1 安装
要成功编译、构建和安装 Numdiff,需要一些工具。首先是 ANSI C 编译器。该编译器至少应接受 -o 选项(将输出写入指定文件)、-D 选项(用于宏预定义)、-l 选项(搜索指定库)以及 -I 和 -L 选项(分别将指定目录添加到包含文件和库文件的搜索路径中)。
此外,你还需要一个 make 工具的 POSIX 实现(我使用了 GNU make 和 Joerg Schilling 的 smake 来编译 Numdiff),以及 rm 和 find 命令的 POSIX 实现。最后,你还需要正确安装 GNU Texinfo(以便安装 info 文档)和兼容 sh 的 shell。
Numdiff 已成功编译并在以下平台上进行了测试:
Slackware® GNU/Linux 10.2 with the version 3.3.6 of the GNU C Compiler (GCC),Slackware GNU/Linux 11 with GCC 3.4.6,Slackware GNU/Linux 12.2 with GCC 4.2.4,Slackware GNU/Linux 13 with GCC 4.3.3,Debian® GNU/Linux 4.0 with GCC 4.1.2 20061115 (prerelease) (Debian 4.1.1-21),Debian GNU/Linux 6.0.3 with GCC 4.4.5 (Debian 4.4.5-8),Debian GNU/Linux 7.1 with GCC 4.7.2 (Debian 4.7.2-5),Debian GNU/Linux 8.6 with GCC 4.9.2 (Debian 4.9.2-10),SunOS® 5.8 with GCC 2.95.3, andSunOS 5.10 (i386) with the version 5.9 of the Sun C compiler.
配置、构建和安装 Numdiff 可通过标准的三个步骤完成:
./configuremakemake install
如果你启用了自然语言支持,并且还想安装本地化文件(目前只提供意大利语本地化文件),那么在 “make ”之后,你必须键入并运行
make install-nls
默认情况下,“make install ”将安装 /usr/local/bin、/usr/local/info 等目录下的所有文件。您可以在配置步骤中使用选项 --prefix 指定 /usr/local 以外的安装前缀,例如“--prefix=$HOME”:
./configure --prefix=$HOME
为了更好地控制,可以使用选项 --bindir、--infodir 等。输入“./configure --help” 可获得所有可用选项的完整列表。
文档文件(包括 HTML、PDF 和纯 ASCII 文本格式的完整《用户手册》)将始终放在 DOCDIR/numdiff 中,其中 DOCDIR 是选项 --docdir 指定的路径,如果配置中未给出该选项,则为 PREFIX/local/doc。这里的 PREFIX 是选项 --prefix 指定的安装前缀或默认的 /usr/local。
安装 Numdiff 后,只需 “make uninstall ”即可删除与 Numdiff 相关的所有文件。如果你还通过 “make install-nls ”安装了本地化文件,也可以用 “make uninstall-nls ”代替 “make uninstall ”删除它们。
configure 接受的选项包括--enable-debug、--enable-optimization、--enable-nls 和--enable-gmp。
