一、实验目的
了解词法分析程序的两种设计方法:
- 根据状态转换图直接编程的方式;
- 利用DFA编写通用的词法分析程序。(选做)
二、实验内容
1. 根据状态转换图直接编程
编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。

具体任务有:
- 组织源程序的输入
- 识别单词的类别并记录类别编号和值,形成二元式输出,得到单词流文件
- 删除注释、空格和无用符号
- 发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。
- 对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则填写符号表或常量表并且返回位置。
- 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址
注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值
2.编写DFA模拟程序(选做)
算法如下:
DFA(S=S0,MOVE[ ][ ],F[ ],ALPHABET[ ])
/*S为状态,初值为DFA的初态,MOVE[ ][ ]为状态转换矩阵,F[ ] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[ ][ ] 中列标题的字母顺序一致。*/
{
Char Wordbuffer[10]=“”//单词缓冲区置空
Nextchar=getchar();//读
i=0;
while(nextchar!=NULL)//NULL代表此类单词
{ if (nextchar!∈ALPHABET[]) {ERROR(“非法字符”),return(“非法字符”);}S=MOVE[S][nextchar] //下一状态if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误wordbuffer[i]=nextchar ; //保存单词符号i++;nextchar=getchar();
}
Wordbuffer[i]=‘\0’;
If(S∈F)return(wordbuffer); //接受Else return(“不接受”);
}
该算法要求:实现DFA算法,给定一个DFA(初态、状态转换矩阵、终态集、字母表),调用DFA(),识别给定源程序中的单词,查看结果是否正确。
三、实验要求
1. 能对任何S语言源程序进行分析(S语言定义见下面)
在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。
2.能检查并处理某些词法分析错误
词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。
本实验要求处理以下两种错误(编号分别为1,2):
- 非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。
- 源程序文件结束而注释未结束。注释格式为:
/* …… */
四、S语言定义
保留字和特殊符号表
| 种别代码type | 单词 | 类别class | 内码值 |
|---|---|---|---|
| 1 | int | 关键字 | |
| 2 | char | 关键字 | |
| 3 | float | 关键字 | |
| 4 | void | 关键字 | |
| 5 | const | 关键字 | |
| 6 | if | 关键字 | |
| 7 | else | 关键字 | |
| 8 | for | 关键字 | |
| 9 | while | 关键字 | |
| 10 | switch | 关键字 | |
| 11 | break | 关键字 | |
| 12 | begin | 关键字 | |
| 13 | end | 关键字 | |
| 14 | - | 运算符 | |
| 15 | / | 运算符 | |
| 16 | <= | 运算符 | |
| 17 | + | 运算符 | |
| 18 | * | 运算符 | |
| 19 | % | 运算符 | |
| 20 | < | 运算符 | |
| 21 | > | 运算符 | |
| 22 | >= | 运算符 | |
| 23 | == | 运算符 | |
| 24 | != | 运算符 | |
| 25 | /= | 运算符 | |
| 26 | += | 运算符 | |
| 27 | -= | 运算符 | |
| 28 | %= | 运算符 | |
| 29 | *= | 运算符 | |
| 30 | || | 运算符 | |
| 31 | && | 运算符 | |
| 32 | ! | 运算符 | |
| 33+1 | [ | 界符 | |
| 34+1 | ] | 界符 | |
| 35 | , | 界符 | |
| 36 | ) | 界符 | |
| 37 | ( | 界符 | |
| 38 | ; | 界符 | |
| 39+1 | 整形 | 整形 | 在常数表中的位置 |
| 40+1 | 标识符 | 标识符 | 在符号表中的位置 |
| 33 | = | 运算符 | |
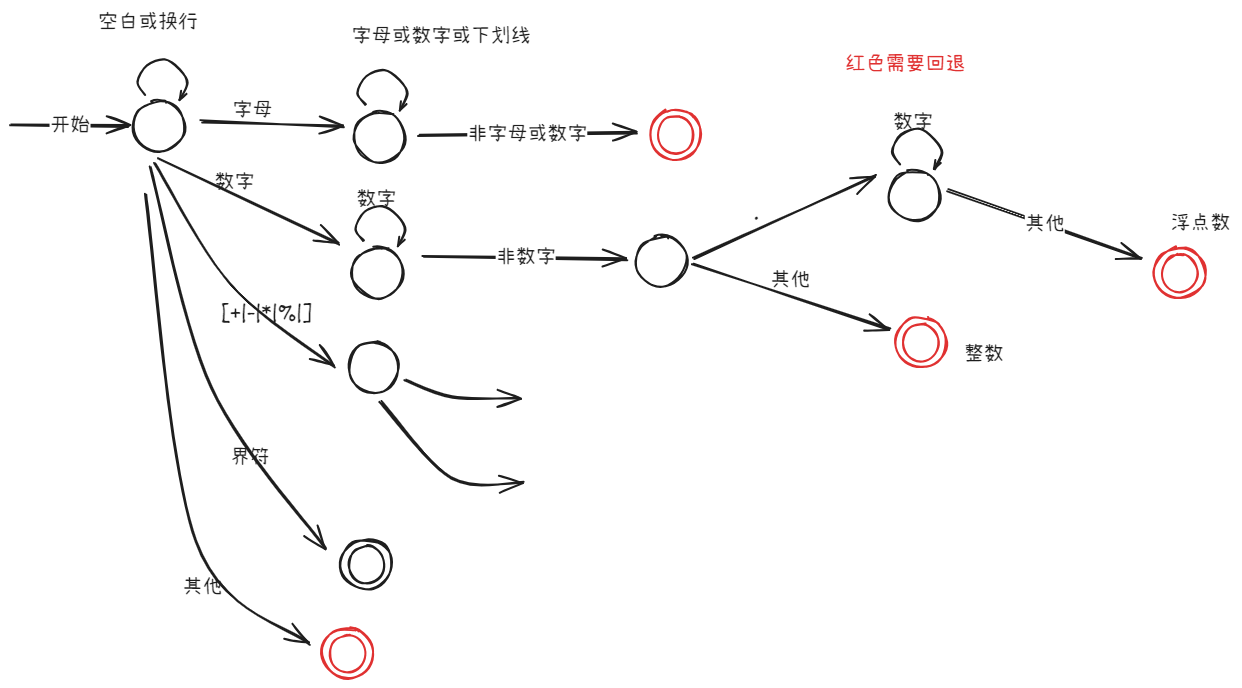
| 单词的构词规则: |
- 字母=
[A-Z a-z] - 数字=
[0-9] - 标识符=`(字母|)(字母|数字|)*
- 数字=
数字(数字)*( .数字+|ε)
S语言表达式和语句说明
1.算术表达式:+、-、*、/、% 2.关系运算符:>、>=、<、<=、==、!=
3.赋值运算符:=,+=、-=、*=、/=、%= 4.变量说明:类型标识符 变量名表; 5.类型标识符:int char float 6.If语句:if 表达式then 语句 [else 语句] 7.For语句:for(表达式1;表达式2;表达式3) 语句 8.While语句:while 表达式 do 语句`
