探秘Transformer系列之(6)--- token
0x00 概述
语言是人类特有的概念。作为一个抽象符号,人是可以理解每个语言单词的意义的,但是现在的NLP语言模型无法直接的从感知中抽象出每个语言符号的意义。为了让模型能够理解自然语言文本,需要把文本转换为模型可以理解的表征,比如整数、浮点数或者向量。
从前面章节我们可以知道,Transformer接受的是高维向量(word embedding),而从文本到向量的转换分为两个阶段:分词和embedding化,分别产出token和word embedding。在构建大模型的过程中,token 分词与word embedding扮演着举足轻重的角色。它们不仅是模型理解文本语言的基础,还深刻影响着模型的性能与精度。本篇会介绍如何做好单词到数字的映射,下一篇介绍如何从数字转换到embedding。
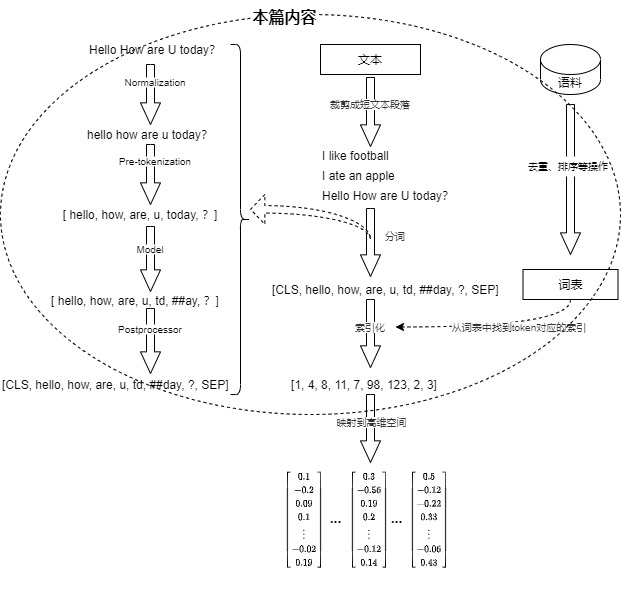
以机器翻译(中译英)为例,我们来概述下一段输入文本在转化为embedding之前都经历了什么(以及开发者做了哪些准备),具体流程如下:
-
建立中文词表和英文词表。此步骤会把语料库中的文字去重、然后排序之后就可以得到词汇表。每个字符在词表中有唯一序号。
-
整理文本。此步骤会把段落等裁剪成短文本。
-
分词。将连续的文本拆分/转换成一个个独立的最小语义单元。生成的每个单元称为token。具体又包括如下几步:
- 规范化(Normalization)。对文本进行必要的清理工作,例如清理特殊符号、格式转换、过滤停用词、Unicode标准化等)。
- 预分词(Pre-tokenization)。将输入拆分为单词。
- 模型处理。把预分词器得到的单词送进分词模型进行分词,得到token序列。
- 后处理(Post-processing)。添加分词器的特殊token,生成注意力掩码等。
此时token仅仅是字符串,还不能直接用于模型的计算。
-
索引化。通过词表将token转换成计算机更容易处理的数字信息。每个token都会去词表中查询,得到该token在词表中的序号,这个序号就是每个token对应的one-hot向量。比如我们可以得到“Hello how are U today”这句话的序号编码为[5, 17, 7, 12, 15]。
总之,经过上述操作之后,每个词汇都被表示为一个整数,一串文本就变成了一串整数组成的向量。然后这个整数向量列表会被转换为更具表达能力的向量形式,以便能够捕获词汇之间的语义关系和特征信息。上面流程在下图中也有对应的展示。
0x01 基础概念
1.1 分词
顾名思义,分词是把一句话分成一个个词。比如按标点符号分词 ,或者按语法规则来分词。Transformer接受的处理是向量,而用户的输入是文本句子,因此需要首先对句子进行分词或者说符号化(tokenize),然后才能生成向量。分词会将输入文本拆分为模型或机器可以处理的小单位,保证各个单位拥有相对完整和独立的语义,并且给每个单元分配一个唯一的标识符,这个标识符我们称之为token(标识符/词元)。比如对于句子“我吃了一个苹果”,分词产生的结果就是一个列表["我","吃了","一个","苹果"],列表每个元素就是一个token。
另外,直接输入完整字符会导致信息丢失或复杂性增加,而分词能保持语义、减少稀疏性,最终提高模型的训练效率和预测准确性。
1.2 token
token(词元):token是分词的结果,也就是最小语义单位,是模型有效理解和管理的单元。token既可以是一个单词、一个汉字,也可能是一个表示空白字符、未知字符、句首字符等特殊字符。
1.3 tokenizer
tokenizer(分词器)的作用就是把原始数据集中的语料按照一定的规则分开,找出具备语义的字符串转换成token,然后把每个token映射到一个整数上。
分词的本质其实就是一个字符到数字的映射,因此tokenizer 需要维护一个类似字典的模块或者功能,该功能或者模块有如下常见方式:基于词典的分词方式、基于统计的分词方式和基于深度学习的分词方式。目前LLM主要是基于词表的分词方式。
1.4 词表
词表是指LLM能够理解和识别的唯一单词或token的集合,是一个由token与数字组成的一个字典(hashmap),用来定义token与整数之间的映射关系。该整数就是此token在词表中的唯一序号,整数的最大范围是词表大小。
词表的基本思想是基于词典匹配,即将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词进行分词,匹配失败则调整或重新选择。在训练模型之前是需要构建好词表的。
下图是哈佛词表的样例。

1.6 分词流程
分词流程主要分为如下几个阶段:标准化、预分词、模型处理和后处理。我们一一介绍。
规范化
规范化是指对文本进行标准化处理,主要包括以下几个方面:
- 文本清洗。比如去除无用字符(比如特殊字符、非打印字符等)和额外空白(多余的空格、制表符、换行符等),只保留对分词和模型训练有意义的内容。
- 标准化写法。比如统一大小写和数字标准化(将所有数字替换为一个占位符或特定的标记,以减少模型需要处理的变量数量)。
- 编码一致性。比如确保文本采用统一的字符编码,处理或转换特殊字符和符号。
- 语言规范化。比如词形还原(Lemmatization)和词干提取(Stemming)。
示例如下:
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents
normalizer = normalizers.Sequence([NFD(), StripAccents()])
normalizer.normalize_str("Héllò hôw are ü?")
预分词
预分词是指在将文本分割成 token 之前的预处理步骤。具体是基于一些简单的规则(如空格和标点)进行初步的文本分割,得到更小的单元(比如单词)。对于英文就是按照空格进行切分,把文本拆分成单词,最终的token将是这些单词的一部分。中文因为没有空格分割,所以一般不需要此步骤。
比如,为了优化多语言的压缩效率,DeepSeek-V3 对预分词器(Pretokenizer)和训练数据进行了专门的调整。与 DeepSeek-V2 相比,新的预分词器引入了将标点符号和换行符组合成新 token 的机制。这种方法可以提高压缩率,但也可能在处理不带换行符的多行输入时引入 token 边界偏差(Token Boundary Bias)。为了减轻这种偏差,DeepSeek-V3 在训练过程中以一定概率随机地将这些组合 token 拆分开来,从而让模型能够适应更多样化的输入形式,提升了模型的鲁棒性。
模型处理
把预分词器得到的单词送进分词模型或者依据词汇表进行分词。具体是在Pre-tokenization的基础上,根据选定的模型或算法(BPE,WordPiece,Unigram或SentencePiece等)进行更细致的处理,包括通过大量文本数据,根据算法规则生成词表, 然后依据词表,将文本拆分为Token。
后处理
后处理阶段是对编码后的文本进行一些额外的处理步骤,以确保编码后的文本符合特定模型的输入要求。后处理主要包括:
- 序列填充与截断:为保证输入序列的长度一致,对过长的序列进行截断,对过短的序列进行填充。
- 特殊Token添加:根据模型需求,在序列的适当位置添加特殊Token(如[CLS], [SEP])。
- 构建注意力掩码:对于需要的模型,构建注意力掩码以区分实际Token和填充Token。
0x02 词表
词表是指LLM能够理解和识别的唯一单词或token的集合。我们接下来先使用哈佛代码来看看如何构建、使用词表。此流程比较复杂,因此绘制下图进行辅助分析。
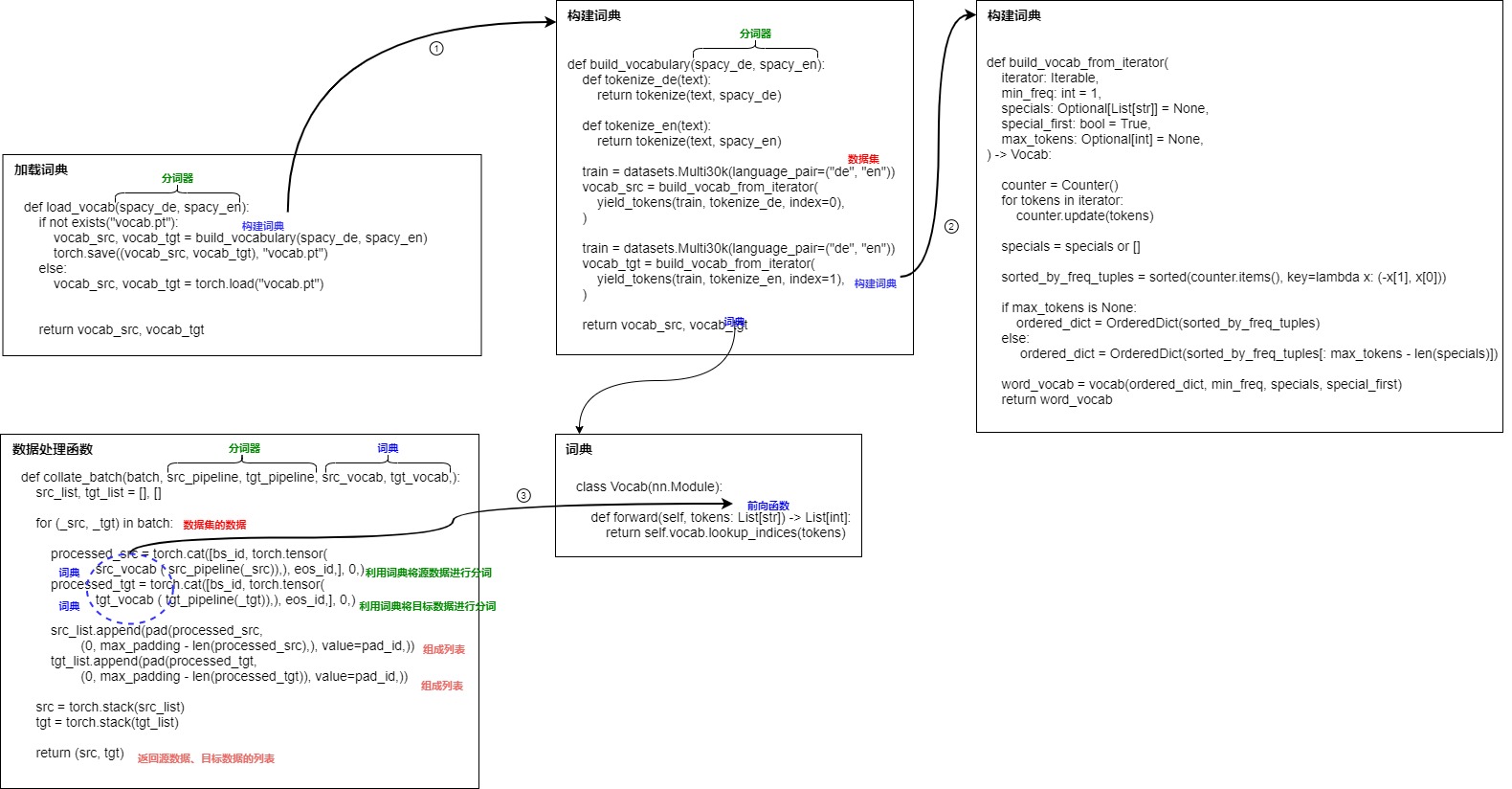
2.1 构建词表
前文简述了如何加载词表,这里看看如何构建词表。build_vocabulary()函数会从数据集中通过迭代器来读取数据,最终返回英语词典和德语词典,两个词典都是Vocab对象。
def build_vocabulary(spacy_de, spacy_en):# 德语分词方法def tokenize_de(text):return tokenize(text, spacy_de)# 英语分词方法def tokenize_en(text):return tokenize(text, spacy_en)# 调用datasets.Multi30k得到三个Iteratorprint("Building German Vocabulary ...")train, val, test = datasets.Multi30k(language_pair=("de", "en"))# 调用PyTorch函数build_vocab_from_iterator()来构建德语词典vocab_src = build_vocab_from_iterator(# 使用分词器从三个Iterator之中获取tokenyield_tokens(train + val + test, tokenize_de, index=0),min_freq=2,specials=["<s>", "</s>", "<blank>", "<unk>"],)print("Building English Vocabulary ...")train, val, test = datasets.Multi30k(language_pair=("de", "en"))vocab_tgt = build_vocab_from_iterator(yield_tokens(train + val + test, tokenize_en, index=1),min_freq=2,specials=["<s>", "</s>", "<blank>", "<unk>"],)# 设置缺省index为"<unk>",分词器无法识别的单词会被归为`<unk>`vocab_src.set_default_index(vocab_src["<unk>"])vocab_tgt.set_default_index(vocab_tgt["<unk>"])return vocab_src, vocab_tgt # 返回德语词典和英语词典
tokenize_en()函数是英语分词函数,其会调用传入的分词器参数对语句进行分词。tokenize_de()函数是德语分词函数,与tokenize_en()类似。
def tokenize(text, tokenizer): """功能:调用分词模型tokenizer对text进行分词示例:tokenize("How are you", spacy_en)返回:['How', 'are', 'you']""" return [tok.text for tok in tokenizer.tokenizer(text)]
build_vocabulary()函数中使用了build_vocab_from_iterator()函数,该函数的作用是:
- 统计数据集中词语的频率。
- 依据频率对词语进行排序。
- 如果有限定max_tokens,则需要将特殊单词排除。
- 按照词语频率将词语写入词汇表。
- 返回一个Vocab对象。
具体代码如下。
def build_vocab_from_iterator(iterator: Iterable, # 迭代器,里面是分好的词min_freq: int = 1, # 当某个单词出现的频率大于min_freq,才会被加入词典specials: Optional[List[str]] = None, # 一个包含特殊标记(special tokens)的列表。这些特殊标记在构建词汇表时会被添加到词汇表中,例如`<unk>`(未知单词)、`<pad>`(填充)、`<bos>`(句子开始)和`<eos>`(句子结束)。special_first: bool = True, # 如果special_first为True,则特殊单词会加入到词典最前面specialsmax_tokens: Optional[int] = None,
) -> Vocab:"""Build a Vocab from an iterator.Args:iterator: Iterator used to build Vocab. Must yield list or iterator of tokens.min_freq: The minimum frequency needed to include a token in the vocabulary.specials: Special symbols to add. The order of supplied tokens will be preserved.special_first: Indicates whether to insert symbols at the beginning or at the end.max_tokens: If provided, creates the vocab from the `max_tokens - len(specials)` most frequent tokens.Returns:torchtext.vocab.Vocab: A `Vocab` objectExamples:>>> #generating vocab from text file>>> import io>>> from torchtext.vocab import build_vocab_from_iterator>>> def yield_tokens(file_path):>>> with io.open(file_path, encoding = 'utf-8') as f:>>> for line in f:>>> yield line.strip().split()>>> vocab = build_vocab_from_iterator(yield_tokens(file_path), specials=["<unk>"])"""# counter表示词汇表中的单词及其频次信息。其中键是词汇表中的单词,值是对应的单词频次统计。counter = Counter()for tokens in iteratorcounter.update(tokens)specials = specials or []# First sort by descending frequency, then lexicographicallysorted_by_freq_tuples = sorted(counter.items(), key=lambda x: (-x[1], x[0]))
"""
实际变量打印如下:
[('a', 32828), ('.', 28591), ('A', 18068), ('in', 15365), ('the', 10268), ('on', 8311), ('is', 7796), ('and', 7647), ('man', 7628), ('of', 7106), ('with', 6370), (',', 4102), ('woman', 3970), ('are', 3862), ('to', 3243), ('Two', 3233), ('at', 3011), ('wearing', 2706), ('people', 2641), ('shirt', 2405), ('white', 2292), ('young', 2147), ('black', 2063), ('his', 2041), ('an', 2023), ('while', 2003), ('blue', 1944), ('red', 1799), ('sitting', 1799), ('girl', 1722), ('dog', 1706), ('boy', 1690), ('men', 1675), ('standing', 1672),...
