| 这个作业属于哪个课程 | 软件工程 |
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
一、使用说明📝
1.使用环境:c++;Visual studio 2022
2.使用方法:
1.本系统采用LCS比较来得出论文查重率,采用了相似度计算公式,并对特殊文档进行额外处理。
2.本系统查重时会对文档进行预处理,过滤无用字符,如标点符号、空格等。
3.本系统增加了保存、查看、清空历史记录的功能,命令行中输入-history可查看历史记录,输入-clear可清空历史记录,这两个命令请单独输入,否则无法执行!
3.参数格式
main.exe <原文路径> <抄袭版路径> <输出路径> # 标准查重模式
main.exe -h # 查看历史记录
main.exe -clear # 清空历史记录
4.示例代码
main.exe "input/orig.txt" "input/orig_0.8_dis_1.txt" "output/result.txt"# 查看最近5条记录
main.exe -history# 清空历史记录
main.exe -clear
二、程序流程图🧩
graph TDA[命令行参数解析] --> B{参数校验}B -->|成功| C[读取原文/抄袭版文件]B -->|失败| D[打印帮助信息]C --> E[文本预处理]E --> F[计算LCS长度]F --> G[计算相似度]G --> H[输出结果文件]H --> I[保存历史记录]I --> J[打印格式化表格]
