一、安装部署核心内容包的结构
部署核心内容包包含了对操作系统的优化、中间件的安装配置和子平台的安装配置等类型。
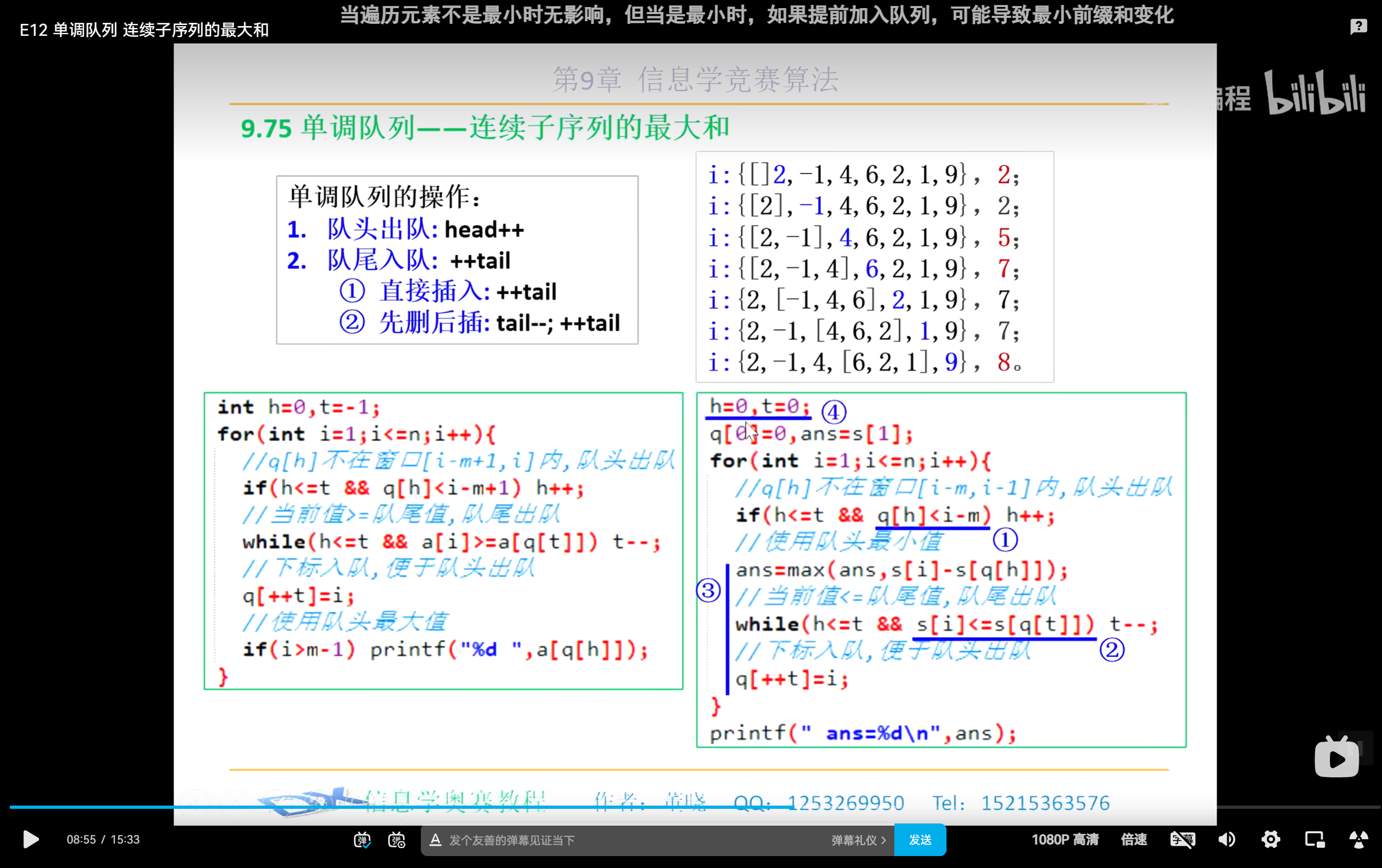
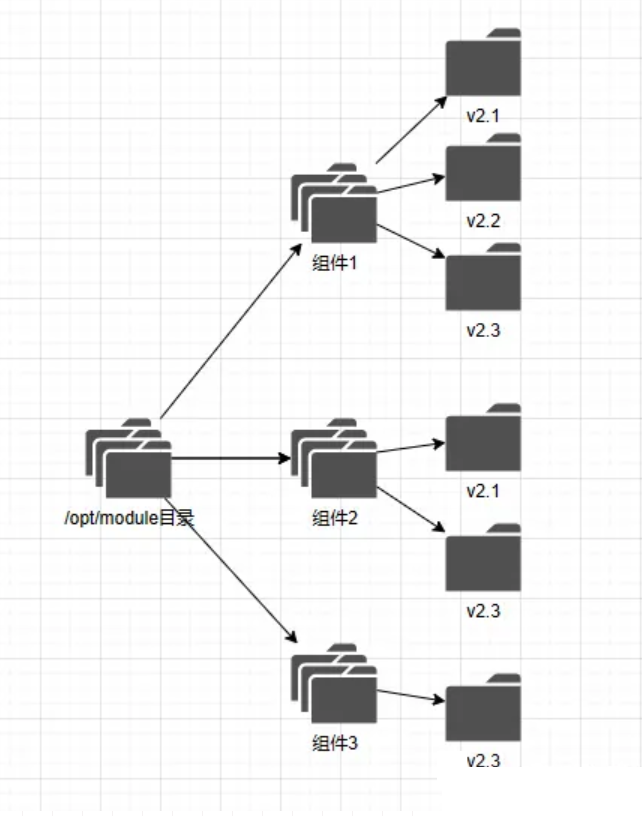
1.1 现有交互式部署工具V1的小组件部署结构
目前的交互式部署工具V1进行细化的部署工作,V1工具为每个组件定义了完整的部署逻辑,同时V1工具也为每一个可变参数,sql都定义了执行流。
一键化部署工具V2会根据授权信息中的授权的大业务组件,对需要的小组件进行安装和校验,如果用户在外部没有为组件定义缺省参数,则各组件会依照原有自动化部署中的默认参数进行配置和部署。
下面是小组件的结构
config存放各类可能存在变化的配置文件nginx配置java启动配置文件kafka topic 初始化配置
sqls按版本或分组形成的sql清单
services服务化启动脚本
下面是知识库子平台安装时利用这套规则引擎的配置例子:
name: 'knowledge'
version: '0.0.1'
folder_name: 'knowledge_0.0.1'
check_own_run_sh: '[ -d "/opt/module/knowledge_0.0.1" ] && echo "路径存在" || echo "路径不存在"'
run_sh: 'systemctl start knowledge'
config_sh: 'cat /opt/module/knowledge_0.0.1/application-knowledge.yml'
re_config_sh: 'cd /opt/module/knowledge_0.0.1/package && tar -zxvf dist.tar.gz'
dependences:- name: jdk17- name: pgsql
services_params:- service_name: knowledge.servicedescription: 知识库系统params:- conf_name: jar的名字(去除-SNAPSHOT.jar,只保留组件名和版本)param_name: jar_nameparam_default_value: public_knowledge_admin-1.0
update_sqls:sqls:- code: 1name: 初始化函数file: init_func.sql- code: 2name: 建表sqlfile: create_table.sql- code: 3name: 导入的数据 - 知识库基础file: preview_public_app_knowledge_hole_base_info.sql- code: 4name: 导入的数据 - cnnvd数据file: preview_public_app_knowledge_hole_cnnvd.sql- code: 5name: 导入的数据 - cnvd数据file: preview_public_app_knowledge_hole_cnvd.sql- code: 6name: 导入的数据 - cve数据file: preview_public_app_knowledge_hole_cve.sql
config_params:- file_name: knowledge-nginx.conftarget_folder: /opt/module/nginx/conf.dparams:- code: 1name: webqianduan_portdescription: webqianduan_portdefault: 18080- code: 2name: webhouduan_ipdescription: webhouduan_ipdefault: 127.0.0.1- code: 3name: webhouduan_portdescription: webhouduan_portdefault: 35001- code: 4name: authapi_ipdescription: 网关ipdefault: 127.0.0.1- code: 5name: authapi_portdescription: 网关端口default: 21001- code: 6name: pathdescription: 前端资源地址default: /opt/module/knowledge_0.0.1/package/dist- file_name: application-knowledge.ymltarget_folder: /opt/module/knowledge_0.0.1params:- code: 1name: server_portdescription: server_portdefault: 35001- code: 2name: pgsql_ipdescription: pgsql_ipdefault: 127.0.0.1- code: 3name: pgsql_portdescription: pgsql_portdefault: 5432- code: 4name: pgsql_dbdescription: pgsql_dbdefault: postgres- code: 5name: pgsql_schemadescription: pgsql_schemadefault: public- code: 6name: redis_ipdescription: redis_ipdefault: 127.0.0.1- code: 7name: redis_pwddescription: redis_pwddefault: ********- code: 8name: eureka_ipdescription: eureka_ipdefault: 127.0.0.1- code: 9name: minio_ipdescription: minio_ipdefault: 127.0.0.1- code: 11name: redirect_ipdescription: redirect_ipdefault: 127.0.0.1- code: 12name: gateway_ipdescription: gateway_ipdefault: 127.0.0.1 - code: 13name: pgsql_userdescription: pgsql_userdefault: postgres- code: 14name: pgsql_pwddescription: pgsql_pwddefault: ********
这一套规则引擎用于自动化部署、配置和升级 组件,涵盖 操作系统优化、中间件安装配置、子平台安装配置 三类内容。
规则的核心是基于 YAML 配置,定义了 组件安装、依赖管理、参数配置、数据库更新、服务管理 等内容,能够适应不同类型的组件部署需求。
1.2 规则解析
1、基础信息
name: 'knowledge'
version: '0.0.1'
folder_name: 'knowledge_0.0.1'
name:组件名称(如 knowledge)。
version:组件版本(如 0.0.1)。
folder_name:安装路径(如 /opt/module/knowledge_0.0.1)。
2、运行检测与执行命令
check_own_run_sh: [ -d "/opt/module/knowledge_0.0.1" ] && echo "路径存在" || echo "路径不存在"
run_sh: systemctl start knowledge
config_sh: cat /opt/module/knowledge_0.0.1/application-knowledge.yml
re_config_sh: cd /opt/module/knowledge_0.0.1/package && tar -zxvf dist.tar.gz
check_own_run_sh:用于 检测 组件是否已安装。
run_sh:用于 启动 组件(例如 systemctl start knowledge)。
