NeoBERT代表了双向编码器模型的新一代技术发展,通过整合前沿架构改进、现代大规模数据集和优化的预训练策略,有效缩小了传统编码器与高性能自回归语言模型之间的性能差距。该模型在支持4096 tokens的扩展上下文窗口的同时,仅维持250M参数规模的紧凑设计。值得注意的是,尽管参数量较小,NeoBERT在MTEB(Massive Text Embedding Benchmark)基准评估中展现了领先性能,在相同微调条件下超越了多个参数规模更大的竞争模型。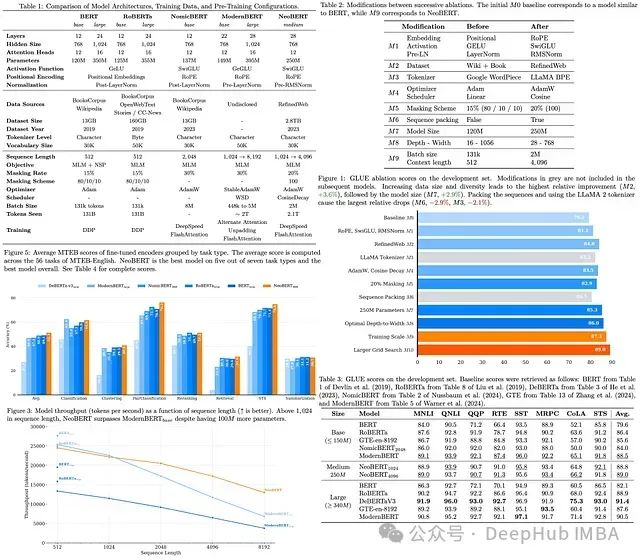
https://avoid.overfit.cn/post/b72db5824bff45c68fbcb75e5aa081a5