选项 --enable-debug 在编译源代码时开启调试功能。这可以通过向编译器传递 -g 选项来实现,但你也可以在启动 configure 之前通过设置环境变量 DBGFLAGS 来更改这一默认调试标志(你的编译器可能根本无法识别)。
选项 --enable-optimization 在编译源代码时开启基本优化。这可以通过向编译器传递 -O 选项来实现,但你也可以在启动 configure 之前通过设置环境变量 OPTFLAGS 来更改这个默认标志(编译器可能根本无法识别)。
选项 --enable-nls 可以开启自然语言支持。由于自然语言支持默认已启用,因此无需明确使用。要禁用它,请使用 --disable-nls 。如果要在没有 GNU gettext 库的系统上安装 Numdiff,建议禁用自然语言支持。在这种情况下,可以通过以下方式安装 Numdiff:
./configure --disable-nlsmakemake install
自 5.2.0 版起,Numdiff 使用 GNU 多精度算术库(也称为 GNU MP 或 GMP)执行所有计算,前提是该库在构建时可用。在 GNU MP 不存在的情况下,旧的多重精度算术内部支持是一种备用方法。不过,即使 GNU MP 可用,也可以使用多重精度运算的内部支持:只需在编译程序前向配置脚本传递选项 --enable-gmp=no 或 --disable-gmp 即可,如以下所示
./configure --disable-gmpmakemake install
启用旧版的内部多精度运算支持已经过时,使用 GNU MP 会更好。GNU MP 的最新版本可从 http://ftp.gnu.org/gnu/gmp/ 获取。有关 GNU MP 的最新信息,请参见 http://gmplib.org/ 上的 GNU MP 网页。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- 承接IT类招聘发布,相关阅读量5000+, ding钉或v信: pythontesting
2 快速入门
计算机用户经常会问两个文件有何不同。也许一个文件是另一个文件的更新版本。或者这两个文件一开始是完全相同的拷贝,但被不同的人修改过。
有几种方法可以查看两个文件之间的差异。其中一种方法是查看为生成另一个文件而从一个文件中删除、插入或更改的一系列行。著名的 diff 程序会逐行比较两个文件,找出不同的行组,并报告每组不同的行。在没有特定选项的情况下,比较行时,diff 程序会将字符数量或类型的任何变化都视为差异。不过,通过一些命令行选项,用户可以抑制某些对其不重要的差异输出。例如,diff 提供的选项可以忽略单词或行之间留白量的差异,或字母大小写的差异。
另一种查看两个文件差异的方法是,考虑一个文件中被删除、插入或更改的单词,以生成另一个文件。这里的 “单词 ”指的是一个非空格字符序列,由几个空格分隔,一个在单词之前,另一个在单词之后。
弗朗索瓦-皮纳尔(François Pinard)编写的 wdiff 程序 pinard(at)iro(dot)umontreal(dot)ca 会比较两个文件中的单词,并报告差异。
最后,我们可以将两个文件之间的差异看作是不同字节对的序列。cmp 程序逐字节而不是逐行或逐字报告两个文件之间的差异。因此,在比较二进制文件时,它往往比 diff 或 wdiff 更有用。
不过,如果要比较两个部分或全部由数字字段组成的文本文件,上述方法都不太适用。在这种情况下,通常要获得的是第二个文件中与第一个文件中相应字段在数值上不同的数字字段列表。但是,虽然一个数字可以用不同的符号来书写,但像 diff 或 wdiff 这样的程序却无法识别两个数字字段之间的差异仅仅是符号的差异,还是数值的差异。