9.S语言程序:由函数构成,函数不能嵌套定义。
函数格式为:
返回值 函数名(参数)
begin数据说明语句
end
复合语句构成
begin语句序列
end
五、程序结构参考说明
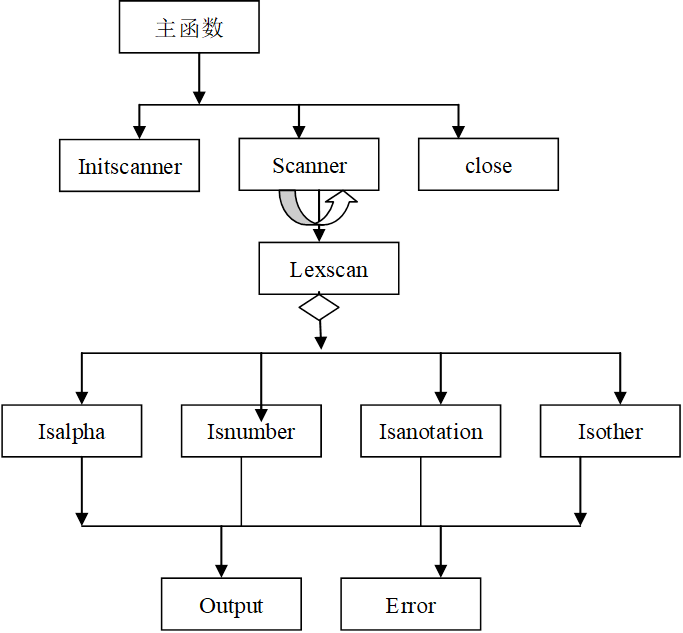
1.Initscanner函数:程序初始化:输入并打开源程序文件和目标程序文件,初始化保留字表
2.Scanner函数:若文件未结束,反复调用lexscan函数识别单词。
3.Lexscan函数:根据读入的单词的第一个字符确定调用不同的单词识别函数
4.Isalpha函数:识别保留字和标识符
5.Isnumber函数:识别整数,如有精力,可加入识别实数部分工功能
6.Isanotation函数:处理除号/和注释
7.Isother函数识别其他特殊字符
8.Output函数:输出单词的二元式到目标文件,输出格式(单词助记符,单词内码值),如(int,-)(rlop,>)……
9.Error函数:输出错误信息到屏幕
10.除此之外,还可以设置查符号表,填写符号表等函数,学生可自行设计。
六、实现
```c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>// 记录已识别的单词
int node_num = 0;
int line = 1;
char buf[1024];// 四元组
typedef struct Node{int type; // 种别代码 最小的分类单位char name[10]; // 变量名int* addr; // 变量地址int line; // 第几行
} Node;Node nodes[1024] = {};/** 这一块是表的等价,如果需要添加或修改关键字,只需要改动一下代码,解耦*/
// 保留字和特殊符号
// 关键字表(共13个)
char keyword[][10] = {"int", // 1"char", // 2"float", // 3"void", // 4"const", // 5"if", // 6"else", // 7"for", // 8"while", // 9"switch", //10"break", //11"begin", //12"end" //13
};// 运算符表(共19个)
char calculation[][10] = {"-", //14"/", //15"<=", //16"+", //17"*", //18"%", //19"<", //20">", //21">=", //22"==", //23"!=", //24"/=", //25"+=", //26"-=", //27"%=", //28"*=", //29"||", //30"&&", //31"!" //32"=" // 41
};// 界符表(共6个)
char delimiter[][10] = {"[", //33"]", //34",", //35")", //36"(", //37";" //38
};// 分别表示关键字、界符、运算符的个数
int nk = sizeof(keyword) / sizeof(keyword[0]);
int nd = sizeof(delimiter) / sizeof(delimiter[0]);
int nc = sizeof(calculation) / sizeof(calculation[0]);
// 分别是关键字、界符、运算符、整形、标识符在表中的偏移量 offset偏移o make标识符m 整形i
int ok = 1, oc = 14, od = 34, oi = 40, om = 41;// -----函数声明-------
// 判断是否是整数
bool is_integer(char ch){return ch >= '0' && ch <= '9';
};
// 判断是否字母
bool is_character(char ch){return ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z';
}// 判断字符串是否是关键字,是则返回下标,否则返回-1;不是关键字 则为标识符
int keyword_index_of(const char s[]){for (int i = 0; i < nk; i++){if(strcmp(s,keyword[i]) == 0){return i;};}return -1;
};
// 判断字符串是否纯字母
bool is_pureCharacter(const char s[], int len){bool flag = true;for (int i = 0; i < len; i++){if (!is_character(s[i]))flag = false;}return flag;
}// 判断是否界符,是则返回下标,否则返回-1
int delimiter_index_of(char ch){for (int i = 0; i < nd; i++)if (ch == delimiter[i][0])return i;return -1;
};// 根据种别代码范围判断类别
char* getClassStr(int n){static char name[20];if (n >= ok && n <= ok + nk - 1) strcpy(name, "关键字");else if (n >= oc && n <= oc + nc - 1) strcpy(name, "运算符");else if (n >= od && n <= od + nd - 1) strcpy(name, "界符");else if (n == oi) strcpy(name, "整形");else if (n == om) strcpy(name, "标识符");else strcpy(name, "未识别");return name;