config_sh:用于 查看配置(读取 application-knowledge.yml)。
re_config_sh:用于 重新配置 (解压 dist.tar.gz 进行更新)。
3、组件依赖
dependences:- name: jdk17- name: pgsql
声明当前组件依赖的其他组件,如:依赖 jdk17(Java 运行环境)。依赖 pgsql(PostgreSQL 数据库)。
在部署前,需要检查这些依赖是否已经安装。
4、服务参数
services_params:- service_name: knowledge.servicedescription: 知识库系统params:- conf_name: jar的名字(去除-SNAPSHOT.jar,只保留组件名和版本)param_name: jar_nameparam_default_value: public_knowledge_admin-1.0
service_name:服务名称(如 knowledge.service)。
description:服务描述(如 知识库系统)。
params:配置该服务需要的
核心参数。jar_name:JAR 包名称(去除 -SNAPSHOT.jar 后缀)。
这部分规则用于管理 Systemd 服务、Jar 包部署等操作。
5、SQL脚本
update_sqls:sqls:- code: 1name: 初始化函数file: init_func.sql- code: 2name: 建表sqlfile: create_table.sql- code: 3name: 导入的数据 - 知识库基础file: preview_public_app_knowledge_hole_base_info.sql- code: 4name: 导入的数据 - cnnvd数据file: preview_public_app_knowledge_hole_cnnvd.sql
【数据库 SQL 变更管理】:
code:SQL 变更编号。
name:SQL 变更描述(如 「建表 SQL」)。
file:SQL 文件路径(如 create_table.sql)。
系统解析该部分后,会按顺序执行 SQL 变更,确保数据库初始化或升级到最新状态。
6、配置参数
config_params:- file_name: knowledge-nginx.conftarget_folder: /opt/module/nginx/conf.dparams:- code: 1name: webqianduan_portdescription: webqianduan_portdefault: 18080
【用于动态修改配置文件】(如 nginx 或 application-knowledge.yml)。
关键字段:
code:编号。
name:参数名称。
description:描述。
default:默认值。
file_name:配置文件名称(如 knowledge-nginx.conf)。
target_folder:目标存放目录(如 /opt/module/nginx/conf.d)。
params:参数列表,每个参数包含:
7、组件核心配置
- file_name: application-knowledge.ymltarget_folder: /opt/module/knowledge_0.0.1params:- code: 1name: server_portdescription: server_portdefault: 35001- code: 2name: pgsql_ipdescription: pgsql_ipdefault: 127.0.0.1
这部分主要用于配置应用的 YAML配置文件。
组件核心参数如:
server_port:服务端口(默认 35001)。
pgsql_ip:数据库 IP(默认 127.0.0.1)。
pgsql_user/pgsql_pwd:数据库账号密码。
系统解析时,会将参数注入到 application-knowledge.yml,支持自定义配置。