例如,11.23 和 11.2300000 是相同的数字,但表示方法不同。如果您感兴趣的是数值,那么表示方法的不同就没有意义,因此应该忽略。然而,diff 和 wdiff 总是将前一个数字视为实际差异:您无法告诉这些程序忽略它。
这种类型的另一个例子是 98765.4321 和 9.87654321E04。这里的差别只是因为使用了科学记数法而不是普通的十进制记数法。
此外,根据您所在国家的不同,您可以坚持使用不同的数字书写习惯。例如,“三亿五千二百四十六美分 ”这个数字,意大利会计通常写成 300.052.000.46 美元,而美国会计则写成 300.052.000.46 美元。当然,300.052.000,46$ 和 300,052,000.46$ 表示的金额是一样的,但 diff 和 wdiff 会报告出差异,在这种情况下这可能不是您想要的。
最后,有时您可能希望忽略数值上的差异,只要它们不超过某个临界值。换句话说,您可能希望抑制报告所有 “微小 ”的数值差异。
例如,您可能希望忽略绝对值不大于 0.0001 的所有数值差异。如果是这种情况,那么数字字段 33 和 33.00009 应被视为相等,而 33 和 33.00011 应被报告为不同。
然而,diff 和 wdiff 无法忽略微小的数值差异,因为它们甚至不知道什么是数值差异。
正因为如此,我才决定开发一个新程序,使其能够适当比较包含数值字段的文件。在编写这个程序的过程中,我受到了盐湖城大学 Nelson H. Baabe 的 GPL 软件 ndiff 的启发。但我并不完全喜欢它的工作方式,于是就有了 numdiff。尽管ndiff启发了numdiff,但从源代码的角度来看,它们完全不同:numdiff完全是从零开始编写的,其中加入了来自GNU bc、GNU diff和GNUlib的代码。此外,最新版本的 Numdiff 提供了比 ndiff 更多的功能。
numdiff 接收两个必选参数,即要比较的两个文件的路径,然后根据给定的字段分隔符列表将文件分成若干行,将行分成若干字段,然后比较第一个文件的每一行的每个字段和第二个文件的对应字段。这里对应的具体含义取决于命令行中传给程序的选项。在没有选项的情况下,对应的意思是第二个文件中处于相同位置的字段,这里的位置既指行号,也指行中的位置。如果比较的字段都是合法的数值,numdiff 将对它们进行数值比较,否则将进行字面比较,即通常的逐字节比较。在字面比较的情况下,如果两个字段由相同的字符序列组成,则视为相等。在数值比较的情况下,如果没有特定的命令行选项,两个字段的数值差为零,则视为相等。请注意,如果没有通过选项 -s 或 -D 明确指定字段分隔符列表,numdiff 会将换行符('\n',ASCII 码 0x0A)、水平制表符('\t',ASCII 码 0x09)和空白符('',ASCII 码 0x20)作为字段分隔符。
例如,如果文件 list1 包含数据
accident 123 23Joshua 34.55 +3+4i water
dog -3455.321 cat 2.345678e-9 .0005-6.23e2i
和文件 list2 包含的数据
Accident 123 23456 34.5500 +3.0001+4i
dog -3455.320098 Cat +2.345678e-9 -6.23e2i $$$新的一行
那么命令 “numdiff list1 list2 ”的输出将是:
值得注意的是,只要复数以 a+bi 或 a-bi 的形式书写,并且在数值 a、b 和符号 + 或 - 之间没有多余的字符,numdiff 就能识别复数(用于表示虚数单位的符号 i 可以通过适当的命令行选项进行更改,请参见调用 numdiff)。如果您不知道复数是什么,请不要担心:您可能永远不会管理包含复数的文件,因此没有复数也能愉快地生活。)
