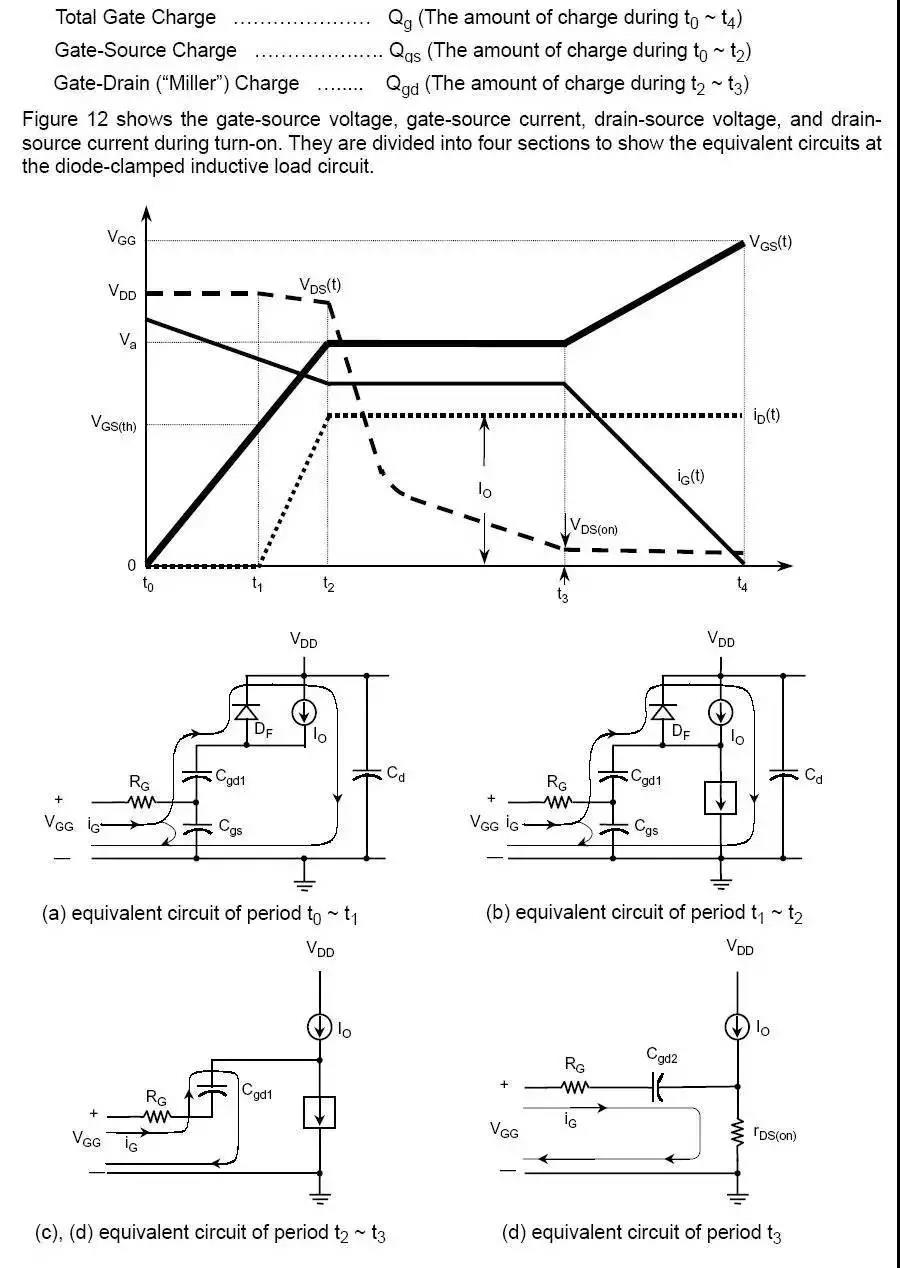
- 概
- Pic2Word
- 代码
Saito K., Sohn K., Zhang X., Li C., Lee C., Saenko K., and Pfister T. Pic2Word: Mapping pictures to words for zero-shot composed image retrieval. CVPR, 2023.
概
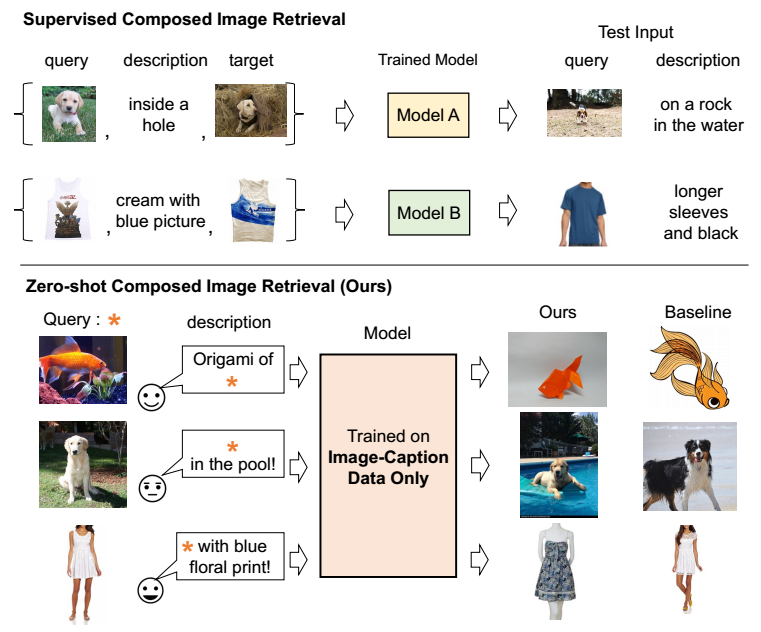
本文关注的是 Composed Image Retrieval (CIR) 任务: 给定一个 reference (query) image 和一段文本描述, 检索同时满足二者需求的图片. 比如给定一张狗狗趴在草地上的图片, 和一段描述 "在泳池中", 那么理应检索出在泳池中的狗狗的图片.