三、核心算法实现🛠️
1.LCS动态规划
// 空间复杂度O(n)的滚动数组实现
int lcs(UnicodeChar *X, int m, UnicodeChar *Y, int n) {int *prev = (int *)calloc(n+1, sizeof(int));int *curr = (int *)calloc(n+1, sizeof(int));for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {curr[j] = (X[i-1] == Y[j-1]) ? prev[j-1] + 1 : max(prev[j], curr[j-1]);}swap(&prev, &curr); // 指针交换}return prev[n];
}
2.文章预处理,使得查重更为清晰
UnicodeChar* convert_to_unicode(const char* utf8_str, int* len) {int capacity = 256;*len = 0;UnicodeChar* array = (UnicodeChar*)malloc(capacity * sizeof(UnicodeChar));UnicodeChar *new_array = (UnicodeChar*)realloc(array, capacity * sizeof(UnicodeChar));
if (!new_array) {perror("内存扩容失败");free(array);exit(EXIT_FAILURE);
}
array = new_array;const char* p = utf8_str;while (*p) {unsigned char c = *p;int char_len = 0;UnicodeChar code_point = 0;// UTF-8解码逻辑if ((c & 0x80) == 0) { // 1字节字符char_len = 1;code_point = c;}else if ((c & 0xE0) == 0xC0) { // 2字节字符char_len = 2;code_point = (c & 0x1F) << 6;code_point |= (p[1] & 0x3F);}else if ((c & 0xF0) == 0xE0) { // 3字节字符char_len = 3;code_point = (c & 0x0F) << 12;code_point |= (p[1] & 0x3F) << 6;code_point |= (p[2] & 0x3F);}else if ((c & 0xF8) == 0xF0) { // 4字节字符char_len = 4;code_point = (c & 0x07) << 18;code_point |= (p[1] & 0x3F) << 12;code_point |= (p[2] & 0x3F) << 6;code_point |= (p[3] & 0x3F);}else {p++; // 非法起始字节continue;}// 验证后续字节有效性int valid = 1;for (int i = 1; i < char_len; i++) {if ((p[i] & 0xC0) != 0x80) {valid = 0;break;}}if (valid) {// 保留汉字、字母、数字(过滤标点符号)if (isalnum(c) || (code_point >= 0x4E00 && code_point <= 0x9FFF)) {if (*len >= capacity) { // 动态扩容capacity *= 2;array = (UnicodeChar*)realloc(array, capacity * sizeof(UnicodeChar));}array[(*len)++] = code_point;}p += char_len;}else {p++; // 跳过无效字节}}printf("预处理后有效字符数:%d\n", *len);return array;
}
四、程序的特色🌈
1.处理能力得到优化
- 支持较大文件的快速处理(<500ms)。
- 采用滚动数组优化了空间复杂度。
2.友好的交互设计
- 界面有专门提示
- 实时显示查重流程
- 错误输入可以及时反馈
- 可以保留历史记录
五、程序调试结果🔧
1.性能分析:

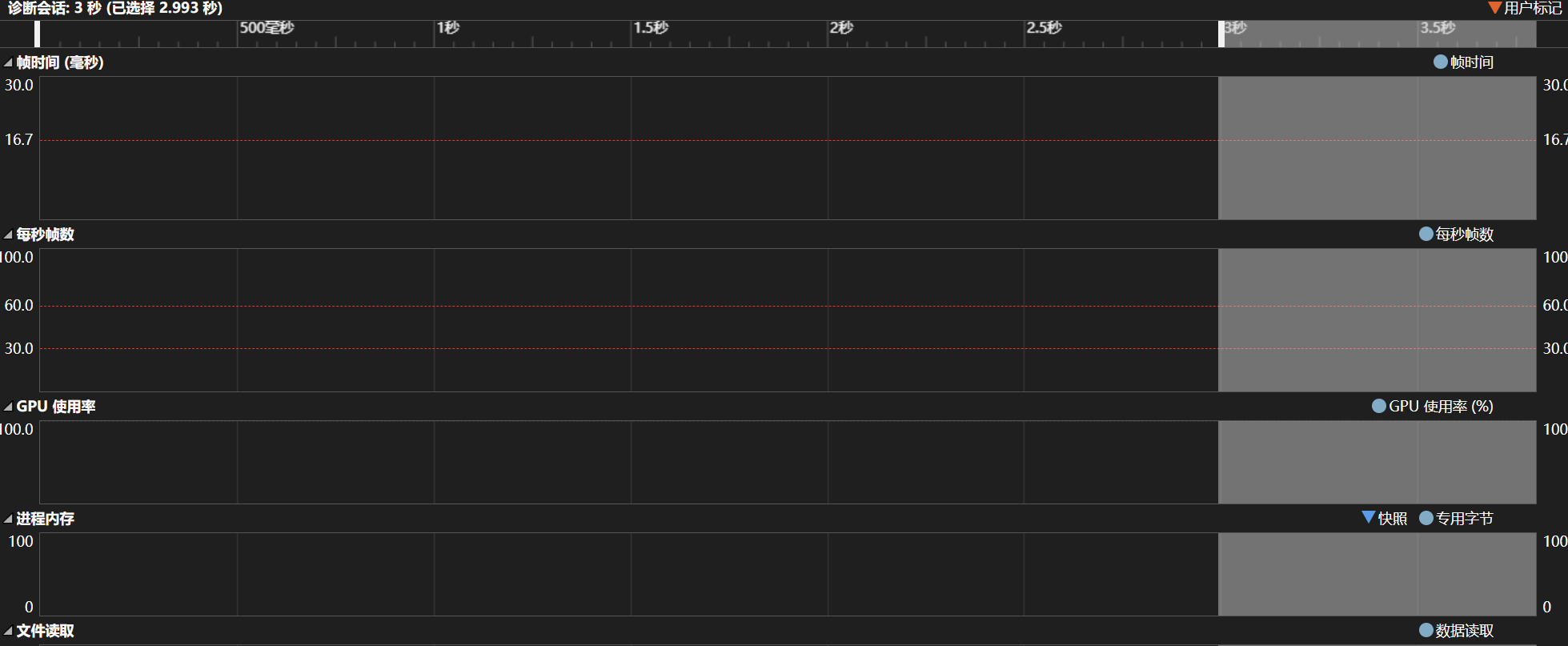