现在我们来看一个例子,说明在添加或删除一行或多行的情况下,Numdiff 如何重新同步两个文件之间的行。如果要比较的两个文件中间有一个文件的行数比另一个文件的行数多或少,Numdiff 5 之前的版本就不能很好地工作。例如,如果您有一个 1000 行的文件,要将其与另一个 1001 行的文件进行比较,而除了位于第 500 行的那一行之外,两个文件是完全相同的,那么 numdiff 4.x 版本就不会只显示这一行的差异:一旦文件不同步,numdiff 4.x 就会将每一行都报告为不同。从第 5 版开始,在这种情况下可以激活过滤器来处理行的增删。过滤器的实际工作方式有多种选择,稍后我将详细介绍如何使用它们来获得所希望的结果。激活过滤器的最简单方法是使用选项 -z @。如果账单 1 和账单 2 的值分别为
bill1
Month Expenses
-------------------------Jan09 $ 233.56Feb09 $ 850.77Mar09 $ 12.55Apr09 $ 524.00May09 $ 78.25Jun09 $ 230.00Jul09 $ 443.10Aug09 $ 67.65Sep09 $ 10.00Oct09 $ 201.45Nov09 $ 110.00Dec09 $ 200.27
-------------------------
Total $ 2961.60bill2
Month ExpensesJan09 $ 234.00Mar09 $ 13.00May09 $ 78.25Jul09 $ 443.10Sep09 $ 10.00Nov09 $ 110.00Jan10 $ 200.00
-------------------------Total $ 1088.35vi
分别表示账单 1 和账单 2,那么这两个文件的区别在于
- 在 bill1 中,在月份列表前插入分隔符 -------------------------、
- 在bill2 中删除与 2 月、4 月、6 月、8 月、10 月和 12 月的费用有关的行、
- 在bill2 中对 2009 年 1 月和 3 月的支出进行了小幅修改、
- 在bill2 中,在分隔符 ------------------------- 之前出现了 2010 年 1 月的分录、
- 在分隔符 ------------------------- 之后的账单 2 中增加了一个空行、
- 以及费用总和的不同值。
命令 “numdiff -z @ -V bill1 bill2”(我在这里添加了选项-V,让 Numdiff 显示每次比较的是哪几行)的输出完全显示了预期的差异:
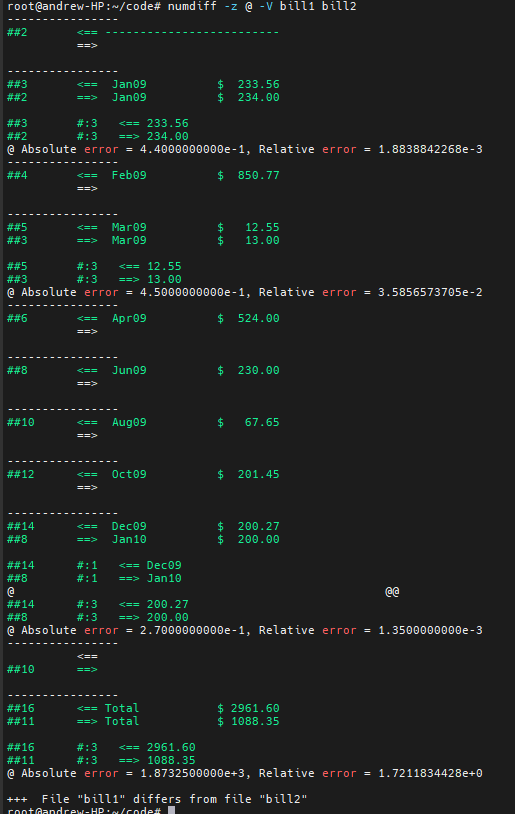
从显示的报告中我们可以看到
- 文件 bill1 的第二行,即包含分隔符的那一行,没有对应关系,或者,如果你愿意,已经从文件 bill2 中删除。
- bill2 中与 2009 年 1 月和 3 月有关的行略有改动,即支出值略有不同。请注意,2009 年 1 月的支出行在文件账单 1 中是第三行,而在文件账单 2 中是第二行。
- 与支出总额相关的一行在两个文件中的显示也不同,因为支出额不同。请注意,这一行在账单 1 中是第 16 行,而在账单 2 中是第 11 行。
- 账单 1 中的第 4、6、8、10 和 12 行在账单 2 中不存在。
- 账单 1 中包含 2009 年 12 月支出的一行在账单 2 中被包含 2010 年 1 月支出值的一行所取代。
- 账单 2 的第 10 行,即分隔符后的空行,在账单 1 中不存在。因此,对于账单 1 来说,这一行是新增的。
