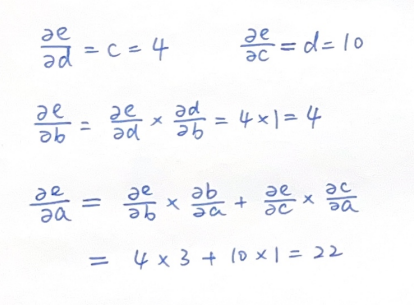在Transformer模型中,除了CLS标记外,还有许多其他的特殊标记(special tokens),这些标记用于帮助模型理解输入序列的结构和任务要求。以下是一些常见的特殊标记及其用途:
1. BOS (Beginning of Sentence)
- 用途:表示句子的开始,常用于生成任务(如GPT、Seq2Seq)。
- 示例:在生成任务中,模型会从BOS标记开始生成文本。
2. EOS (End of Sentence)
- 用途:表示句子的结束,用于生成任务或指示多句模式中某句的终止。
- 示例:在生成任务中,模型会生成到EOS标记为止。
3. SEP (Separator Token)
- 用途:用于分隔两个句子,例如在自然语言推理(NLI)任务或问答(Q&A)任务中。
- 示例:在BERT模型中,SEP标记用于分隔两个句子,帮助模型区分多句场景。
4. PAD (Padding Token)
- 用途:用于补齐序列长度,使不同长度的输入保持一致(通常出现在批量训练中)。
- 示例:在批量训练中,较短的序列会用PAD标记填充到与最长序列相同的长度。
5. MASK (Masking Token)
- 用途:表示需要预测的掩码,用于掩盖部分输入数据(如BERT的预训练任务)。
- 示例:在BERT的掩码语言模型任务中,MASK标记用于遮掩部分单词,模型需要预测这些被遮掩的单词。
6. UNK (Unknown Token)
- 用途:代表词汇表中未包含的单词。
- 示例:如果输入文本中包含词汇表中没有的单词,这些单词会被替换为UNK标记。
7. Additional Special Tokens
- 用途:自定义的特殊标记,用于扩展特定任务需求。
- 示例:在某些特定任务中,可以添加自定义的特殊标记,如
[CUSTOM_CLS]或[CUSTOM_SEP]。
这些特殊标记在不同的模型和任务中可能会有所不同,但它们的基本用途和功能是相似的。通过这些特殊标记,模型能够更好地理解和处理输入序列,从而提高任务的性能。
在Transformer模型中,CLS(Classification Token)通常是预定义的特殊标记,但其嵌入向量是通过训练得到的。以下是具体的说明:
1. 预定义的特殊标记
- CLS标记在模型的输入序列中被预定义为一个特殊的标记,通常位于输入序列的第一个位置。它并不对应自然语言中的任何单词,而是一个占位符,用于表示整个输入序列的语义信息。
- 在模型的输入阶段,CLS标记会被插入到输入序列的开头,例如在BERT模型中,输入序列的格式为:
[CLS] + 句子1 + [SEP] + 句子2 + [SEP]。
2. 训练得到的嵌入向量
- CLS标记的嵌入向量在模型训练过程中是可学习的参数。在模型初始化时,CLS标记的嵌入向量通常是随机初始化的(例如全零向量或随机值),然后通过训练过程中的反向传播算法逐步调整。
- 在训练过程中,CLS标记的嵌入向量会逐渐学习到整个输入序列的全局信息。通过自注意力机制,CLS标记能够捕获输入序列中所有单词或词元的上下文信息,最终成为整个序列的代表性特征。
3. 具体应用场景
- 在BERT模型中,CLS标记的最终隐藏状态被用作整个句子的语义表示,用于下游任务(如文本分类、情感分析等)。在这些任务中,CLS标记的嵌入向量会经过一个分类层(如全连接层)进行分类预测。
- 在Vision Transformer(ViT)中,CLS标记同样被添加到输入序列的开头,用于表示整个图像的全局信息。在图像分类任务中,CLS标记的嵌入向量会经过一个线性分类器完成分类预测。
总结
- CLS标记本身是预定义的特殊标记,但其嵌入向量是通过模型训练得到的。这种设计使得CLS标记能够有效地捕获整个输入序列的全局信息,从而在分类任务中发挥重要作用。