人类意识是从我们大脑的导航系统里出现的——AI的意识会不会也是这么出现的?
Rick Mammone

科幻电影《机械姬》里,由艾丽西亚·维坎德扮演的科幻人形机器人艾娃。图片来源:电影剧照
那句很有名的话,
“我思,故我在”,
是笛卡尔说的。简单来说,就是说,如果我有足够的自我意识去问“我存在吗?”这个问题,那答案就是个响亮的“是的!”——因为是“我”问了这个问题。
动物的大脑,用一个内部的自我和世界的表征模型来帮助它活下去。意识,就是你对“你存在”和“世界存在”的觉知。最基本层面的意识,就是知道你的身体和这个世界是分开的。这个对身体和世界分离的觉知,还有好几层,有时候叫做身体自我。这包括你知道你在空间里的位置,知道你可以控制你的身体和身体的各个部分,知道你只能从你自己在空间里的这个视角看世界。我们马上就会看到,世界的内部模型里其实有一张用来导航的认知地图。这个世界模型里,还包括“心理理论”(ToM),让我们能把其他动物和人类看成是有自己思维的生物。所以,我们就会预测它们的行动会和无生命的东西不一样。这种对其他动物有“心”的觉知,反过来也让我们觉察到,我们自己也被看作是有“心”的。
意识,经过很多年的演化,走了一条跟智慧演化差不多的路。智慧和意识不一样,但是两个有关联,都是心灵的一部分。智慧更多是关于你怎么跟世界互动,通过学策略去解决问题。说来也奇怪,大家对智慧这东西的神秘感,远远比不上对意识的神秘感。所以我们先聊聊,智慧到底是怎么来的。包括我们自己在内,动物的智慧,随着时间进化,是为了提升我们在世界里导航的能力,既能躲避掠食者,又能找到食物和配偶。一本非常棒的书,叫《智慧简史》(A Brief History of Intelligence),是Max Bennett写的。他把智慧的演化分成五个阶段:操控、强化、模拟、心理化和语言化。

生物智慧的进化和机器智慧的进化对比。图片来源:The Quantastic Journal,基于作者信息和Max Bennett的《智慧简史》的概念
大概5.5亿年前,“操控”进化出来,帮动物决定要继续往前还是退回去,这取决于是可能的奖励大,还是可能的惩罚大。接着是“强化学习”,帮动物根据过去的经验,做出下一个动作,好增加未来拿到奖励的机会。“模拟”,是动物想象未来动作和可能后果的能力,提前想好哪个是“最优动作”。“最优动作”通常就是那个被认为最可能带来最大未来奖励的动作。“心理化”,就是能想象自己和其他生物都有心和个性。这是ToM的能力,就是能在模拟里把自己和别人的心理也一起建模进去。这个能力让动物在合作和竞争里都有更高成功率。智慧进化的最后阶段,Bennett叫它“语言化”,也就是语言的使用,能让知识快速从一个头脑传到另一个头脑,不需要每个人都再用强化学习去反复试错了。
在智慧进化的整个过程中,动物都被认为有某种“主动性”,它们可以根据世界的当前输入和自己的历史经历,随时选择自己的动作。这种主动性可以看成是一种“自我”的模型,经过几百万年的进化,慢慢变得越来越多层次、越来越自觉。人类(也许还有其他动物)现在这种自我觉知状态,就是我们说的“自我意识”。咱们来回顾一下,动物的这种自我觉知是怎么进化的,AI以后会不会也进化出这样的东西。
AI的进化,和动物智慧的进化,其实走了很多相似的路。随着AI的不断进化,AI的“意识”可能也会跟人类一样,以类似的方式慢慢浮现出来。
你家还是我家
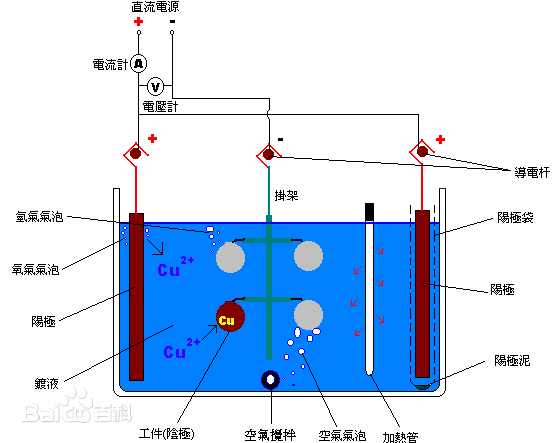
1971年,O’Keefe和Dostrovsky发现了老鼠海马体里的“位置细胞”。位置细胞在动物到达环境里的某个特定位置时,放电频率就会增加。比如说迷宫的一个岔路口,某个位置细胞只在老鼠到这个岔路口时放电,另外一个位置细胞则负责另一个位置。所有位置细胞覆盖整个环境的所有位置,就形成了一张认知地图。

