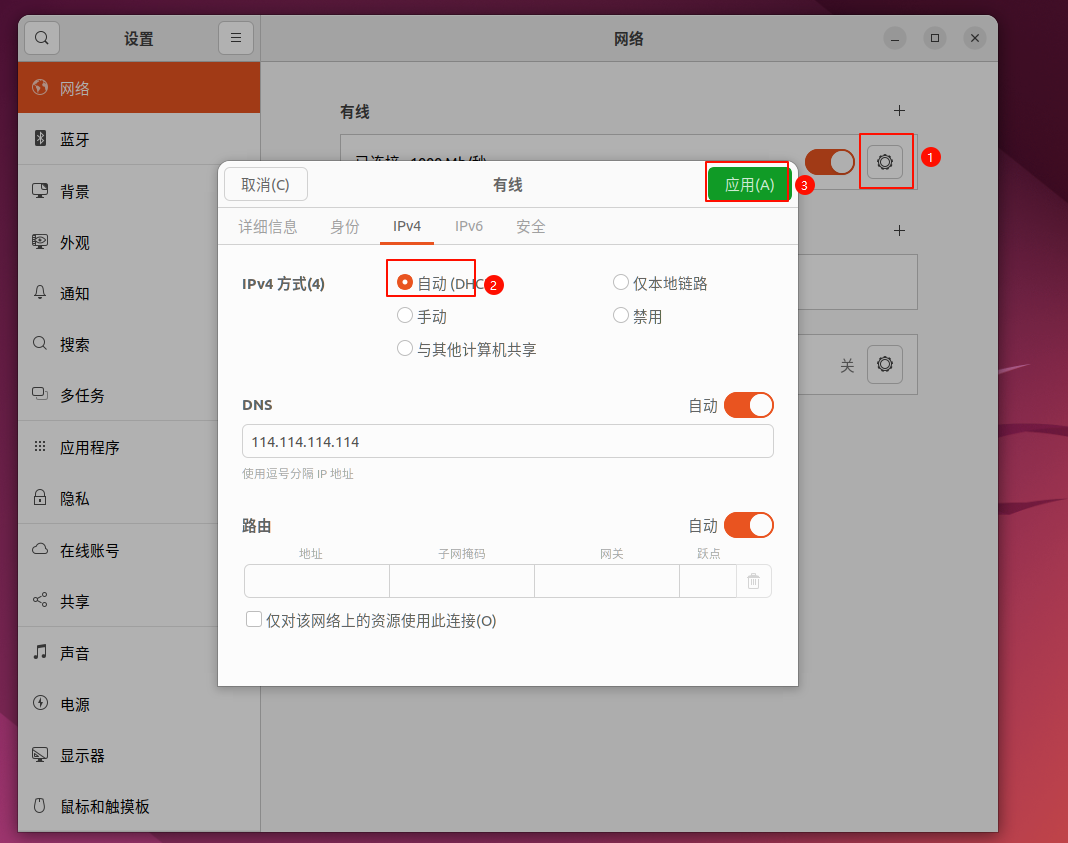
挑战
① 基于可用日志先验知识设计的日志解析器性能有限,且不具有泛化性
② 一些日志解析器在日志本身差异性大时无法正常工作
③ 劳动密集型模型调整
框架

离线训练
使用 WordPiece 进行 Tokenization(子词模型),然后输入到 Transformer 中进行上下文特征集成,然后输入 sigmoid 函数,进行二分类任务
在线解析
模型以在线日志为输入,得到经过 sigmoid 层后的可变概率,如果一个词的可变概率低于预定义的概率边界,则该词被视为常量
然后按照可变概率升序排序提取前 n 个单词作为常量词,然后根据每条日志的常量词进行分组,分完组后进行以下四个步骤:单词比较->顺序比较->长度比较->连续变量检测,如果匹配成功,则输入日志将被添加到匹配的日志组中,并进行下一步日志模板更新
模版更新步骤很简单,确保列中所有常量字的对齐。一旦添加新日志导致某一列中出现不同的单词,日志模板中对应的单词将在相应位置替换为通配符“<*>”
总结
使用 Transformer 进行变量概率预测,然后提出了一套流处理的方法来进行模版的匹配和更新