以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。
以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。技术背景
在前面一篇文章中,我们介绍过Cython+CUDA框架下实现一个简单的Gather算子的方法。这里演示Gather算子的升级版本实现——BatchGather算子。不过这里只是加了一个Batch维度,并没有添加其他的维度,例如Dimension维度,在这里暂不考虑。
CUDA头文件
这里我们保留了原本的Gather部分,只添加一个BatchGather的运算,以下为cuda_index.cuh的内容:
#include <stdio.h>extern "C" float Gather(float *source, int *index, float *res, int N, int M);
extern "C" float BatchGather(float *source, int *index, float *res, int N, int M, int B);
BatchGather只是在Gather的基础上加了一个B的维度。除了CUDA算子本身的头文件之外,这里我们还使用到了异常捕获头文件error.cuh:
#pragma once
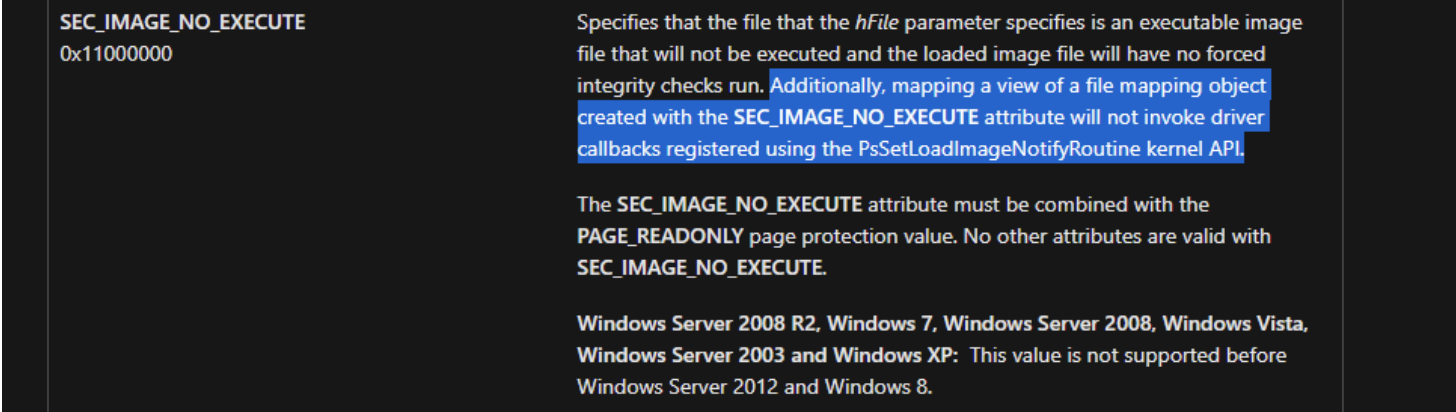
#include <stdio.h>#define CHECK(call) do{const cudaError_t error_code = call; if (error_code != cudaSuccess){printf("CUDA Error:\n"); printf(" File: %s\n", __FILE__); printf(" Line: %d\n", __LINE__); printf(" Error code: %d\n", error_code); printf(" Error text: %s\n", cudaGetErrorString(error_code)); exit(1);}} while (0)
其中的宏可用于检测CUDA函数所抛出的异常。另外还有一个用于统计CUDA函数运行时长的头文件:
#pragma once
#include <stdio.h>
#include <cuda_runtime.h>// 宏定义,用于测量CUDA函数的执行时间
#define TIME_CUDA_FUNCTION(func) \do { \cudaEvent_t start, stop; \float elapsedTime; \cudaEventCreate(&start); \cudaEventCreate(&stop); \cudaEventRecord(start, NULL); \\func; \\cudaEventRecord(stop, NULL); \cudaEventSynchronize(stop); \cudaEventElapsedTime(&elapsedTime, start, stop); \printf("Time taken by function %s is: %f ms\n", #func, elapsedTime); \\cudaEventDestroy(start); \cudaEventDestroy(stop); \} while (0)// 宏定义,用于测量CUDA函数的执行时间并返回该时间
#define GET_CUDA_TIME(func) \({ \cudaEvent_t start, stop; \float elapsedTime = 0.0f; \cudaEventCreate(&start); \cudaEventCreate(&stop); \cudaEventRecord(start, NULL); \\func; \\cudaEventRecord(stop, NULL); \cudaEventSynchronize(stop); \cudaEventElapsedTime(&elapsedTime, start, stop); \\cudaEventDestroy(start); \cudaEventDestroy(stop); \\elapsedTime; \})
可选择直接打印时长,也可以选择返回时长的float值。
CUDA文件
接下来就是正式的CUDA函数内容cuda_index.cu:
// nvcc -shared ./cuda_index.cu -Xcompiler -fPIC -o ./libcuindex.so
#include <stdio.h>
#include "cuda_index.cuh"
#include "error.cuh"
#include "record.cuh"__global__ void GatherKernel(float *source, int *index, float *res, int N){int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N){res[idx] = source[index[idx]];}
