首先,RNN是逐个处理词元的,这个部分应该是指传统的RNN模型,比如LSTM或GRU,它们是按时间步依次处理输入序列的,每个时间步只处理一个词元,并且当前的输出依赖于前一个时间步的隐藏状态。所以它的处理是顺序的,不能同时处理后面的词元,必须一个接着一个来。这样做的好处是能够捕捉到序列中的时间依赖关系,比如语言中的语法结构或者上下文信息。不过这样顺序处理的方式可能会导致训练速度比较慢,尤其是当序列很长的时候,计算时间会随着序列长度线性增长。
而自注意力机制则是基于并行计算的,它放弃顺序操作这一点应该怎么理解呢?自注意力机制的核心思想是让每个词元都能够同时注意其他所有词元,而不是像RNN那样逐个处理。这样的话,不管序列有多长,都可以在一次操作中同时计算所有词元之间的关系。比如说,对于一个句子中的每个单词,自注意力机制可以一次性计算出它与其他所有单词的相互影响,这样在训练时可以更高效地利用计算资源,减少时间成本。
举个例子,比如处理一句话“我 爱 吃 苹果”,RNN会先处理“我”,然后拿着“我”的状态去处理“爱”,接着依次处理“吃”和“苹果”。而自注意力机制则会同时处理这四个词,每个词都会同时考虑其他三个词对自己的影响,所以它们的处理是并行的,不需要按顺序一步一步来。
不过,自注意力机制虽然在并行能力上更强,但它牺牲了顺序操作的特点,也就是说它不显式地保留序列的顺序信息。比如,对于序列中的每个词来说,虽然它能一次性关注到所有其他词,但顺序上的先后关系需要通过其他方式来编码,比如在Transformer模型中,会使用位置编码来为每个词元加入位置信息。而RNN因为逐个处理,天然就保留了词元的顺序。
10.6.1 自注意力
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/889013.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

跟着狂神学markdown作业01天
markdown学习
标题
一共可以做六级标题 格式为#+空格+标题 几级标题就打几个空格
字体
粗体:hello,world
两边各加两个*号
斜体:hello,world
两边各加一个*号
粗体+斜体:hello,world
两边各加三个***号
删除效果:hello,world