}// offset nodes数组元素偏移量,识别一行的单词,返回单词数量
int Lexscan(const char* s, Node* srcNode){Node* node = srcNode;char tokens[20];int i = 0; //记录token起止 i为开始 j为偏移量// 注意 fgets的末尾,\0结尾while (s[i] != '\0'){int j = 0;// "自旋"while (s[i] == '\n' || s[i] == '\r' || s[i] == '\t' || s[i] == ' '){i++;}if (s[i] == '\0') break; // !!!! 可能空格后没有单词// 字母 下划线始if (is_character(s[i]) || s[i + j] == '_'){j++;while (is_character(s[i + j]) || is_integer(s[i + j]) || s[i + j] == '_'){j++;}// 非字母下划线数字j--;if (is_pureCharacter(s + i, j + 1)){strncpy(tokens, s + i, j + 1);tokens[j + 1] = '\0';// 如果纯字母,判断是否关键字int index = keyword_index_of(s + i);if (index != -1){// 是关键字strcpy(node->name, tokens);node->type = index + ok;node++;i = j + 1;// printf("(%s, 关键字, %d)\n", tokens, node->type);continue;}}// 是标识符strncpy(tokens, s + i, j + 1);tokens[j + 1] = '\0';node->type = om;strncpy(node->name, tokens, j + 1);node->name[j + 1] = '\0';node->line = line;node++;// printf("(%s, 标识符, %d)\n", tokens, om);i += j + 1;}// 数字else if (is_integer(s[i])){j++;while (is_integer(s[i + j])){j++;}// 非数字j--;strncpy(node->name, s + i, j + 1);node->type = oi;node->line = line;node++;i += j + 1;}// 运算符else if (s[i] == '-'){if (s[i + 1] == '='){j++;strcpy(tokens, "-=");tokens[j + 1] = '\0';strncpy(node->name, s + i, j + 1);node->type = 27;}else{strcpy(tokens, "-");tokens[j + 1] = '\0';strncpy(node->name, s + i, j + 1);node->type = 14;}node->line = line;i += j + 1;node++;}else if (s[i] == '/'){if (s[i + 1] == '='){j++;strcpy(tokens, "/=");tokens[j + 1] = '\0';strncpy(node->name, s + i, j + 1);node->type = 25;}else{strcpy(tokens, "/");tokens[j + 1] = '\0';strncpy(node->name, s + i, j + 1);node->type = 15;}node->line = line;i += j + 1;node++;}else if (s[i] == '<'){if (s[i + 1] == '='){strcpy(tokens, "<=");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 16;i += 2;}else{strcpy(tokens, "<");tokens[1] = '\0';strncpy(node->name, s + i, 1);node->type = 20;}node->line = line;node++;}else if (s[i] == '+'){if (s[i + 1] == '='){j++;strcpy(tokens, "+=");tokens[2] = '\0';strncpy(node->name, s + i, j+1);node->type = 26;}else{strcpy(tokens, "+");tokens[1] = '\0';strncpy(node->name, s + i, j+1);node->type = 17;}node->line = line;i += j+1;node++;}else if (s[i] == '*'){if (s[i + 1] == '='){j++;strcpy(tokens, "*=");tokens[2] = '\0';strncpy(node->name, s + i, j+1);node->type = 29;i += j+1;}else{strcpy(tokens, "*");tokens[1] = '\0';strncpy(node->name, s + i, j+1);node->type = 18;i+=j+1;}node->line = line;node++;}else if (s[i] == '%'){if (s[i + 1] == '='){strcpy(tokens, "%=");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 28;i += 2;}else{strcpy(tokens, "%");tokens[1] = '\0';strncpy(node->name, s + i, 1);node->type = 19;i+=1;}node->line = line;node++;}else if (s[i] == '>'){if (s[i + 1] == '='){strcpy(tokens, ">=");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 22;i += 2;}else{strcpy(tokens, ">");tokens[1] = '\0';strncpy(node->name, s + i, 1);node->type = 21;i+=1;}node->line = line;node++;}else if (s[i] == '='){if (s[i + 1] == '='){strcpy(tokens, "==");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 23;i += 2;}else{strcpy(tokens, "=");tokens[1] = '\0';strncpy(node->name, s + i, 1);node->type = 33;/* 适当的类型编号 */i+=1;}node->line = line;node++;}else if (s[i] == '!'){if (s[i + 1] == '='){strcpy(tokens, "!=");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 24;i += 2;}else{strcpy(tokens, "!");tokens[1] = '\0';strncpy(node->name, s + i, 1);node->type = 32;i+=1;}node->line = line;node++;}else if (s[i] == '&' && s[i + 1] == '&'){strcpy(tokens, "&&");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 31;node->line = line;node++;i += 2;}else if (s[i] == '|' && s[i + 1] == '|'){strcpy(tokens, "||");tokens[2] = '\0';strncpy(node->name, s + i, 2);node->type = 30;node->line = line;node++;i += 2;}// 界符else if (delimiter_index_of(s[i]) != -1){int index = delimiter_index_of(s[i]);strncpy(tokens, s + i, 1);tokens[1] = '\0';strncpy(node->name, tokens, 1);node->name[1] = '\0';node->type = od + index;i += strlen(delimiter[index]);// printf("(%s, 界符, %d)\n", delimiter[index], node->type);node->line = line;node++;}else{printf("未知符号: %d\n", (int)s[i]);perror("Lexscan Error");exit(0);}}return node - srcNode;
}// 扫描函数
int Scanner(FILE* fp, Node* nodes){char text[1024] = {};int Maxline = sizeof(text) / sizeof(text[0]) - 1;int num = 0;while (fgets(text, Maxline, fp) != NULL){int len = strlen(text);// printf(">>>识别第 %d 代码: %s", line++, text);num += Lexscan(text, nodes + num);line++;}printf("识别出:%d 单词\n", num);for(int i=0;i<num;i++){printf("(%s, %s, %d, %d)\n", nodes[i].name, getClassStr(nodes[i].type), nodes[i].type,nodes[i].line);}return num;
}int main(){char in_file[100] = "../test.txt";char out_file[100] = "out.txt";FILE *fpin, *fpout;printf("<<<<<<<<<<<<WELCOME>>>>>>>>>>>>\n");fpin = fopen(in_file, "r");if (fpin == NULL){perror("Error opening input file");return 1;}fpout = fopen(out_file, "w");if (fpout == NULL){perror("Error opening output file");fclose(fpin);return 1;}node_num = Scanner(fpin, nodes);fclose(fpin);fclose(fpout);return 0;
}