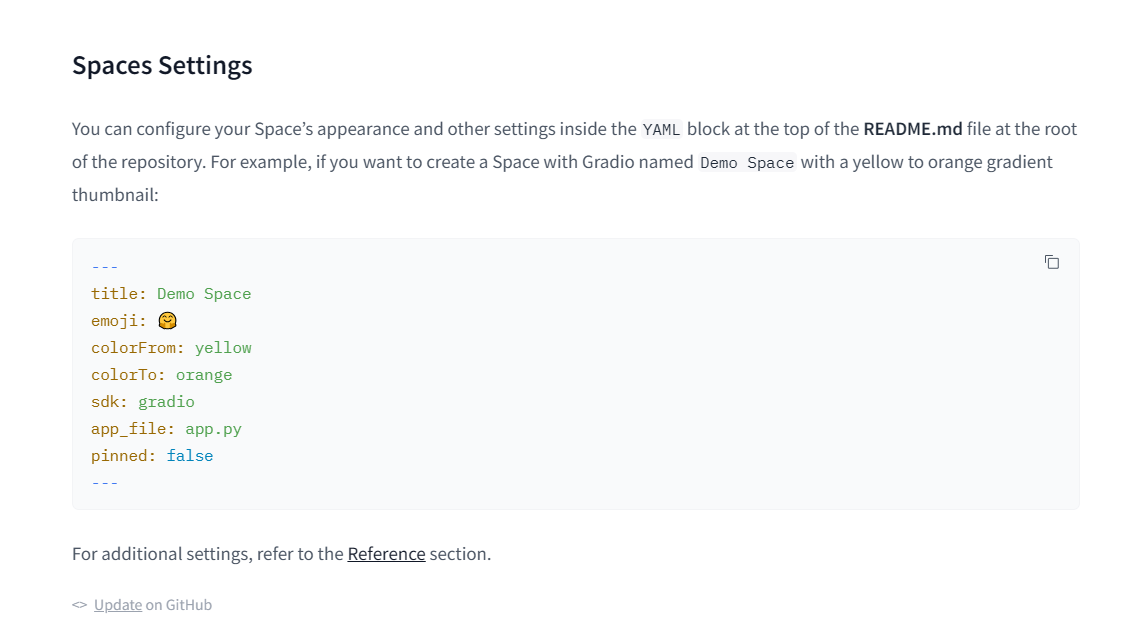
精读《Java Performance》第6章(编译阈值/逃逸分析数值临界点)的核心内容总结:
1. 编译阈值(Compilation Thresholds)
-
核心概念:
JIT(Just-In-Time)编译器并非立即编译所有代码,而是通过观察方法调用或循环执行次数(称为“热度”)决定是否触发编译。- 分层编译:现代JVM使用分层编译(C1、C2编译器搭配工作):
- C1编译器:快速编译(低优化),关注启动性能。
- C2编译器:慢速编译(高度优化),关注长期运行的性能。
- 阈值参数:
-XX:CompileThreshold:触发JIT编译的方法调用次数的默认值(例如C1为1500次,C2为10000次)。-XX:TierXCompileThreshold(X为层数):精细控制不同编译层的触发条件。
- 机制影响:过低的阈值可能导致过早编译非热点代码,浪费资源;过高的阈值可能延迟优化。
- 分层编译:现代JVM使用分层编译(C1、C2编译器搭配工作):
-
应学会:
- 通过
-XX:+PrintCompilation监控编译过程,识别热点代码。 - 在高并发或低延迟系统中,通过调整阈值平衡启动时间与峰值性能。
- 通过
2. 逃逸分析(Escape Analysis)与数值临界点
-
核心概念:
JVM通过逃逸分析判断对象的生命周期是否“逃逸”出方法或线程作用域,从而应用以下优化:- 栈上分配(Stack Allocation):对象直接分配在栈上(而非堆),避免GC开销。
- 锁消除(Lock Elision):若同步锁仅限单线程访问,则移除锁操作。
- 标量替换(Scalar Replacement):将对象分解为基本类型变量存储。
-
临界点与限制:
- 数值复杂性限制:逃逸分析复杂度较高时(如多层嵌套循环、过多对象引用),JVM可能放弃优化。
- 逃逸状态分类:
- NoEscape:对象未离开方法(可完全优化)。
- ArgEscape:对象作为方法参数传递但未被其他线程访问(部分优化)。
- GlobalEscape:对象逃逸到外部(无法优化)。
- 触发条件:热点代码(达到编译阈值后)才会进行逃逸分析。
-
应学会:
- 编写有利于逃逸分析的代码:
- 尽可能缩小对象作用域。
- 避免在循环中创建庞大对象。
- 谨慎使用对象作为返回值或传递到外部方法。
- 结合
-XX:+DoEscapeAnalysis(默认启用)与-XX:+PrintEscapeAnalysis(需调试版本JVM)验证优化效果。
- 编写有利于逃逸分析的代码:
3. 关键性能调优技巧
- 参数调整:
-XX:+TieredCompilation:启用分层编译以提高预热效率。-XX:InlineSmallCode:控制内联代码大小,间接影响逃逸分析效果。
- 代码优化:
- 避免长时间运行的方法中存在大对象分配(优先使用局部变量)。
- 单线程环境下优先用
ThreadLocal存储对象,减少逃逸可能性。
- 监控工具:
JITWatch:可视化JIT编译过程,分析优化结果。Async Profiler:检测代码热点和逃逸优化失效点。
应掌握的核心理念:
- 编译与优化是动态的:JIT编译依赖于运行时的热点探测,代码的实际执行路径比静态结构更重要。
- 临界点是权衡结果:所有优化都有成本(如分析时间、内存消耗),JVM仅在收益明显时应用高级优化。
- 理解数值边界:开发中应避免接近逃逸分析的复杂度边界(例如过深的对象嵌套),防止优化失效。
推荐实践:
- 对性能敏感模块,通过JMH(Java Microbenchmark Harness)测试编译阈值和逃逸优化的实际影响。
- 高频交易或实时系统中,可用
-XX:CompileThreshold降低阈值提前优化关键路径,但需权衡启动延迟。
通过本章学习,读者应能定位代码中的潜在编译与优化瓶颈,并借助JVM机制提升执行效率。