1.3 总结
✅ 通用性强:适用于 操作系统优化、中间件安装、子平台部署。
✅ 模块化设计:每个组件都有独立的 运行检测、配置、依赖、SQL 变更 规则。
✅ 自动化管理:可基于规则自动 安装、配置、升级、SQL 变更。
✅ 可扩展:支持 新增组件,只需新增一份 YAML 规则即可。
这套规则引擎能满足:
- 新组件的自动安装
- 已有组件的升级
- 服务的自动化启动和配置
- 数据库结构的变更
它的核心目标是标准化、自动化、模块化的部署管理。
1.4 外部调用内部组件部署的理念
当外部调用内部组件进行部署的时候,我们可以实现一个转换码表的概念,将用户在外部配置的参数映射到内部组件要配置的参数。所以这里我们需要提供给部署用户完整的转换码表,在用户进行非一键化部署的时候使用。
这套转换码表其实就是整个系统中的元数据,比如业务数据库账号,业务数据库密码这种参数,在许多平台都会设置,那么在外层只需要设置一次,就可以处处生效。
从上面的参数可以发现,我们在定义小组件部署的时候设置了参数的默认值,所以当进行外部调用时,如果用户没有配置对应的参数,我们直接使用该参数的默认值即可。
二、利用非对称加密对部署核心内容包进行加密解密
我们的内部部署包经过压缩后,形成的包文件为:
NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz
现在我们需要使用非对称加密对其进行加密和解密,并将加解密功能集成到部署工具deploy_tool中。
由于 deploy_tool 可能会被反编译,私钥存在泄漏风险,因此在私钥存储和使用时,需要采取混淆与保护策略。
2.1 生成密钥对
在 deploy_tool 工具初始化时,需要支持 动态生成密钥对 ,并提供安全的存储机制。
# 生成私钥(private_key.pem)
openssl genpkey -algorithm RSA -out private_key.pem -pkeyopt rsa_keygen_bits:4096# 从私钥提取公钥(public_key.pem)
openssl rsa -in private_key.pem -pubout -out public_key.pem
公钥用于加密,可公开存储。
私钥用于解密,需采取混淆存储或动态生成策略。
2.2 加密
加密过程由 deploy_tool 完成,主要步骤如下:
使用公钥对部署包进行加密 :
openssl rsautl -encrypt -pubin -inkey public_key.pem -in NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz -out NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz.enc
加密后的文件NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64-Enc.tar.gz 可安全分发。
2.3 解密
解密过程需在 deploy_tool 中实现,主要步骤如下:
openssl rsautl -decrypt -inkey private_key.pem -in NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz.enc -out NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz
但由于 deploy_tool 可能会被反编译,私钥的直接存储存在安全风险,因此需要额外的私钥混淆与保护策略。
1、动态生成固定私钥算法
如果我们的直接放到 deploy_tool 工具中,被反编译之后,可能会被直接拿到解密私钥,造成私钥泄漏的风险。所以这里需要考虑对私钥进行混淆。
【例如】,我们可以考虑下面的方法
将私钥拆分成多个部分,分别存储在不同位置(例如:配置文件 + 代码逻辑 + 运行时生成)。
运行时动态组合私钥:
part1 = "-----BEGIN PRIVATE KEY-----\n..."
