本文介绍了深度学习和神经网络的基本概念,深度学习和传统机器学习的差别,还了解了PyTorch框架,最后通过一个例子演示了如何基于PyTorch使用一个视觉检测模型来快速完成图片的目标检测任务,十分方便。
本文介绍了深度学习和神经网络的基本概念,深度学习和传统机器学习的差别,还了解了PyTorch框架,最后通过一个例子演示了如何基于PyTorch使用一个视觉检测模型来快速完成图片的目标检测任务,十分方便。大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第9站,一起了解下大数据和GPU时代下的 深度学习 和 PyTorch框架。
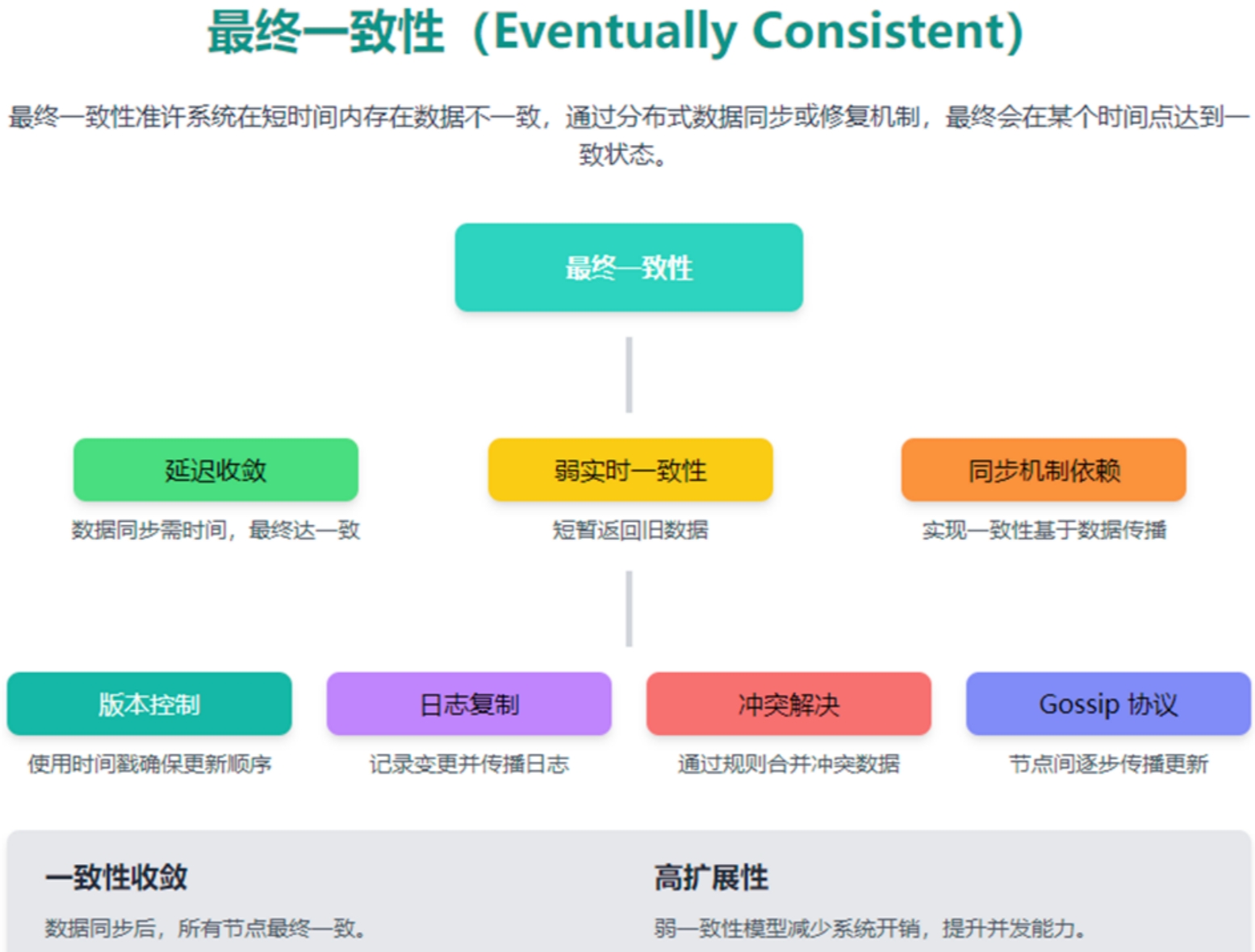
深度学习介绍
根据之前的学习,我们知道了人工智能的范围很广阔,而机器学习是人工智能的一个重要分支,而今天要学习的深度学习又是机器学习的一个重要分支。
在大数据和GPU的加持下,我们现在正处于深度学习的黄金时代。
深度学习是机器学习实践方法中的一种,它是基于神经网络的机器学习方法。