如果不使用选项-z @来比较账单 1 和账单 2,结果完全是误导性的。Numdiff 将 bill1 的第一行、第二行、第三行与 bill2 的第一行、第二行、第三行进行比较,以此类推。但在这种情况下,这可能不是您想要的:合理的做法是比较与同一月份相关的条目,而不是具有相同位置(即相同行号)的行。
Numdiff 还提供了一个选项,只运行过滤器,看看它是如何在不对相应行进行任何比较的情况下重新同步两个给定文件的。numdiff -z @ -f bill1 bill2 "的输出结果是
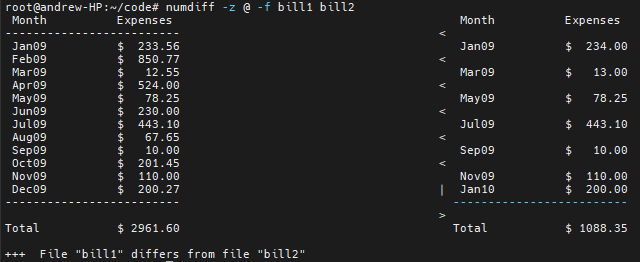
并显示过滤器以正确的方式工作,根据月份而不是行号关联行。在不能确定筛选器是否如您所愿工作时,只运行筛选器是非常有用的。您必须以正确的方式指示过滤器,使其正常工作,这就需要根据要比较的文件结构使用不同的选项。由于猜测正确的选项有时会很棘手,因此只运行过滤器并查看结果是确定一切设置正确的最佳方法。稍后,在 “筛选 ”部分,我将详细解释
- 过滤器在幕后做了什么,以了解它是否以及如何重新同步文件进行比较、
- 以及相关选项如何影响过滤器的操作。
顺便说一下,使用 -f 时甚至可以不使用过滤器的任何其他附加选项,如 “numdiff -f bill1 bill2”,但结果与删除字段分隔符后逐字节比较的结果差不多。
选项 -f 后面可以跟一个整数形式的参数,其含义将在后面解释,参见选项 -f 的使用。
尽管 numdiff 的输出结果应该是不言自明的,但在下一节中,我将详细解释关于它的所有知识。
- 输出格式: numdiff 如何在 stdout 上打印报告
- 概览模式: 打印差异列表的另一种方式
- 过滤器输出: 内置过滤器如何打印报告
- 原始输出: 适合自动解析的简洁输出格式
下一步: 概述模式, 上一页 概述 [目录][索引]
2.1 输出格式
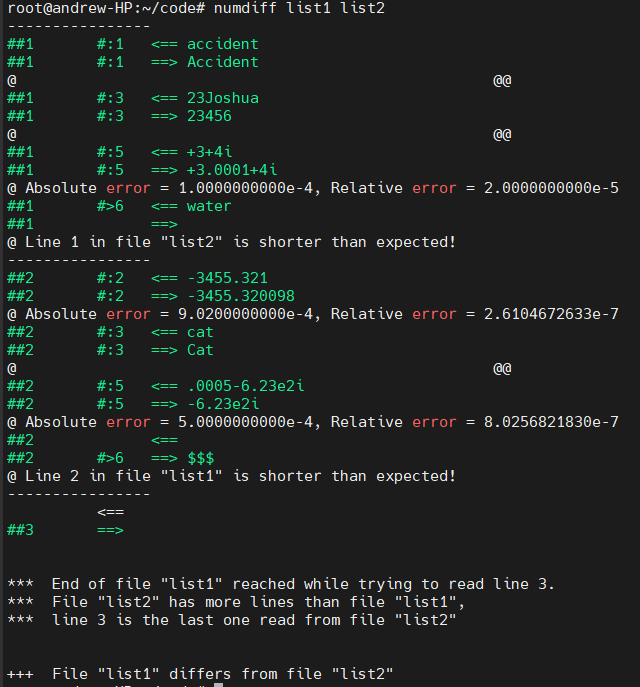
numdiff list1 list2
----------------
##1 #:1 <== accident
##1 #:1 ==> Accident
@ @@
##1 #:3 <== 23Joshua
##1 #:3 ==> 23456
@ @@
##1 #:5 <== +3+4i
##1 #:5 ==> +3.0001+4i
@ Absolute error = 1.0000000000e-4, Relative error = 2.0000000000e-5
##1 #>6 <== water
##1 ==>
@ Line 1 in file "list2" is shorter than expected!
----------------
##2 #:2 <== -3455.321
##2 #:2 ==> -3455.320098
@ Absolute error = 9.0200000000e-4, Relative error = 2.6104672633e-7
##2 #:3 <== cat
##2 #:3 ==> Cat
@ @@
##2 #:5 <== .0005-6.23e2i
##2 #:5 ==> -6.23e2i
@ Absolute error = 5.0000000000e-4, Relative error = 8.0256821830e-7
##2 <==
##2 #>6 ==> $$$
@ Line 2 in file "list1" is shorter than expected!
----------------<==
##3 ==>*** End of file "list1" reached while trying to read line 3.