2.用于调试的文档
点击查看测试文档
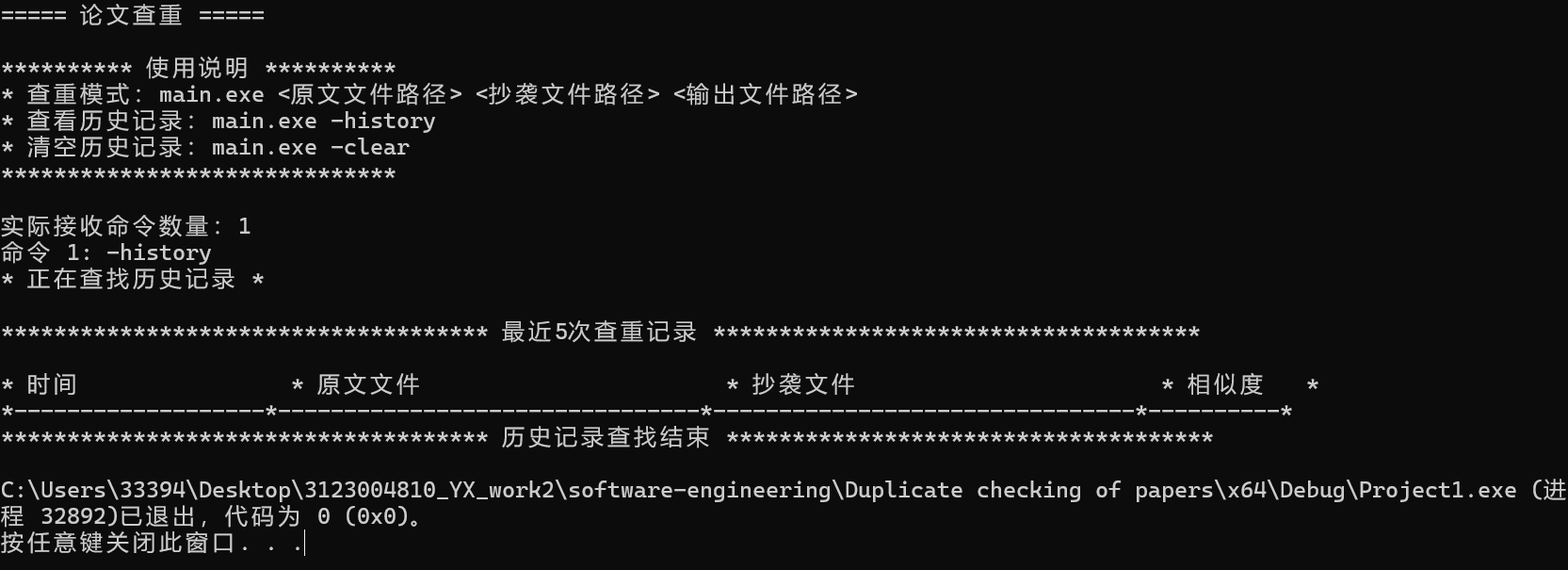
3.论文查重
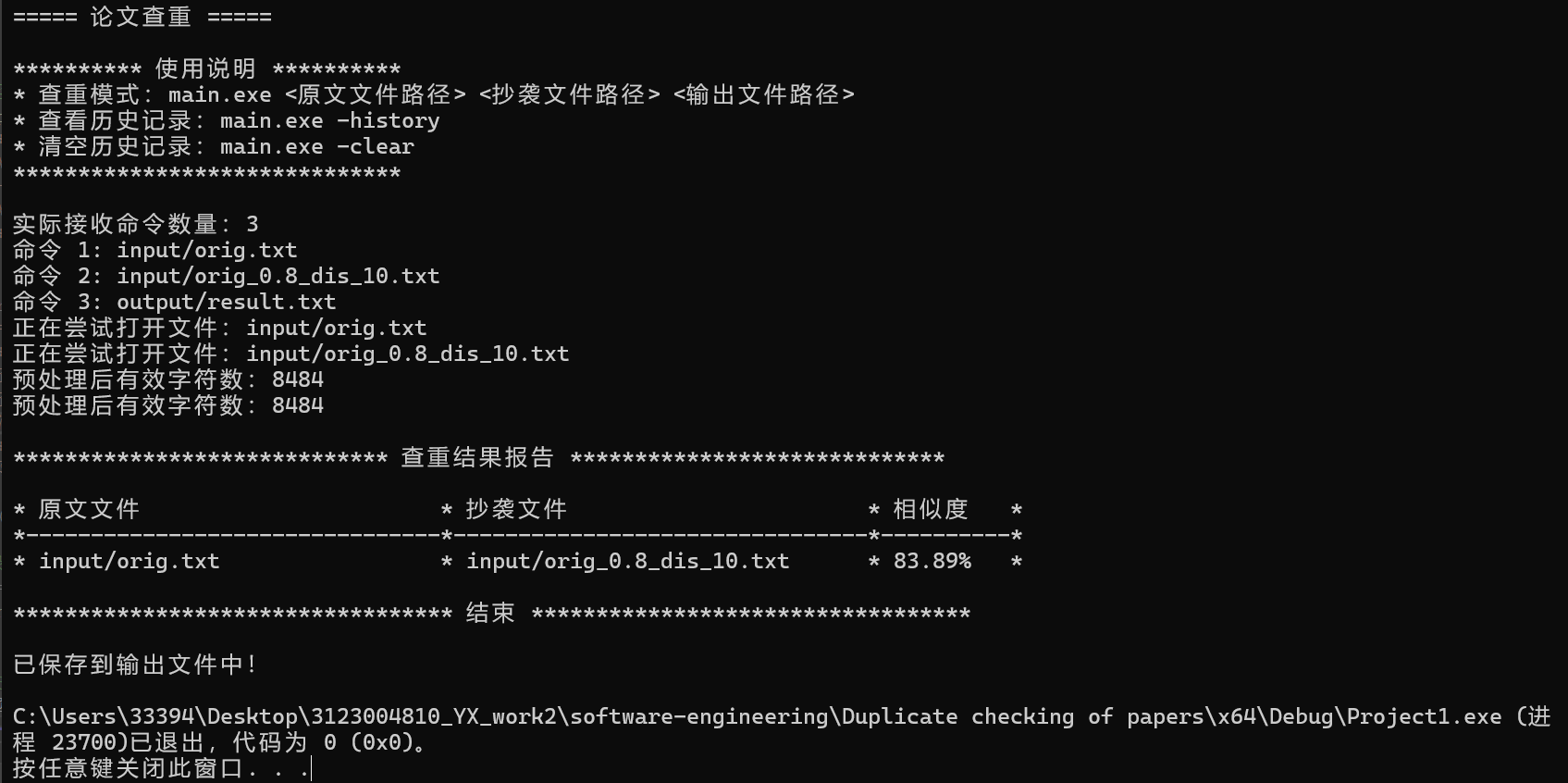
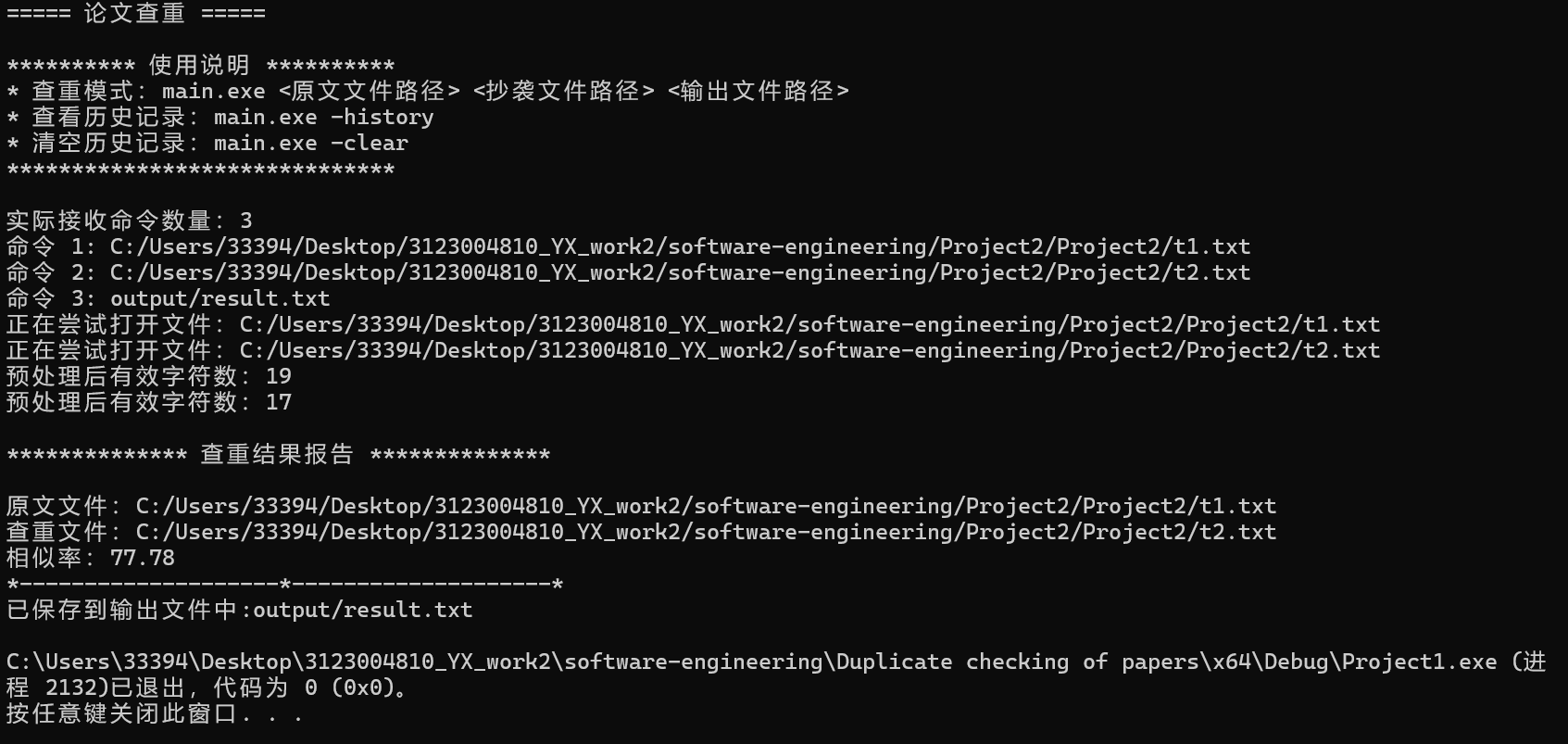
4.保存历史记录
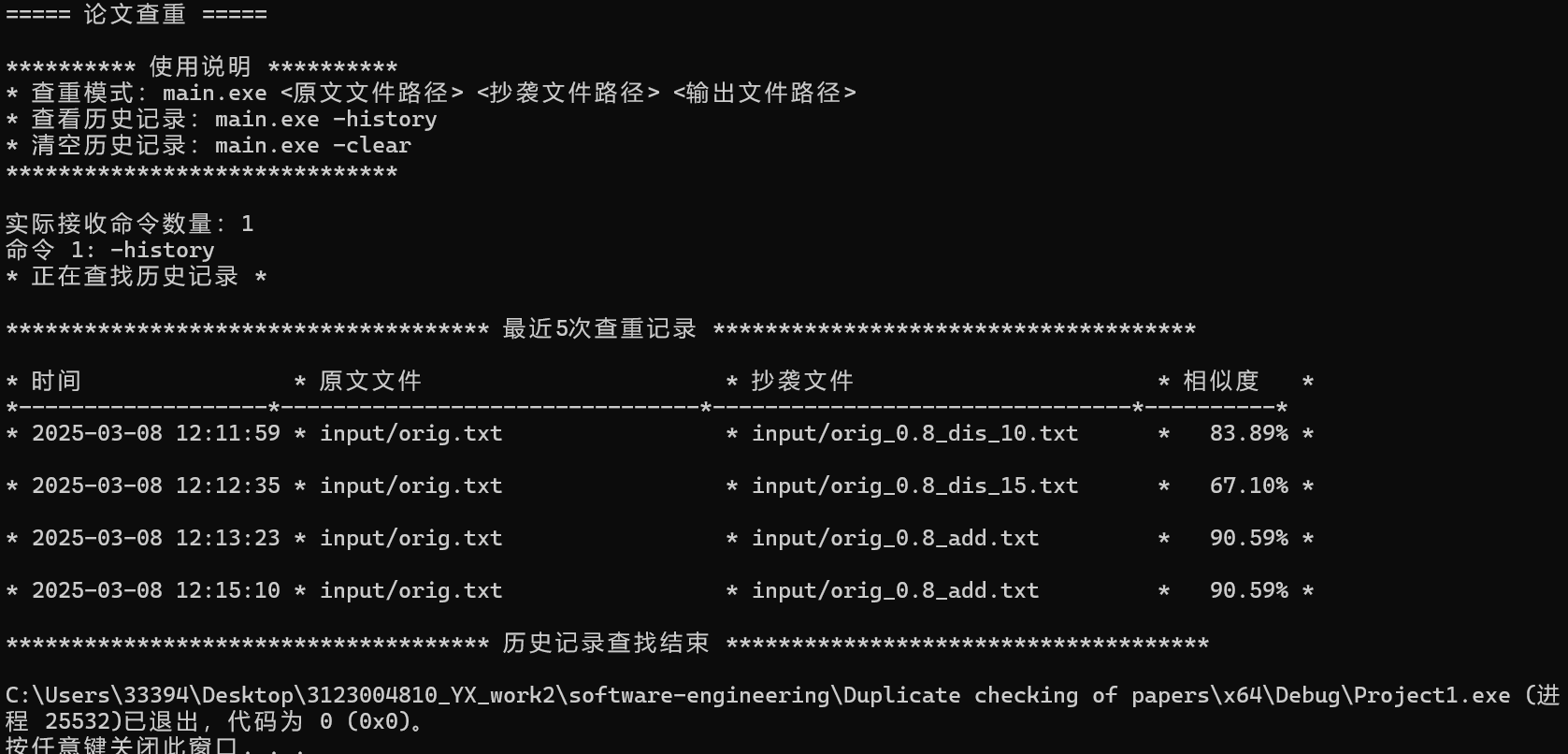
5.清空历史记录
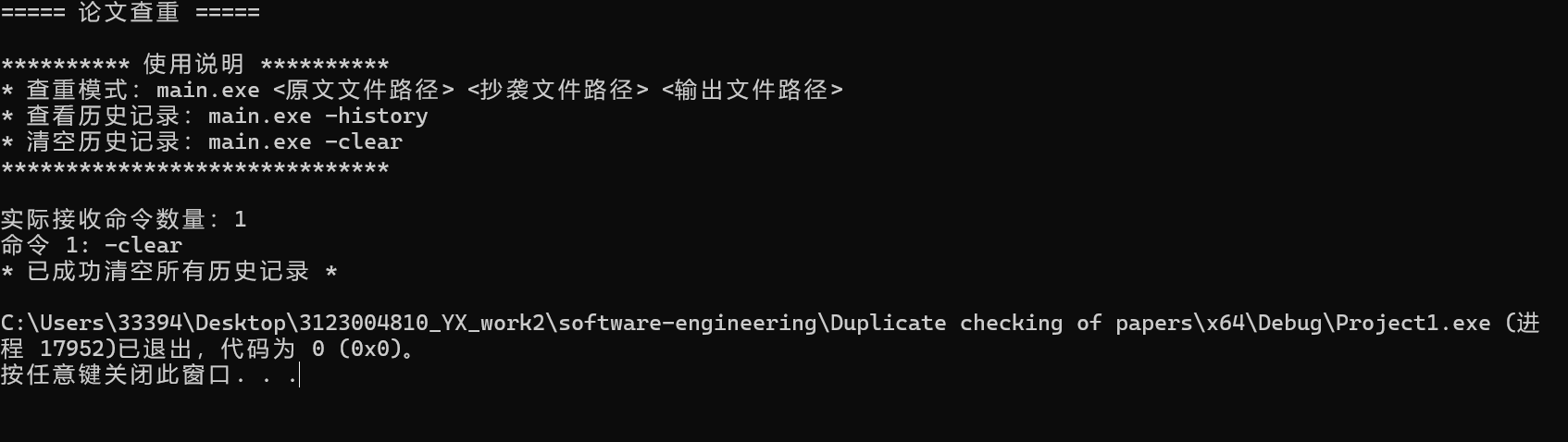
六、PSP2.1 个人开发流程时间管理表☕
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning(计划) | 20 | 20 |
| · Estimate(估计任务时间) | 20 | 20 |
| Development(开发) | 300 | 340 |
| · Analysis(需求分析,含学习新技术) | 60 | 65 |
| · Design Spec(生成设计文档) | 20 | 20 |
| · Design Review(设计复审) | 10 | 15 |
| · Coding Standard(制定代码规范) | 20 | 20 |
| · Design(具体设计) | 40 | 60 |
| · Coding(具体编码) | 60 | 70 |
| · Code Review(代码复审) | 20 | 20 |
