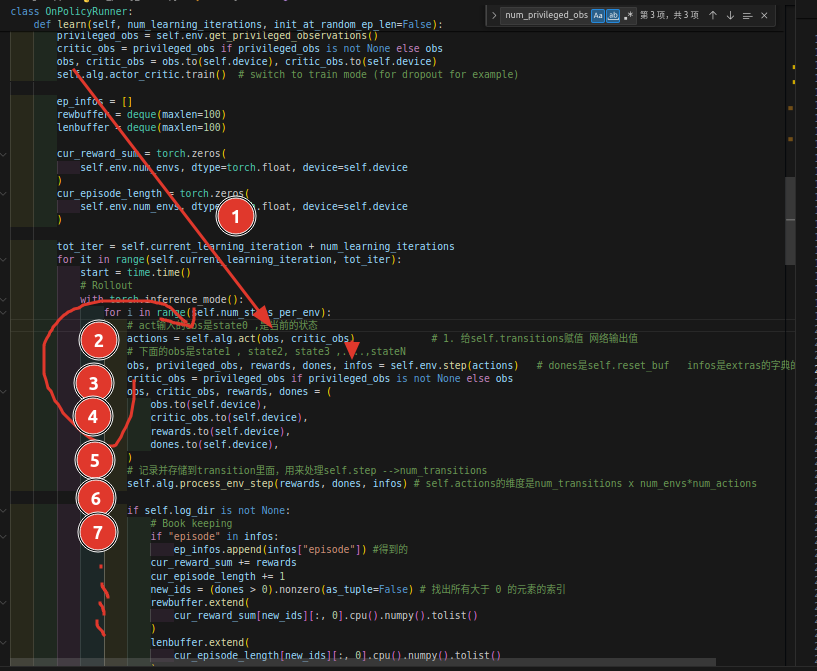
在on_policy_runner.py文件夹下,初始化的地方:
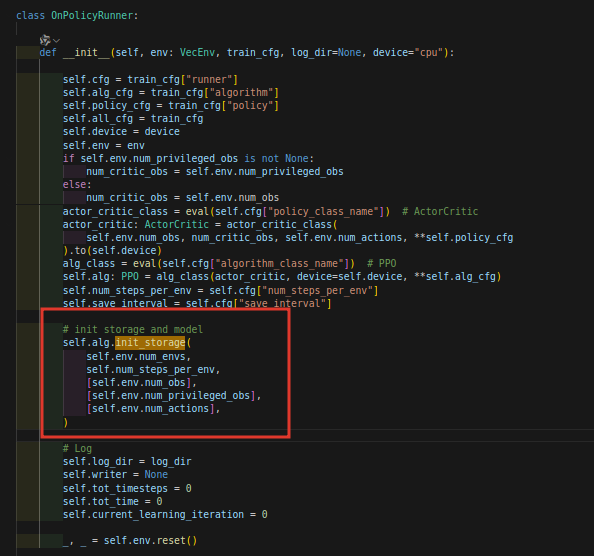
然后我们寻找定义的地方,在ppo.py文件夹下:
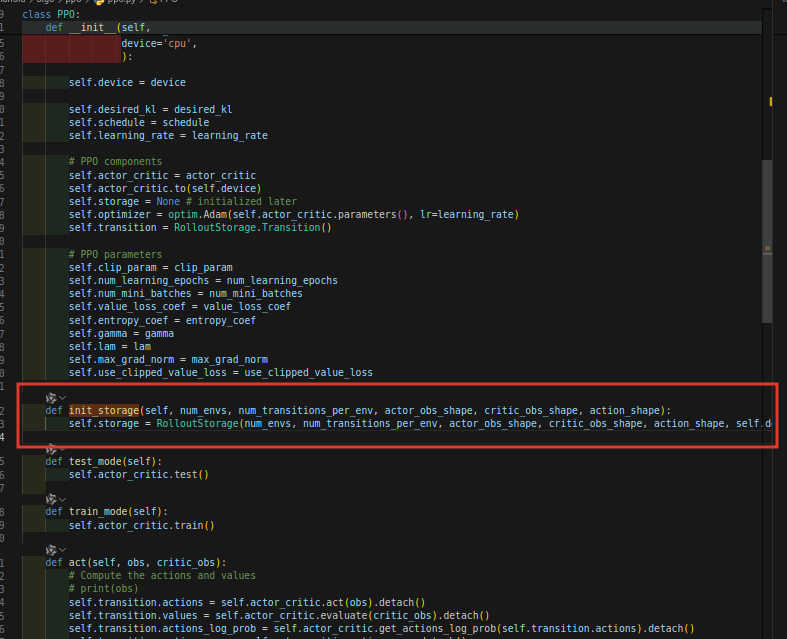
其中参数num_transitions_per_env其实是self.num-steps-per-env,这个量其实就是:self.num_steps_per_env = self.cfg["num_steps_per_env"],也就是config文件: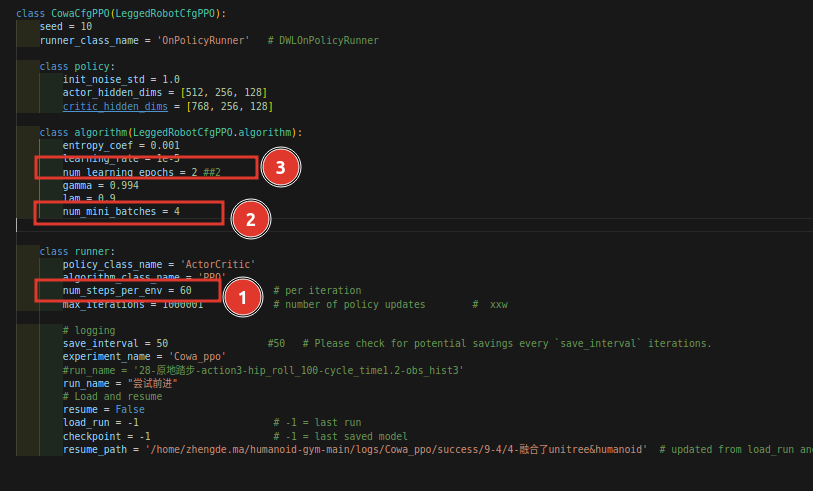 中圈1的部分,我们记住是60
中圈1的部分,我们记住是60
2.1
进入RolloutStorage的类里面,这个类在rollout_storage.py文件夹下,是我们今天的关注点。