海马体位置细胞在导航时有目标导向的矢量场。ConSinks和矢量场在蜂巢迷宫中组织位置细胞的活动。放电模式由指向特定位置的矢量场很好地描述,研究者Jake Ormond和John O’Keefe把这个点叫做“汇聚点”,简称ConSink。(a)显示3号老鼠所有起点平台和目标平台。虚线框是b的部分。(b)试验1的四个选择示意图。动物被困在“子试验起点”,直到两个相邻平台升起,然后它通过移动到“选定平台”来做选择。(c)动物的朝向相对于参考点(ConSink)计算,是正前方0°和自我空间里目标点方向之间的角度。(d)一个ConSink位置细胞的代表例子。左边两个图是两个独立试验中的路径(白色)和放电点(红色)。目标平台边界黑色。中间两个图是位置场热图(右上角最大放电率),全部路径(灰色)和放电点(红色)。右二是矢量场,显示不同位置的平均头部方向。ConSink是红色实心圆。最右是极坐标图,显示相对于ConSink的头部方向分布(来源:lacense CC)。
大概5.2亿年前,脊椎动物在寒武纪大爆发时第一次出现。所有脊椎动物,包括哺乳动物,都有海马体,而且大部分被认为都有位置细胞。位置细胞的功能,代表了一种非常原始的意识。动物知道自己在世界的某个特定位置。这是一种身体自我意识,知道“我”有一个有限的身体,正处在世界里的一个特定点上。在世界上无数的物体里,能有这个独特能力的东西,其实真不多。

上面:一个飞行蝙蝠身上的遥测系统,按比例绘制;左边:从飞行蝙蝠的海马体记录到的3D位置细胞的例子。神经元的空间放电的3D图。左上:放电点(红点)叠加在蝙蝠位置轨迹(灰线)上;还展示了四个电极通道上的放电波形(平均±标准差)。右上:3D颜色编码的放电率地图,右上角标注了最大放电率。下面:包围神经元位置场的凸包(红色多边形)和蝙蝠飞行时覆盖的空间(灰色多边形);右边:3D空间在飞行蝙蝠的海马体里是均匀编码的,几乎是各向同性的。(A到D)是从四只蝙蝠海马体记录到的所有位置场(不同颜色代表不同神经元)。蝙蝠1到3(A到C)测试于长方体飞行房,蝙蝠4(D)测试于立方体房间。(来源,感谢Nicholas M. Dotson和Michael M. Yartsev,2013年)
2005年,Edvard Moser和May-Britt Moser发现了内嗅皮层(EC)里的网格细胞。内嗅皮层是跟海马体(位置细胞的老家)和新皮层(决策者)交流的。网格细胞会在环境里的固定间隔放电,形成一种类似笛卡尔坐标系或者网格的东西,叠加在认知地图上,帮助动物在空间里导航。网格细胞,还有其他一些细胞,比如头方向细胞和边界细胞,一起构成我们和其他动物用来导航世界的完整认知地图。O’Keefe和Moser夫妇因为发现了大脑的导航系统,2014年获得了诺贝尔生理学或医学奖。这个导航系统里,因为位置细胞的存在,环境里的一些地标也被标注出来了。
这个世界的内部模型,是我们所觉知(意识到)的真实世界的第一层近似版。这个阶段的自我模型,就是认知地图上代表我们当前所在位置的一个有限区域。有点像你在商场地图上看到的那个“你在这里📍”的小箭头。
内嗅皮层还充当海马体和基底神经节之间的接口,而基底神经节负责运动控制、认知和情绪处理。有两个非常著名的脑回路使用强化学习(RL):一个是围绕基底神经节和腹侧被盖区(VTA)的快速决策反馈回路,另一个是涉及前额叶皮层(PFC)和基底神经节纹状体的慢速反馈回路。我们马上会看到,这个快的RL回路在我们进化早期就出现了,它对世界的模型比较简单;后来的慢速RL回路对世界的模型就丰富多了。而对世界模型的丰富程度,直接决定了自我模型的丰富程度,帮助我们更好地在世界里导航。
随着智慧的进化,自我和世界的表征模型变得越来越详细。最终的自我模型,就是我们说的意识的一个关键组成部分。
我们来看看强化学习是怎么提升自我和世界模型的。
强化学习登场
AI里强化学习(RL)有两种基本类型:无模型(model-free)强化学习和有模型(model-based)强化学习。无模型RL是直接从真实世界的输入里学习,并且执行策略来导航世界的。有模型RL多了一套内部动态世界模型,可以用来训练,不需要一直和真实世界互动。有时候用内部世界模型训练,就像Bennett书里说的那样,叫做“模拟”。我们后面会讲模拟,也就是有模型RL。先说无模型RL,这个在动物和AI里都出现得比较早。