"""if max_tokens is None:ordered_dict = OrderedDict(sorted_by_freq_tuples)else:ordered_dict = OrderedDict(sorted_by_freq_tuples[: max_tokens - len(specials)])word_vocab = vocab(ordered_dict, min_freq=min_freq, specials=specials, special_first=special_first)return word_vocab
构建词汇表需要对数据集进行分词。yield_tokens()函数完成了这个功能。
def yield_tokens(data_iter, tokenizer, index):"""从iterator之中获取句子,调用分词器进行分词,返回一个token列表。比如,从data_iter之中得到了from_to_tuple为:('Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche.', 'Two young, White males are outside near many bushes.')如果index为0,则说明对德语进行分词,返回德语token列表,如果index为1,则说明对英语进行分词,返回英语token列表""" for from_to_tuple in data_iter:yield tokenizer(from_to_tuple[index])
2.2 使用词表
词典如何使用?在collate_batch()函数中会把词表传入进去,我们进入此函数来继续深挖。collate_batch()函数是DataLoader类的collate_fn (Callable, optional)参数,其作用是将一个样本列表组合成一个张量的mini-batch。DataLoader内部会将”句子对的列表“传给collate_batch()函数来处理,然后把输入的batch发给模型。
def collate_batch(batch, # 句子对的列表。比如[(源句子1, 目标句子1),(源句子2, 目标句子2),.....],列表大小为batch sizesrc_pipeline, # 德语分词功能,即spacy_de的封装器tgt_pipeline, # 英语分词功能,即spacy_en的封装器src_vocab, # 德语词典,Vocab对象tgt_vocab, # 英语词典,Vocab对象device,max_padding=128, # 句子最大长度pad_id=2,
):# <bos>和<eos>在词典中的indexbs_id = torch.tensor([0], device=device) # <s> token ideos_id = torch.tensor([1], device=device) # </s> token idfor (_src, _tgt) in batch: # 遍历句子对列表# 首先调用src_vocab(src_pipeline(_src))对源句子处理,具体是利用分词器src_pipeline和词表src_vocab把句子转换为词表index的序列;其次调用torch.cat在句子前面加上<bos>,句子后面加上<eos>。processed_src = torch.cat([bs_id,torch.tensor(src_vocab(src_pipeline(_src)), # 这里调用词表dtype=torch.int64,device=device,),eos_id,],0,)# 首先调用tgt_vocab(tgt_pipeline(_tgt))对源句子处理,具体是利用分词器tgt_pipeline和词表tgt_vocab把句子转换为词表index的序列;其次调用torch.cat在句子前面加上<bos>,句子后面加上<eos>。processed_tgt = torch.cat([bs_id,torch.tensor(tgt_vocab(tgt_pipeline(_tgt)), # 这里调用词表dtype=torch.int64,device=device,),eos_id,],0,)collate_batch()函数实际上调用到了Vocab对象的forward()函数,该函数返回token列表所对应的index列表,这样就可以句子转换为词表索引的序列。
class Vocab(nn.Module):@torch.jit.exportdef forward(self, tokens: List[str]) -> List[int]:r"""Calls the `lookup_indices` methodArgs:tokens: a list of tokens used to lookup their corresponding `indices`.Returns:The indices associated with a list of `tokens`.""""""
从下面的数据结构之中,可以管窥。
vocab = {Vocab: 8185} <torchtext._torchtext.Vocab object at 0x0000021A26983DF0>0000 = {str} '<s>'0001 = {str} '</s>'0002 = {str} '<blank>'0003 = {str} '<unk>'0004 = {str} '.'0005 = {str} 'Ein'0006 = {str} 'einem'
""" return self.vocab.lookup_indices(tokens)
2.3 词表大小
在自然语言处理模型中,确定合适的词汇表大小是一个关键步骤,它直接影响模型的性能、效率以及适应性。事实上,较新的SLM(Small Language Model)词汇表通常超过50,000个单词或token。下图给出了从2022年到2024年间,SLM词汇表的变化趋势。可以看到,在总体趋势上,词表大小呈现增长趋势。词汇表的扩大使模型能够处理更广泛的语言,并提供更准确和更全面的响应。
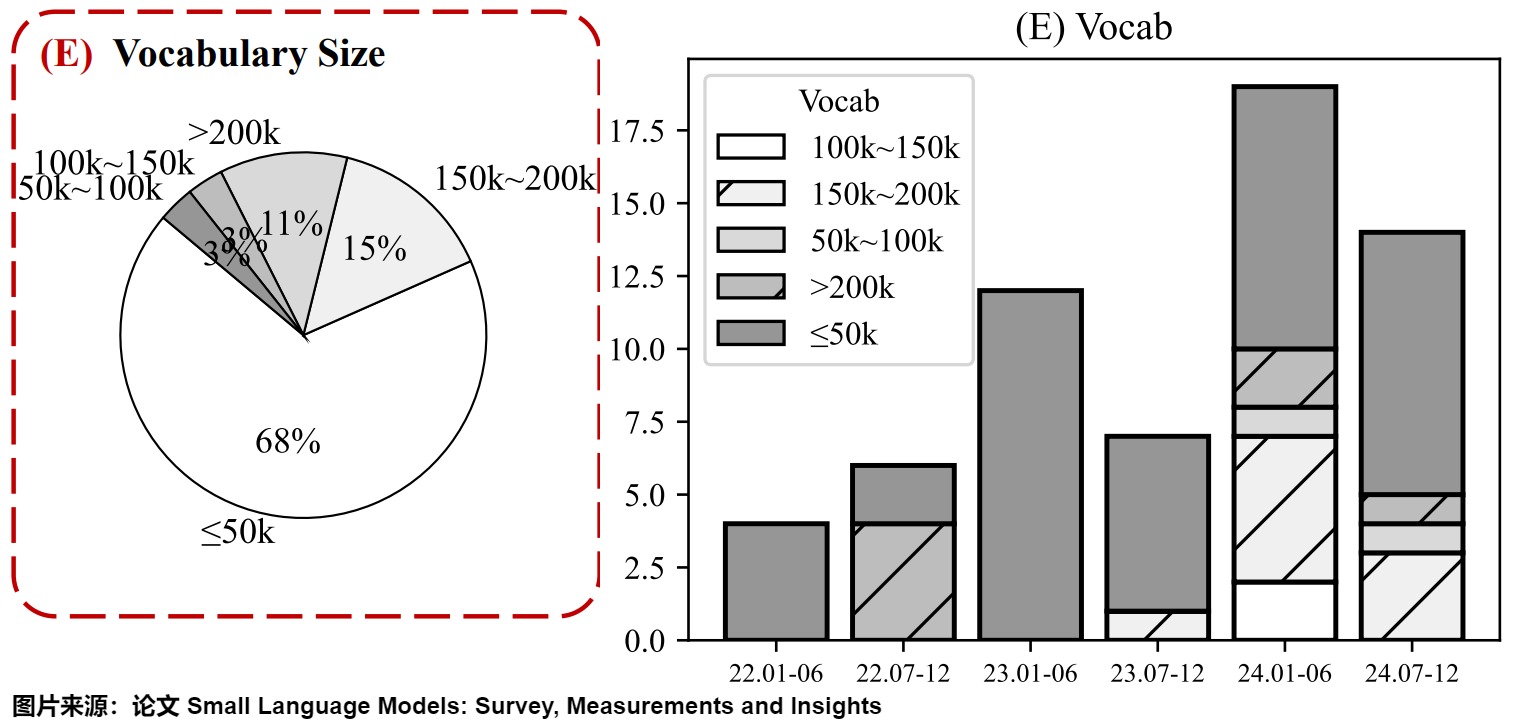
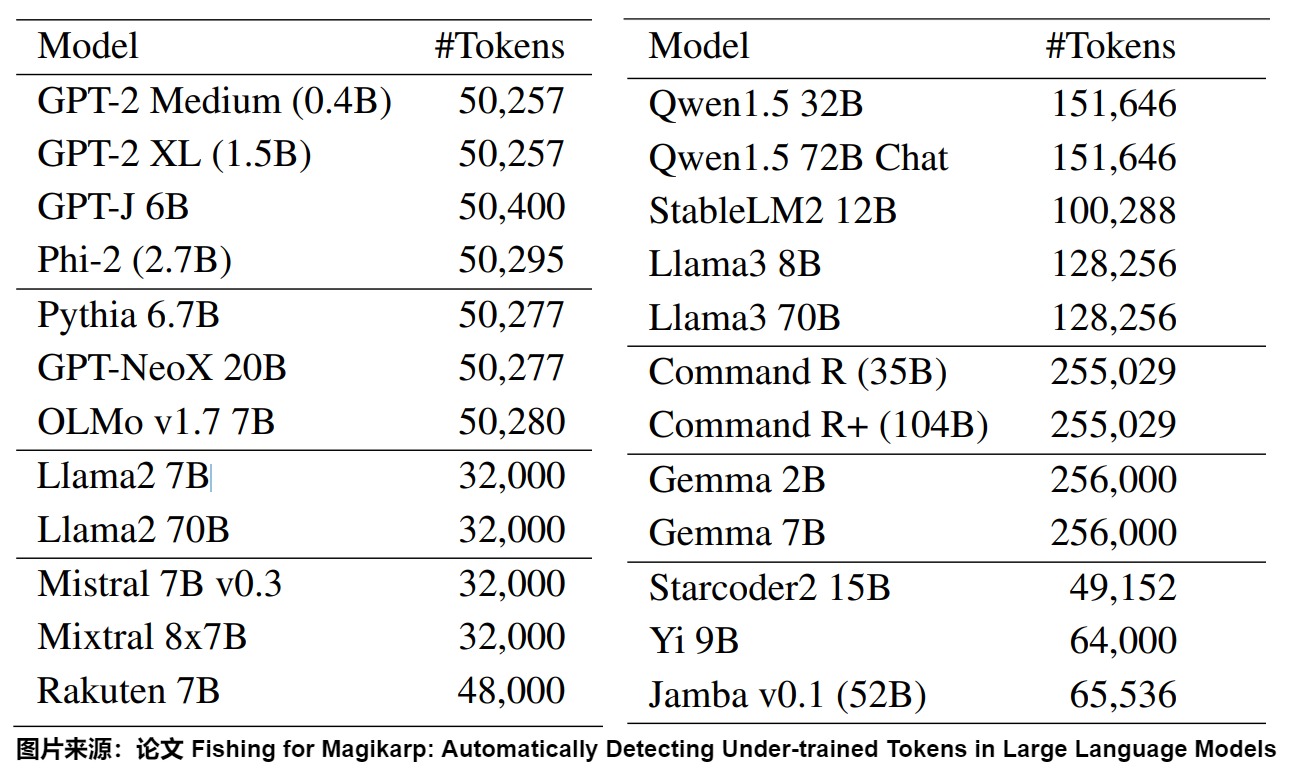
下图则给出了部分LLM的词表大小。
任务相关
理想的词汇表应该在保证模型性能和效率的同时,满足特定任务和数据集的需求。不同的自然语言处理任务可能需要不同大小的词汇表。例如,精细的文本生成任务可能需要较大的词汇量以覆盖更多细节,而一些分类任务则可能只需较小的词汇表即可达到较高性能。这都需要在设置词汇表时考虑,比如。
-
领域特定词汇:如果特定领域包含大量专业术语和行话,而这些词汇在通用词表中可能不存在或不够丰富,那么词表扩增通常是有必要的。这有助于模型更准确地理解和生成领域相关的文本,从而提升在特定任务上的性能。另外,在专业领域,某些词汇可能有特定的含义,扩增词表有助于减少模型在理解这些词汇时的歧义,并提高对领域文本的理解和生成能力。
-
数据集中文本的复杂性和多样性也影响词汇表的设置,丰富多变的数据集可能需要更大的词汇量来捕获文本的多样性。不同语言的结构差异意味着对词汇表的需求也不同。例如,拼接语(如德语)可能需要更大的词汇量来覆盖其丰富的复合词形态。
-
分词策略非常重要,不同的分词方式会导致模型对数值的理解差异。比如那个著名问题:embedding模型是否可以判断9.11 比 9.9哪一个更大?研究人员给出了各种猜测,包括预训练数据的构成和模型架构本身。而词汇表的设计就会直接影响数字的表示。例如,如果词汇表只包括 0-9 的数字,那么 11 可能被分为单独的 1 和 1,而非作为整体的 11。
另外,论文 Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral指出,虽然扩展词表能够显著提升目标语言的编解码效率,但并不意味着一定会提升下游任务效果,甚至可能会对下游任务效果产生负面影响。而且,词表扩增可能会增加模型的计算和存储成本。
因此,在实际操作中,可以通过分析数据集的特点,针对性地扩充词表,从而提高模型的性能。有时候,简单的词表截断或者使用基于规则的方法来处理领域特定词汇也可以取得不错的效果。最佳的词表扩增策略会因特定任务和领域的需求而不同,建议根据具体情况进行评估和实验。总的来说,领域模型词表扩增是一个值得考虑的策略,它可以在保持模型通用能力的同时,提升模型在特定领域的性能。但是,是否扩增词表应该基于对领域数据的详细分析和对模型性能需求的准确理解。
优势
较大的词汇表可以提高模型覆盖不同词汇和表达的能力,有助于模型更好地理解和生成文本;论文"Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies"就探讨了大型语言模型(LLMs)的词表大小对模型性能的影响,其结论是大模型的词表大小同样适用于Scaling Law,并且强调了在设计和训练 LLMs 时,需要综合考虑模型参数、训练数据和词表大小。关于词表大小 V 对语言模型的性能的影响,论文的具体结论如下:
- 增加词表大小可以提高标记化分词的效率,也就是用更短的词元去表示文本,从而提高模型性能。
- 更大的模型应该配备更大的词表。因为随着模型计算量的增加,更大的词表大小增强了模型理解更多样化文本的能力,也可以让模型表达更复杂的语言模式。
- 当词表大小达到一定程度之后,逐渐增加词表大小所带来的分词效率收益会逐渐减少,且可能导致词表有关参数的欠拟合,特别是针对低频词的词表征。
综上所述,词表大小对模型扩展至关重要。
论文也提出3 种预测最优词表大小的方法 (基于 FLOPs 的、基于导数的和基于损失函数参数拟合的估计方法),并且列出了当前主流的大型语言模型(LLMs)的词表参数和预测最优词表参数的关系。下图这张表列出了对于不同大小模型理论上最优的词表大小。
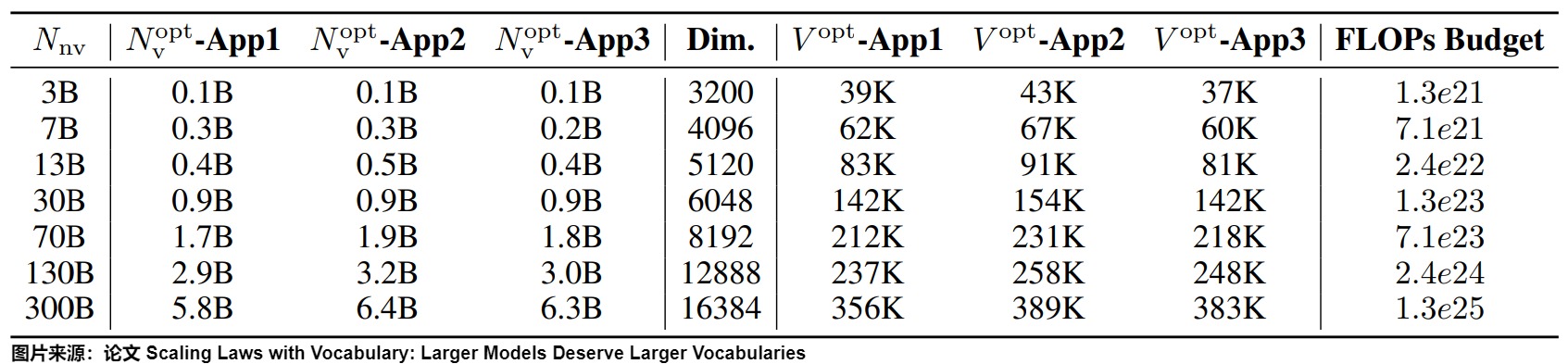
当前大多数 LLMs 的词表参数由于词表尺寸小于预测的最优值而处于次优状态。 例如下图所示,预测 Llama2-70B 的最优词表大小应该是至少 216K,远大于其实际的 32K。近来,社区开始转向更大的词汇量,例如Llama3的词汇量从Llama2的32K增加到128K。然而,扩展数据仍然是最关键的部分,解决数据稀缺问题应该是未来工作的重点。

该论文还发现,在给定算力的情况下,最优的词表大小是有上限的。通过在不同 FLOPs 预算下训练 3B 参数的模型验证了这些预测,发现仅仅把原始词表的大小替换成预测的最优词表大小,就可以提高模型在多个下游任务的性能。
劣势
然而过大的词表也有问题:
- 过大的词汇表可能导致某些token训练不足。因为大词汇表意味着更稀疏的token分布(词嵌入空间的稀疏性问题)和更细粒度的token切分,这必然会导致更多低频token和无意义的token残片,进而导致模型在某些较少见的Token上的训练不足(under-trained),难以有效学习到这些Token的表示,影响其泛化能力。论文"Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models"对LLM中训练不足的token(这些“训练不足”的token会导致模型产生异常输出)进行了检测,发现训练不足能让大模型“发疯”的token在这些大模型上普遍存在。而词汇表较大的模型,“训练不足”token的数量也会明显增多。因此该论文提出优化词汇表结构和tokenizer算法是解决token训练不足问题的关键。
- 词汇表的大小也会影响模型的处理速度。在资源有限的环境下,较大的词汇表意味着模型需要更多的计算资源来处理存储分词嵌入,也会在生成输出时产生计算负担,从而减慢处理速度,导致训练和推理过程变得低效。
如上所述,在实际应用中,可能需要通过实验和调整来找到最适合特定模型和任务的词汇表大小。
0x03 Tokenizer
tokenizer总体上做两件事情:
- 分词。tokenizer将字符串切分为子词(sub-word)token,然后将token映射到数字(词表中的序号)。
- 切分成token是依据词表进行匹配的过程,如果词表中可以查到对应的token,就输出token,否则输出某个表示token不存在的特殊符号。
- 从字串映射到数字的过程被称为tokenizer的编码过程,从数字映射回字串称为tokenizer的解码过程。
- 扩展词表。某些tokenizer会把训练语料出现的且词汇表中本来没有的token或者特殊字符加入词表。当然用户也可以手动添加这些token。
理想的tokenizer应该具备如下基本特性:
- 高压缩率。可以使用更少的token表示更多的数据。
- 训练友好:可以在合理时间内完成训练。
- 语言无关:训练和分词都和某种语言特性无关。
- 无损压缩:分词结果应该可以无损还原为输入。
在LLM时代,如何设计一个兼顾通用且高效推理的Tokenizer是非常重要的事情。
3.1 分词粒度
按切分文本的颗粒度,分词通常分成三大类:按单词粒度(word base)来分,按字符粒度(character base)来分和按子词粒度来分(subword tokenization)。以英文文本“Today is sunday”为例,三种方法切分结果如下
| 颗粒度 | 切割方式 | 分词结果 |
|---|---|---|
| 单词 | 单词级别分词,英文天然可以根据空格或者标点来分割出单词 | [today, is, sunday, .] |
| 字符 | 字符级别分词,以单个字符作为最小颗粒度,会穷举所有出现的字符,所以是最完整的。 | [t, o, d,a,y,i, s, s,u,n,d,a,y,.] |
| 子词 | 介于word和character之间,将word拆分为子串。子词分词法有很多不同方法,例如BPE,WordPiece,Unigram等等。 | [to, day,is , s,un,day, .] |
按单词粒度
词(Word)在NLP任务中是最常见的基础单元。传统构造词表的方法会先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。每个词都分配一个ID。
优点:
- 容易保持语义。如同人类阅读一样,用词作为切分粒度,可以很好地保留词的边界信息和完整语义。
- 容易切分句子。词是最自然的语言单元,对于英文这种存在空格的语言天然就容易切分。
劣势:
- 词表过大。因为罗列出单词的所有组合明显比穷举出所有字符更加困难,所以按单词粒度来切分所构造的词典太过庞大,严重影响计算效率和消耗内存。