我们找到mini_batch_generator这个函数:
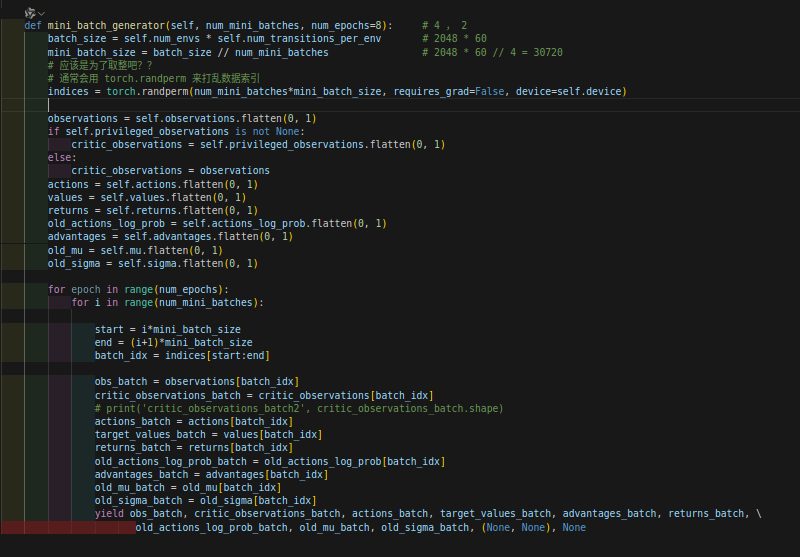
我们注意到里面的observation.flatten(0,1),我们看一下observation的维度:
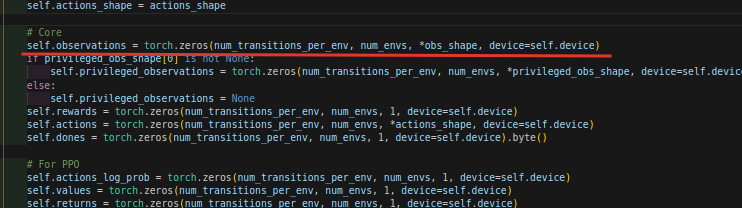
维度是:60X2048Xnum_obs
经过.flatten(0, 1)变成了:122880Xnum_obs
2.1
循环里面:
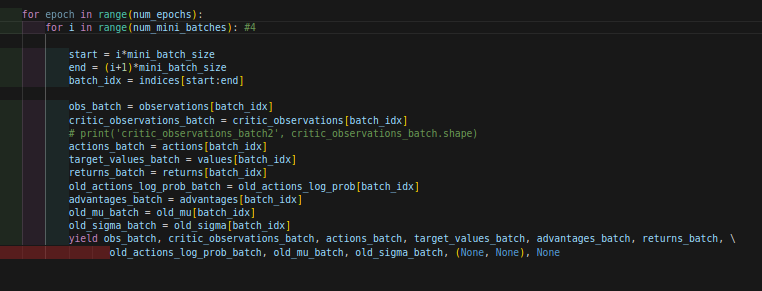
我来解释一下:这里是将每一个env(比方说2048个环境)的transition(比方说一个env有60个transition)全部都混到一起去,总共有2048x60=122880个transtion,这就是一个batch,顺序全部打乱,所以一个batch_size就是122880,然后按照mini_batch-size(比方和说是4),分为4个小batch,每个batch是122880//4=30720 ,按照030720,3072061440,6144092160,92160122880的进度取这个大batch,当然顺序是打乱的,
2.1
然后我们看这个是在哪里调用的:我们来到ppo.py文件下,发现generator是从刚才的mini_batch_generator函数得来的。
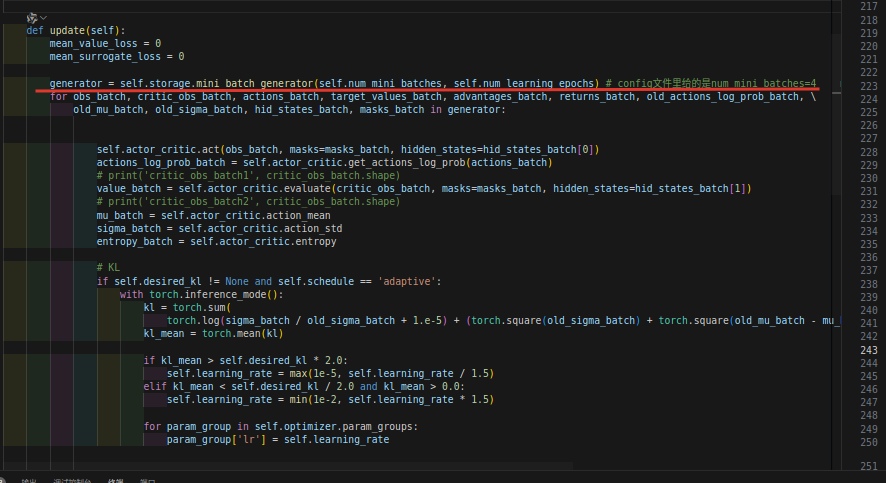
这里的generator是随即采样的结果,里面包含很多的值:你看,有这么多:

2.1
然后value_batch就是从self.actor_critic.evaluate函数里返回,这个函数在actor_critic.py文件下:
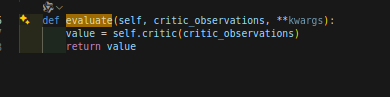
输入是随即batch的观测值,经过神经网络输出value_batch
2.1
再看compute_returns函数:位于rollout_stotage.py文件里面:
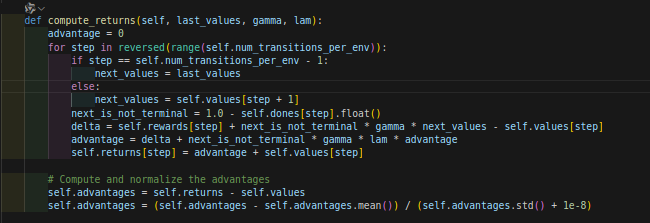
2.1
actor网络输出的actions是一个distribution,有均值和方差的。
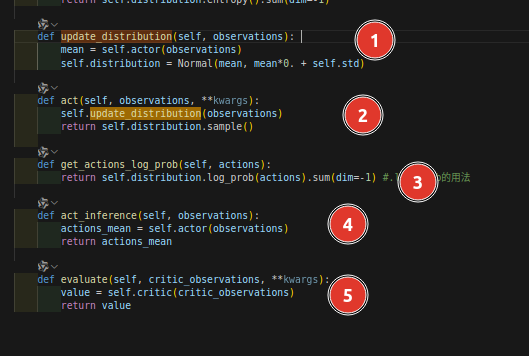
见我下面的注释内容:
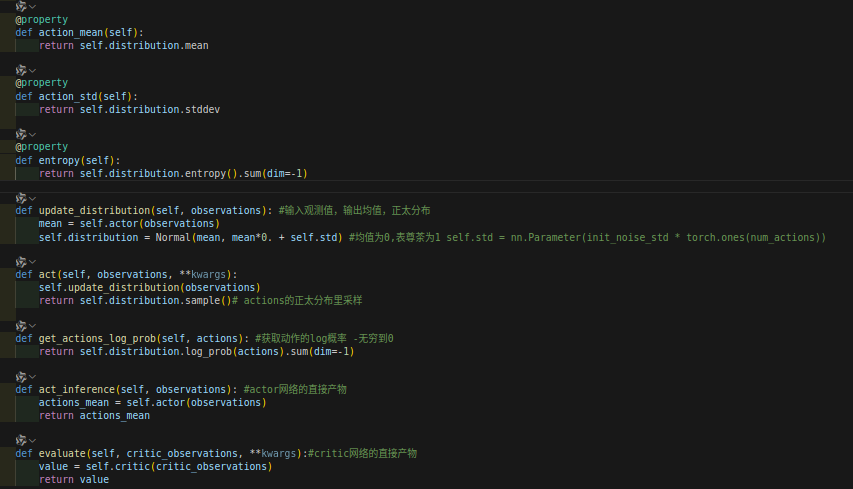
2.1
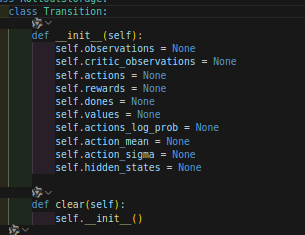
transition含有的值:
里面就rewards和dones没办法直接获得,所以除了这两个值其他都得到了。。。
2.1
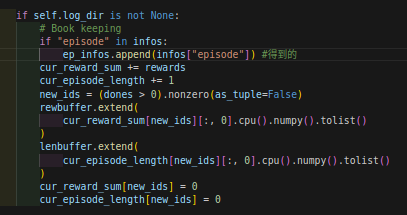
计算,直到infos['time_outs']=True,

下面是infos变量,也就是extras的值,

下面就用到了:
2.1
注意obs不是一个!!!!
2.1
2.1
2.1
2.1
2.1
2.1
3. 后记
这篇博客暂时记录到这里,日后我会继续补充。