引用选择狂神说java,走向人生巅峰(用>…

java知识面试day4
1.常见的关键字有哪些static:静态变量,静态变量被所有对象共享,在内存中只有一个副本。具有静态变量,静态方法块,静态代码块(在类加载时候被指执行一次),静态内部类:非静态内部类需要依赖外部实列,但静态内部类不需要。final 基本数据类型用final修饰不能修改,引用对象被…
![[QOJ 8366] 火车旅行](https://img2024.cnblogs.com/blog/3584318/202502/3584318-20250224140737540-1060414145.png)
[QOJ 8366] 火车旅行
毒瘤边化点,有人说非排列只需要加一些细节,但是这个题毒瘤在于非排列。
statement
给定一个长度为 \(n\) 的序列 \(a_i\)。
对于位置 \(x\) 和 \(y\):若 \(y < x\) 且 \(max_{y < i < x} a_i < min(a_x, a_y)\) 则位于 \(x\) 的棋子可以花费 \(L_x\) 的代价跳到…
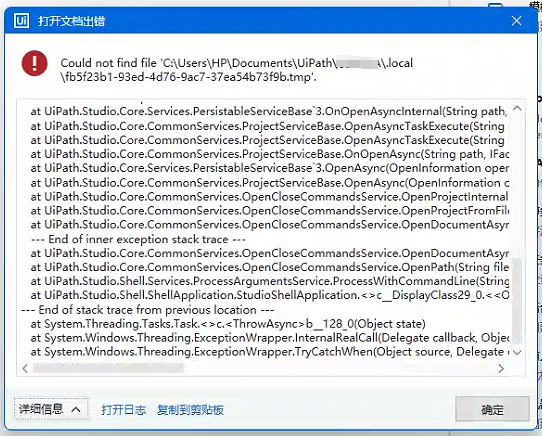
uipath更新到最新版本2025.0.161出现严重问题
uipath更新到最新版本2025.0.161出现严重问题:1. 打开既有项目,会报CS0246错误2. 无法创建新项目,一直报无权限访问尝试办法:1. 重新安装uipath,未解决2. 删除项目重新添加,未解决3. 给账户添加最高权限,未解决
workaround:把项目从默认文件夹复制到其他盘(除了C盘外…

Python正则表达式之re.compile函数
在Python编程语言中,re.compile函数是正则表达式模块(re)中的一个核心组件,它负责将文本形式的正则表达式编译成一个正则表达式对象。这个对象随后可以被用来执行高效的模式匹配操作,如查找、替换或者分割字符串等。理解并有效利用 re.compile对于编写高效且可维护的正则表…
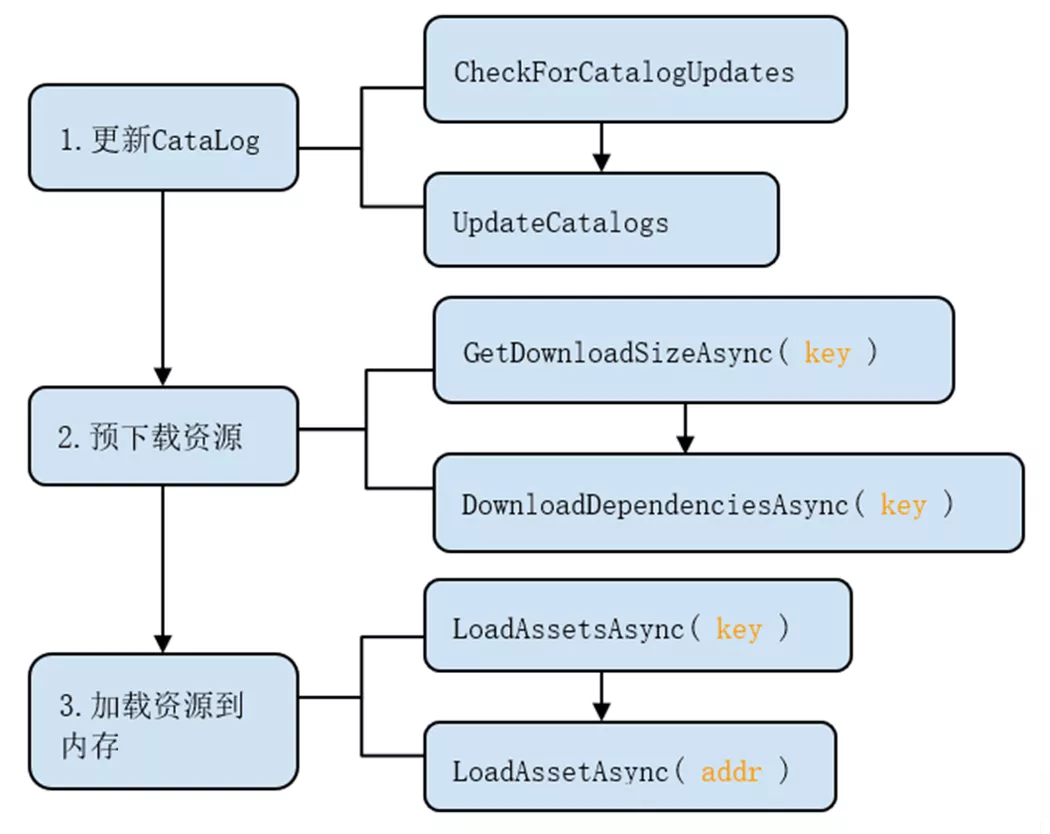
Unity Addresable打包总结第二弹
前言
前文介绍了Addressables在本地打包是怎么使用,这里介绍下怎么打远程包,并且怎么做到打增量包,Lets Go!