无模型RL被基底神经节和VTA用来快速导航,也被AI用来做像下西洋双陆棋这种事(图作者自绘)。
动物里的无模型RL,是在腹侧被盖区(VTA)和基底神经节之间进行的。大脑的奖励系统,基本上就是VTA释放多巴胺。VTA的投射,既到边缘系统引发好的或坏的感觉,也到基底神经节的背侧纹状体(DS)负责协调运动。基底神经节和VTA一起,组成了一个演员-评论员(actor-critic)强化学习系统。演员(基底神经节)学习选最优动作,评论员(VTA)评估各种可能动作,帮忙选最好的。时间差分(TD)强化学习方法,就是用当前奖励和预测奖励之间的差值,作为误差信号,去更新演员和评论员的模型。
已经发现,动物大脑里的多巴胺浓度,就是动物大脑用来更新演员和评论员部分的时间差分信号。这种简单的无模型演员-评论员RL方法,1992年被用在一个叫TD-Gammon的AI里,这个AI玩西洋双陆棋玩到专家级水平。之后,这种TD方法的更强版本,也不断被开发出来。

1992年,IBM宣布了AI通过游戏开发的又一个重要进展:Tesauro写的一个程序,靠自己学会了玩西洋双陆棋,水平高到能和职业选手对抗。那年,TD-Gammon在西洋双陆棋世界杯里38场比赛打了19胜19负——比之前任何西洋双陆棋程序表现都好(来源)。
Google DeepMind的A3C,大概是目前最先进的无模型演员-评论员算法。Google团队用A3C做过一个实验,展示出2014年得诺奖的那套大脑导航系统,居然是用A3C和一个模拟的AI动物(animat),自然演化出来的。这个AI动物,即使迷宫里的原始配置被随机打乱,比如封闭通道或打开墙壁,它还是能顺利导航。它的导航表现,甚至比一些人类专家还好。这证明了,无模型演员-评论员RL对导航的进化适应性——这也是大多数动物使用的方式。
古老的脊椎动物,通过使用基底神经节的无模型强化学习,极大提升了它们的导航能力。这让它们有了操作性条件反射和建立联想记忆的能力。一旦动物学会了用强化学习的试错法学习,它们就具备了把感觉和动作、物体关联起来的能力。VTA的投射,既到边缘系统,也到控制运动的地方。所以,边缘系统可以引发跟我们目标越来越接近时相关的感觉。动物在这个阶段,还发展出了联想记忆。比如,每次看到绿草后,通常都会找到吃的水果(奖励),所以单看到绿草,就可能让我们感觉愉快。这种联想记忆,会根据我们每个人的独特经历有所不同。看到绿草,我可能想到吃水果很开心,你可能想到每次看到绿草都被剑齿虎追。所以这些联想带来的感觉,可能就是哲学家说的“质感”(qualia),也就是我们觉知世界里不同东西时,产生的不同感觉和情绪的起点。
我们需要更大的大脑
大概2.25亿年前,哺乳动物从脊椎动物里分化出来,拥有了相对更大的前额叶皮层(PFC)。前额叶皮层,除了其他功能之外,还让动物能在脑子里维持一套动态的环境模型。这套动态模型,让动物可以在做出真实动作之前,先在脑子里演练各种“如果这样会怎么样”的情境。这种学会用某种“虚拟现实”来代表真实世界的能力,叫做有模型强化学习(model-based reinforcement learning)。有些研究者说,动物发展出这种用动态世界模型的能力时,意识很可能也就随之浮现了。
