ollama
ollama配置环境变量

ollama地址与镜像
C:\Users\DK>curl http://10.208.10.240:11434
Ollama is running
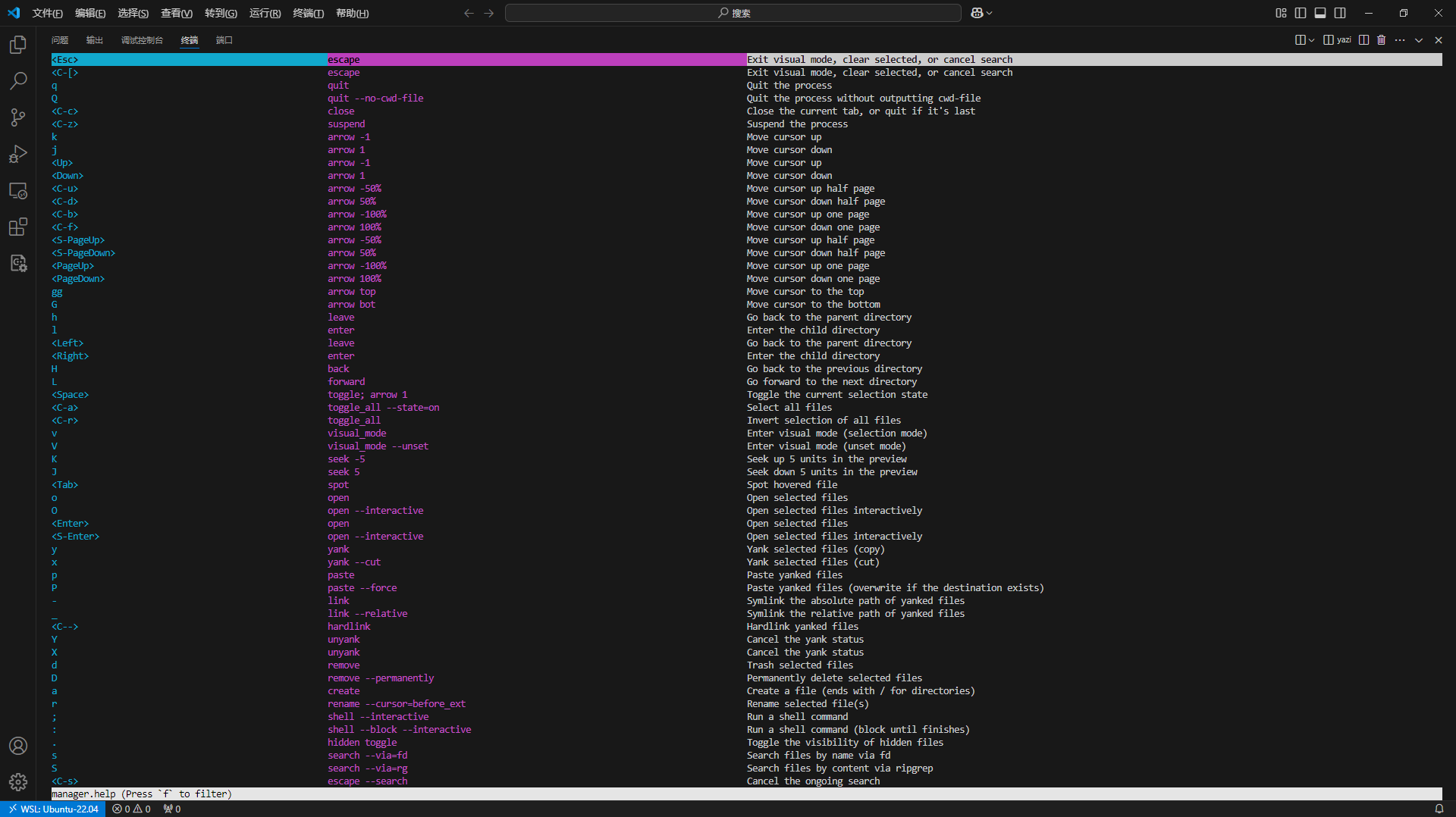
C:\Users\DK>ollama list
NAME ID SIZE MODIFIED
bge-m3:latest 790764642607 1.2 GB 28 hours ago
deepseek-coder-v2:latest 63fb193b3a9b 8.9 GB 2 days ago
gemma:latest a72c7f4d0a15 5.0 GB 2 days ago
qwen:14b 80362ced6553 8.2 GB 2 days ago
llama3:latest 365c0bd3c000 4.7 GB 2 days ago
deepseek-r1:70b 0c1615a8ca32 42 GB 2 days ago
nomic-embed-text:latest 0a109f422b47 274 MB 3 days ago
deepseek-r1:32b 38056bbcbb2d 19 GB 3 days ago
deepseek-r1:14b ea35dfe18182 9.0 GB 3 days agoC:\Users\DK>
参数的基本概念
大模型中的token
token 是模型输入和输出的基本单位。它通常代表一段文本的某个小部分,例如单词、字符或子词(subword)。在自然语言处理(NLP)中,token化(tokenization)是将文本分解为这些基本单元的过程。在许多现代语言模型(如GPT系列)中,一个token可能是一个词、部分单词、标点符号或一个字母。1. 本地AI大模型的token设置
在本地部署AI大模型时,token的设置通常由模型的架构和训练配置决定。设置token数量时的一个关键考虑是显存(GPU memory)和推理性能之间的平衡:
token数量越高,处理的上下文越多:增加token数量可以使模型能够考虑更长的文本上下文,可能有助于提高模型的表现,尤其在处理长文档或复杂推理任务时。
显存需求增加:然而,token数量越高,需要的计算资源(尤其是显存)就越多。GPU显存有限,因此增加token数量可能导致内存不足,特别是在本地部署时。1. token设置的影响
通常,token的设置并不是越高越好,而是需要根据任务的性质和硬件资源来优化:
对于短文本或较简单的任务,较低的token数量可能已经足够,甚至有助于提高处理速度。
对于长文本或需要复杂推理的任务,增加token数量可能会提升模型的表现,但需要确保有足够的硬件资源来支撑。
每个模型定义的token不一样,有的可以扩容有的不行
本地大模型附带RAG
RAG(检索增强生成)是一种结合了外部知识库的生成模型。它通过从知识库中检索相关信息,并基于这些信息生成回答。这种方式通常提高了生成模型的知识范围和准确性。在这种情况下,token设置可能受到以下因素的影响:输入token的限制:RAG模型的输入通常包含两部分:一个是查询文本,另一个是从知识库中检索到的文档。在设置token数量时,必须同时考虑查询文本和检索的文档的总token数。过多的token可能会导致超出模型的最大上下文长度限制,尤其是当知识库中包含较大文档时。
知识库大小和文档长度:如果知识库中的文档非常长,需要确保有足够的token来处理这些内容,同时也要平衡查询和检索信息的token数量。
因此,对于包含RAG知识库的大模型,token的设置应根据以下考虑:查询文本的长度:查询通常是问题或请求,需要设置足够的token来表示查询信息。
文档的上下文:从知识库检索到的文档也会占用token,确保模型能处理这些信息。
硬件资源的限制:提高token数量虽然可以提高生成的上下文,但也会增加内存使用,可能导致性能下降或显存溢出。
token数量的设置是一个平衡:需要根据任务复杂度、硬件资源和模型能力来合理选择。对于包含RAG知识库的模型,还需考虑文档检索和查询文本的合适token配比。
显存的计算
每个token的显存占用:每个token的显存占用通常在 0.5MB到1MB 左右,具体取决于实现和优化。
以0.7MB每个token计算,10240token的显存需求大约为: 10240tokens x 0.7MB/token = 7168MB 约7GB
14B模型 的显存需求已经达到 10GB到20GB 左右
大约27GB的显卡可以带动 10240token + 14B模型
RAG,文件上传的越多。大模型的token就必须设置的越大
Max Embedding Chunk Length
文本的平均长度与分块策略
文本长度:如果大多数文本都较短,设置更小的 Max Embedding Chunk Length(比如1024或2048)可以提高处理效率。这有助于在不需要处理整个长文本的情况下,快速完成嵌入计算。
长文本:如果你的文本普遍较长,设置 4096 或更大的 Max Embedding Chunk Length 可以减少不必要的切割,避免频繁分块带来的额外计算开销。计算效率与内存消耗
每个token占用的内存是固定的,但文本切割成多个块时,内存和计算消耗会成倍增加。因此,在设置时需要平衡 计算效率 和 内存消耗。
较小的块大小(如1024 token) 可以提高计算的并行性,但需要更多的计算和内存资源来处理多个块。
较大的块大小(如4096 token) 减少了块的数量,可能会提高效率,但也会增加每个块的处理负担,特别是在GPU显存有限的情况下。对于一个 1000字的中文文档,确实不需要将其分成 4096 tokens 大块。如果希望减少GPU功耗和显存消耗,使用较小的块(如 512 token 或 1024 token)是一个更优的选择。这样做可以在保证计算效率的同时降低资源消耗,尤其是在需要处理大量文档时效果更为明显。
配置Anythingllm
docker运行
export STORAGE_LOCATION="$HOME/anythingllm" \
&& mkdir -p "$STORAGE_LOCATION" \
&& touch "$STORAGE_LOCATION/.env" \
&& docker run -d -p 3001:3001 \--cap-add SYS_ADMIN \-v "$STORAGE_LOCATION:/app/server/storage" \-v "$STORAGE_LOCATION/.env:/app/server/.env" \-e STORAGE_DIR="/app/server/storage" \--privileged \--restart unless-stopped \--memory 64g --cpus 32 \mintplexlabs/anythingllm
进入anythingllm配置模型全局选项