part2 = "..."
part3 = "-----END PRIVATE KEY-----"
private_key = part1 + part2 + part3
优点:每个部分都可以使用算法生成,这样攻击者无法直接在代码中找到完整私钥。减少私钥泄漏的风险。
三、给安装包生成完整性校验码MD5
利用md5sum命令对安装包生成完整性校验码。
可以使用以下命令生成 md5sum 校验码并将其保存到 checksum.txt 文件中:
md5sum NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz > checksum.txt
3.1 说明
md5sum:计算文件的 MD5 校验码
NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz:需要计算的目标文件
>:将输出重定向到 checksum.txt,存储 MD5 校验码
运行后,checksum.txt 文件内容示例:
d41d8cd98f00b204e9800998ecf8427e NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz
如果需要验证完整性,可使用:
md5sum -c checksum.txt
如果文件未被篡改,则会显示:
NgSoc-Custom-XYZCorp-V1.5.0-Full-20241230-x86_64.tar.gz: OK
四、deploy_config部署参数的配置和解析
在上文提到的deploy_config.yaml中,我们提到了用户可能会配置一些必要的配置参数。
4.1 最简单的部署的参数配置
以下配置均由打包部署人员在打包时进行配置,交到用户手上就是已经配置好的结果。
最简单的部署配置,我们目前只考虑下面的情况:
1、package_name与加密包名字保持一致
package_name与加密包名字保持一致,用于检查部署配置和部署包的同步性(防止部署配置文件与部署包不匹配引起的部署异常)。
2、默认配置为单实例部署模式
默认为单实例部署,且部署并启动所有的应用。
instance_type 部署实例(0代表单实例,1代表三机实例),默认为0。
master 节点配置,ip为127.0.0.1、主机名为master。
下面是默认的配置参数示例:
package_name: NgSoc-Custom-XYZCorp-V2.1.1-Full-20241230-x86_64-Enc.tar.gz # 打包时配置
instance_type: 0
master:ip: 127.0.0.1 # 默认的单节点iphost_name: master # 默认的单节点主机名
4.2 子平台安装依赖配置规则
除了简化的配置以外,如果我们想实现版本的升级等功能,就需要配置出版本的依赖关系。
package_name: NgSoc-Custom-XYZCorp-V2.1.1-Full-20241230-x86_64-Enc.tar.gz # 打包时配置
