一、缓存
1. 什么是缓存
缓存的作用是减低对数据源的访问频率。从而提高我们系统的性能。
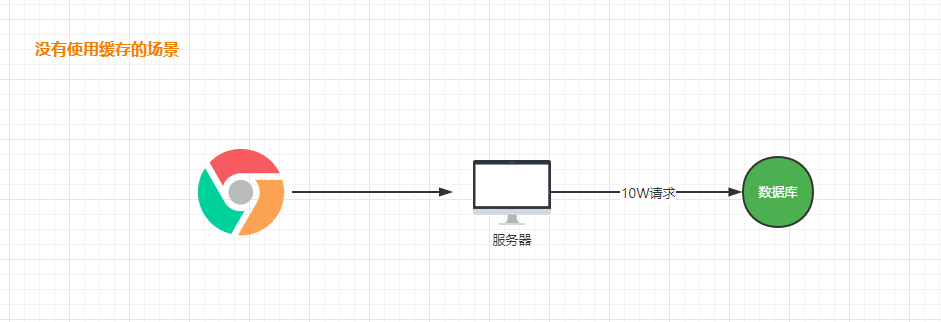
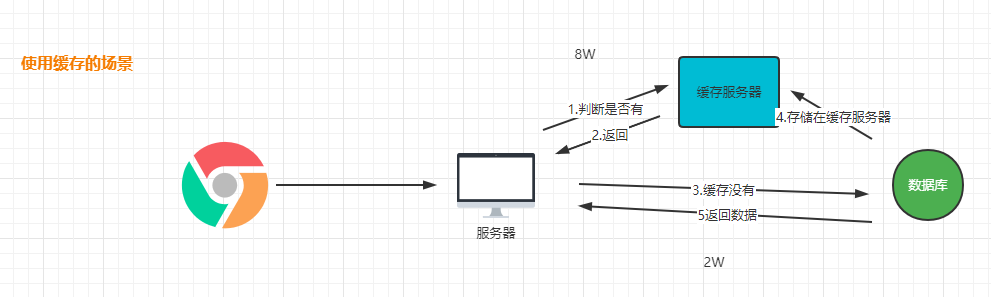
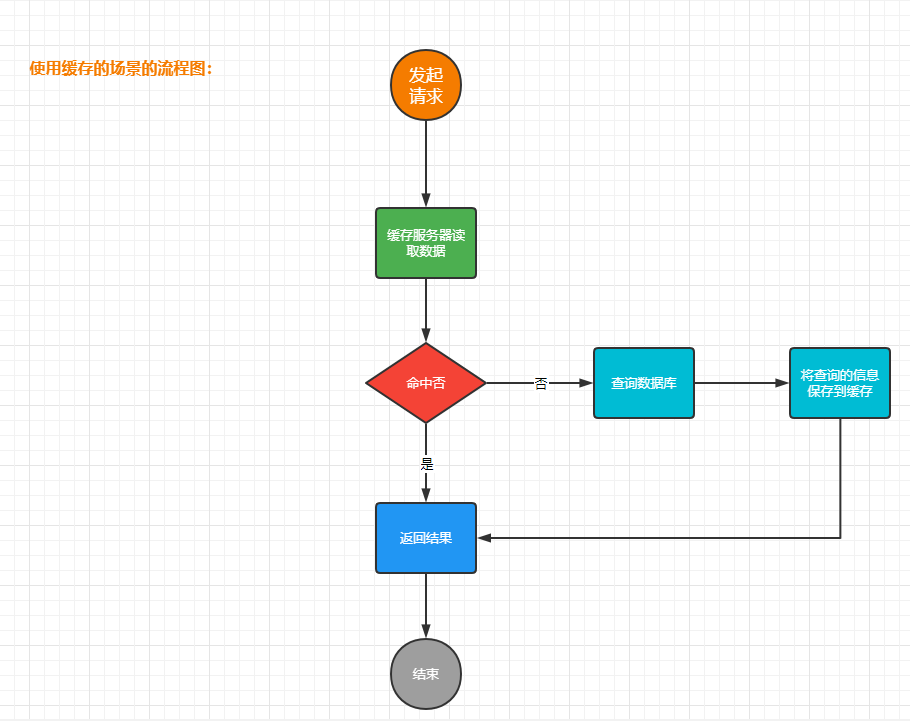
缓存的流程图
2.缓存的分类
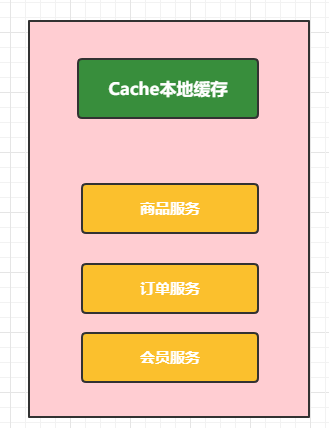
2.1 本地缓存
其实就是把缓存数据存储在内存中(Map <String,Object>).在单体架构中肯定没有问题。

单体架构下的缓存处理
2.2 分布式缓存
在分布式环境下,我们原来的本地缓存就不是太使用了,原因是:
- 缓存数据冗余
- 缓存效率不高
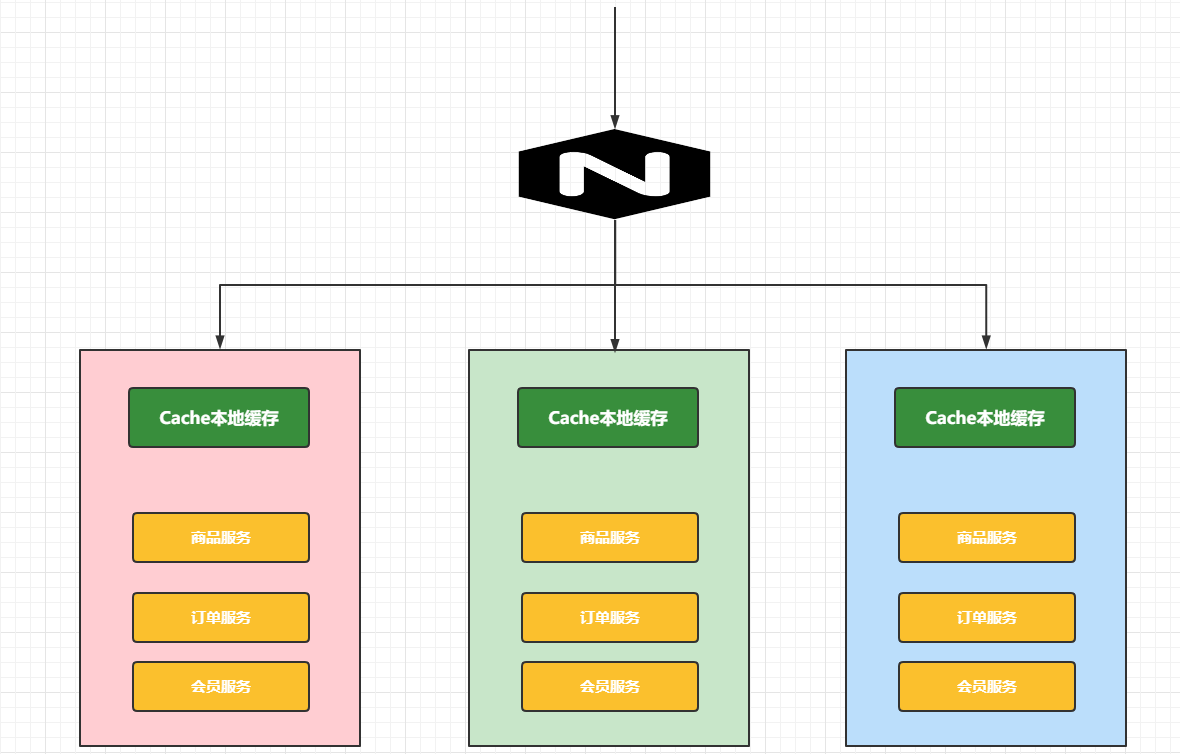
分布式缓存的结构图

3.整合Redis
要整合Redis那么我们在SpringBoot项目中首页来添加对应的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