- 容量有限。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。这会导致OOV(Out Of Vocabulary, OOV)问题。而且,这种词表长尾效应严重(存在大量低频词语占据词表空间),低频词无法得到充分训练,导致模型无法充分理解这些词的语义。
- 难以处理语义关系。比如无法处理单词的形态、词缀、单复数等语义关系和泛化性。
按字符粒度
此分词法会将单词拆分为单个字符和特殊符号。
优点:
- 字符数量少,5000多个中文常用字基本能组合出所有文本序列,不会产生OOV问题。
劣势:
- 丢失了边界信息导致无法承载单词级别的丰富语义,增加了建模难度。比如每个字符对应的嵌入向量会承载太多语义信息,模型很难学习到词与词、句子与句子之间的关系。
- 序列长度增大,增加了文本表征的成本。比如推理和训练都会带来更多的计算成本,且训练难以收敛。
另外,虽然按字符分词对于中文比较合理,但是在中文里,某些词语(或者成语)才是表达语义的最小单元,站在单字视角很难获得一个有价值的语义信息。
按子词粒度
按子词粒度分词(subword tokenization)是上面两种方法的平衡。该方法会把一个词切成更小的一块一块的子词,得到一种划分粒度介于词与字符之间的中间粒度表示,或者说,这些 token 可能是完整的单词、也可能是一个单词的一部分,这使得模型能够在处理未知词时仍然具有很好的泛化能力,提供了良好的灵活性和扩展性。
它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享token压缩空间。这样可以较好的平衡了词汇量、语义独立性和语义表达能力。从而通过一个有限的词表来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低。
比如 friendly and lovely,从词粒度切分,会得到friendly / and / lovely,加上常见的friend和love,词典中会得到5个词。从子词粒度切分,会得到friend / ly / and / love / ly,词表中只包含4个词。
而且,subword划分出来的词片段可以用来组成更大的词。有点类似英语中的词根词缀拼词法。比如可以将”looking”划分为”look”和”ing”两个子词,而划分出来的"look",”ing”又能够用来构造其它词,如"look"和"ed"子词可组成单词"looked",因而按子词粒度分词方法能够降低词典的大小,同时对相近词能更好地处理。
比如下面就是一个可能的词典形式,这里的##代表这个词应该紧跟在前面的那个词之后来组成一个完整的词。
// 动词
look
see
speck
...
// 形容词
big
small
smart
...
// 表示时态的后缀
##ed
##ied
##ing
##s
##ies
// 表示比较级和最高级后缀
##er
##est
...
Subword 方法是目前LLM的主流切词粒度,有三种主流算法,分别是:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model。
如何选择
选择 Tokenization(分词)方法通常取决于多个因素,需要综合考虑,并根据实际应用场景做出最合适的决策。常见的因素如下:
- 任务需求。不同的任务可能需要不同的分词粒度。
- .语言特性。不同语言的结构决定了适合它们的分词策略。
- 模型要求。具体到每一种模型,它们可能会根据自身的设计目标和优化方向选择最适合的分词工具。比如某些特定的分词方法可以帮助模型更好地理解和处理未见过的词汇。
- 上下文相关性。某些 Tokenization 方法能够保留上下文信息,这对于理解语义非常重要。
- 计算效率。在处理大规模数据集时,分词的速度和内存消耗也是重要的考量因素。
- 可解释性。在某些应用场景中,分词结果的可解释性也是一个重要因素。
3.2 常见tokenizer
下表整理了部分LLM使用的tokenizer。
| LM | Tokenizer |
|---|---|
| BERT | Word-Piece |
| DistilBERT | Word-Piece |
| ALBERT | Sentence-Piece |
| RoBERTa | BPE |
| GPT-2 | BPE |
| GPT-3 | BPE |
| GPT-3.5 (ChatGPT) | BPE |
| GPT-4 | BPE |
| T5 | Sentence-Piece |
| Flan T5 | Sentence-Piece |
| XLNet | Sentence-Piece |
| BART | Word-Piece |
| Llama 1 | Sentence-Piece |
| Llama 2 | Sentence-Piece |
| Llama 3 | Tiktokenizer |
| MiniMax-01 | BPE |
| DeepSeek-V3 | BPE |
3.3 Llama3示例
因为哈佛代码中tokenizer部分比较简单,所以我们用Llama3中的代码作为示例来进行分析。
定义
Tokenizer类封装了Tiktoken tokenizer。
class Tokenizer:"""Tokenizing and encoding/decoding text using the Tiktoken tokenizer."""special_tokens: Dict[str, int]num_reserved_special_tokens = 256pat_str = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+" # noqa: E501def __init__(self, model_path: str):"""Initializes the Tokenizer with a Tiktoken model.Args:model_path (str): The path to the Tiktoken model file."""mergeable_ranks = load_tiktoken_bpe(model_path)num_base_tokens = len(mergeable_ranks)special_tokens = ["<|begin_of_text|>","<|end_of_text|>","<|reserved_special_token_0|>","<|reserved_special_token_1|>","<|reserved_special_token_2|>","<|reserved_special_token_3|>","<|start_header_id|>","<|end_header_id|>","<|reserved_special_token_4|>","<|eot_id|>", # end of turn] + [f"<|reserved_special_token_{i}|>"for i in range(5, self.num_reserved_special_tokens - 5)]self.special_tokens = {token: num_base_tokens + i for i, token in enumerate(special_tokens)}self.model = tiktoken.Encoding(name=Path(model_path).name,pat_str=self.pat_str,mergeable_ranks=mergeable_ranks,special_tokens=self.special_tokens,)self.n_words: int = self.model.n_vocab# BOS / EOS token IDsself.bos_id: int = self.special_tokens["<|begin_of_text|>"]self.eos_id: int = self.special_tokens["<|end_of_text|>"]self.pad_id: int = -1self.stop_tokens = {self.special_tokens["<|end_of_text|>"],self.special_tokens["<|eot_id|>"],}编码
编码过程的代码如下。
def encode(self,s: str,*,bos: bool,eos: bool,allowed_special: Union[Literal["all"], AbstractSet[str]] = set(),disallowed_special: Union[Literal["all"], Collection[str]] = (),
) -> List[int]:"""Encodes a string into a list of token IDs.Args:s (str): The input string to be encoded.bos (bool): Whether to prepend the beginning-of-sequence token.eos (bool): Whether to append the end-of-sequence token.allowed_tokens ("all"|set[str]): allowed special tokens in stringdisallowed_tokens ("all"|set[str]): special tokens that raise an error when in stringReturns:list[int]: A list of token IDs.By default, setting disallowed_special=() encodes a string by ignoringspecial tokens. Specifically:- Setting `disallowed_special` to () will cause all text correspondingto special tokens to be encoded as natural text (insteading of raisingan error).- Setting `allowed_special` to "all" will treat all text correspondingto special tokens to be encoded as special tokens."""# The tiktoken tokenizer can handle <=400k chars without# pyo3_runtime.PanicException.TIKTOKEN_MAX_ENCODE_CHARS = 400_000MAX_NO_WHITESPACES_CHARS = 25_000substrs = (substrfor i in range(0, len(s), TIKTOKEN_MAX_ENCODE_CHARS)for substr in self._split_whitespaces_or_nonwhitespaces(s[i : i + TIKTOKEN_MAX_ENCODE_CHARS], MAX_NO_WHITESPACES_CHARS))t: List[int] = []for substr in substrs:t.extend(self.model.encode(substr,allowed_special=allowed_special,disallowed_special=disallowed_special,))if bos:t.insert(0, self.bos_id)if eos:t.append(self.eos_id)return t解码
解码过程如下所示。
def decode(self, t: Sequence[int]) -> str:"""Decodes a list of token IDs into a string.Args:t (List[int]): The list of token IDs to be decoded.Returns:str: The decoded string."""# Typecast is safe here. Tiktoken doesn't do anything list-related with the sequence.return self.model.decode(cast(List[int], t))0x04 BPE
BPE是在2015年由Google在论文[1508.07909] Neural Machine Translation of Rare Words with Subword Units中提出的一种按子词粒度分词方法。
4.1 思路
BPE(Byte Pair Encoding)全称为字节对编码,最早其实是一种数据压缩算法,来自于一篇发表于1994年的论文:“A new algorithm for data compression”。比如有一段数据是“cddcdycdyc”,其中相邻字母对的组合中"cd"出现最多,是3次。因此可以使用一个字母X去代替"cd",把数据压缩成:"XdXyXyc"。以此类推,下一个'Xy'继续被替换成Y,数据变成:"XdYYc"。因为没有出现多次的字节对,所以"XdYYc"不能被进一步压缩。反向执行以上过程即可将压缩的编码复原。
Google把这种方法引入到了NLP领域。该方案的思路是:从一个基础小词表开始,通过统计文本中字符对的频率进而不断合并文本数据中最频繁出现的字符或字符序列(高频的连续token对),以此来产生新的token。BPE 可以确保最常见的词在token列表中表示为单个token,而罕见的词被分解为两个或多个subword tokens,这样可以自适应地动态构建词汇表,并且可以很好地处理未知词汇。
4.2 算法
训练tokenizer与训练模型不同。模型训练使用随机梯度下降,是自然随机化的过程。而训练tokenizer是一个统计过程,是确定性的。这种算法总是在给定语料库中最适合选择的子词,这意味着在同一语料库上使用相同的算法进行训练时,总是得到相同的结果。另外,因为存在大量if-else的分支,所以tokenizer很难并行,使用GPU训练的利用率很低。
为了以最有效的方式构建语料库,BPE遵循一种贪婪的策略来尽可能取得最优的解决方案。算法先将每个文本词(Word)拆分成 Char粒度的字母序列,然后从字符级别开始,每一步都将出现频数最大的一对“相邻token”合并为该数据中没有出现过的一个“新token”。这样可以逐渐构建出更长的词汇或短语表示。这个过程反复迭代直到达到预设的词汇表大小或合并次数为止。后期使用该方案时需要使用一个合并(merge)表来重建原始数据。贪心算法可能不一定是全局最优、频数也不一定是最好的合并指标,但不可否认BPE是一个性能非常高效的Tokenizer算法、同时它能很方便将Token总数量控制在一个手动设置的数目内。