components: # 配置平台的安装顺序- name: base # 主平台baseversion: >=2.1- name: asset # 资产子平台version: ==2.1- name: vuln # 漏洞子平台version: ==2.1- name: notice # 通知通报子平台
instance_type: 0
master:ip: 127.0.0.1host_name: master
这里的 components主要存放当前安装版的安装子平台;version字段主要用于版本依赖校验:如果子平台已经安装过并且存在,那么要做更新或迭代时应该满足的老版本。如果version字段不存在,则表示直接安装即可。
在安装包中,打包人员需要按照以下规则配置 components 及其 version 依赖关系,以确保各子平台的正确部署和更新。
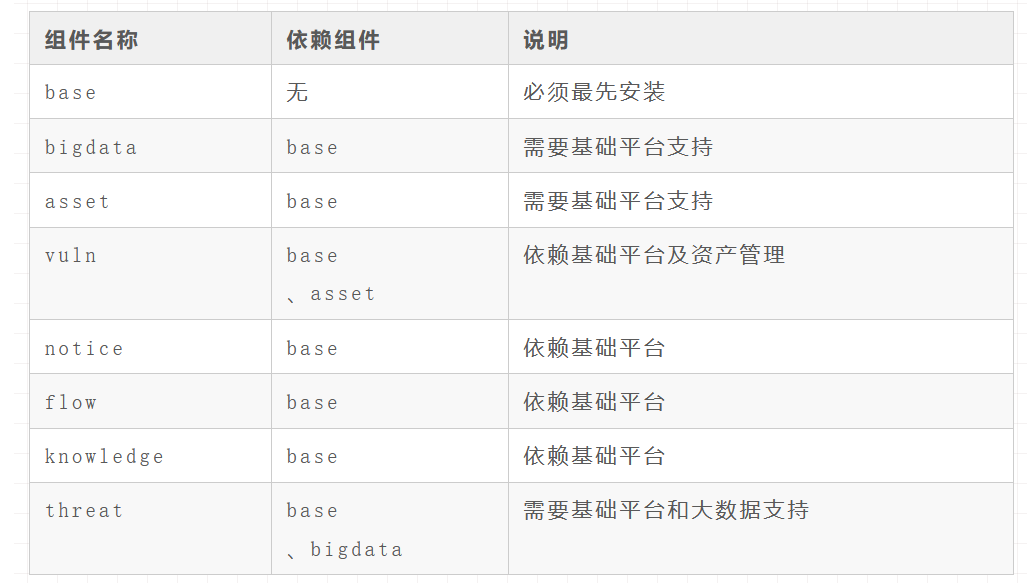
1、组件安装顺序
由于部分子平台存在依赖关系,安装顺序需遵循以下原则:
- 基础平台 (base) 必须最先安装,所有其他子平台均依赖 base 运行。
- 大数据底座 (bigdata) 需要在依赖大数据存储或计算的子平台之前安装(如 threat)。
- 业务子平台可根据需求选择安装,但应满足依赖关系。
2、版本依赖规则
在 components 配置中,version 字段用于版本依赖校验,具体规则如下:
-
>=X.Y : 该子平台的版本必须大于等于 X.Y 才能安装或更新。
-
==X.Y : 该子平台必须正好安装 X.Y 版本。
-
缺失 version 字段: 直接重新安装,无版本校验。
3、组件安装依赖
4、配置示例
components: - name: baseversion: >=2.1- name: bigdataversion: >=2.1- name: assetversion: ==2.1- name: vulnversion: ==2.1- name: notice- name: flow- name: knowledge- name: threatversion: >=2.1
bigdata 依赖 base,所以 base 必须先安装。
vuln 依赖 asset 和 base,所以 asset 需提前安装。
threat 依赖 bigdata 和 base,所以必须满足 >=2.1 版本。
这样,打包人员可以根据不同环境需求调整 components 列表,以保证安装的顺序和依赖正确。
4.3 部署时将本次的部署参数存放到环境变量中以便下次部署时验证使用
在安装内部组件的时候,我们需要把部署的版本存放到环境变量中,以供后续更新迭代部署的时候进行校验使用。
1、存储部署信息
为了在下次部署时验证当前系统中的组件信息,可以在 首次部署 时,将 当前安装的组件信息 存入环境变量或配置文件(如 /etc/deploy_env.conf)。
可以采用如下格式:
export INSTALLED_COMPONENTS="base:2.1,asset:2.1,vuln:2.1,notice:2.1"
或者存入 JSON 配置文件:
{"components": {"base": "2.1","asset": "2.1","vuln": "2.1","notice": "2.1"}
}
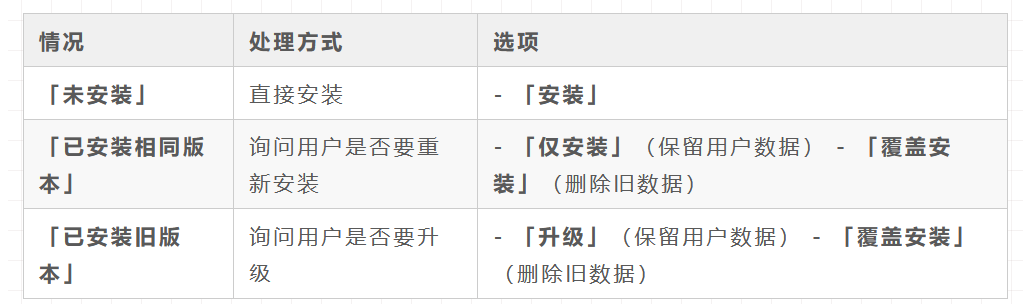
2、检测当前系统的组件版本
在 下次部署时,可以执行以下步骤:
- 解析当前 INSTALLED_COMPONENTS 变量或配置文件,获取已安装的组件及版本。
- 读取本次部署的参数,逐个对比组件是否已安装、版本是否匹配。
- 根据检测结果提供不同的部署选项。
3、部署逻辑
五、建立外部参数与内部参数的映射关系
5.1 外部必填参数的默认映射
在上面的描述中,当为单机部署时,master.ip为必填参数,那么部署工具会默认将其匹配为内层参数中包含%_ip% 字段的所有字段并写入该值。
当为三台机器部署时,master.ip、node[1].ip 和 node[2].ip 为必填参数,那么部署工具也会默认将其分别给主节点和两个从节点匹配为内存参数中包含 %_ip% 的字段,并写入对应的值。
5.2 外部非必填参数的映射方式
在内层包内,所有的配置参数均以 组件-配置文件名-参数名进行维护的,所以对于外部非必填参数来说,最基础的匹配方式便是使用 按组件-文件名-参数名 --对应相等 的方式。
经过我们早期的实践可知,业务组件在多数时候可能存在相同的配置参数,例如数据库名、数据库密码等等。
所以这里考虑实现以下规则引擎:
-
当用户配置参数时,是完整的
组件-配置文件名-参数名结构,则按全匹配相等进行填充; -
当用户配置时没有带组件名,则按
配置文件名-参数名匹配相等进行填充; -
当用户配置时只有参数名,则按
参数名匹配相等进行填充; -
当用户没有配置非必填参数时,则先读取现有部署环境的配置参数值,如果存在,则使用该值;如果不存在,则使用默认的配置值。
这样,当我们使用工具进行内部参数填充的时候,就可以根据用户的配置情况和默认参数的配置情况进行处理。
1、匹配逻辑流程
- 检查用户是否提供完整路径(组件-文件-参数):
如果提供,则直接使用该值。
如果未提供,进入下一步。
- 检查是否提供配置文件名+参数名:
如果提供,则匹配所有符合该条件的参数。
如果未提供,进入下一步。
- 检查是否仅提供参数名:
如果提供,则匹配所有符合该参数名的配置项。
如果未提供,进入下一步。
- 先读取现有部署环境的配置参数值,如果存在,则使用该值;如果不存在,则使用默认的配置值。
六、deploy_tool 部署工具的实现原理
部署工具应该实现的功能如下:
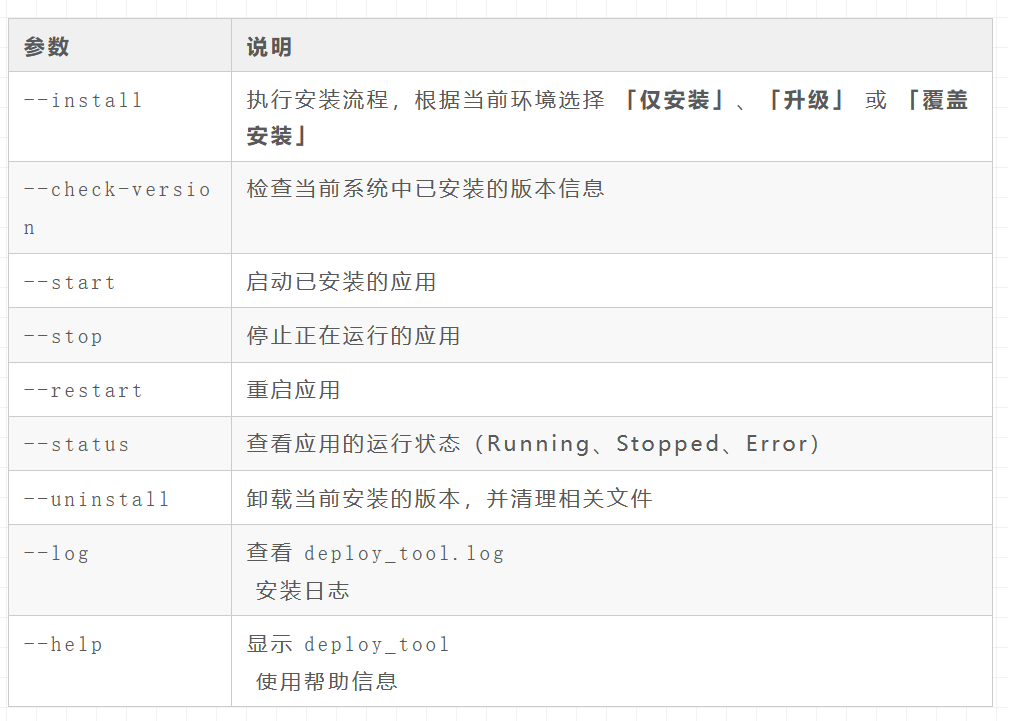
6.1 install指令的实现逻辑
上面已经提到了deploy_tool工具在实现解密和依赖检查的逻辑。接下来我们来说一下安装的步骤实现的详细逻辑。
1、解密
2、依赖检查
3、读取deploy_config的配置
