基本概念
- Tokens(标记):在自然语言处理中,token是输入文本被分割成的小单元。一个token可以是一个单词、一个子词,甚至是一个字符。这取决于文本的具体分割方式。
OpenAI常用参数
1. max_tokens(最大token数)
定义:指令生成的回答中包含的最大token数。例如,如果设置为100,那么模型生成的回答中token数不会超过100个。
用法:用来控制生成内容的长度。特别是在需要简短回答或有限字数情况下,这个参数非常实用。
2. temperature(温度/文风的温度)
定义:控制文本生成的随机性。值范围通常在0到1之间。值越大,生成文本越随机;值越小,生成文本越确定。
用法:用来调整模型回答的创造性。高温度适合创造性任务;低温度适合需要确定性高的回答。
- 温度 = 0:模型会产生最确定的输出,但可能显得重复或模板化。
- 0 < 温度 < 0.5:输出将倾向于较为稳定和保守,提供高度相关且一致的回应。
- 温度 = 0.5:产生的文本会有一个适中的平衡,既不过于随机也不过于保守。
- 0.5 < 温度 < 1:输出会更具创意和变化,但可能牺牲一些连贯性。
- 温度 = 1:模型会产生最大程度的创意和随机性,可能产生出奇不意的答案,但风险也更高。
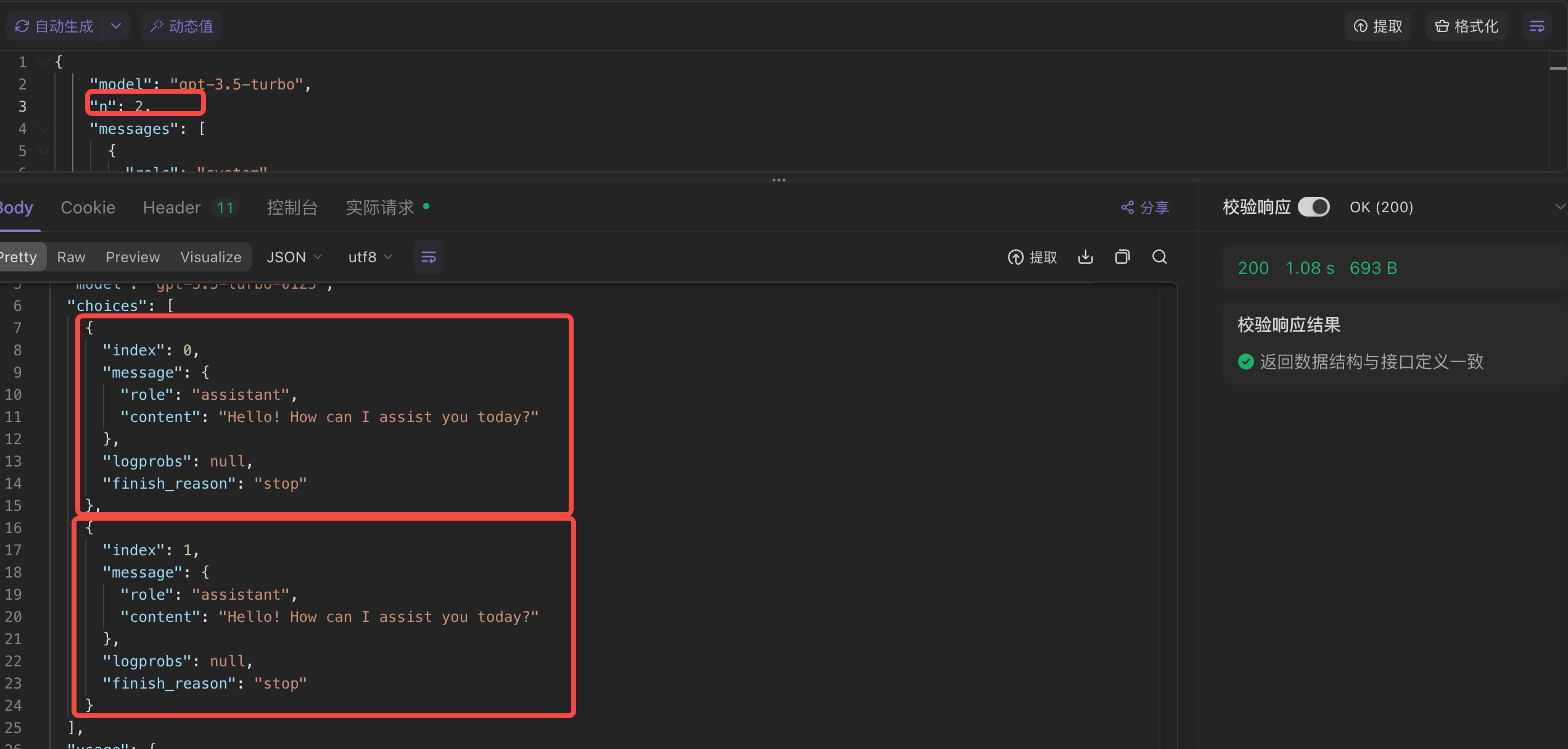
3. n(生成次数)
定义:模型对每个输入生成的回答数量。设置为n就会生成n个独立的回答。
用法:用来获取多个回答,便于选择或综合。
4. top_p(控制采样)
定义:确定生成文本时考虑的token累计概率。值为0到1之间,常用来替代温度设置。top_p为0.9时,模型仅在最有可能的token集合(累计概率达到0.9)中进行选择。
用法:控制生成内容的多样性,top_p越小,生成内容越确定。
5. presence_penalty(出现惩罚/阻止调整)
定义:影响模型生成新主题内容的倾向。值范围通常在-2.0到2.0之间。较高的值鼓励模型生成前面未出现过的新内容。
用法:用来避免重复内容,增加多样性。
6. frequency_penalty(频率惩罚、短语效应)
定义:影响模型是否重复使用某些词或短语。值范围通常在-2.0到2.0之间。较高的值会减少模型重复使用某些词或短语的频率。
用法:用来减少重复词语,提高输出的流畅度和多样性。
7. stream
定义:stream 参数用于控制是否以流式方式接收生成的文本。流式输出意味着生成的文本会逐步发送,而不是一次性全部发送。
用法:
stream=True:启用流式输出,生成的文本会逐步发送。stream=False:禁用流式输出,生成的文本会一次性发送。
总结
max_tokens:控制生成内容的长度。temperature:控制生成内容的随机性和创造性。n:生成多个回答供选择。top_p:通过概率控制生成内容的多样性。presence_penalty:鼓励生成新内容,避免重复。frequency_penalty:减少词语重复,提高多样性。stream:控制生成的文本是否以流式方式逐步发送。
接口调用
Request方式调用
import os
import requestsfrom dotenv import load_dotenvload_dotenv()url = os.getenv('OPENAI_BASE_URL') + '/chat/completions'data = {"model": "gpt-3.5-turbo","n": 2,"messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "Hello!"}]
}headers = {"Authorization": 'Bearer' + os.getenv("OPENAI_API_KEY")
}response = requests.post(url, headers=headers, json=data)print(response.text)SDK方式调用
from dotenv import load_dotenv
from openai import OpenAIload_dotenv()client = OpenAI()
response = client.chat.completions.create(model='gpt-3.5-turbo',messages=[{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "Hello!"}]