然后我们需要添加对应的配置信息

测试操作Redis的数据
@AutowiredStringRedisTemplate stringRedisTemplate;@Testpublic void testStringRedisTemplate(){// 获取操作String类型的Options对象ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();// 插入数据ops.set("name","bobo"+ UUID.randomUUID());// 获取存储的信息System.out.println("刚刚保存的值:"+ops.get("name"));}
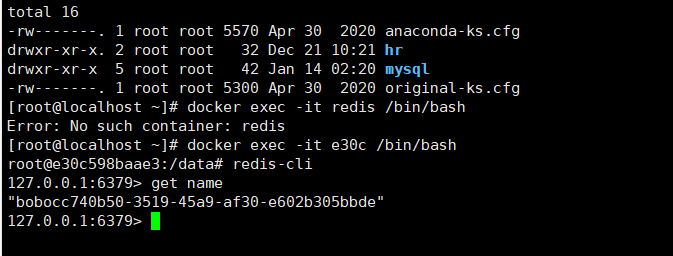
查看可以通过Redis的客户端连接查看
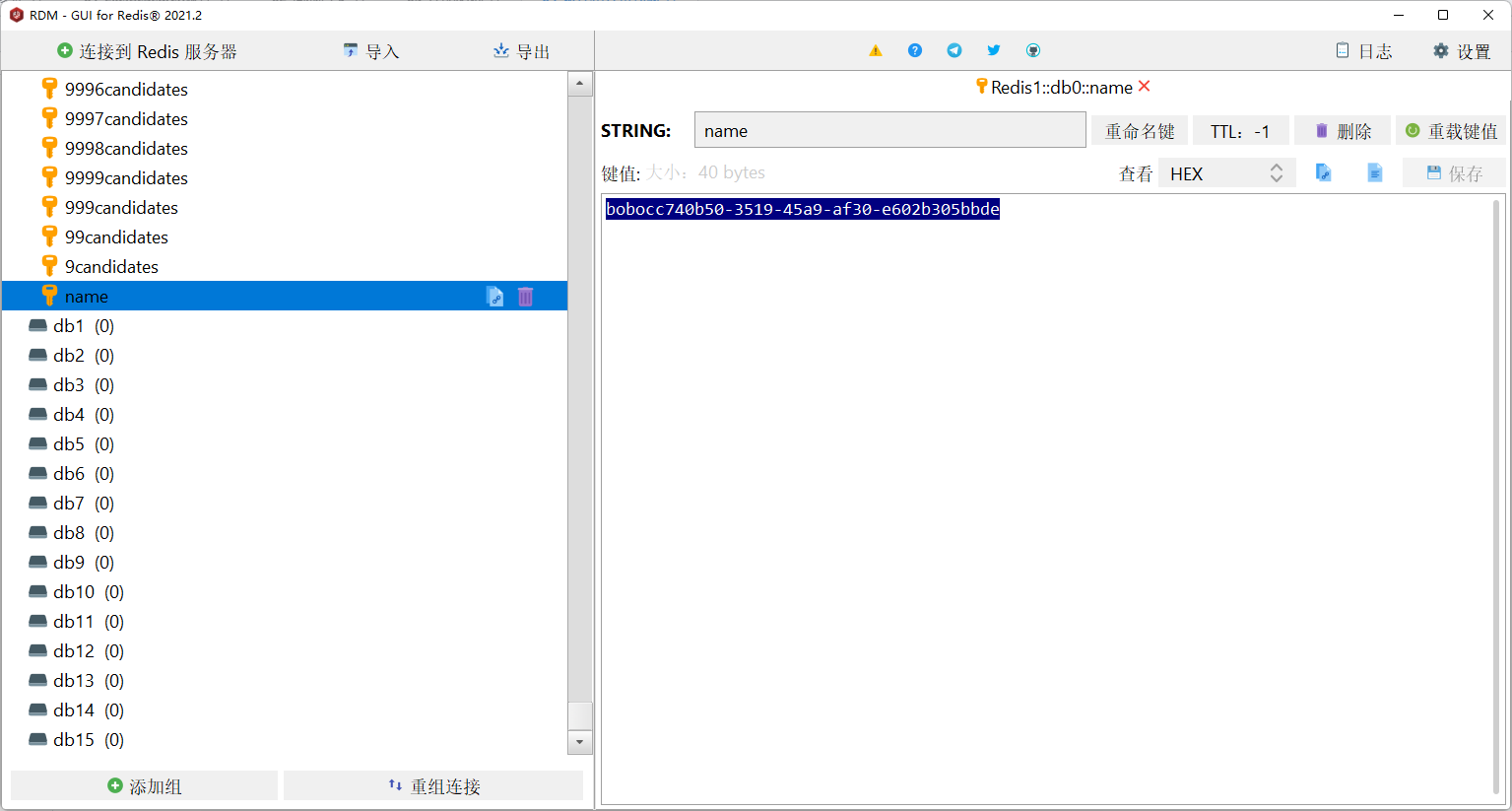
也可以通过工具查看
4.改造三级分类