BPE算法的主要步骤如下:
- 准备足够大的训练语料;设定最大分词词典数量。
- 准备基础词表,比如英文中26个字母加上各种符号;
- 初始化:初始化一个词典。基于基础词表将将语料中所有文本切成最小单元(单个字符形式)加入词典,并且将特殊字符也加入词典。
- 统计共现频率:对已经切为字符的语料,全局统计所有相邻字符对的共现频率。
- 合并操作:选择最频繁出现的字符对,将它们合并为一个整体(当作一个词),将这个整体添加到词典,并且在语料中将这个字符对也同步全部替换为这个新的整体。
- 重复:重复上述过程,直到达到预设的合并次数或词汇表大小,或下一个最高频的字节对的频率为1。
- 输出:输出为运行算法得到的subword词表。后续的任务都以这个分词词典来切词和编码。

我们再看看词表大小。单看每一轮操作完,词表的数量可能增大,也可能减少。但整体上,随着合并的次数增加,词表总数通常先增大,后逐会减少到趋于一个稳定值。比如"loved","loving","loves"这三个单词。其实本身的语义都是“爱”的意思,但是如果我们以单词为单位,那它们就算不一样的词。在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好。BPE算法通过训练,能够把上面的3个单词拆分成"lov”,“ed”,“ing”,"es"几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
4.3 示例剖析
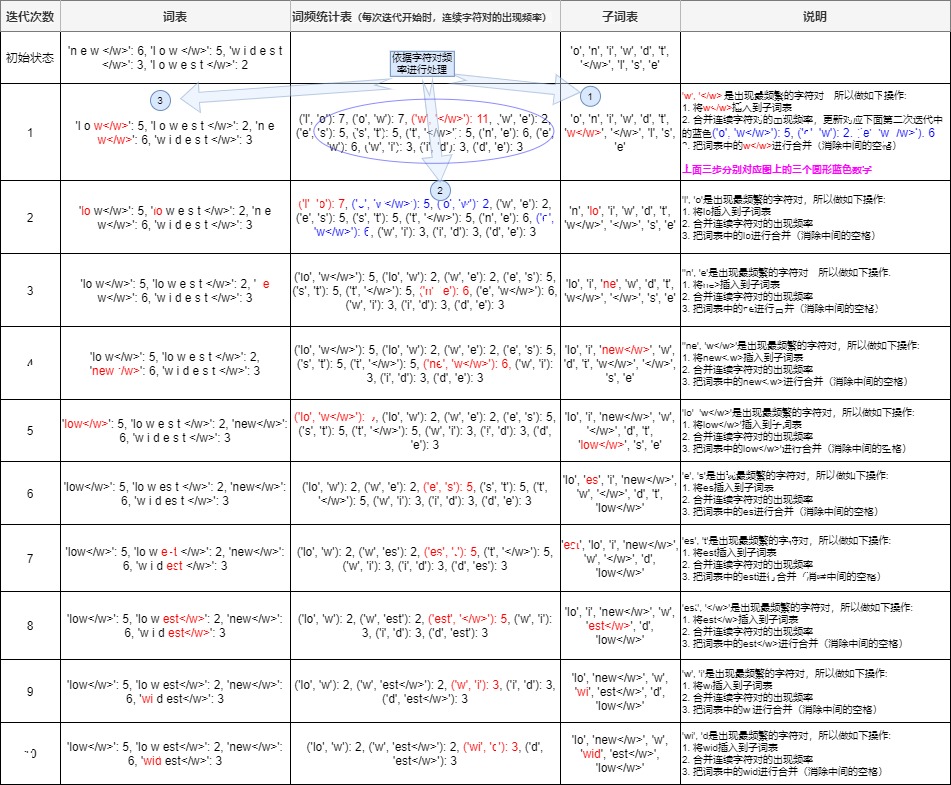
接下来我们用一个实例来进行剖析。假设我们有一个语料库,在对预语料进行预分词(pre-tokenization)之后,我们得到了一个原始词集合,其中包含如下单词:old, older, highest, 和 lowest。
统计频率
我们首先计算这些词在语料库中的出现频率。假设这些词出现的频率如下:
{"low": 5, "lowest": 2, "new": 6, "widest": 3}初始分割
本阶段的subword的粒度是字符,因此我们先将这些单词分割成单个字符,并在每个单词的末尾添加一个特殊的结束标记“”来表示终止符。同时我们也标记出该单词出现的次数。例如," low"的频率为5,那么我们将其改写为" l o w </ w>":5。此时的子词频数表如下:
{'l o w </w>': 5, 'l o w e s t </w>': 2, 'n e w </w>': 6, 'w i d e s t </w>': 3}终止符""的意义在于,它表示subword是词后缀,这样可以标识单词边界,能够让算法知道每个单词的结束位置(因为我们统计相邻字符对时不能把分别位于两个单词中的字符对算进去),这有助于算法查看每个字符并找到频率最高的字符配对。稍后我们将看到“”也能被算作字符对的一部分。
另外,终止符也有助于算法理解“star”和“highest”等词之间的区别。 这两个词都有一个共同的“st”,但一个词在结尾有一个“st”,一个在开头有一个“st”,二者意义截然不同。因此,像“st”和“st”这样的token需要被不同地处理。 如果算法看到token “st”,它就会知道它更可能是“highest”这个词的token,而不是“star”的。
对于英文,我们可以直接简单地使用空格加一些标点符号来分词;中文可以使用jieba分词或者直接按照字来进行分词。
构建初始词表
接下来我们构建基础词表(base vocab) 并开始学习合并规则(merge rules)。对于英语来说,我们选择字母来构成基础词表。以下是初始状态下的所有子词,以列表形式表示,一共10个子词,都是字母。
['l', 'o', 'w', '</w>', 'e', 's', 't', 'n', 'i', 'd']注:这个基础词表就是我们词表的初始状态。虽然看起来好像使用26个英文字母就可以表示所有单词,压缩率很高,但是这样的子词基本上无法表示相应的含义。所以,我们要使用 BPE 算法进行迭代,让这些初始子词将逐渐被合并成更长,更有语义的子词。我们会不断构建新词,加进去,直到达到我们理想的词表规模。
循环迭代学习结合规则
BPE 算法的下一步是寻找最频繁的字符对,合并它们,并一次又一次地执行相同的迭代,直到达到我们预先设置的token数限制或迭代次数限制。
- 合并字符可以让你用最少的token来表示语料库,这也是 BPE 算法的主要目标,即数据的压缩。
- 为了合并,BPE 寻找最常出现的字节对。然后将最常见的字节对合并成一个token,并将它们添加到token列表中,并重新计算每个token出现的频率。因为频率计数将在每个合并步骤后发生变化。
- 我们将继续执行此合并步骤,直到达到预先设置的token数限制或迭代限制。
每次迭代都做同样事情,我们来具体看看。
第一次迭代
统计字符对频率
首先根据基础词表,我们可以对原始的词集合进行细粒度分词,并看到基础词的词频,得到如下。
('l', 'o'): 7, ('o', 'w'): 7, ('w', '</w>'): 11, ('w', 'e'): 2, ('e', 's'): 5, ('s', 't'): 5, ('t', '</w>'): 5, ('n', 'e'): 6, ('e', 'w'): 6, ('w', 'i'): 3, ('i', 'd'): 3, ('d', 'e'): 3合并最高频字符对
接下来我们会选择最高频的字符对进行合并。例如,现在的最高频率是('w', ''),我们将其合并为一个新的子词。具体分为三步。
首先我们把'w'加进子词表,现在我们新的的子词表如下:注意,此处去除了('w', '')内部的空格:
['l', 'o', 'w</w>', 'e', 's', 't', 'n', 'i', 'd','w','</w>]其次,要更新词频统计表:
('l', 'o'): 7, ('o', 'w</w>'): 5, ('o', 'w'): 2, ('w', 'e'): 2, ('e', 's'): 5, ('s', 't'): 5, ('t', '</w>'): 5, ('n', 'e'): 6, ('e', 'w</w>'): 6, ('w', 'i'): 3, ('i', 'd'): 3, ('d', 'e'): 3最后,把词表中的w进行合并(消除中间的空格)。
{'l o w</w>': 5, 'l o w e s t </w>': 2, 'n e w</w>': 6, 'w i d e s t </w>': 3}可以看出,相比上次,词表里多了一个新的子词'w'。每次合并后词表可能出现3种变化:
- +1,表明加入合并后的新字词,同时原来的2个子词还保留(2个字词不是完全同时连续出现)。
- +0,表明加入合并后的新字词,同时原来的2个子词中一个保留,一个被消解(一个字词完全随着另一个字词的出现而紧跟着出现)。
- -1,表明加入合并后的新字词,同时原来的2个子词都被消解(2个字词同时连续出现)。
随着合并的次数增加,词表通常先增加后减小。因为原有词表中的单词逐步被合并,所以把原有单词从词表中驱除。在实践中需要仔细设置迭代次数。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个合适的中间值。
然而现在词表还是太大,我们需要进入第二次迭代。
第二次迭代
我们再次统计更新后的字符对频率:
{('l', 'o'): 7, ('o', 'w</w>'): 5, ('o', 'w'): 2, ('w', 'e'): 2, ('e', 's'): 5, ('s', 't'): 5, ('t', '</w>'): 5, ('n', 'e'): 6, ('e', 'w</w>'): 6, ('w', 'i'): 3, ('i', 'd'): 3, ('d', 'e'): 3})这时,最高频的字符对是('l', 'o')。因此,我们将这一对字符合并为新的子词 lo。
更新后的子词表如下:
['lo', 'w</w>', 'e', 's', 't', 'n', 'i', 'd', 'w','</w>']更新后的频数表如下:
{('l', 'o'): 7, ('o', 'w</w>'): 5, ('o', 'w'): 2, ('w', 'e'): 2, ('e', 's'): 5, ('s', 't'): 5, ('t', '</w>'): 5, ('n', 'e'): 6, ('e', 'w</w>'): 6, ('w', 'i'): 3, ('i', 'd'): 3, ('d', 'e'): 3}更新后的词表如下。
{'lo w</w>': 5, 'lo w e s t </w>': 2, 'n e w</w>': 6, 'w i d e s t </w>': 3}后续迭代
我们继续重复以上步骤,直到达到预设的词表规模或者满足迭代条件,或者下一个最高频的字符对出现频率为 1。最终得到的子词词汇表如下:
['est</w>', 'new</w>', 'low</w>', 'wid', 'lo', 'w']我们从最初的10个字母成功得到了6个子词,这个子词也被我们称为token。我们也看到了在编码的过程中,输入的句子被打散变为一个个token的过程。
注意,在上述算法执行后,如果句子中仍然有子字符串没被替换但所有subword都已迭代完毕,则将剩余的子词替换为特殊token,如
小结
我们用下图来把迭代流程做一下梳理。我们最初的token列表为['l', 'o', 'w', '', 'e', 's', 't', 'n', 'i', 'd'],一共10个token。现在token列表为['lo', 'new', 'w', 'wid', 'est', 'low'],一共6个token,这说明token列表被有效压缩了。例子中我们的语料库很小,现实中的语料库会大很多,我们能通过更多的迭代次数将token列表缩小更多。
4.4 使用
编码
BPE 的编码过程是将单词分割成词表中的token的过程。在得到Subword词表后,针对每一个单词,我们可以采用如下的方式来进行编码:
- 子词排序。将词典中的所有子词按照长度由大到小进行排序,因为我们接下来会优先匹配最长的 token,然后迭代到最短的token。
- 匹配子字串。对于单词w,我们依次遍历排好序的词典。查看当前子词是否是w的子字符串,如果是,则使用当前子词替换w中的子字符串。并对w剩余的字符串继续匹配。
- 重复直到无法匹配。最终我们将遍历所有tokens,并且token的子字符串将被替换为我们子词列表中已经存在的子词。
- 处理未匹配的子字符串。如果遍历完字典后,仍然有子字符串没有匹配但所有token都已迭代完毕,则将剩余字符串替换为特殊符号(如”
”)输出。 - 单词的表示即为上述所有输出子词。
基本流程如下。
for subword in subwords:for word in words:# 执行替换操作比如,我们使用上面生成的子词表['lo', 'new', 'w', 'wid', 'est', 'low']来对一个新造的单词 "wwidlow"进行编码,得到['w','wid', 'low']。可以很直观的看出,一个从没有出现过的新单词被编码成为词表里的token,而这是传统分词方法做不到的。
解码
解码过程是编码的逆过程,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符,这样可以恢复原始单词。也可以看到,在拼接时,"< /w >"的作用就是其可以隔离开不同的单词。举例如下。
# 编码序列
[“the</w>”, “high”, “est</w>”, “moun”, “tain</w>”]# 解码序列
“the</w> highest</w> mountain</w>”4.5 MINBPE
我们接下来用MINBPE来看看具体实现。
基础函数
get_stats()和merge()函数是编码时使用到的基础函数。
# 统计字频
def get_stats(ids, counts=None):"""Given a list of integers, return a dictionary of counts of consecutive pairsExample: [1, 2, 3, 1, 2] -> {(1, 2): 2, (2, 3): 1, (3, 1): 1}Optionally allows to update an existing dictionary of counts"""counts = {} if counts is None else countsfor pair in zip(ids, ids[1:]): # iterate consecutive elementscounts[pair] = counts.get(pair, 0) + 1return counts# 合并子词
def merge(ids, pair, idx):"""In the list of integers (ids), replace all consecutive occurrencesof pair with the new integer token idxExample: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx=4 -> [4, 3, 4]"""newids = []i = 0while i < len(ids):# if not at the very last position AND the pair matches, replace itif ids[i] == pair[0] and i < len(ids) - 1 and ids[i+1] == pair[1]:newids.append(idx)i += 2else:newids.append(ids[i])i += 1return newidsTokenizer
Tokenizer是基类,提供了分词器所需的基础能力。