4、进入内部包执行部署工作流
- 读取部署顺序配置文件
- 执行部署
5、校验各个部分部署完成的状态
6.2 其他指令的实现逻辑
--check-version
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 获取当前系统已安装的版本信息
● 校验版本信息是否完整
--start
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 进入内部包执行启动工作流
○ 读取应用启动配置
○ 执行启动命令
● 校验应用是否成功启动
--stop
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 进入内部包执行停止工作流
○ 读取应用停止配置
○ 执行停止命令
● 校验应用是否成功停止
--restart
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 进入内部包执行重启工作流
○ 读取应用重启配置
○ 先执行停止命令
○ 再执行启动命令
● 校验应用是否成功重启
--status
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 进入内部包执行状态检查
○ 查询进程状态
○ 解析状态信息(Running、Stopped、Error)
● 返回应用状态
--uninstall
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 进入内部包执行卸载工作流
○ 读取卸载配置
○ 停止应用
○ 删除相关文件
● 校验卸载是否完成
--log
● 解密
● 依赖检查
● 读取 deploy_config 的配置
● 读取 deploy_tool.log 日志内容并输出
--help
● 解析 deploy_tool 可用命令
● 输出帮助信息
七、内部组件级部署工具的实现
在目前的V1部署版本中,已经实现基于组件的部署方式。我们已经可以做到基于单一组件的交互式部署和升级等功能。下面是一个简单的说明。
7.1 交互式部署扩展为自动部署
首先,我们目前已经维护了所有组件包的交互式部署配置。
让我们以现在的业务部署biz_base配置为例:
它的结构存放了替换的配置文件config目录,sqls清单和所有的服务化脚本配置。
conf.yml为这个业务大组件部署的规则清单,里面定义了部署的方式,定义了参数替换的清单,可以直接对sqls里面的脚本清单按序号进行执行。
这里的序号设计为一个组或版本,这样我们就可以实现旧版本的先执行,新版本的后执行。
在原有交互式部署的方法上,我们需要改造脚本,让其能够自动执行相关的安装操作。
例如,之前会等待用户输入,现目前的逻辑替换为 获取外层脚本传入的参数清单,并依据默认的参数和已经配置的参数,重新配置各个参数。
这样一来,我们就可以实现内部自动部署和外部简单配置相协调的方案了。
原创 demo123567 海燕技术栈