所谓神经网络,说的其实是它在模拟人类大脑神经系统,通过多个层次的大量参数来模拟一层一层的神经元的效果,这些多层次的参数节点最终形成一个巨大的参数网络,然后通过不断的参数调参,进而完成如预测、分类、NLP等任务。
神经网络最厉害的地方在于:特征的自动抽取能力。也就是说,我们不需要告诉算法该如何去抽取要解决问题的特征(在机器学习中通常这块工作量很大),它自己就可以学习和抽取特征。例如,下面这个用CNN(卷积神经网络)进行手写数字的识别,要告诉算法特征值工作量很大,但是用神经网络它自己就可以一层一层地抽取到特征。

而深度神经网络,通常是指层数很多(网络隐藏层)的神经网络,例如上图中的网络隐层。现在的网络隐藏层可以是几万层或者无限层,层数越多,下一层就可能学习到新的特征,也就能够处理越复杂的问题,处理问题的效果也就越好,当然,需要的计算资源也越高,成本当然也就越高。
近年来,深度学习常常用在复杂问题的处理上,如图像识别、目标检测、NLP、机器翻译等领域,它需要大量的数据和大量计算资源,特别典型的基于深度学习的模型就是Transformer。
下图展示了各种现代神经网络模型,你一定用过或听过一个或多个:

深度学习 vs 传统机器学习
前面几篇我们学习到的就是传统的机器学习方法,现在也叫它“浅层机器学习”,因为它没有多层的神经网络,无法自己学习提取特征,因此它就不适合做结构不良好的数据集的分类或回归等任务。

相反,深度学习就可以处理结构不良好的数据集的机器学习任务,特别是感知类的问题。所谓感知类问题,通常涉及视觉和听觉,比如图像、音频、视频 包括 文字的理解等等。
如果我们遇到的是一个结构良好的数据集,那么我们完全可以使用传统机器学习方法进行回归和分类等任务。
而如果我们遇到的是一个感知类的问题,那么我们就需要考虑使用深度学习方法了。
神经网络是如何学习的
假设有一个成千上万层的网络,一层层地堆叠起来,你把输入数据假设是一张猫的图片丢给它,网络会通过各种各样的参数进行提纯和过滤,通过损失函数判断当前网络的效能(类似于一个裁判,判别网络识别的正确与否),然后通过优化器(梯度下降)来调整权重,寻找到从输入到输出的最佳函数,进而得到输出也就是识别结果是猫。当然,这个最佳函数特别复杂,可能无法用一个数学公式写出来,也没必要写出来。

NOTE:损失函数在判断正确与否时,当得到的是一个错误的结果,网络中神经元的权重就会受到惩罚,优化器(梯度下降工具)就会去调整权重。
多层神经网络的前向和反向传播
在神经网络中存在前向和反向传播:

(1)前向传播从输入层开始,经过各个网络隐藏层,计算出最终结果的过程。比如,丢一张猫图片进去,网络给到结果:0代表猫,1代表狗 之类的。
大体过程:
-
输入数据
-
线性转换
-
激活函数
-
每一层重复上述步骤
-
损失函数计算损失
(2)反向传播是从输出层开始,比如当识别结果错误时,通过计算梯度向前面的层进行反馈,告知其更新权重。
大体过程:
-
计算输出层的梯度
-
计算隐藏层的梯度
-
更新权重和偏置
-
迭代反复
从上可以看出,识别到错误的结果不重要,重要的是反向传播迭代更新,最终就能提高识别准确率。毕竟,知错能改,善莫大焉。
PyTorch:深度学习框架
了解了深度学习的一些基本概念,那么我们小白如何参与深度学习呢,借助各种深度学习框架,就可以事半功倍。常见的深度学习框架有 TensorFlow 和 PyTorch,今天我们主要了解PyTorch。

PyTorch 是一个开源的机器学习库,主要用于应用如计算机视觉和自然语言处理等领域。它由 Facebook 的 AI 研究团队开发,并以 Python 编程语言为基础,提供了强大的 GPU 加速支持。PyTorch 旨在让研究人员和开发者能够以一种直观、灵活的方式来构建和训练神经网络。
目前,PyTorch以其灵活、高效、易上手的特点以及丰富的预训练模型和工具、活跃的社区和生态资源等优势,成为深度学习和机器学习领域的热门框架之一。
你可以通过pip快速安装PyTorch:
pip install torch torchvision
基于PyTorch使用ResNet完成目标检测
接下来,我们就通过一个例子来看看如何基于PyTorch来使用一个视觉模型ResNet快速完成目标检测,从中可以看出基于PyTorch可以很方便地使用丰富的预训练神经网络模型。至于模型的训练,就留到下一篇吧。
假设我们要识别一张图片中的狗,自行车 和 汽车,刚好我们也有一张这样的图片,它来自公开的COCO数据集,想要丢给模型让其帮助识别出来,并给我标注好图片中他们分别在哪个位置。

这里我们使用PyTorch集成好的一个预训练视觉检测模型ResNet50:
Step1 导入必要库
import torch import torchvision from torchvision.models.detection import fasterrcnn_resnet50_fpn from torchvision.transforms import functional as F from PIL import Image, ImageDraw import matplotlib.pyplot as plt
Step2 导入ResNet50模型
从pytorch中直接引入:
model = fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
Step3 加载图片 并 进行预测
image = Image.open('dog_bike_car.jpg') image = image.resize((800, 600)) image_tensor = F.to_tensor(image) with torch.no_grad():prediction = model([image_tensor])
Step4 筛选分数>=0.7的预测
labels = prediction[0]['labels'] scores = prediction[0]['scores'] boxes = prediction[0]['boxes'] # 筛选分数大于0.7的预测 threshold = 0.7 labels = labels[scores > threshold] boxes = boxes[scores > threshold].cpu().numpy() scores = scores[scores > threshold].cpu().numpy()
分数定义的越高,识别出来的可能就越少,因为你要求的准确度高啊。
Step5 绘制最终识别结果
为了清晰地看到结果,绘制带边界框的结果图:
COCO_CLASSES = ['N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus','train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A','stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse','sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack','umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis','snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard','surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife','spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog','pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A','N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book','clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'] # 使用PIL在图像上绘制边界框 draw = ImageDraw.Draw(image) for box, label, score in zip(boxes, labels, scores):class_name = COCO_CLASSES[label.item()]draw.rectangle(box, outline='yeloow', width=3)draw.text((box[0], box[1]), text=f'{class_name} {score:.2f}', fill='blue') # 绘制最终结果图 plt.imshow(image) plt.axis('off') plt.show()
最终的识别结果如下所示:

小结
本文介绍了深度学习和神经网络的基本概念,深度学习和传统机器学习的差别,还了解了PyTorch框架,最后通过一个例子演示了如何基于PyTorch使用一个视觉检测模型来快速完成图片的目标检测任务,十分方便。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。