class Tokenizer:"""Base class for Tokenizers"""def __init__(self):# default: vocab size of 256 (all bytes), no merges, no patternsself.merges = {} # (int, int) -> int 对哪两个进行合并,以及合并之后对应的索引self.pattern = "" # strself.special_tokens = {} # str -> int, e.g. {'<|endoftext|>': 100257}# 词典self.vocab = self._build_vocab() # int -> bytesdef train(self, text, vocab_size, verbose=False):# Tokenizer can train a vocabulary of size vocab_size from textraise NotImplementedErrordef encode(self, text):# Tokenizer can encode a string into a list of integersraise NotImplementedErrordef decode(self, ids):# Tokenizer can decode a list of integers into a stringraise NotImplementedErrordef _build_vocab(self):# vocab is simply and deterministically derived from merges# 单字节tokenvocab = {idx: bytes([idx]) for idx in range(256)}# 字节对tokenfor (p0, p1), idx in self.merges.items():vocab[idx] = vocab[p0] + vocab[p1]# 特殊tokenfor special, idx in self.special_tokens.items():vocab[idx] = special.encode("utf-8")return vocabdef save(self, file_prefix):"""Saves two files: file_prefix.vocab and file_prefix.modelThis is inspired (but not equivalent to!) sentencepiece's model saving:- model file is the critical one, intended for load()- vocab file is just a pretty printed version for human inspection only"""# write the model: to be used in load() latermodel_file = file_prefix + ".model"with open(model_file, 'w') as f:# write the version, pattern and merges, that's all that's neededf.write("minbpe v1\n")f.write(f"{self.pattern}\n")# write the special tokens, first the number of them, then each onef.write(f"{len(self.special_tokens)}\n")for special, idx in self.special_tokens.items():f.write(f"{special} {idx}\n")# the merges dictfor idx1, idx2 in self.merges:f.write(f"{idx1} {idx2}\n")# write the vocab: for the human to look atvocab_file = file_prefix + ".vocab"inverted_merges = {idx: pair for pair, idx in self.merges.items()}with open(vocab_file, "w", encoding="utf-8") as f:for idx, token in self.vocab.items():# note: many tokens may be partial utf-8 sequences# and cannot be decoded into valid strings. Here we're using# errors='replace' to replace them with the replacement char �.# this also means that we couldn't possibly use .vocab in load()# because decoding in this way is a lossy operation!s = render_token(token)# find the children of this token, if anyif idx in inverted_merges:# if this token has children, render it nicely as a mergeidx0, idx1 = inverted_merges[idx]s0 = render_token(self.vocab[idx0])s1 = render_token(self.vocab[idx1])f.write(f"[{s0}][{s1}] -> [{s}] {idx}\n")else:# otherwise this is leaf token, just print it# (this should just be the first 256 tokens, the bytes)f.write(f"[{s}] {idx}\n")def load(self, model_file):"""Inverse of save() but only for the model file"""assert model_file.endswith(".model")# read the model filemerges = {}special_tokens = {}idx = 256with open(model_file, 'r', encoding="utf-8") as f:# read the versionversion = f.readline().strip()assert version == "minbpe v1"# read the patternself.pattern = f.readline().strip()# read the special tokensnum_special = int(f.readline().strip())for _ in range(num_special):special, special_idx = f.readline().strip().split()special_tokens[special] = int(special_idx)# read the mergesfor line in f:idx1, idx2 = map(int, line.split())merges[(idx1, idx2)] = idxidx += 1self.merges = mergesself.special_tokens = special_tokensself.vocab = self._build_vocab()BPE Tokenizer
BasicTokenizer是BPE算法的实现。
class BasicTokenizer(Tokenizer):def __init__(self):super().__init__()def train(self, text, vocab_size, verbose=False):assert vocab_size >= 256num_merges = vocab_size - 256# input text preprocessing# 得到原始字节text_bytes = text.encode("utf-8") # raw bytesids = list(text_bytes) # list of integers in range 0..255# iteratively merge the most common pairs to create new tokens# merges用来决定把哪些单字节合并成一个token,并且标记一个索引merges = {} # (int, int) -> int# 前256个单字节tokenvocab = {idx: bytes([idx]) for idx in range(256)} # int -> bytes# 扩充词典for i in range(num_merges):# count up the number of times every consecutive pair appears# 计算每个相邻对出现的次数stats = get_stats(ids)# find the pair with the highest count# 找到出现最多的字节对,将其构建成为一个新的tokenpair = max(stats, key=stats.get)# mint a new token: assign it the next available id# 给这个新token设置对应的索引idx = 256 + i# replace all occurrences of pair in ids with idx# 对ids进行更新,即把ids中出现的pair替换成idxids = merge(ids, pair, idx)# save the mergemerges[pair] = idx# 更新词汇表,新idx对应的token就是原来词汇表中两个对应字节的拼接vocab[idx] = vocab[pair[0]] + vocab[pair[1]]# printsif verbose:print(f"merge {i+1}/{num_merges}: {pair} -> {idx} ({vocab[idx]}) had {stats[pair]} occurrences")# save class variablesself.merges = merges # used in encode()self.vocab = vocab # used in decode()def decode(self, ids):# 从整数列表还原成字节字符串# given ids (list of integers), return Python stringtext_bytes = b"".join(self.vocab[idx] for idx in ids)text = text_bytes.decode("utf-8", errors="replace")return text# 编码函数def encode(self, text):# given a string text, return the token idstext_bytes = text.encode("utf-8") # raw bytes# 把字节变成整型数(0~255)的列表。中文可能对应多个字节ids = list(text_bytes) # list of integers in range 0..255while len(ids) >= 2: # 遍历ids# find the pair with the lowest merge index# 计算相邻字节的频数stats = get_stats(ids)# 对于stats的每个key,调用merge函数,得到最小值pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))# subtle: if there are no more merges available, the key will# result in an inf for every single pair, and the min will be# just the first pair in the list, arbitrarily# we can detect this terminating case by a membership check# 排名最短的pair都不在merge之中,说明没有需要合并的pair,就不需要再编码了if pair not in self.merges:break # nothing else can be merged anymore# otherwise let's merge the best pair (lowest merge index)idx = self.merges[pair]# 合并ids = merge(ids, pair, idx)# ids中所有可以合并的pair都被替代了,得到了新的idsreturn ids4.5 优劣
优点
BPE的优点如下:
-
更小的词表。BPE 可以生成一个更小的词表。这不仅节省存储空间,还提高了计算效率。
-
更好的泛化能力。BPE的词汇表包含了从单个字符到较长的子词单位,模型可以利用这些单位来表示任何输入文本。这种方法尤其适用于处理大量的未知词汇或拼写错误的情况,因为它允许模型通过组合已知的部分来推测新的词汇。例如,遇到一个新词,我们可以用现有的子词来表示它,而不需要为每个新词创建一个新的词条。
-
可以有效地平衡词典大小和编码步骤数。
劣势
BPE的劣势是:
- 基于贪婪算法和确定的符号替换导致BPE不能提供带概率的多个分词结果。
- 解码的时候会面临歧义问题。比如对于同一个句子, 例如Hello world,可能会有不同的Subword序列(Hell/o/ word和H/ello/ world)。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。导致在翻译任务中,不同的id序列可能翻译出不同的句子。
- 在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习。
另外,“9.9 和 9.11 到底哪个大?”这个问题,也可以从tokenizer角度来给出解释。比如不同tokenizer 对于处理数字方法有所不同,这导致对语言模型中的算术性能有显著影响。
- GPT-2 论文使用BPE将频繁出现的子词合并为单个单元,直到词汇量达到目标大小。然而,这种做法生成的词汇表在很大程度上取决于输入到 tokenizer 中的训练数据,从而导致了在数字编码方式上的不一致性。例如,在训练数据中常见的数字(例如 1-100、1943 年这样的表示)很可能被表示为单个 token,而较少见到的数字则被拆分成多个 token。
- Llama 和 Llama 2 使用 SentencePiece的 BPE 实现对数字进行了显著的调整:它们将所有数字拆分为单个数字。这意味着只有 10 个唯一 token(0-9)来表示任何数字,从而简化了 LLM 的数字表示。