在首页查询二级和三级分类数据的时候我们可以通过Redis来缓存存储对应的数据,来提升检索的效率。
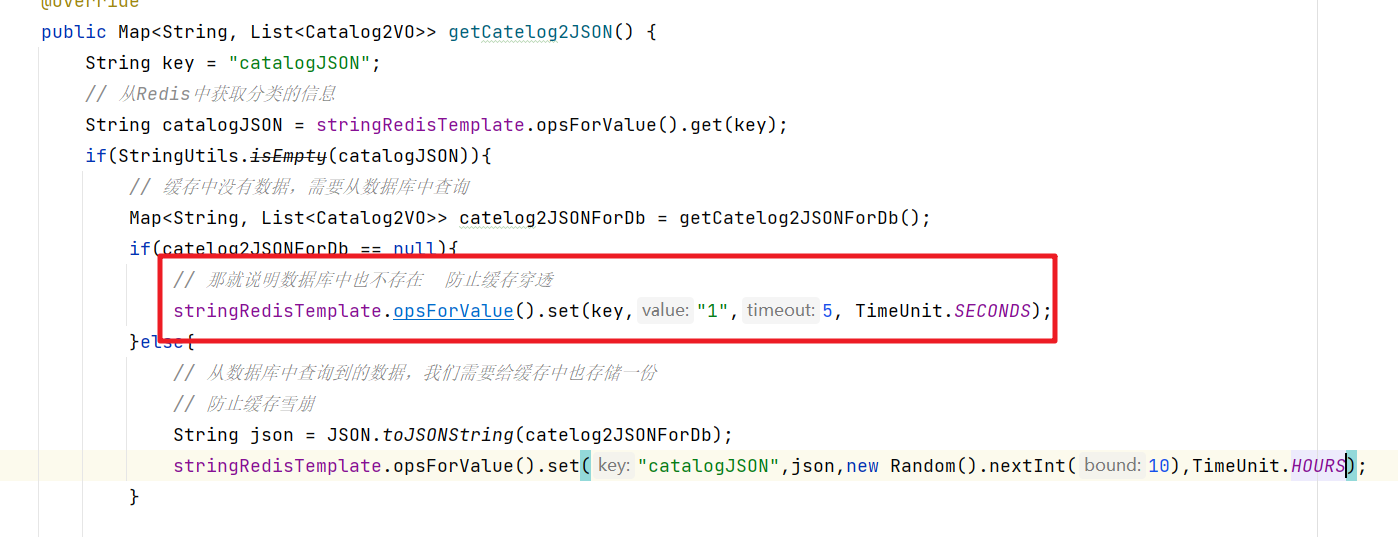
@Overridepublic Map<String, List<Catalog2VO>> getCatelog2JSON() {// 从Redis中获取分类的信息String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");if(StringUtils.isEmpty(catalogJSON)){// 缓存中没有数据,需要从数据库中查询Map<String, List<Catalog2VO>> catelog2JSONForDb = getCatelog2JSONForDb();// 从数据库中查询到的数据,我们需要给缓存中也存储一份String json = JSON.toJSONString(catelog2JSONForDb);stringRedisTemplate.opsForValue().set("catalogJSON",json);return catelog2JSONForDb;}// 表示缓存命中了数据,那么从缓存中获取信息,然后返回Map<String, List<Catalog2VO>> stringListMap = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catalog2VO>>>() {});return stringListMap;}
然后对三级分类的数据做压力测试
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 三级分类压测(业务优化后) | 50 | 448 | 113 | 227 |
| 三级分类压测(Redis缓存) | 50 | 1163 | 49 | 59 |
通过对比可以看到Redis缓存加入后的性能提升的效果还是非常明显的。
5.缓存穿透
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义.