举个例子,想象一只猴子,看到一串香蕉,想拿到最大的那根。它会在脑子里模拟各种方法去够那根香蕉,可能是爬上去,也可能是跳上去。它会觉得爬上去安全点,然后才真正行动。这样一来,它就增加了成功几率,还把受伤的风险降到最低。
动物这种在真实动作之前,先模拟行动的能力,是意识里非常重要的一个部分,叫做自觉意识(autonoetic consciousness)。这种能想象未来可能发生什么,同时还能重建过去经历的能力,需要动物对自己作为一个持续存在的“自我”,在动态世界里活动,有非常强的觉知。
我们来仔细看看这种心理模拟是怎么工作的。科学家发现,当老鼠在迷宫里寻找奖励时,它经常会停下来,左右看看,好像在思考走哪条路。1930年代,科学家就把这种行为叫做“替代性试错”(vicarious trial and error,VTE)——意思是老鼠好像在脑子里提前预演未来。
后来神经科学证实了这个想法。科学家发现,当老鼠站在迷宫的岔路口时,它的“位置细胞”会像真的走到右边和左边那样依次放电,然后才做出真正的选择。这种神经模式,说明老鼠在脑子里已经先想象了自己走到不同位置的可能性,然后才行动。老鼠还表现出能记住过去的经历,并且从中总结出通过迷宫拿到奖励的窍门。这种既能重建过去的个人经历,又能想象和模拟未来场景的能力,叫做心理时间旅行(mental time travel)。

有模型强化学习(model-based RL)用环境的动态模型来获取更多样本,不需要在真实世界里实际动作(图作者自绘)。
AlphaGo用的也是无模型强化学习和有模型强化学习结合的办法来下围棋。它用有模型强化学习,在当前棋局的基础上,搜索未来可能的走法。这个最佳走法的搜索被设计成一棵树搜索——第一步是树的根,后续每一步就是从根分出的分支。可能的走法数量,跟全宇宙的原子数量差不多,所以不可能每条分支都算到底。于是,AlphaGo用了启发式方法,找“差不多最优解”。搜索空间通过修剪来缩小,去掉那些明显不可能赢的分支。
未来可能走法的这一连串,就是一个“回合”(rollout)。回合可以一直延续到对局结束。但是,为了减少树的长度,回合通常只选演员主动选出来的几步,然后让评论员根据当前估计的胜率,决定提前终止。除了长度,搜索树的宽度也要缩减。只有那几个最有希望赢的走法才会被保留。这样,AlphaGo每走一步之前,都会在脑子里预演成千上万个回合。
动物也会经常在真实行动之前,提前在脑子里模拟好几步。例如,你下象棋时,可能会提前考虑未来几步棋。你可能会想四种最好的走法,然后每种走法后面再想三步。这种提前规划的做法,有模型强化学习的AI也在用。它已经被认为是意识的一个重要组成部分。这种提前选择要模拟哪些回合的随机抽样方法,叫做蒙特卡洛搜索(Monte Carlo search)。AlphaGo用的这个有模型强化学习的树搜索方法,正式名字叫蒙特卡洛树搜索(MCTS)。