- DeepSeek-V2则有一个类似的单位数(single-digit)的 tokenizer 。
- Llama 3 采用了不同的方法来处理数字,将它们 tokenizing 为三位数。因此,从 1 到 999 的数字每个数都有唯一的 token。
- 后来又出现了从右到左(R2L)的分词方法,该方法以三个字符为一组,从文本的末尾开始向开头处理。
我们可以根据问题类型优化 tokenization 策略,从而提高 LLM 在数学任务上的表现。
0x05 其它算法
前面提到过,常用的subword分词算法有如下三种:BPE、WordPiece和Unigram。本小节我们来看看WordPiece和Unigram,以及其它的子词分类算法。
5.1 WordPiece
WordPiece算法出自论文“JAPANESE AND KOREAN VOICE SEARCH”,用于解决日语和韩语的语音问题。这种算法的字面理解是把word拆成一片一片,可以看作是BPE的变种。与BPE相比,WordPiece可以更有效地处理词汇的变体和未知词汇。
思想
WordPiece与BPE类似,走的是合并的思路。即从一个基础小词表出发,每次词表中选出两个Subword合并成新的Subword,通过不断合并来产生最终的词表。主要的差别在于,BPE按频率来选择合并的token对,而wordpiece基于语言模型似然概率的最大值来相邻子词合并,它不仅计算这些组合的频率,还考虑了合并后带来的概率增益。也可以这样理解,wordpiece按token间的互信息进行合并。即如果 P(ed) 的概率比P(e) + P(d)单独出现的概率更大,WordPiece就会把他们合并放入词表。
注:互信息,在分词领域有时也被称为凝固度、内聚度,可以反映一个词内部的两个部分结合的紧密程度。互信息越大,两个子词在语言模型上就拥有越强的关联性。
算法
WordPiece引入了一个假设:所有subword的出现都是独立的,并且subword序列由subword出现概率的乘积产生。WordPiece的算法如下:
- 准备足够大的训练语料,确定期望的子词表大小。
- 准备基础词表,比如英文中26个字母加上各种符号。
- 基于基础词表将语料拆分为最小单元。
- 基于第3步数据训练语言模型(比如unigram语言模型)。
- 从所有可能的token对中选择加入语言模型后,能最大程度地增加训练数据概率的token对作为新的子词。
- 重复第5步直到达到第2步设定的subword词表大小或概率增量低于某一阈值。
算法的输出是子词表。
优势与劣势
-
优势:可以较好的平衡词表大小和OOV问题;
-
劣势:可能会产生一些不太合理的子词或者说错误的切分;对拼写错误非常敏感;对前缀的支持不够好;
5.2 UniLM
ULM出自论文 "Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates"。ULM 算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
Unigram 与 WordPiece 的相同点是:同样使用语言模型来挑选子词,即Unigram 也使用概率统计的方式来预测每个单词作为独立单元出现的概率,并基于这个概率来进行分词。这个过程中,某些词可能会被拆分成更小的单元,以便模型可以更灵活地处理语言中的变化和新词。
Unigram 与 WordPiece 的最大区别是:WordPiece 算法的词表大小是从小到大变化。UniLM 的词库则是从大到小变化,可以看成是WordPiece算法在执行过程中进行反向操作。Unigram 先初始化一个大词表,之后每一步根据评估准则不断丢弃词表中的子词(根据评估不断删除排序靠后的Subword),直到满足限定条件。由于每次保留、删除的是一批Subword,因此,Unigram 算法复杂度比WordPiece(每次合并一个)要低。
算法
- 准备足够大的训练语料,确定期望的子词表大小。
- 准备基础词表:初始化一个很大的词表,比如所有字符+高频ngram,也可以通过BPE算法初始化。
- 针对当前词表,用语言模型来估计每个子词在语料上的概率。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个分词结果。
- 计算删除每个subword后对总loss的影响,作为该子词的得分。
- 将子词按照Score大小进行排序,保留前X%的Subword。可见,ULM会倾向于保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被删除,其损失会很大。
- 重复步骤3到5,直到词表大小减少到设定值,或第5步的结果不再变化。
算法的输出是的subword词表。
优势与劣势
优势:
- 使用的训练算法可以利用所有可能的分词结果,这是通过data sampling算法实现的;
- 提出一种基于语言模型的分词算法,这种语言模型可以给多种分词结果赋予概率,从而可以学到其中的噪声;
- 能够自动适应不同语言的特性,使得模型在处理多语言文本时更加高效,它在GPT-1中被使用。
劣势:
- 效果与初始词表息息相关,初始的大词表要足够好,比如可以通过BPE来初始化;
- 略显复杂。
比对
下面的表格和图例给出了三种分词方法的对比。
| 名称 | BPE | WordPiece | Unigram |
|---|---|---|---|
| 选择子词方法 | 出现频率 | 互信息(使用语言模型) | 互信息(使用语言模型) |
| 操作 | 合并子词 | 合并子词 | 删除使得最大似然概率减小最小的子词 |
| 词表变化 | 逐步变大 | 逐步变大 | 逐步减小 |

5.3 BBPE
论文"Neural Machine Translation with Byte-Level Subwords"在基于BPE基础上提出了一种新的subword算法,将BPE的思想从字符级别扩展到子节级别,故称之为BBPE,即Byte-level BPE。
动机
几乎所有现有的机器翻译模型都建立在基于字符的词汇表之上:characters, subwords or words(只是字符的粒度不同)。 对于英文、拉美体系的语言来说使用BPE分词足以在可接受的词表大小下解决OOV的问题,然而,对于噪声文本或字符丰富的语言(如日语和中文),其稀有字符可能会不必要地占用词汇表并限制其紧凑性。用字节级别表示文本并使用 256 字节集作为词汇表是解决此问题的潜在方法。 然而,高昂的计算成本阻碍了它在实践中的广泛部署或使用。 因此,论文作者提出了字节级子词BBPE,它比字符词汇表更紧凑,没有词汇表外的标记,但比仅使用纯字节更有效。
思想
BBPE是从UTF8编码入手的。相比ASCII只能覆盖英文中字符,UTF-8编码创建的本身就是为了通用的将世界上不同的语言字符尽可能全部用一套编码进行编号,相比之下,UTF-32对于每个字符都采用4位字节(byte)则过于冗长。改进的UTF-8编码是一个变长的编码,有1~4个范围的字节(bytes)长度。对于不同语言中字符可以采用不同长度的字节编码。
BBPE从原理上和BPE类似,也是选取出现频数最高的字符对进行合并。最主要区别是BPE基于char粒度去执行合并的过程生成词表,而BBPE是先通过UTF-8的编码方式将任意字符转化为长度1到4个字节,1个字节有256种表示,然后以字节为颗粒度进行聚合,其他流程和BPE是一样的。
优劣
优点如下:
- 效果与BPE相当,其大小仅为 BPE 的 1/8。针对稀有字符,BBPE不会为其分配专门的token id,而是使用字节级别来编码来解决OOV的问题,一定程度上控制了词表大小和解决了稀疏字符难以训练的问题。
- 可以跨语言共用词表。BBPE 可以最大限度地共享多种语言的词汇并实现更好的翻译质量。
- 任意语种都可以被编码到字节进行表示,而UTF-8编码可以在不同语言之间具有一定互通性,这样底层字节层面的共享就可能带来知识迁移。
缺点如下:
- 编码序列时,长度可能会略长于BPE,计算成本更高。比如单个中文字符被切割为多个字节表示,导致表征的成本上升。
- 由于字节层面比字符粒度更低一层,也会导致在解码的过程中对于某个字节不确定是来自某个Character还是单独的Character中从而导致歧义。这个时候可能需要借助上下文的信息和一些动态规划的算法来进行解码。
0x06 发展
我们接下来看看和token相关的一些有特色或者较新的论文。
6.1 Better Than Tokens
传统的语言模型依赖于 tokenizer 来预处理数据,但 tokenization 有其固有的局限性,包括固定的词汇表、处理多语言或噪声数据的效率低下,以及由压缩启发式方法引入的偏见。论文"Byte Latent Transformer: Patches Scale Better Than Tokens"提出的字节潜在 Transformer(Byte Latent Transformer,简称 BLT)挑战了这种常规做法。BLT 通过直接建模原始字节流,将它们根据熵动态分组为patch(片段/补丁)以实现高效计算。这种无需 tokenizer 的方法代表了语言建模的重大转变。
主要贡献
论文的主要贡献是:
-
动态patch划分:BLT通过基于熵的patch划分方法,动态地将字节分组为patch,从而在数据复杂性较高的地方分配更多的计算资源。
-
扩展研究:本文首次对字节级模型进行了FLOPs控制的扩展研究,展示了BLT在8B参数和4T训练字节的规模上,能够与基于token的模型(如Llama 3)相匹配,并且在推理效率上具有显著优势。
-
推理效率提升:BLT可以在保持相同推理FLOPs预算的情况下,同时增加模型大小和patch大小,从而实现更高的扩展效率。
-
鲁棒性提升:BLT在处理噪声输入和字符级任务(如拼写检查、音素转录等)上表现出色,显示出对子词结构和字符级信息的更好理解。
-
由于在数据可预测时动态选择长patch,BLT使训练和推理效率都得到提升,同时在推理和长尾数据泛化方面也取得了定性改进。
-
字节化预训练模型:论文还探讨了通过初始化预训练的基于token的模型(如Llama 3)的全局Transformer参数,快速训练BLT模型的方法,展示了其在减少训练FLOPs方面的潜力。
动机
现有的LLM几乎完全端到端训练,除了token化——这是一个将字节分组为静态token集的启发式预处理步骤。token化之所以重要,是因为直接在字节维度上来着眼,会导致序列长度较长。从而导致LLM在大规模训练上成本过高,而使用token可以避免这个问题。这种偏重于如何压缩字符串的token化方式会导致一些缺点,如领域/模态敏感性、对输入噪声的敏感性、缺乏字法知识等。之前的研究通过采用更高效的自注意力机制或无注意力架构来缓解这些问题。然而,这主要有助于训练小模型。在大模型上训练时,Transformer的主要计算成本并非注意力机制,而是主要由运行在每个字节上的大型FFN来主导。
基于token化的LLM为每个token分配相同的计算量,以效率换取性能。但是token是通过压缩启发式方法生成的,这些启发式方法并不总是与预测的复杂性相关。而BLT论文作者认为,模型应该动态分配计算资源,以满足实际需求。例如,预测大多数单词的结尾不需要大型Transformer,因为这些是相对简单、低熵的决策,而选择新句子的第一个单词则更为困难。
patch指的是没有固定词汇表的动态分组序列。patch和token之间的一个关键区别是,使用token时,模型无法直接访问底层字节特征。为了高效分配计算资源,论文作者提出了一种动态、可学习的方法,将字节分组为patch,并引入了一种新的混合了字节和patch信息的模型架构。具体来说是如下几点:
- 动态学习。与传统的基于token的模型不同,BLT没有固定的patch词汇表,而是从原始字节数据中直接学习,这样避免了静态词汇表的限制,并能更好地处理多样化和带噪声的输入。
- 基于熵的 Patch:根据信息复杂度动态地将字节分组为 Patch,从而动态分配计算资源。BLT根据下一个字节预测的熵对数据进行分段,创建信息密度相对均匀的上下文化字节分组。即对高熵区域(复杂输入)分配更多的计算资源,在低熵区域节省资源。
- 引入了一种新的模型架构,通过轻量级的编码器和解码器模块将任意字节组分组为潜在的patch表示。混合了字节和patch信息。
在标准LLM中,增加词汇表大小意味着平均token更大,因此模型步骤更少,但最终投影层的输出维度也更大。这种权衡限制了基于token化的方法在token大小和推理成本上实现显著提升。BLT对基于token化模型的关键改进就是重新定义了词汇表大小和计算之间的权衡。在生成时,BLT需要决定当前字节序列的步骤是否处于patch边界,因为这决定了是否通过潜在Transformer来调用更多计算。形式上,patch方案\(f_p\)需要满足增量patch化的属性:
比如,BPE就不是增量patch化方案,因为相同的前缀可以根据延续序列以不同方式来token化,因此不满足上述属性。
因为接下来要涉及到熵的概念,所以我们要先拿出来说一下。信息熵用来衡量系统不确定性或随机性,这里指大脑关于世界的内部模型的不确定性。大脑的目标是将其内部模型与感官输入之间的预测误差最小化,减少信息熵是减少预测误差的一种方法。通过减少信息熵,大脑可以对世界做出更准确的预测,这等于是使系统的自由能最小化。预训练 pre-train 阶段,优化目标是最小化交叉熵(cross entropy), 对于GPT 自回归语言模型而言,是看能否正确预测到下一个单词。这里的交叉熵就是信息熵。
Patch化
patch函数\(f_p\)将长度为n的字节序列\(x=\{x_i, | i=1,...,n\}\)分段为长度为m<n的patch序列\(p=\{p_j, | j=1,...,m\}\),具体方式是将\(x_i\)映射到集合{0,1},其中1表示新patch的开始。这样使得BLT可以依据上下文动态分配资源。patch的平均大小是使用给定patch函数在训练和推理期间处理数据的主要因素。论文使用的三种patch函数如下:
- 每patch固定字节数。最直接的字节分组方法是固定大小的patch。固定跨步易于实现训练和推理,提供了一种改变平均patch大小的简单机制,因此易于控制FLOP成本。然而,这种patch函数存在显著的缺点。首先,计算资源没有动态分配到最需要的地方:如果仅预测代码中的空白字符就可能会浪费一个Transformer步骤,而导致没有为信息密集的字节(如数学符号)分配到足够的计算资源。其次,这导致相似字节序列的不一致和非上下文patch化,例如同一个单词被用不同的方式进行分割。
