一、什么是RAG(可以参考资料:/s/1arFJBZkt7ajtGTpVeeZiKw 提取码:6ddh )
RAG 即“检索增强生成”(Retrieval Augmented Generation),这项技术通过将大量外部数据与基础模型相结合,显著增强了语言模型(LLM)的能力,使得AI的回应更加真实、个性化和可靠。
RAG 技术的核心在于结合了检索(Retrieval)和生成(Generation)两大核心技术。在处理复杂的查询和生成任务时,RAG 首先通过检索模块从大量数据中找到与查询最相关的信息,然后生成模块会利用这些检索到的信息来构建回答或生成文本。
自2020年提出以来,从最初的朴素RAG(Naive Rag),到高级RAG(Advance Rag),再到模块化RAG(Modular Rag),RAG系统不断优化和迭代,以解决实际应用中遇到的问题,如索引环节中的核心知识淹没问题、「检索环节中的用户意图理解不准确问题」,以及生成环节中的冗余信息干扰问题等
二、GraphRAG框架的关键组件
查询处理器(Query Processor):负责预处理用户定义的查询,使其能够与图数据源进行交互。
检索器(Retriever):根据预处理后的查询从图数据源中检索相关内容。
组织者(Organizer):对检索到的内容进行整理和优化,以提高生成器的性能。
生成器(Generator):根据组织后的信息生成最终答案。
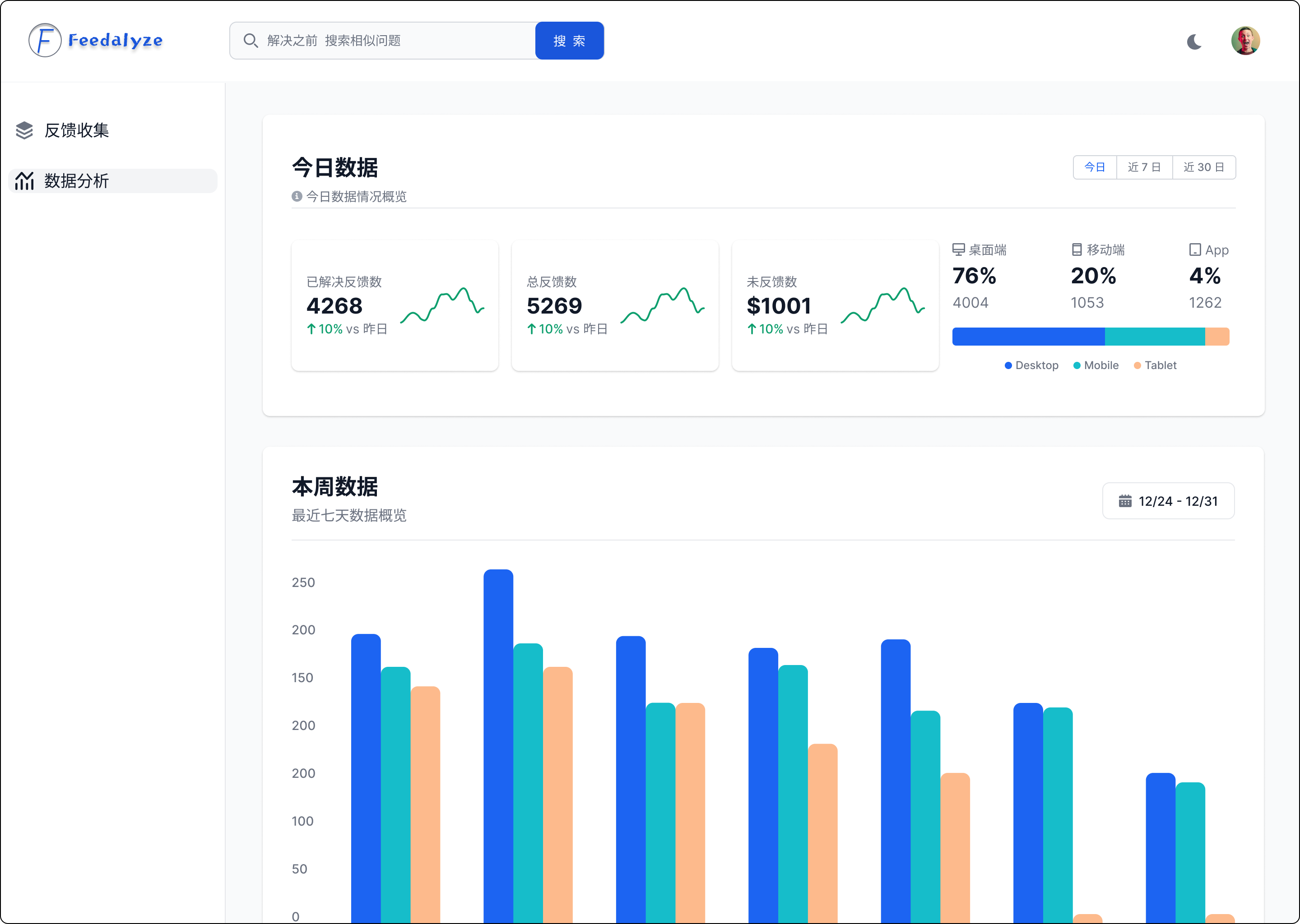
三、企业大规模落地 RAG 核心问题
经过了很长时间对 RAG 的研发,总结出了企业 RAG 落地的关键点,分别是效果、性能和成本。
效果:今天很多企业并没有大规模的落地 RAG,或者说是在一些关键场景上没有去使用 RAG,是因为企业担心用了以后,会因为效果问题,影响他们核心场景的业务。所以效果问题是现在 RAG 落地最关键的因素。
性能:在 RAG 链路里很多环节是需要使用大模型的,比如说向量化、文档解析,最后大模型的生成、 大模型 Agent 等。这样整个链路多次调用大模型,会导致离线和在线性能都会有不同程度的下降。比如说像 GraphRAG ,一个30K 的文档需要将近1个小时时间才能把数据处理好,这样的话很难在一个生产环境中去落地。
成本:相对于其他的应用来说,RAG 应用需要去多次调用大模型,而大模型背后就是 GPU , 但 GPU 资源是紧缺和昂贵的,这就不可避免的导致这类应用比其他应用的成本高很多,所以很多客户无法接受这个成本。
四、RAG 优化效果—数据提取和解析