AlphaGo Master(白)对唐韦星(2016年12月31日),AlphaGo执白中盘胜。白36这一手,获得广泛好评(来源)。
2015年,AlphaGo把A3C和MCTS结合起来,在和李世石的五番棋里,五战五胜。演员预测最优走法,评论员评估这些走法的胜算。这种结合直觉(评论员)和行动模拟(演员)的方式,正是人类学习和解决复杂问题的方式。围棋高手不需要每步都下出“最优解”,他们只要比对手强就够了,所以启发式方法往往是最实用的策略。
AlphaGo还能创新新走法
当AI代理成功达到目标,比如走到迷宫终点,它可能就会一遍又一遍重复同样的路径,不再学新东西。这时候,“随机性”就登场了。在强化学习里,“探索”(exploration)指的是代理主动尝试新动作(随机选),去了解环境,发现可能的最优策略。相反,“利用”(exploitation)是指用当前的知识,选出目前看起来最有希望获得最高奖励的动作——也就是充分利用已有知识。关键的难题,是在探索和利用之间找到平衡,也叫“探索-利用权衡”(exploration-exploitation tradeoff)。
为了探索,代理可能会随机选动作,或者特意选那些高不确定性的动作,或者用“ε-贪婪”(epsilon-greedy)策略——在已经知道最优动作的情况下,保留一小部分随机选动作的可能性。利用阶段,就主要选那些当前看来最可能带来最高奖励的动作。
比如,AI代理在迷宫里找奖励,探索阶段它会乱走,东试西试,了解迷宫布局,就算花更长时间也无所谓。利用阶段,代理已经对迷宫非常熟了,它会直接走最短路径去拿奖励,充分利用已经学到的知识。
这种探索-利用的权衡,也叫“探索-利用困境”(explore-exploit tradeoff),在很多决策领域里都存在。比如,AlphaGo和李世石下的第二局,AlphaGo下了第37手——一招当时只有万分之一的可能性会被AI选中的走法。这一手决定性的创新,让AlphaGo赢了那局棋,也颠覆了围棋界几百年的传统理解。AlphaGo通过探索,学会并用了人类高手几乎不知道的策略。这就是我们能从AI身上学到的好例子——它们可以在几乎无限的搜索空间里,不断探索,找到我们人类容易忽略的模式。
有意识的人形机器人未来会怎样
人形机器人,就是AI的未来。因为这个世界是人类为人类设计的,所以最适合在这个世界里活动的机器人,很可能就是长成人形的。人形机器人可能会干我们现在做的任何工作,甚至干得更多。这些机器人,很可能会用强化学习来学怎么在环境里导航,就跟动物当年一样。它们最终也得学会和人类还有其他动物互动,所以,心理理论(ToM)这种能力,迟早会加到它们基于强化学习的导航和运动控制系统里去。
波士顿动力(Boston Dynamics)一直是人形机器人领域的领头羊,你可以看看下面这个它们机器人跳舞的视频。现在,很多公司都在准备专注开发人形机器人和训练它们用的真实世界模型。Google DeepMind已经和Apptronik联手造人形机器人了。OpenAI和Meta最近也都宣布,要研发人形机器人。马斯克的特斯拉也在开发Tesla Bot人形机器人。还有像Sanctuary AI、Physical Intelligence、Figure AI这些新公司,也都推出了自己的机器人。其他国家也没闲着,比如中国的AI Engine公司,也在造人形机器人。英伟达(NVIDIA)还搞了一套世界基础模型(World Foundation Models),用逼真的虚拟数据训练机器人,这些数据还符合物理规律。现在这场竞赛已经打响了,人形机器人会比你想象的更快出现在你面前,在我们的物理现实里自由穿行。
基于强化学习的自我模型,最终还会扩展到能模拟情绪反应,能对人类风格的交流,比如讽刺和幽默,做出恰当的回应。它们会根据人类合作伙伴的语气和肢体语言,来决定合适的反应。这种带情绪的自我模拟,会让AI的自我模型越来越接近我们人类的自我意识,甚至逐步逼近真正的“意识”。这种内部自我模型,不仅要能识别人类的情绪,也要能识别自己的情绪,还得能模拟一个在世界里导航的身体自我。AI的心理化能力——也就是能考虑其他智能体的“心”,包括人类和其他AI,正在逐步成熟。比如你可以看看这里的相关研究。这个高级版本的自我觉知,正在迅速逼近,也许很快,第一个机器人就会开口说:
“我思,
故我在。”
动物的智慧和自我觉知的进化路径,很可能会被AI人形机器人,以某种类似的方式再走一遍。你怎么看?有意识的人形AI机器人,真的会变成现实吗?那又会怎样改变我们对意识本身的理解呢?你会接受一个机器人当朋友、家人、或者同胞吗?

波士顿动力的人形机器人们跳得很开心的视频