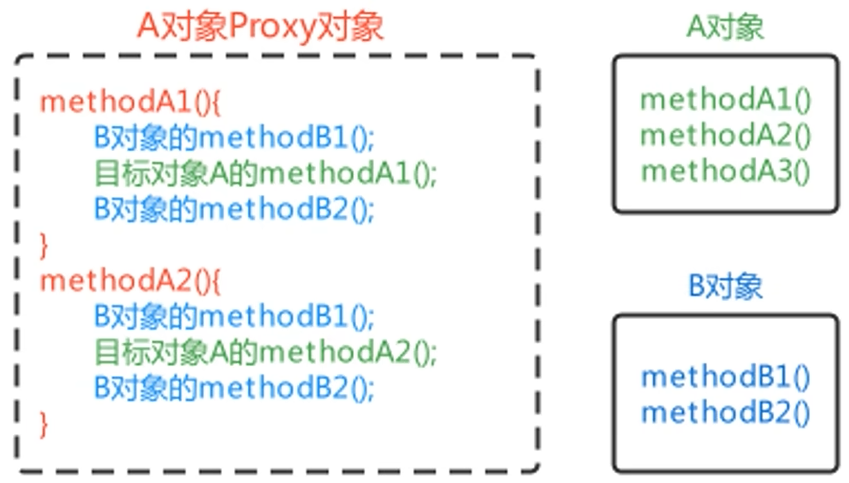
一、部署环境准备
系统信息:
- 主机名为 10-200-3-23
- IP 地址为 10.200.3.23
- 操作系统为 ubuntu 22.04
- 配备 8 卡 A100。
二、驱动与桥接器安装
- 安装 gcc
执行命令
apt-get update -y
apt install build-essential -y
- 安装驱动
下载驱动
wget https://us.download.nvidia.com/tesla/560.35.03/NVIDIA-Linux-x86_64-560.35.03.r un。
运行安装命令
sh NVIDIA-Linux-x86_64-560.35.03.run,注意在交互式安装时确认安装 32 位兼容库并 Rebuild initramfs。
- 安装桥接器
确保桥接器版本与驱动版本完全一致(包括次版本),下载桥接器
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/nvidia-fabricmanager-560_560.35.03-1_amd64.deb。
安装桥接器
dpkg -i nvidia-fabricmanager-560_560.35.03-1_amd64.deb,并执行 systemctl enable nvidia-fabricmanager --now 和 systemctl status nvidia-fabricmanager。
重启服务器后配置持久模式
nvidia-smi -pm 1
三、docker 安装与配置
- 安装 docker
安装必要系统工具 sudo apt-get update 和 sudo apt-get install ca-certificates curl gnupg。
信任 Docker 的 GPG 公钥,执行一系列命令如 sudo install -m 0755 -d /etc/apt/keyrings 等。
写入软件源信息,将相关内容通过 echo 命令写入 /etc/apt/sources.list.d/docker.list。
安装 Docker
sudo apt-get update 和 sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin,也可安装指定版本。
配置 docker 使用 nvidia-runtime-toolkit
执行 curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dear mor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg 和后续相关命令下载配置文件并修改软件源信息。
执行 apt update -y 和 apt install -y nvidia-container-toolkit nvidia-container-runtime。
在 /etc/docker/daemon.json 中添加配置 {"default-runtime": "nvidia","runtimes": {"nvidia": {"path": "/usr/bin/nvidia-container-runtime","runtimeArgs": []}}},然后重启 docker systemctl restart docker。
四、镜像与模型获取
- 获取镜像
构建 vllm 镜像,示例 Dockerfile 为 FROM docker.m.daocloud.io/nvidia/cuda:12.6.3-runtime-ubuntu22.04 等,通过 docker build -t vllm:v0.7.2. 构建。
获取 open-webui 镜像 docker pull ghcr.m.daocloud.io/open-webui/open-webui:main。
- 获取模型
创建 /data 目录,进入该目录后执行 git lfs install 和 git clone https://www.modelscope.cn/cognitivecomputations/DeepSeek-R1-awq.git 下载 deepseek-r1-awq 模型。
五、项目部署
- 部署 deepseek
docker run -d --runtime nvidia --gpus all -v /data:/mnt/models -p 12345:12345 --ipc=host hub.wanjiedata.com/models/vllm:v0.7.2 python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 12345 --max-model-len 65536 --trust-remote-code --tensor-parallel-size 8 --quantization moe_wna16 --gpu-memory-utilization 0.97 --kv-cache-dtype fp8_e5m2 --calculate-kv-scales --served-model-name deepseek-reasoner --model /mnt/models/DeepSeek-R1-AWQ
- 部署 open-webui
docker run -d -p 3030:8080 -e ENABLE_OLLAMA_API=false -e OPENAI_API_KEY=NULL -e OPENAI_API_BASE_URL=http://10.200.3.23:12345/v1 -e ENABLE_RAG_WEB_LOADER_SSL_VERIFICATION=false -v open-webui:/app/backend/data --name open-webui --restart always ghcr.m.daocloud.io/open-webui/open-webui:main


![P2661 [NOIP 2015 提高组] 信息传递——染色做法](/file/50/qpaXZlN2J8nQPPkHxHnED.png)