- 空白patch。Slagle提出了一种简单而有效的改进,即在任何空白字节后创建新patch,这些空白字节是许多语言中语言单元的自然边界。在空白patch化中,一个潜在Transformer步骤(即更多的FLOP)被分配来建模每个单词。这确保了单词在序列中以相同方式patch化,并为通常跟随空白的困难预测分配FLOP。例如,预测问题“谁创作了《魔笛》?”的第一个字节比预测“M”之后的字节要困难得多,因为第一个字符显著减少了可能的选择,使得完成“莫扎特”相对容易预测。然而,空白patch化无法优雅地处理所有语言和领域,最重要的是无法改变patch大小。
- 使用小字节语言模型的动态熵patch。这种方法使用熵估计来推导patch边界,即采用数据驱动的方法来识别高不确定性的下一个字节预测。作者训练了一个小字节级自回归语言模型,在字节词汇表V上的LM分布\(p_e\)下计算下一个字节的熵。如果下一个字节的熵大,就说明是一个新patch的开始。

上图展示了用不同的方式对字节进行分组,每种方案会导致不同的patch数量。由于每个patch都通过一个大的Transformer步骤进行处理,因此patch的数量直接决定了计算开销(以FLOPs计)的主要部分。这些方案通过以下方式将字节分组为patch:
- 每四个字节进行跨步分组,如MegaByte。
- 使用字节对编码(BPE)进行token化。
- 基于熵的patch划分。
- 基于空白字节来划分patch。
- 使用具有2字节上下文的小型CNN字节级模型对熵进行预测,然后基于熵来划分patch。
BLT架构
BLT 由一个对 patch 表征进行操作的大型全局自回归语言模型以及两个较小的局部模型组成。这两个较小的局部模型将字节序列编码为 patch,并将 patch 表征解码回字节。
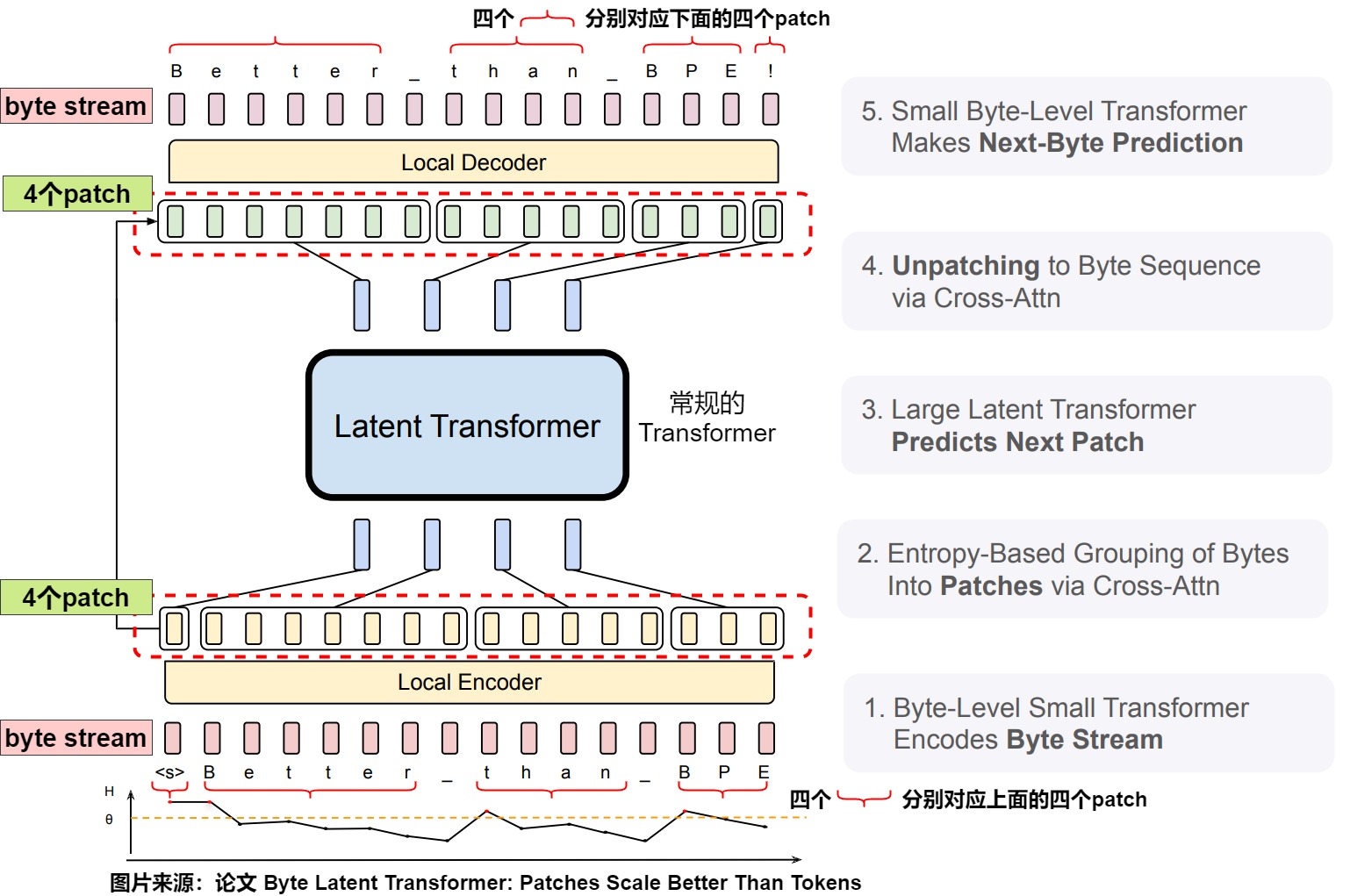
上图中,BLT由三个模块组成:一个轻量级的局部编码器,用于将输入字节编码为patch表示;一个计算量较大的潜在Transformer会处理patch表示;以及一个轻量级的局部解码器,用于解码下一个patch的字节。BLT结合了字节n-gram嵌入和交叉注意力机制的优点,这样可以最大化潜在Transformer与字节级模块之间的信息流动。与固定词汇表的token化不同,BLT动态地将字节分组为patch,同时保留了对字节级信息的访问。
潜在全局Transformer模型
潜在全局 Transformer 是一个具有 \(l_G\) 层的自回归 transformer 模型 G,它将一系列潜在输入 patch 表征 $p_j $映射到一系列输出 patch 表征 \(o_j\)。论文使用下标 j 表示 patch,使用下标 i 表示字节。全局模型使用块因果注意力掩码。
**局部编码器 **
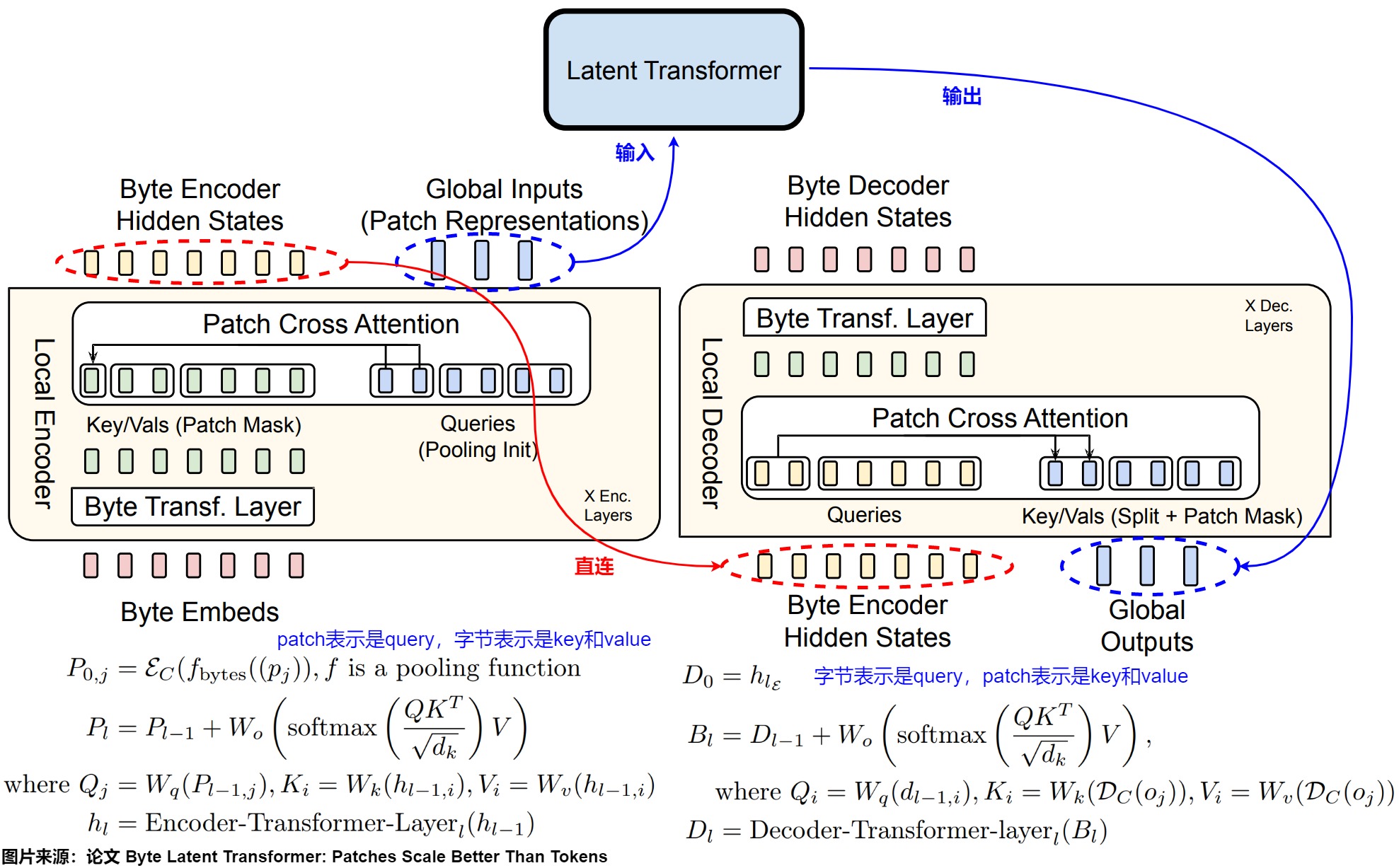
局部编码器模型(用 ε 表示)是一种基于 Transformer 的轻量级模型,具有 $ l_ε \ll l_g$ 层,其主要作用是将输入字节序列 \(b_i\) 映射为表达性 patch 表征$ p_j$。此处与 Transformer 架构的主要区别是在每个 Transformer 层之后添加了一个交叉注意力层,其功能是将字节表征池化为 patch 表征。其具体操作如下:
首先,使用\(R^{256 \times h_ε}\) 矩阵把输入字节序列 \(b_i\) 表示为嵌入$ x_i$ 。这些嵌入可以选择以散列嵌入的形式来添加附加信息。然后,一系列交替的 Transformer 层和交叉注意力层将这些表征转换为patch 表征 \(p_i\),这些patch将由全局 transformer G 处理。这些Transformer 层使用局部块因果注意力掩码;每个字节都关注前面字节的固定窗口,该窗口通常可以跨越动态 patch 边界,但不能跨越文档边界。
局部解码器
与局部编码器类似,局部解码器 D 是一个基于 transformer 的轻量级模型,具有$ l_d \ll l_g$ 层,它将全局 patch 表征序列 \(o_j\) 解码为原始字节 \(y_i\) 。因为局部解码器根据解码的字节来预测原始字节序列,因此需要将局部编码器为字节序列生成的隐藏表征输入给局部解码器。在解码器交叉注意力中,query和key/value的角色互换,即字节表示现在是query,patch表示是key/vale。
交互
下图给出了几个模块之间的交互关系。局部编码器使用一个交叉注意力模块将字节表示编码为patch表示,其中patch表示作为查询,字节表示作为键/值,局部解码器使用类似的模块,但角色相反,即字节表示是查询,patch表示是键/值。此处交叉注意力k = 2。
6.2 Tokenformer
论文"TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS"主要探讨了一种革新性的基于参数token化的高效可扩展的Transformer架构设计方案,该方案通过参数token化实现了模型的高效扩展和计算优化。
研究团队引入了 TokenFormer来统一 Token-Token 和 Token-Parameters Interaction 的计算。其 Token-Parameter attention 具有灵活性,并能够处理可变数量的参数,从而本质上最大化了 Transformer 的灵活性,增强了模型的可扩展性。
主要贡献
Tokenformer消除了在增加模型规模时需要从头开始重新训练模型的需求,大大降低了成本。论文中提出的关键创新包括:
- 完全基于注意力的架构设计。该设计不仅用于token之间的交互,还用于token和模型参数之间的交互,提供了更大的架构灵活性。
- 参数token化方法。该方法将模型参数视为可学习的token,使用交叉注意力机制管理交互,同时支持动态参数扩展。
动机
论文的研究团队观察到,虽然Transformer架构在多个领域取得了巨大成功,但其可扩展性受到了严重限制,主要是因为在token-parameter交互计算方面采用了固定的线性投影方法。这种线性投影设计限制了模型的灵活性和可扩展性。因为这些投影层的参数大小是固定的,所以当需要增加模型规模时无法重用以前的小规模模型。而必须改变这些线性投影层的维度,这就需要重新训练整个模型,导致极大的计算开销。
为了克服这一挑战,论文作者提出了Tokenformer,这是一种新的完全基于注意力的更灵活的架构,包括token-参数交互,支持逐步扩展模型参数量等,从而大大降低了训练大型Tokenformer架构的总体成本。
架构
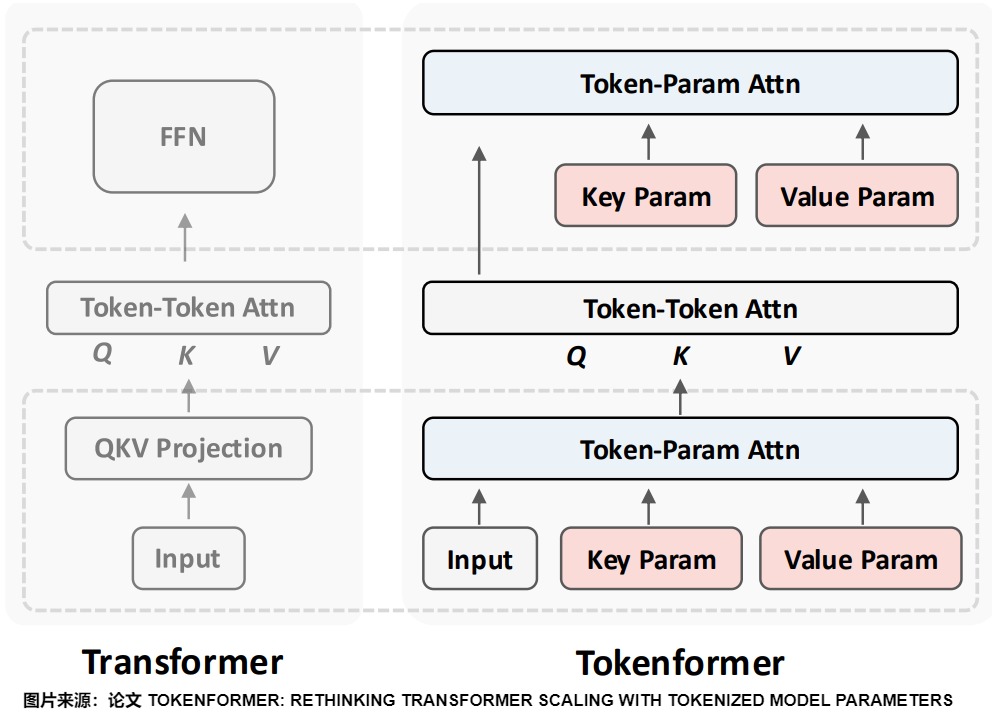
对比
下图给出了传统Transformer和Tokenformer之间的区别。对于vanilla Transformer,输入首先通过线性投影块来计算注意力块的输入,即Q、K和V矩阵。这个阶段涉及模型参数和输入token之间的交互,使用线性投影进行计算。然后,自注意力组件允许输入token之间相互交互,通过注意力块进行计算。最后,前馈网络(FFN)产生下一层的输出,此处同样表示使用线性投影计算的token和参数之间的交互。
Tokenformer则不同。为了计算自注意力块的输入(Q、K和V矩阵),输入token被送入一个称为token-参数注意力的新组件,在这里除了输入token外,还传入了参数。输入token代表查询部分,参数代表token-参数注意力块的键和值部分。然后是和vanilla Transformer相同的自注意力组件。最后为了准备下一层的输出,论文用另一个token-参数注意力块替代了FFN,这个token-参数注意力块的query来自自注意力块的输出,Key和value则用新的参数组件中获取。
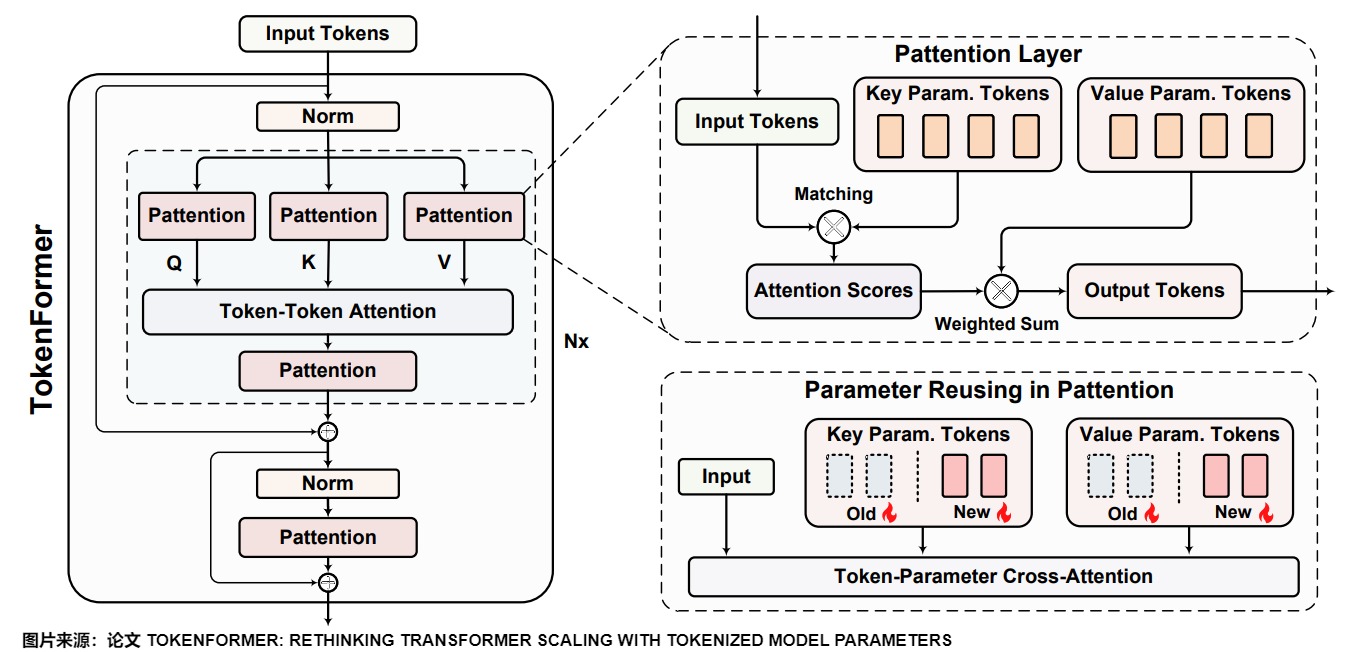
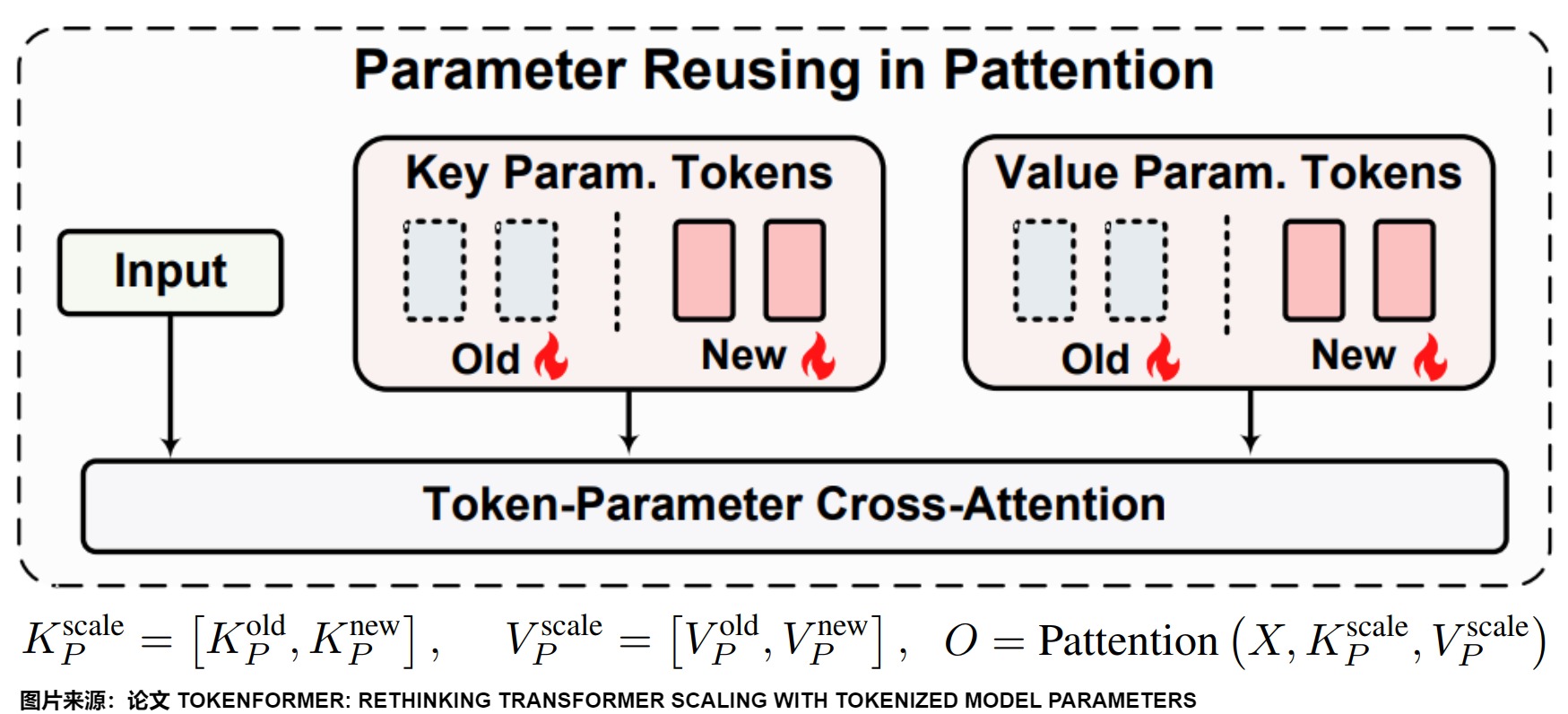
论文中的详细架构图展示了Tokenformer的完整设计。Tokenformer是一个完全由注意力驱动的架构,具有一个新的token参数注意力(Pattention)层。Pattention使用一组可学习的token来表示模型参数,这些可学习的token可以和输入token进行注意力计算。
在架构图的右下方,我们可以看到,当想要通过添加新参数来增量增加模型规模时,我们基本上是通过在每个Pattention块的键和值矩阵中添加更多的参数token行来扩展现有的键值参数集,同时保留已训练的参数token。从实验结果中可以看到,相比从头开始训练,规模增加的模型训练速度要快得多。
TokenFormer 提供一种新的看待模型的视角,即网络的计算就是一些 Tokens 相互任意交互。基于这些 Tokens (比如 data token, parameter token, memory token)和 attention 机制可以灵活地构造任意的网络结构。因此,该团队希望 TokenFormer 可以作为一种通用的网络结构。

Pattention机制
Tokenformer 的核心创新是 Token-Parameter Attention(Pattention) Layer,研究团队使用 Pattention Layer 替换掉标准 Transformer 中的所有的线性投影层。Pattention使用一组可训练的 tokens 作为模型参数,并通过交叉注意力来管理 Input Token 与这些 Parameter Tokens 之间的交互。
这样,Pattention层引入了一个额外的维度——参数token的数量——它独立于输入和输出通道维度运行。这种解耦使输入数据能够与可变数量的参数动态交互,通过重用预训练的模型提供增量模型缩放所需的灵活性。

上图给出了标准注意力和Pattention的对比。具体来说,Pattention就是让 input data 作为 query,同时引入了两组具有 n 个可学习的 Tokens:代表 key,\(V_p\)表示 value。图上A是从\(X\cdot K^{\top}_P\)得到的分数。Θ 是改进的 softmax,为了防止梯度 exponential 带来的梯度问题:τ 是标量scale factor,缺省设置为\(\sqrt n\)。f() 是任意非线性函数,默认使用 gelu。
通过这种方式,Pattention 层引入了一个额外的维度 —Parameter Token 的数量,这一维度独立于输入和输出维度。此解耦方式使得输入数据可以与可变数量的参数(variable number of parameters)进行交互,提供了增量模型扩展所需的灵活性。因此,训练更大的模型大大加快了速度,同时实现了与从头开始训练的 Transformer 相当的性能。
论文对比了标准注意力机制和新提出的Pattention机制,这种新的注意力机制设计具有以下优势:更好的梯度稳定性;支持动态参数扩展;保持输出分布的连续性。
FFN的革新
在Tokenformer中,传统Transformer中的前馈网络被替换为两个连续的pattention块,然后通过残差连接与输入token合并,这样可以支持模型参数的动态扩展。
复用
从TokenFormer 灵活的性质,我们可以延伸出很多应用。这里以增量式 model scaling 为例。由于Pattention层的多功能设计,它非常适合沿参数轴(parameter axis)进行大规模模型训练,这允许通过重用较小的预训练对应模型的参数来增量开发较大的模型。假设已经训练好了一个 TokenFormer,其 key parameters 和 value parameters 计为 \(K_P^{old}\)和 \(V_P^{old}\)。如下图所示,我们将加入新的重新初始化的 key-value parameter pairs,计为 \(K_P^{new}\)和 \(V_P^{new}\),进而和原有参数一起组合成新的 key-value 集。然后使用 pattention layer,让 input data 与 Parameter tokens 进行交互。直观的理解就是每个 Key-Value 代表一种学好的 pattern,其组成一个巨大的知识库。incremental scaling 就是在原有的知识库上进一步拓展训练。
这种缩放方案允许在不改变输入或输出维度的情况下集成任意数量的参数。如图3所示,这种方法显著提高了更大规模模型的训练效率,而不会降低性能。重要的是,通过将Knew P初始化为零,类似于LoRA技术,该模型可以完美地从预训练阶段恢复模型状态,而不会丢失所学的知识,从而促进更快的收敛并加速整体缩放过程。
总结
vanilla Transformer 模型通常将处理单个 Token 所需的计算分为两个部分:与其他 Token 的交互(Token-Token Interaction)和涉及模型参数的计算(Token-Parameter Interaction)。Token-Parameter 计算主要依赖于固定的 linear projection,大大限制 model size 的 scaling。Scaling model 是通常改变模型结构,往往需要从头训练整个模型,带来了过多的资源消耗,使其越来越不切实际。
TokenFormer 则打破了原有人们区别看待 data 和 model 的观念,使用 token 这一概念来建模所有的计算。即,不仅像原始 Transformer 一样将输入数据进行 token 化,将模型参数也视为一种 token,而且将 attention 机制拓展到 Token 和模型参数的交互中,把计算统一为各种不同的 token (比如data tokens and parameter tokens) 之间通过注意力机制来进行交互。这大大增强了 Token-Parameter 交互的灵活性,从而能够基于训好的模型上增量的拓展新的更大的模型,从而显著降低了训练负担。
6.3 LCM
论文"The Future of AI: Exploring the Potential of Large Concept Models"提出了大型概念模型(Large Concept Models, LCMs)。这篇论文不仅是对现有大语言模型(LLMs)局限性的深刻反思,更是对AI未来发展路径的前瞻性探索。
问题
LLM的Token粒度其实并不是一个好的表达语义的方式,基于Token的学习方式对于学习语义来说效率也比较低。 这种“逐词预测”的模式,虽然在很多任务上取得了成功,但在处理长文本和复杂概念时,容易出现“只见树木,不见森林”的问题。
因为人脑并不在单词层面运作。人的思维明显是分层的。网上一个非常恰当的例子是:你并不是基于学习在每个路口如何打方向盘,来学习如何从北京开到广州的。这里的每个路口如何打方向盘就是一个过于细粒度的单元,也就是对应到这里的Token。