*** File "list2" has more lines than file "list1",
*** line 3 is the last one read from file "list2"+++ File "list1" differs from file "list2"
表示第二行的第二个字段在第一个文件中为“-3455.321”,在第二个文件中为“-3455.320098”。由于两个文件中的字段内容都是数字,因此 numdiff 也会打印绝对误差和相对误差。
绝对误差(或绝对差值)由两个文件中出现的数值之差的绝对值给出。
相对误差(或相对差值)的定义实际上更为复杂。如果 n1 是出现在第一个文件中的值,n2 是出现在第二个文件中的值,那么绝对误差由公式 A=|n1-n2| 得出,而相对误差 R 则由以下公式得出:
- 如果 n1 和 n2 相等,则 R = 0、
- 如果 n2 与 n1 不同且至少有一个为零,则为 Inf(无穷大)、
- R=A/min(|n1|, |n2|),如果 n1 和 n2 都不为零,且 n2 与 n1 不同。min(|n1|, |n2|)表示 n1 的绝对值与 n2 的绝对值之间的最小值。
根据这些绝对误差和相对误差的定义,可以得出 A(n2, n1) = A(n1, n2) 和 R(n2, n1) = R(n1, n2)。换句话说,如果只改变比较值的顺序,绝对误差/相对误差不会改变。实际上,从第 5 版开始,可以让 Numdiff 计算相对误差时始终以第一个文件中的值为基准,或始终以第二个文件中的值为基准,而不是使用前面的公式。这可以通过选项 -F 来实现,请参见计算相对误差的其他公式。
如果比较的字段中至少有一个不是数值字段,那么报告绝对误差和相对误差的输出行将由分隔符代替:"@ @@"
可能会出现这样的情况,即要比较的两个文件中,一个文件的某一行比另一个文件的相应行包含更多的字段。如果出现这种情况,numdiff 就会报告这种差异,指出某一行(用行号标识)比预期的要短。
此外,numdiff 还显示长行的尾部,使用符号 “#>n ”表示长行中第一个字段的编号 n,而短行中没有相应的字段。例如
符号 <<*>>(如果出现)用于表示 “文件结束”,即一行或一行的尾部位于相应文件的末尾,且没有换行终止符。
也可能出现这样的情况,即要比较的两个文件中,一个文件的行数少于另一个。在这种情况下,如果没有向程序传递特殊选项,numdiff 会打印两个文件中仅有一个文件出现的第一行的行号,并在标准错误中显示信息,说明两个文件中哪一个文件过早结束:
除非使用选项 -q(请参阅调用 numdiff),否则 numdiff 会在标准输出中打印一条信息,报告比较的最终状态。这条信息要么显示两个文件相等,要么显示两个文件不同。
2.2 模式概述
自 5.6 版起,可以通过选项 -O 激活另一种显示两个文件差异的方式。如果命令行中包含该选项,numdiff 将打印并排报告,而不是通常的报告。
例如,如果 sheet1 包含文本
A 1 1
B 2 4
C 3 9
D 4 16
E 5 25
F 6 36
G 7 49
H 8 64
I 9 81
J 10 100
而 sheet2 包含以下行
A 1 1
B 2 4
C 3.3 9.03
D 4 16
E 5.5 25.05
F 6.6 36
G 7.7 49.49
H 8 64
I 9.9 81.09
则 “numdiff -O sheet1 sheet2 ”将打印此报告
A 1 1 A 1 1
B 2 4 B 2 4
C 3 9 :!:C 3.3 9.03
D 4 16 D 4 16
E 5 25 :!:E 5.5 25.05
F 6 36 :!:F 6.6 36
G 7 49 :!:G 7.7 49.49
H 8 64 H 8 64
I 9 81 :!:I 9.9 81.09
J 10 100 :<:*** End of file "sheet2" reached while trying to read line 10.
*** File "sheet1" has more lines than file "sheet2",
*** line 10 is the last one read from file "sheet1"+++ File "sheet1" differs from file "sheet2"左边是来自命令行第一个指定文件(即 sheet1)的行,右边是来自命令行第二个文件(在本例中为 sheet2)的行。中间有一个沟槽,其中包含一个标记:
- 空白: 相应的行是共用的。也就是说,要么这两行是相同的,要么由于选项 -s、-D、-I、-X、-a、-r、-P 或 -N 之一的原因,差异被忽略。
- ':!:': 相应行至少有一个字段不同。
- ':<:': 文件不同,且只有第一个文件包含该行。
- ':>:': 文件不同,且只有第二个文件包含该行。
在工作表 1 和工作表 2 的情况下,报告后会打印一条信息,说明已提前到达第二个文件的末尾。这两个文件的行数并不完全相同,过滤器也未激活。
选项 -O 可以包含一个可选参数,用于设置输出的宽度,并最终抑制普通行,参见调用 numdiff。并排报告宽度的默认值为 130。因此,“numdiff -O40 sheet1 sheet2 ”命令显示的报告行数较短也就不足为奇了,如果将报告宽度设置为太小的值,可能会出现比较文件中的部分甚至全部行被截断的情况。
,数字参数必须紧跟在选项 -O 之后,中间不允许有空格。对于 -f 的可选参数也是如此,而 Numdiff 中需要强制参数的选项则允许在它们和参数之间存在中间空格。
除了 -f、-q、-U、-E、-V 和 -b 以外,选项 -O 可以与 Numdiff 的任何其他选项一起使用。使用 -O 时,-U、-E、-V 和 -b 将被忽略。如果 -q 和 -O 同时出现在命令行中,则 -O 将被忽略。最后,如果 -f 和 -O 同时出现,那么行为取决于顺序:命令行中最先出现的选项才是最重要的。
选项 -O 可以与过滤器一起使用,以处理行的添加/删除。如果文件 sheet3 包含文本
A 1 1
C 3.3 9.03
E 5.5 25.05
G 7.7 49.49
I 9.9 81.09
J 10 100.00
K 0 0.02
那么 “numdiff -O40 sheet1 sheet3 ”就会打印出错误的报告,如文件 bill1 和 bill2 的示例:
e# numdiff -O40 sheet1 sheet3
A 1 1 A 1 1
B 2 4 :!: C 3.3 9.03
C 3 9 :!: E 5.5 25.05
D 4 16 :!: G 7.7 49.49
E 5 25 :!: I 9.9 81.09
F 6 36 :!: J 10 100.00
G 7 49 :!: K 0 0.02
H 8 64 :<:*** End of file "sheet3" reached while trying to read line 8.