利用不存在的数据进行攻击,数据库瞬时压力增大,最终导致崩溃,解决方案也比较简单,直接把null结果缓存,并加入短暂的过期时间
6.缓存雪崩
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
注意这里的随机数要取正数,这里有可能随机出负数,那么有效期时间就是无效的会报异常

7.缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
解决方案:加锁,大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db。

但是当我们压力测试的时候,输出的结果有点出乎我们的意料
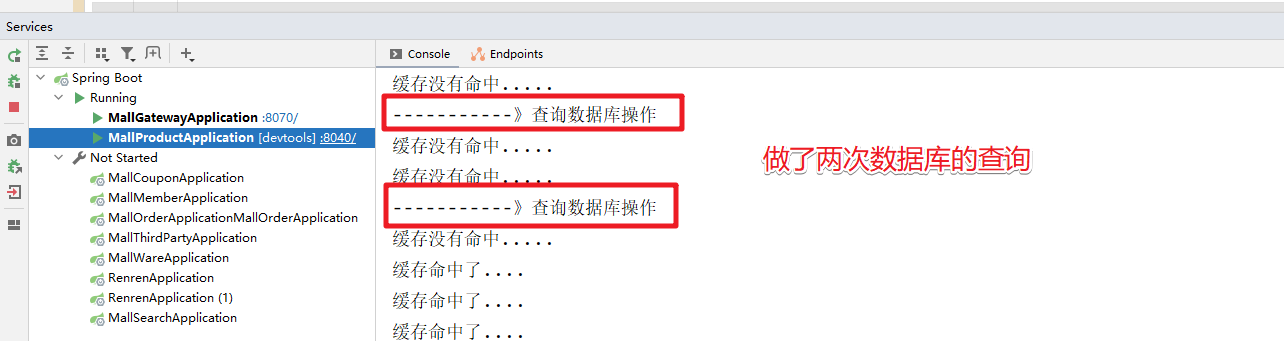
做了两次的查询,原因是释放锁和查询结果缓存的时序问题
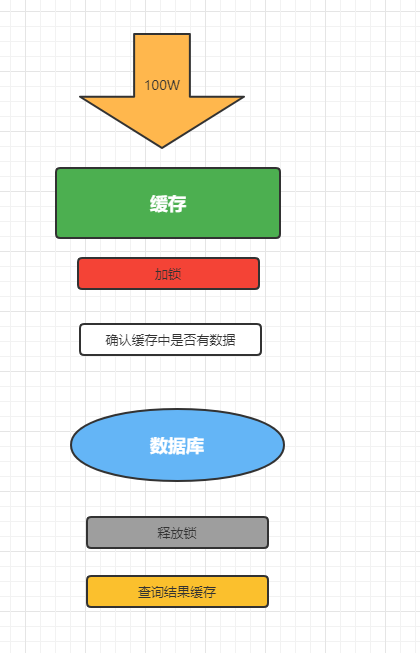
我们只需要调整下释放锁和结果缓存的时序问题就可以了
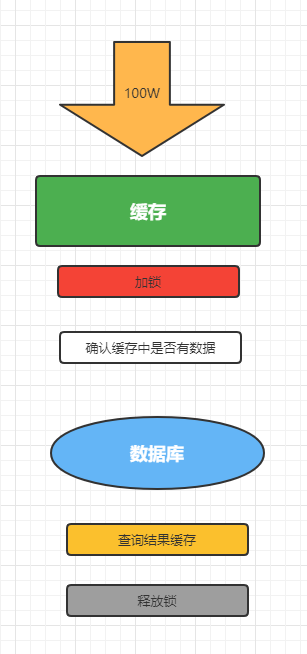
然后就是完整的代码处理
/*** 查询出所有的二级和三级分类的数据* 并封装为Map<String, Catalog2VO>对象* @return*/@Overridepublic Map<String, List<Catalog2VO>> getCatelog2JSON() {String key = "catalogJSON";// 从Redis中获取分类的信息String catalogJSON = stringRedisTemplate.opsForValue().get(key);if(StringUtils.isEmpty(catalogJSON)){System.out.println("缓存没有命中.....");// 缓存中没有数据,需要从数据库中查询Map<String, List<Catalog2VO>> catelog2JSONForDb = getCatelog2JSONForDb();if(catelog2JSONForDb == null){// 那就说明数据库中也不存在 防止缓存穿透stringRedisTemplate.opsForValue().set(key,"1",5, TimeUnit.SECONDS);}else{// 从数据库中查询到的数据,我们需要给缓存中也存储一份// 防止缓存雪崩String json = JSON.toJSONString(catelog2JSONForDb);stringRedisTemplate.opsForValue().set("catalogJSON",json,10,TimeUnit.MINUTES);}return catelog2JSONForDb;}System.out.println("缓存命中了....");// 表示缓存命中了数据,那么从缓存中获取信息,然后返回Map<String, List<Catalog2VO>> stringListMap = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catalog2VO>>>() {});return stringListMap;}/*** 从数据库查询的结果* 查询出所有的二级和三级分类的数据* 并封装为Map<String, Catalog2VO>对象* 在SpringBoot中,默认的情况下是单例* @return*/public Map<String, List<Catalog2VO>> getCatelog2JSONForDb() {String keys = "catalogJSON";synchronized (this){/*if(cache.containsKey("getCatelog2JSON")){// 直接从缓存中获取return cache.get("getCatelog2JSON");}*/// 先去缓存中查询有没有数据,如果有就返回,否则查询数据库// 从Redis中获取分类的信息String catalogJSON = stringRedisTemplate.opsForValue().get(keys);if(!StringUtils.isEmpty(catalogJSON)){// 