要做rag这里的token可以高一点
嵌入数据库可以将上传的文件变为向量存在向量数据库里,向量数据库为默认LanceDB

最大切块为2048降低GPU效率,我上传的简历没有特别大的文件

预指令必须设置。且把聊天模式改为查询增加查询文档精确度

增加向量数据库准确性

增加文件到rag
deepseek7b对话测试

大体方向不会错,会有小错误且嘴硬
张亮英语流利是7B编的
王芳不是中专
张伟编了工作经验
以文档出现的腾讯工作经验对峙,仍然嘴硬
deepseek:14b的失误更少,非常不错,14B适合rag

token在rag中的设置非常重要,过小的token,会让deepseek胡言乱语
其他事项
RAG 检索出来的东西会变成上下文context
大模型会各具特色注意大模型自身token大小和与中文适配度
嵌入式模型不一样会导致嵌入质量不一样
小图钉,固定文档,增加优先级
聊天提示词非常重要,下定义:
你是一位核电的资料员,曾就职于漳州核电,现从事核电资料管理工作。使用知识库回答问题,并用中文回答,必须中文。如果你不知道答案,就直说不知道。不要尝试编造答案。
温度越高,创新度越高。越低越简洁、简短,越接近事实
最大上下文片段。上下文片段是指在数据向量化过程中,将文本拆分成多大。建议将片段数量保持在4-6,以壁面信息过载和干扰。片段的大小和数量会影响模型的理解和生成能力。过多片段可能导致模型混淆,而过少的片段可能无法提供足够的信息。例子百个菜谱要3个高热菜谱会被拒绝
开启精确优化
文档相似性阈值考虑设置为高,排除低质量文本片段
分块大小