*** File "sheet1" has more lines than file "sheet3",
*** line 8 is the last one read from file "sheet1"+++ File "sheet1" differs from file "sheet3"另一方面,-z @ 的存在使 Numdiff 总是比较相应行的字段,如命令 “numdiff -O40 -z @ sheet1 sheet3 ”的输出所示:
e# numdiff -O40 -z @ sheet1 sheet3
A 1 1 A 1 1
B 2 4 :<:
C 3 9 :!: C 3.3 9.03
D 4 16 :<:
E 5 25 :!: E 5.5 25.05
F 6 36 :<:
G 7 49 :!: G 7.7 49.49
H 8 64 :<:
I 9 81 :!: I 9.9 81.09
J 10 100 J 10 100.00:>: K 0 0.02+++ File "sheet1" differs from file "sheet3"并排格式易于阅读,但也有局限性。它生成的输出比一般格式宽得多,而且会截断太长的行。此外,它在很大程度上依赖于排版输出,因此,如果使用不同宽度的字体、非标准制表符站或非打印字符,它的输出看起来会特别糟糕。
2.3 过滤器的输出
运行过滤器(选项 -f)后产生的输出是比较文件的并列差异列表,就像 GNU sdiff 显示的那样。文件分两列列出,两列之间有一个边沟。沟槽包含以下标记之一:
- 空白: 相应的行是相同的。也就是说,要么这两行是相同的,要么因为选项 -s、-D、-I、-X、-z 或 -Z 之一而忽略了差异。
- '|': 相应的行不同,要么都是完整的,要么都是不完整的。
- '<' 或'(': 文件不同,且只有第一个文件包含该行。
- '>'或 ')':文件不同,只有第二个文件包含该行。
- '': 相应行不同,且只有第一行不完整。
- '/': 相应行不同,只有第二行不完整。
如果输入行的最后一个字符不是换行符,则该行不完整。这种情况只有在该行是其文件的最后一行时才会发生。当并列差异列表的输出行代表两个不同的行时,其中一个可能不完整,而另一个则不完整。在这种情况下,如果第一个文件中的行不完整,则沟槽标记为“\”,如果第二个文件中的行完整,则沟槽标记为“/”。
与 -O 一样,选项 -f 可以使用一个可选参数,用于设置输出的宽度,并最终抑制普通行,请参阅调用 numdiff 和选项 -f 的使用。
更一般地说,用户总是可以让 numdiff 避免打印部分或全部本应发送到标准输出的信息。这可以通过一些合适的命令行选项来实现,请参阅调用 numdiff。
2.4 原始输出
从 5.9 版开始,Numdiff 可以用一种特别紧凑的格式报告两个文件的比较结果,这种格式可以很容易地被其他程序解析。只要用户通过命令行选项 --raw 提出要求,Numdiff 就会选择这种原始格式。下面是输出格式一节中比较文件 list1 和 list2 的原始输出示例:
原始格式对人类来说并不方便。原始格式仅供 Numdiff 即将推出的图形用户界面使用(是的,Numdiff 将在未来推出图形用户界面!)。