远程包新建一个Group,将它的 BUild & Load Paths 改为Remote,并将RemoteRes资源文件夹塞入Remote Group,其中包含一个Capsule.prefab资源:在Addressabvles …
![BUUCTF-RE-[2019红帽杯]easyRE](https://img2024.cnblogs.com/blog/3596699/202502/3596699-20250224131420256-1314204608.png)
BUUCTF-RE-[2019红帽杯]easyRE
这道题很难,但是并不难在他的解题要用到的方法和技巧上,而是难在它的题目设计。做的过程中真的有一种闯关的感觉,非常有趣
首先我们通过对字符的定位我们可以来到sub_4009C6函数
__int64 sub_4009C6()
{__int64 result; // raxint i; // [rsp+Ch] [rbp-114h]__int64 v2; // …

2025年免费项目管理软件哪家强?5款零成本工具实测报告
在项目管理领域,众多团队尤其是初创企业和小型项目组,都渴望找到功能实用且零成本的软件来助力项目推进。2025 年,有 5 款免费项目管理软件表现突出,它们分别是禅道、Trello、Asana、Redmine 以及国内新兴的钉钉项目管理相关功能,下面将为大家带来详细的实测报告。一、禅道…
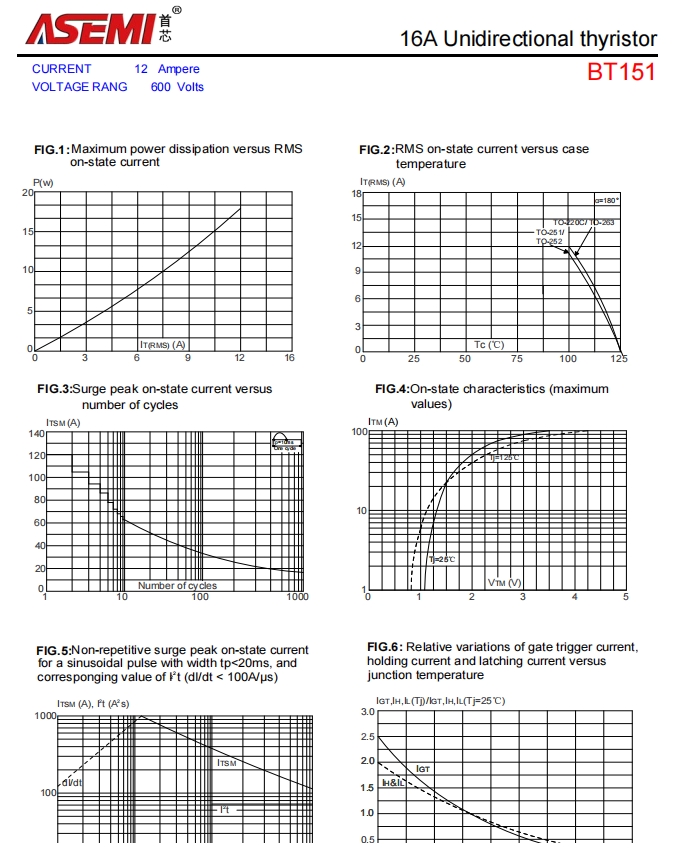
BT151-ASEMI电机控制专用BT151
BT151-ASEMI电机控制专用BT151编辑:ll
在当今科技飞速发展的时代,电子元件宛如繁星般点缀着各个领域,而 BT151 单向可控硅无疑是其中一颗极为耀眼的明星。
BT151-ASEMI电机控制专用BT151
型号:BT151
品牌:ASEMI
封装:TO-220F
正向电流:12A
反向电压:600V~800V
引脚数量…
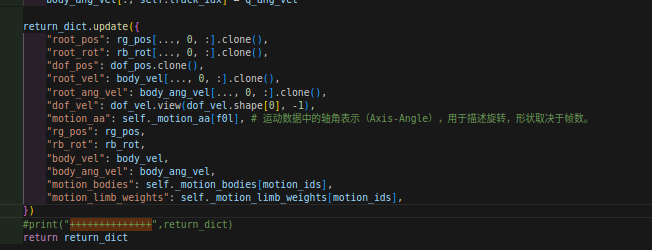
【H2O系列】关于H2O和OmniH2O代码安装及代码解读摘要`
0. 前言
这篇博客主要用于过程记录H2O代码部分的参数解读部分。
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
1. 论文&项目
项目地址:https://omni.human2humanoid.com/
我自己总结的论文摘要…
1小时搭建好的智能车间生产看板长什么样?
大家一提到生产看板搭建,可能脑袋里第一反应就是“哎,这个得花大钱买专业软件吧”或者“搭建起来肯定超级复杂”。
其实,真没那么难!
只要找对方法,学会用对工具,搭建一套生产看板其实很简单。
那天,我就亲自试了一下,结果不到两三小时,就做出了一套智能生产看板。
但…