)print(response.choices[0].message.content)
常用接口调用
embeddings
文本向量化
from dotenv import load_dotenv
from openai import OpenAIload_dotenv()model = "text-embedding-ada-002"client = OpenAI()
response = client.embeddings.create(model='text-embedding-ada-002',input="Hello world!"
)print(response.data[0].embedding)
使用图片
import base64
from dotenv import load_dotenv
from openai import OpenAIload_dotenv()client = OpenAI()def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')base64_image = encode_image('./cat.jpeg')response = client.chat.completions.create(model='gpt-4o',messages=[{"role": "user","content": [{"type": "text","text": "这张照片里有什么?"},{"type": "image_url","image_url": {"url": f'data:image/jpeg;base64,{base64_image}'}}]}]
)print(response.choices[0].message.content)
模型需要
'gpt-4o'
作业
使用代码统计token 数量开发控制台循环聊天
import tiktoken
from openai import OpenAI
from dotenv import load_dotenv# 用户最大输入TOKEN
MAX_TOKEN = 100
MAX_RESPONSE_TOKEN = 500load_dotenv()client = OpenAI()encoder = tiktoken.encoding_for_model('gpt-3.5-turbo')def content_tokens(text):tokens = encoder.encode(text)return len(tokens)def main():messages = [{"role": "system","content": "You are a helpful assistant."},]print("开始聊天吧,输入/bye退出")total_token = 0while True:user_input = input("用户: ")if user_input.strip().lower() == '/bye':breakuser_token = content_tokens(user_input)if user_token > MAX_TOKEN:print(f'您的输入超出token限制 max{MAX_TOKEN}, 当前{user_token}')continuetotal_token += user_tokenmessages.append({"role": "user","content": user_input})response = client.chat.completions.create(model='gpt-3.5-turbo',messages=messages,max_tokens=MAX_RESPONSE_TOKEN,temperature=0.7,top_p=1,n=1)assistant_message = response.choices[0].message.contentassistant_token = content_tokens(assistant_message)total_token += assistant_tokenprint(f"助手: {assistant_message}")print(f"用户tokens数:{user_token},助手tokeens数:{assistant_token},总token数:{total_token}")if __name__ == "__main__":main()