说明缓存命中// 表示缓存命中了数据,那么从缓存中获取信息,然后返回Map<String, List<Catalog2VO>> stringListMap = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catalog2VO>>>() {});return stringListMap;}System.out.println("-----------》查询数据库操作");// 获取所有的分类数据List<CategoryEntity> list = baseMapper.selectList(new QueryWrapper<CategoryEntity>());// 获取所有的一级分类的数据List<CategoryEntity> leve1Category = this.queryByParenCid(list,0l);// 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap(key -> key.getCatId().toString(), value -> {// 根据一级分类的编号,查询出对应的二级分类的数据List<CategoryEntity> l2Catalogs = this.queryByParenCid(list,value.getCatId());List<Catalog2VO> Catalog2VOs =null;if(l2Catalogs != null){Catalog2VOs = l2Catalogs.stream().map(l2 -> {// 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName());// 根据二级分类的数据找到对应的三级分类的信息List<CategoryEntity> l3Catelogs = this.queryByParenCid(list,l2.getCatId());if(l3Catelogs != null){// 获取到的二级分类对应的三级分类的数据List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> {Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName());return catalog3VO;}).collect(Collectors.toList());// 三级分类关联二级分类catalog2VO.setCatalog3List(catalog3VOS);}return catalog2VO;}).collect(Collectors.toList());}return Catalog2VOs;}));// 从数据库中获取到了对应的信息 然后在缓存中也存储一份信息//cache.put("getCatelog2JSON",map);// 表示缓存命中了数据,那么从缓存中获取信息,然后返回if(map == null){// 那就说明数据库中也不存在 防止缓存穿透stringRedisTemplate.opsForValue().set(keys,"1",5, TimeUnit.SECONDS);}else{// 从数据库中查询到的数据,我们需要给缓存中也存储一份// 防止缓存雪崩String json = JSON.toJSONString(map);stringRedisTemplate.opsForValue().set("catalogJSON",json,10,TimeUnit.MINUTES);}return map;} }
8.本地锁的局限
本地锁在分布式环境下,是没有办法锁住其他节点的操作的,这种情况肯定是有问题的

针对本地锁的问题,我们需要通过分布式锁来解决,那么是不是意味着本身锁在分布式场景下就不需要了呢?
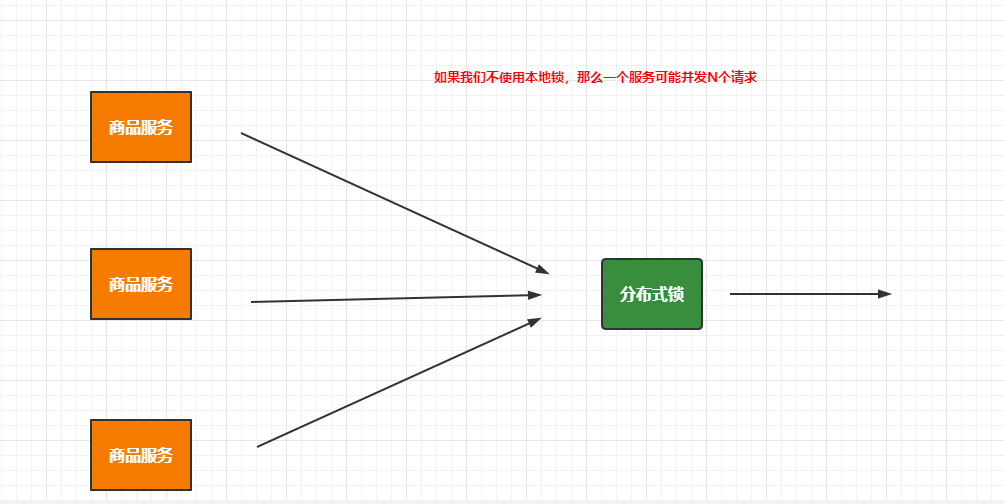
显然不是这样的,因为如果分布式环境下的每个节点不控制请求的数量,那么分布式锁的压力会非常大,这时我们需要本地锁来控制每个节点的同步,来降低分布式锁的压力,所以实际开发中我们都是本地锁和分布式锁结合使用的。