}extern "C" float Gather(float *source, int *index, float *res, int N, int M){float *souce_device, *res_device;int *index_device;CHECK(cudaMalloc((void **)&souce_device, M * sizeof(float)));CHECK(cudaMalloc((void **)&res_device, N * sizeof(float)));CHECK(cudaMalloc((void **)&index_device, N * sizeof(int)));CHECK(cudaMemcpy(souce_device, source, M * sizeof(float), cudaMemcpyHostToDevice));CHECK(cudaMemcpy(res_device, res, N * sizeof(float), cudaMemcpyHostToDevice));CHECK(cudaMemcpy(index_device, index, N * sizeof(int), cudaMemcpyHostToDevice));int block_size = 1024;int grid_size = (N + block_size - 1) / block_size;float timeTaken = GET_CUDA_TIME((GatherKernel<<<grid_size, block_size>>>(souce_device, index_device, res_device, N)));CHECK(cudaGetLastError());CHECK(cudaDeviceSynchronize());CHECK(cudaMemcpy(res, res_device, N * sizeof(float), cudaMemcpyDeviceToHost));CHECK(cudaFree(souce_device));CHECK(cudaFree(index_device));CHECK(cudaDeviceSynchronize());CHECK(cudaFree(res_device));CHECK(cudaDeviceReset());return timeTaken;
}__global__ void BatchGatherKernel(float *source, int *index, float *res, int N, int M, int B){int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N*B){int batch_idx = idx / N;int source_idx = batch_idx * M + index[idx];res[idx] = source[source_idx];}
}extern "C" float BatchGather(float *source, int *index, float *res, int N, int M, int B){float *souce_device, *res_device;int *index_device;CHECK(cudaMalloc((void **)&souce_device, B * M * sizeof(float)));CHECK(cudaMalloc((void **)&res_device, B * N * sizeof(float)));CHECK(cudaMalloc((void **)&index_device, B * N * sizeof(int)));CHECK(cudaMemcpy(souce_device, source, B * M * sizeof(float), cudaMemcpyHostToDevice));CHECK(cudaMemcpy(res_device, res, B * N * sizeof(float), cudaMemcpyHostToDevice));CHECK(cudaMemcpy(index_device, index, B * N * sizeof(int), cudaMemcpyHostToDevice));int block_size = 1024;int grid_size = (B * N + block_size - 1) / block_size;float timeTaken = GET_CUDA_TIME((BatchGatherKernel<<<grid_size, block_size>>>(souce_device, index_device, res_device, N, M, B)));CHECK(cudaGetLastError());CHECK(cudaDeviceSynchronize());CHECK(cudaMemcpy(res, res_device, B * N * sizeof(float), cudaMemcpyDeviceToHost));CHECK(cudaFree(souce_device));CHECK(cudaFree(index_device));CHECK(cudaDeviceSynchronize());CHECK(cudaFree(res_device));CHECK(cudaDeviceReset());return timeTaken;
}
这里传入到CUDA之前,我们需要在Cython或者Python中把相关的数据压缩为一维,所以传入CUDA函数的是一个一维的指针。相比于单一的Gather操作,BatchGather中的几个输入含义有所变化,例如N表示的是单Batch的Index长度,M表示的是单Batch的源数组长度。
Cython文件
对于一个新的Batch函数来说,我们需要构建一个新的Cython调用函数wrapper.pyx:
# cythonize -i -f wrapper.pyximport numpy as np
cimport numpy as np
cimport cythoncdef extern from "<dlfcn.h>" nogil:void *dlopen(const char *, int)char *dlerror()void *dlsym(void *, const char *)int dlclose(void *)enum:RTLD_LAZYctypedef float (*GatherFunc)(float *source, int *index, float *res, int N, int M) noexcept nogil
ctypedef float (*BatchGatherFunc)(float *source, int *index, float *res, int N, int M, int B) noexcept nogilcdef void* handle = dlopen('/path/to/libcuindex.so', RTLD_LAZY)@cython.boundscheck(False)
@cython.wraparound(False)
cpdef float[:] cuda_gather(float[:] x, int[:] idx):cdef:GatherFunc Gatherfloat timeTakenint N = idx.shape[0]int M = x.shape[0]float[:] res = np.zeros((N, ), dtype=np.float32)Gather = <GatherFunc>dlsym(handle, "Gather")timeTaken = Gather(&x[0], &idx[0], &res[0], N, M)print (timeTaken)return res@cython.boundscheck(False)
@cython.wraparound(False)
cpdef float[:] batch_cuda_gather(float[:] x, int[:] idx, int B):cdef:BatchGatherFunc BatchGatherfloat timeTakenint N = idx.shape[0] // Bint M = x.shape[0] // Bfloat[:] res = np.zeros((B*N, ), dtype=np.float32)BatchGather = <BatchGatherFunc>dlsym(handle, "BatchGather")timeTaken = BatchGather(&x[0], &idx[0], &res[0], N, M, B)print (timeTaken)return reswhile not True:dlclose(handle)
这里我们还是接受一维的数组,多引入一个Batch维度的参数B,其他的都是一样的。
Python调用文件
最后是用来调用的最上层Python端的代码test_gather.py:
import numpy as np
np.random.seed(0)
from wrapper import batch_cuda_gatherB = 2
M = 1024 * 1024 * 128
N = 1024 * 1024x = np.random.random((M*B,)).astype(np.float32)
idx = np.random.randint(0, M, (N*B,)).astype(np.int32)np_res = np.zeros((B, N), dtype=np.float32)
for i in range(B):np_res[i] = x.reshape((B,-1))[i][idx.reshape((B, -1))[i]]
np_res = np_res.reshape(-1)res = np.asarray(batch_cuda_gather(x, idx, B))
print (res.shape)
print ((res==np_res).sum())
为了方便处理,在构建数据的时候,我们直接在生成数据阶段就生成一维的数据,然后直接调用Cython函数进行CUDA相关运算。
运行方法
首先将CUDA文件编译成动态链接库,使其可以在Cython中被调用。然后将Cython文件编译成动态链接库,使其可以在Python中被调用。最后运行Python代码即可:
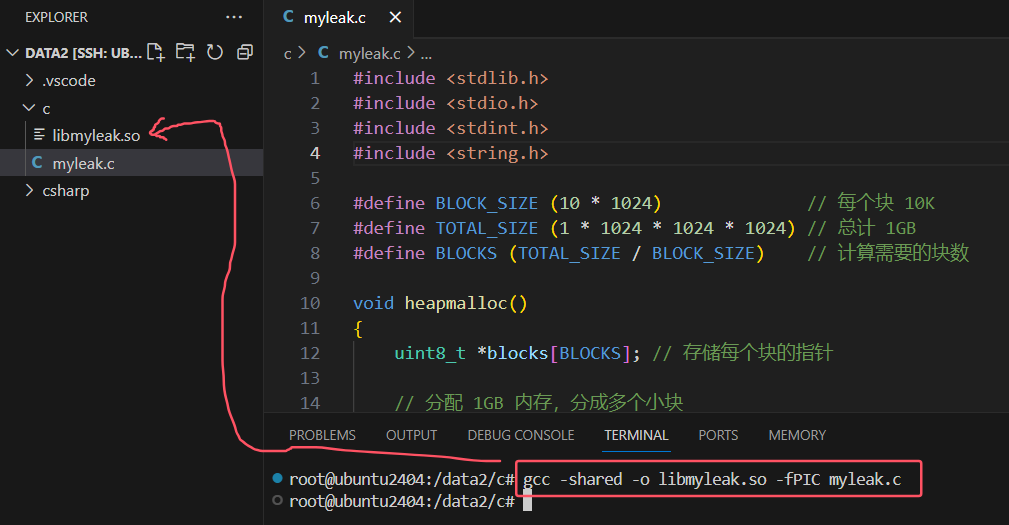
$ nvcc -shared ./cuda_index.cu -Xcompiler -fPIC -o ./libcuindex.so
$ cythonize -i -f wrapper.pyx
$ python3 test_gather.py
运行结果如下:
# 总结概要
以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。# 版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/cython-cuda-batchgather.html作者ID:DechinPhy更多原著文章:https://www.cnblogs.com/dechinphy/请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html