| · Test(测试与修改) | 70 | 70 |
| Reporting(报告) | 80 | 80 |
| · Test Repor(测试报告) | 40 | 40 |
| · Size Measurement(计算工作量) | 20 | 20 |
| · Postmortem & Process Improvement Plan(总结与改进计划) | 20 | 20 |
| 合计 | 400 | 440 |
七、程序改进规划🚀
- 1.提升性能:做好性能瓶颈分析,以及可采用多线程方式是日后研究重点。
- 2.改进用户体验:查重结果输出格式有待完善,多重功能还有待开发。
八、个人总结🌟
- 1.本次程序开发是一个自己之前接触较少的算法,这是一次新的体验,自然会有新的收获。
- 2.我在开发过程中,会仔细思考用户的需求以及如何改善用户的实际体验,这是一种职场觉悟。
- 3.本次开发还有许多不足之处,比如说算法的代码有些冗杂,用户体验仍未达到最佳水平等,需要后期继续改进。
![[T.1] 团队项目:团队成员介绍](https://img2024.cnblogs.com/blog/3614191/202503/3614191-20250308143020241-1934824217.png)


![P3243 [HNOI2015] 菜肴制作(图论)](https://img2024.cnblogs.com/blog/3599636/202503/3599636-20250308133819271-1517872908.png)