之前随着推理硬件性能的提升和各种优化方式的出现,看起来token粒度过小对于性能的影响已经不那么大了。然而近期随着推理期计算等新事物的实现,强化学习在AI各种领域中愈发重要。这需要模型具备语义空间中的能力,而不仅仅是在token序列空间视角中获取到的能力。因此需要寻找一个更好的与Token不同的更接近语义粒度的建模方式。
动机
受人类构思交流的高层级思路启发,Meta AI研究员提出全新语言建模新范式LCM(大概念模型),解耦语言表示与推理。简而言之,LCM将token抛弃,转而采用更高级别的「概念」在「句子嵌入空间」对推理(reasoning)进行建模,直接操作高层级显式语义表示信息,彻底让推理摆脱语言和模态制约。新系统将不再单纯基于下一个token预测,而是像婴儿和小动物那样通过观察和互动来理解世界。
为什么需要「概念」?这是因为现有的LLM都缺少人类智能的一个重要的特点:在多级别抽象上显式的推理和规划。比如在解决一项复杂的任务或撰写一份长篇文档时,人类通常采用自上而下的流程:首先在较高的层次上规划整体结构,然后逐步在较低的抽象层次上添加细节。具有显式的分层结构模型更适合创建长篇输出。而现在市面上的语言模型,比如大家熟悉的GPT,虽然能写诗、写代码、聊天,但它们本质上还是一个字一个字地“猜”出来的。想象一下,就像一个只会背诵但不懂意思的鹦鹉,虽然能流利地说话,但缺乏真正的理解。
LCM的出现,就是要打破这个局面。LCMs不再执着于“下一个词是什么?”,而是思考“这句话、这段话、乃至整篇文章的核心概念是什么?” 这说明AI的“思维”模式正经历着从“词语”到“概念”的质的飞跃。
思路
论文将抽象层次限制为2种:子词token(subword token)和概念。而所谓的「概念」被定义为整体的不可分的「抽象原子见解」。在现实中,一个概念往往对应于文本文档中的一个句子,或者等效的语音片段。论文作者认为,与单词相比,句子才是实现语言独立性的恰当的单元。这与当前基于token的LLMs技术形成了鲜明对比。
LCM的核心在于它不再执着于预测下一个词,而是在更高的语义层级——“概念”上进行思考。它把句子看作一个概念单元,并用一种叫做SONAR的句子嵌入技术来表示这些概念。这意味着LCM处理的不再是单个的词语,不再像传统语言模型那样逐词预测,而是考虑整句话的含义。在句子表征空间中进行建模。这意味着,LCM将句子视为一个概念单元,并利用句子嵌入(sentence embeddings)来表示这些概念。LCM的目标是预测下一个句子的嵌入向量,也就是下一个“概念”。这种方法能够更好地捕捉文本的整体语义结构,使模型能够在更高的抽象层面上进行推理。
例如在句子:
Tim 并不擅长运动,他认为如果参加一项运动就会有所改变,他尝试加入几个团队,但没有一个团队录取他。不同的概念将是:
Tim 并不擅长运动。
他认为如果参加一项运动就会有所改变。
他尝试加入几个团队。
但没有一个团队录取他。我们可以看到每个概念都代表了句子的一个想法。
新方法将与token级别的处理不同,更靠近在抽象空间的(分层)推理。上下文在LCM所设计的抽象空间内表达,但抽象空间与语言或模态无关。也就是说在纯粹的语义层面对基本推理过程进行建模,而不是对推理在特定语言中的实例建模。具体而言,只需要固定长度的句子嵌入空间的编码器和解码器,就可以构造LCM,处理流程非常简单:
- 首先将输入内容分割成句子,然后用编码器对每个句子进行编码,以获得概念序列,即句子嵌入。
- 然后,大概念模型(LCM)对概念序列进行处理,在输出端生成新的概念序列。
- 最后,解码器将生成的概念解码为子词(subword)序列。
总体架构
训练大概念模型需要基于句子嵌入空间的解码器和编码器来训练一个新的嵌入空间,针对推理架构进行优化。此论文使用其开源的SONAR作为句子嵌入的解码器和编码器。或者说,LCM的核心组件是句子嵌入模型SONAR。SONAR是一个强大的多语言、多模态句子表征模型,支持超过200种语言和语音输入。LCM在SONAR嵌入空间中进行操作,这意味着LCM的输入和输出都是SONAR嵌入向量,而不是离散的词语。这种基于连续向量空间的建模方式,为LCM带来了诸多优势。
通过SONAR,LCMs能够在概念层面进行推理,而不仅仅是进行词语的排列组合。例如,当LCMs处理“全球变暖导致海平面上升”这个句子时,它不仅理解了每个单词的含义,更重要的是,它理解了“全球变暖”、“海平面上升”这两个概念,以及它们之间的因果关系。
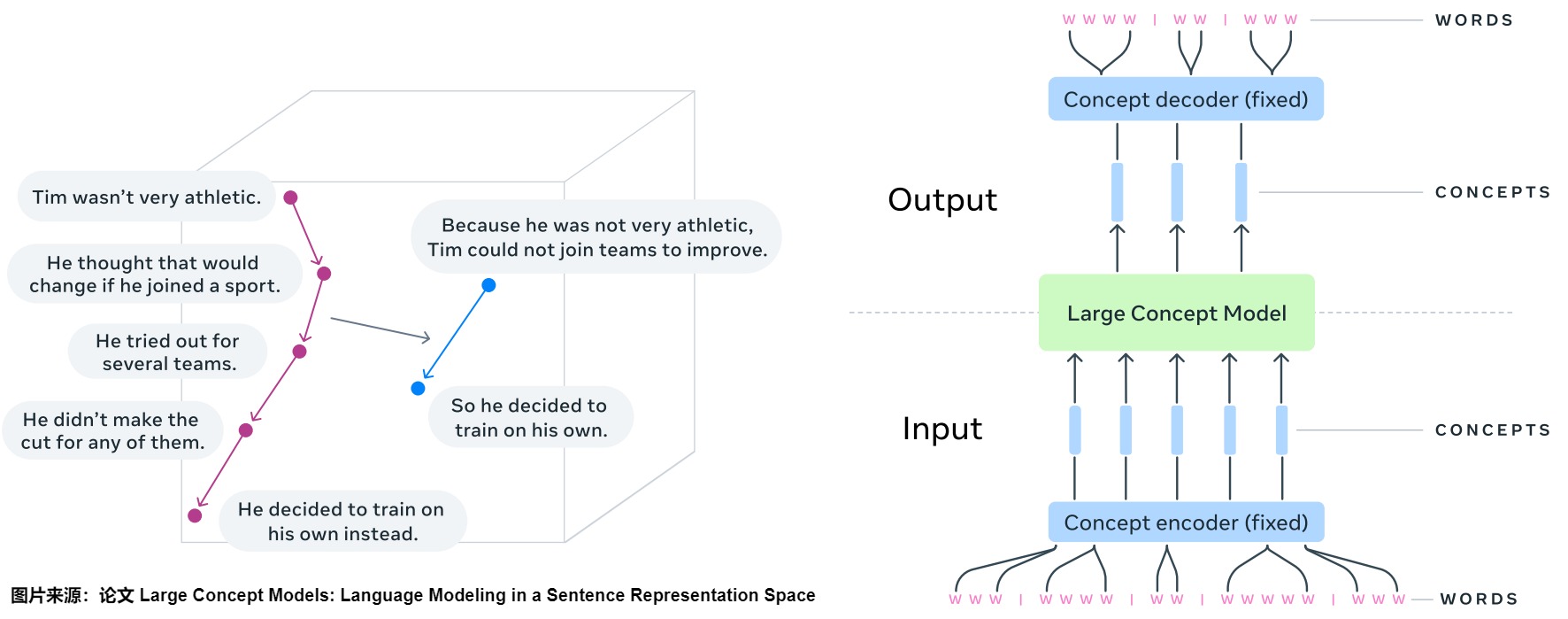
左:概念嵌入空间中推理的可视化(摘要任务)。右:大型概念模型(LCM)的基本架构。
SONAR解码器和编码器(图中蓝色部分)是固定的,不用训练。LCM(图中绿色部分)输出的概念可以解码为其他语言或模态,而不必从头执行整个推理过程。同样, 某个特定的推理操作,如归纳总结,可以在任何语言或模态的输入上以零样本(zero-shot)模式进行。因为推理只需操作概念。
总之,LCM既不掌握输入语言或模态的信息,也不以特定语言或模态生成输出。
细节
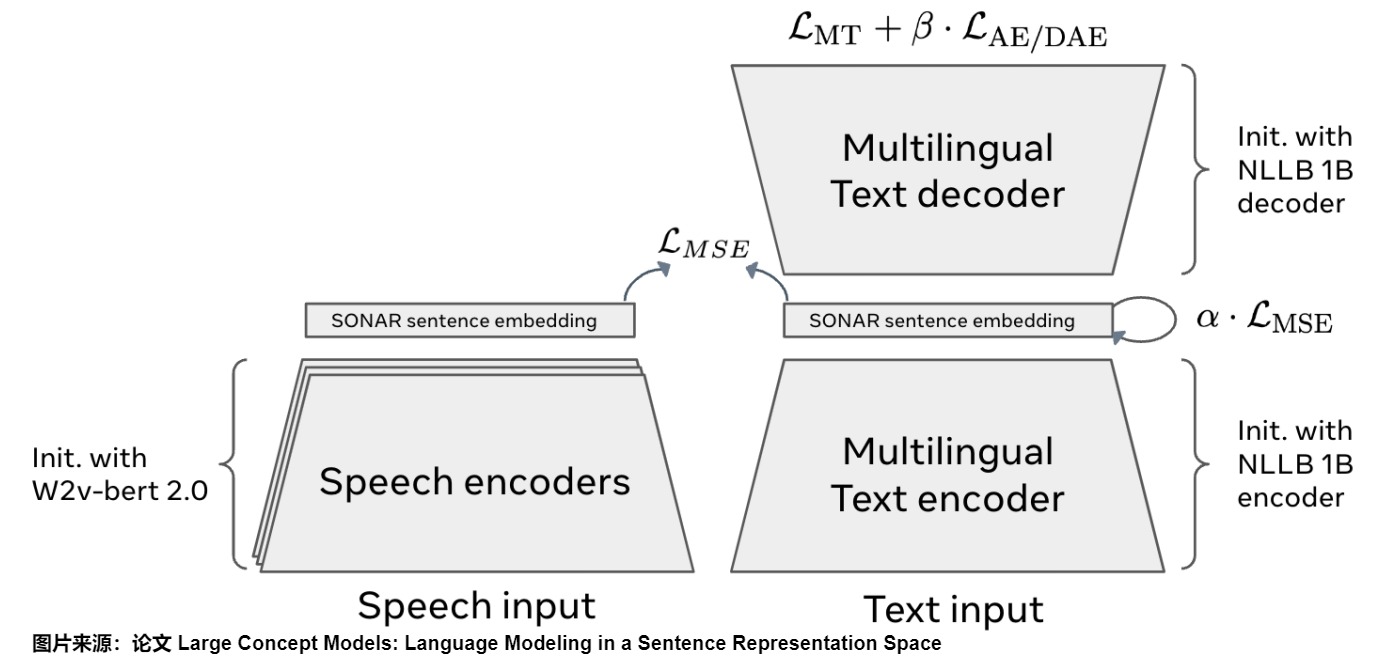
SONAR嵌入空间
SONAR文本嵌入空间使用编码器/解码器架构进行训练,以固定大小的瓶颈代替交叉注意力,如下图。
为了探索在SONAR空间中进行语言建模的最佳实践,Meta AI的研究人员设计了多种LCM架构变体。
Base-LCM
下个概念预测(next concept prediction)的基线架构是Base-LCM,这是一个基于Transformer解码器的基础模型。它将前一个句子的SONAR嵌入作为输入(先行概念),并预测下一个句子的嵌入(概念)。这种架构简单直接,易于理解和实现。
如下图所示,Base-LCM配备了「PostNet」和「PreNet」。PreNet对输入的SONAR嵌入进行归一化处理,并将它们映射到模型的隐藏维度。
Base-LCM在半监督任务上学习, 模型会预测下一个概念,通过优化预测的下一个概念与真实的下一个概念的距离来优化参数,也就是通过MSE回归来优化参数。

基于扩散的LCM(Diffusion-based LCM)
基于扩散的LCM是一种生成式潜变量模型,它能学习一个模型分布\(p_θ\) ,用于逼近数据分布q。与基础LCM相似,可以将扩散LCM建模视为自动回归模型,每次在文档中生成一个概念。
具体而言, 在序列的位置n上,模型以之前全部的概念为条件,来预测在此处某概念的概率。
单塔扩散LCM(One-Tower Diffusion LCM)
该模型引入了扩散模型(Diffusion Model)的思想,通过逐步添加噪声,然后去噪的方式来生成下一个句子的嵌入。这种方法可以生成更具多样性和创造性的文本。
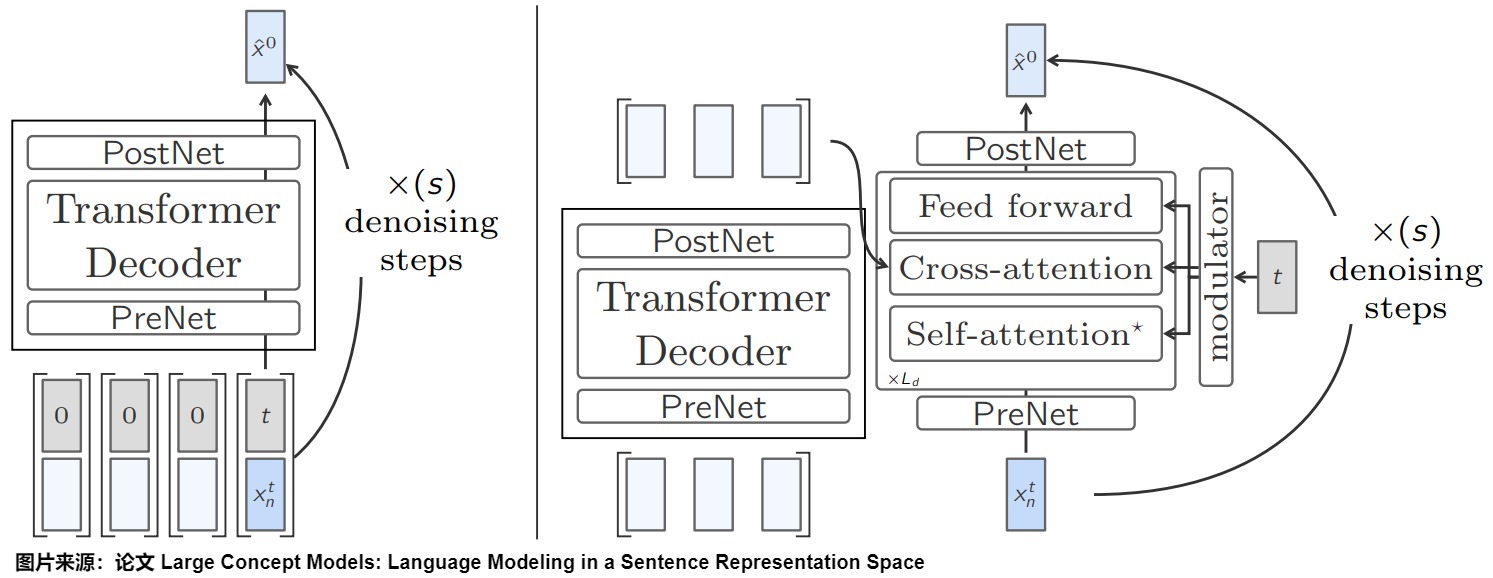
如上图左,单塔扩散LCM由一个Transformer主干组成,其任务是在给定句子嵌入和噪音输入的条件下预测下一个句子嵌入 。
双塔扩散LCM(Two-Tower Diffusion-LCM)
如上图右侧,该模型将编码器和解码器分离,编码器负责处理上下文信息,解码器负责生成下一个句子的嵌入。这种架构更类似于传统的序列到序列模型,可以更好地捕捉长距离依赖关系。
第一个模型,即上下文标注模型,将上下文向量作为输入,并对其进行因果编码。然后,上下文分析器的输出结果会被输入第二个模型,即去噪器(denoiser)。去噪器通过迭代去噪潜高斯隐变量来预测下一个句子嵌入 。
Quant-LCM
为了提高计算效率,该模型对SONAR空间进行量化,将连续的嵌入向量转换为离散的码本。这种方法可以在不损失太多性能的情况下显著降低计算成本。
在图像或语音生成领域,目前有两种处理连续数据生成的主要方法:一种是扩散建模,另一种是先对数据进行学习量化,然后再在这些离散单元的基础上建模。此外,文本模态仍然是离散的,尽管处理的是SONAR空间中的连续表示,但全部可能的文本句子(少于给定字符数)都是SONAR空间中的点云,而不是真正的连续分布。这些考虑因素促使作者探索对SONAR表示进行量化,然后在这些离散单元上建模,以解决下一个句子预测任务。最后,采用这种方法可以自然地使用温度、top-p或top-k采样,以控制下一句话表示采样的随机性和多样性水平。
6.4 动作Tokenizer
论文"FAST: Efficient Action Tokenization for Vision-Language-Action Models"提出了一种高效的机器人动作Tokenization方法,能把动作像语言一样,用离散Token表示。这可以让机器人技术能够与自回归Transformer训练流程无缝衔接,提升了从大规模互联网数据预训练的迁移能力,增强了机器人执行语言指令的能力。
FAST使用了一种基于离散余弦变换(DCT)的压缩算法,来提高VLA模型的训练速度。DCT是一种频域变换,因简洁和计算高效,常用于压缩算法,如JPEG图像压缩、MP3音频的编解码。
FAST首先对输入的动作进行归一化,然后对每个动作维度分别应用离散余弦变换(DCT),最后用BPE来压缩DCT矩阵。将DCT和字节对编码(BPE)结合,就能把原始动作块压缩成数量少但更密集的动作Token。

通常每个动作块包含30-60个Token,和以前的动作Tokenization方法相比,压缩率提高了10倍。
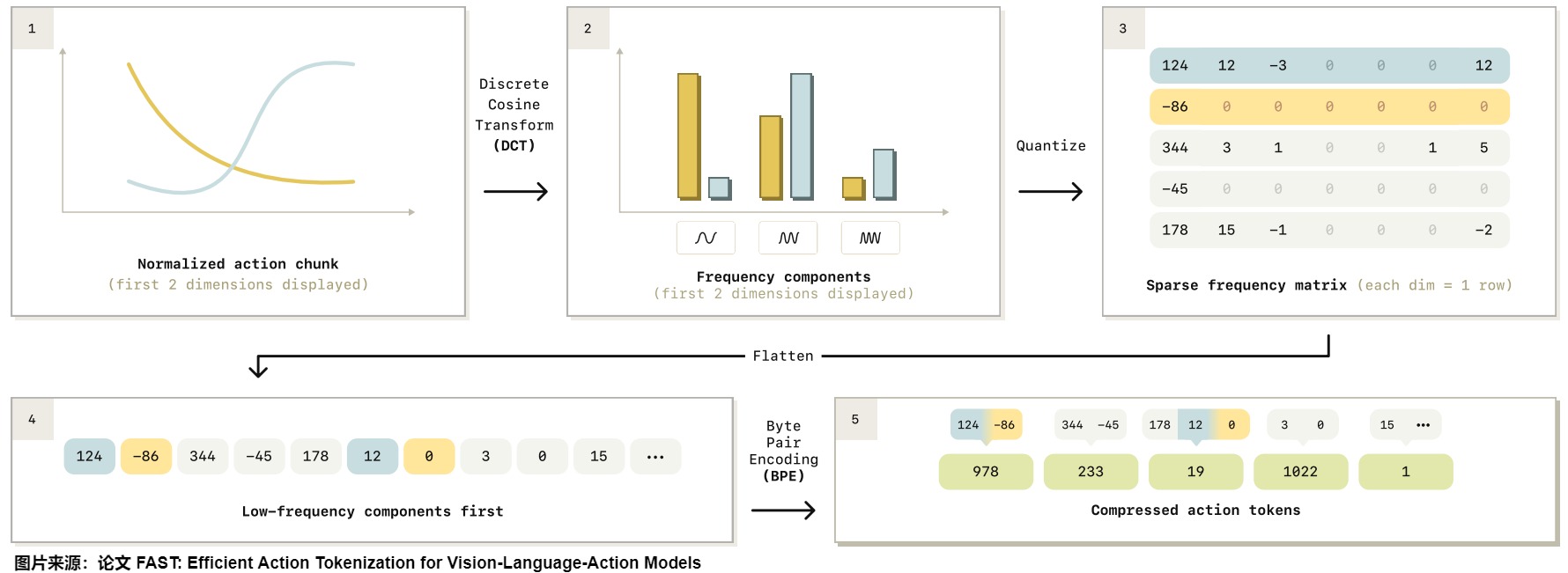
上图给出了FAST动作token化的流水线概述。给定一个归一化的动作块,我们应用离散余弦变换(DCT)将信号转换为频域。然后,我们对DCT系数进行量化,并使用字节对编码(BPE)将每维DCT系数的展平序列压缩为最终的动作标记序列。详细说明见第V-B节。
0xFF 参考
Byte Latent Transformer: Patches Scale BetterThan Tokens——字节潜在Transformer:patch比token更高效 Together_CZ
Byte Pair Encoding and WordPiece Model详解 Yuki
BytePiece:更纯粹、更高压缩率的Tokenizer 苏剑林
FAST: Efficient Action Tokenization for Vision-Language-Action Models
https://huggingface.co/learn/nlp-course/chapter6/6?fw=pt#implementing-wordpiece
Huggingface详细教程之Tokenizer库 基本粒子
JAPANESE AND KOREAN VOICE SEARCH
Large Concept Models: Language Modeling in a Sentence Representation Space
LLM时代Transformer中的Positional Encoding
LLM还没研究透,LCM又来了 Alex [算法狗]
Luke:深入理解NLP Subword算法:BPE、WordPiece、ULM Luke
Neural Machine Translation of Rare Words with Subword Units
Neural Machine Translation of Rare Words with Subword Units
Neural Machine Translation with Byte-Level Subwords
NLP 中的Tokenizer:BPE、BBPE、WordPiece、UniLM 理论
NLP-Tokenizer-BPE算法原理及代码实现 爱喝热水的lucky
NLP三大Subword模型详解:BPE、WordPiece、ULM
NLP中的Tokenization
NLP分词模型:BPE、WordPiece、ULM、SentencePiece
Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral
Robin3D: Improving 3D Large Language Model via Robust Instruction Tunin
Robin3D: Improving 3D Large Language Model via Robust Instruction Tuning
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Tokenization不存在了?Meta最新研究,无需Tokenizer的架构来了 [PaperWeekly]
Tokenization,再见!Meta提出大概念模型LCM,1B模型干翻70B? 新智元
UC伯克利等提出具身智能「动作Tokenizer」,效率飙升5倍! 新智元
【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器(tokenization & tokenizers):BPE/WordPiece/ULM & beyond
【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器(tokenization & tokenizers):BPE/WordPiece/ULM & beyond OpenLLMAI
从2019年到现在,是时候重新审视Tokenization了 机器之心
大模型中的分词器tokenizer
大模型中的分词器tokenizer:BPE、WordPiece、Unigram LM、SentencePiece
智能连接:碳原子与Token 伍鹏 [AI的无限游戏]
机器如何认识文本 ?NLP中的Tokenization方法总结
深入理解NLP Subword算法:BPE、WordPiece、ULM
理解NLP最重要的编码方式 — Byte Pair Encoding (BPE),这一篇就够了
https://arxiv.org/pdf/2412.08821
https://github.com/karpathy/minbpe
https://huggingface.co/learn/nlp-course/chapter6/5%3Ffw%3Dpt)
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
Kudo, Taku. "Subword regularization: Improving neural network translation models with multiple subword candidates." arXiv preprint arXiv:1804.10959 (2018)
Neural Machine Translation of Rare Words with Subword Units Rico Sennrich, Barry Haddow, Alexandra Birch