Pic2Word
-
一般的带监督的 CIR 任务, 其模型训练时依赖三元组: (reference, text, target), 从而能够设计逼近 target 的学习任务.
-
但是这种三元组的获得是很难的 (费时费力). 现存的数据广泛存在的是 (image, text) 这种类型数据.
-
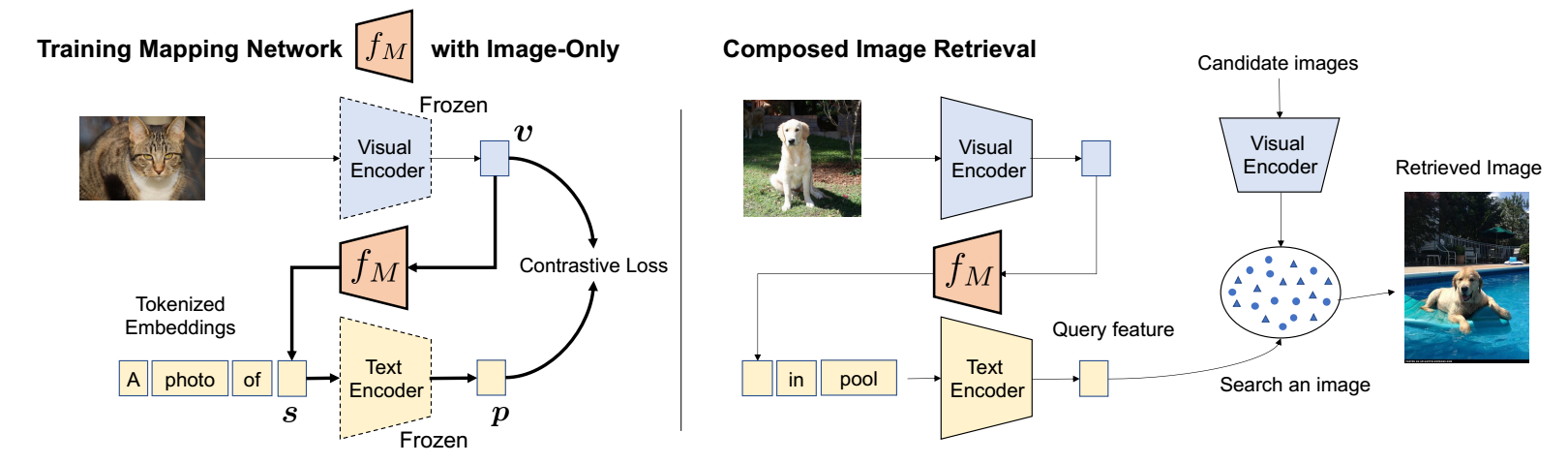
于是, 本文提出了 Pic2Word 在这种情况下也能够获得足够的性能. 如上图所示, 我们需要训练一个 mapping network \(f_M\), 其
\[\bm{s} = f_M(\bm{v}) = f_M(\psi_{visual} (\bm{x})), \]将通过 CLIP 得到图片的表征 \(\bm{v}\) 映射到 token embedding 所在的空间.
这里 \(\psi_{visual}\) 是 CLIP 中的 visual encoder. -
然后在要求图片和描述 'A photo of \(\bm{s}\)' 对齐 (文本描述实际上会有多个模板).
-
具体流程如下:
- 提取图片 \(\bm{x}\) 的表征:\[\bm{v} = \psi_{visual}(\bm{x}); \]
- 通过 mapping network 得到 visual 的 token embedding:\[\bm{s} = f_M (\bm{v}); \]
- 通过 text encoder 提取:\[\bm{p} = \psi_{textual} ("\text{A photo of } \bm{s}"); \]
- 各自 normalized 后的表征用对比损失进行对齐.
- 提取图片 \(\bm{x}\) 的表征:
-
训练完之后, 我们就可以把通过 \(f_M\) 提取得到的图片 token embedding \(\bm{s}\) 作为对象插入到任意的语句中, 此时 '\(\bm{s}\) in pool' 很大程度就近似于 'dog in pool', 于是凭借之后的 textual 表征可以进行直接的检索 (candidate 为图片的 visual 表征).
注: 在这之前以及之后也有类似的用 CLIP 的方法, 但是还是 Pic2Word 更加简练.
代码
[official-code]