首先在效果层面,离线链路里第一个优化点就是文档解析。文档有很多格式,比如说 PDF、Word 、PPT,等等,还有一些结构化数据。然而最大的难点还是一些非结构化的文档,因为里面会有不同的内容。比如说像表格、图片,这些内容 AI 其实是很难理解的。在通过长期大量的优化以后,我们在搜索开放平台里面提供了文档解析服务,支持各种各样常见的文档格式和内容的解析。
五、RAG 优化效果—文本切片
文档解析完,从文档里面能够正确的提取出内容后,接下来就可以进行文本切片。切片有很多种方法,最常见的有层次切分,把段落提取出来,对段落里面的内容再进行段落级的切片;还有多粒度切分,有时除了段落的切片,还可以增加单句的切片。这两种切片都是最常用的。另外对于一些场景,我们还可以进行基于大模型的语义切片,就是把文档的结构用大模型处理一遍,然后再提取一些更精细的文档结构。那么经过了多种切片以后,我们就可以继续进行向量化了。
六、RAG 评估
纯检索指标
精准率(Precision):衡量信号与噪音的比例——检索到的相关文档 / 所有检索到的文档。
召回率(Recall):衡量完整性——检索到的相关文档 / 所有相关文档。我们认为召回率是检索领域的北极星指标。这是因为只有当我们有足够的信心,相信检索到的上下文完整到足以回答问题时,检索系统对于生成任务来说才是可接受的。
F1 分数:精确率和召回率的调和平均值。
检索 & 重排指标
平均倒数排名(Mean Reciprocal Rank, MRR): MRR 计算的是最相关文档的倒数排名的平均值。如果正确答案的排名是高的(即排名接近第一位),则倒数值会大。MRR 值的范围是 0 到 1,值越高表示检索系统性能越好。
平均精确率均值(Mean Average Precision, MAP): MAP 首先计算每个查询的平均精确率,然后对所有查询的平均精确率进行平均。这里的 “精确率” 是指在每个排名阶段检索到的相关文档数量占到目前为止所有检索到的文档数量的比例。MAP 考虑了所有相关文档,并且对检索结果的排序非常敏感,值越高,表示检索系统的排名性能越好。
归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG): NDCG 倾向于赋予排在前面的相关文档更高的权重,是一种位置敏感的度量方法。NDCG 先计算一个未经归一化的折扣累积增益(Discounted Cumulative Gain, DCG),然后用这个值除以一个理想状态(即最佳排名顺序)下的 DCG,从而得到归一化的值。NDCG 的值范围在 0 到 1 之间,越接近 1 表示检索性能越佳,特别是在前面几个结果的质量方面。