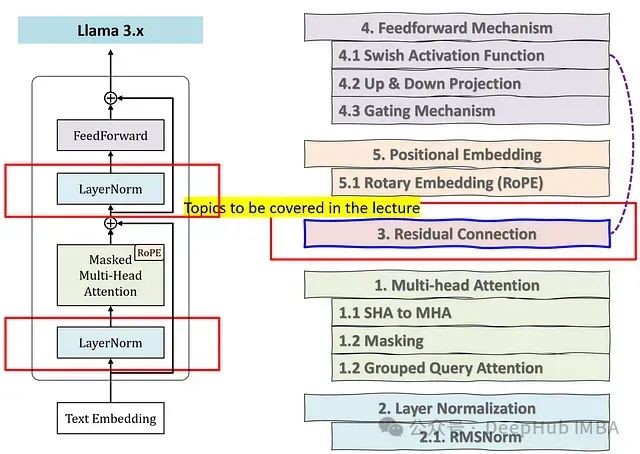
一、引言:大模型与Java的交汇
近年来,大模型技术在人工智能领域迅速崛起,成为推动智能应用发展的核心力量。与此同时,Java作为一种历史悠久且广泛应用于企业级开发的编程语言,凭借其强大的生态系统、跨平台特性和稳定性,一直是软件开发领域的中流砥柱。随着大模型技术的普及,Java与大模型的结合成为了一个备受关注的热点话题。这种结合不仅为Java开发者带来了新的机遇,也为大模型的落地应用提供了更广阔的场景。
在技术发展的浪潮中,Java社区积极拥抱大模型技术,推出了多个开源项目和框架,如Deeplearning4j、DJL(Deep Java Library)等。这些工具为Java开发者提供了丰富的资源,使得他们能够更方便地构建和部署基于大模型的应用。同时,大模型技术也在不断优化,以更好地适配Java的开发环境和应用场景。这种双向的融合不仅推动了技术的进步,也为开发者带来了新的挑战和机遇。
二、大模型与Java结合的技术趋势
(一)Java在大模型中的定位
在大模型的生态系统中,Java主要扮演推理(Inference)环节的角色,而非模型训练。模型训练通常需要高性能的计算资源和高效的并行计算能力,这些通常是Python生态(如TensorFlow、PyTorch)的强项。然而,Java在推理环节具有独特的优势,尤其是在企业级应用中。推理阶段更注重模型的部署、性能优化和与现有系统的集成,而Java的强大生态系统和跨平台特性使其成为理想的选择。
Java的“编写一次,处处运行”的特性使其在不同操作系统中具有良好的兼容性,能够无缝集成到现有的企业级架构中,如微服务、分布式系统等。此外,Java的性能优化能力也使其在处理高并发请求时表现出色,这为大模型的推理提供了可靠的保障。
(二)Java与大模型结合的优势
-
强大的企业级应用生态
Java拥有庞大的开发者社区、丰富的开源框架和库,如Spring、Spring Boot、MyBatis等,这些是构建复杂系统的关键组件。通过这些框架,开发者可以快速搭建高性能、可扩展的企业级应用,并将大模型集成其中。 -
跨平台性
Java的跨平台特性是其核心优势之一。通过JVM(Java虚拟机),Java代码可以在任何支持JVM的操作系统上运行,无需重新编译。这使得基于Java开发的大模型应用能够轻松部署到不同的环境中,无论是服务器端、桌面端还是移动设备。 -
丰富的库支持
Java生态系统中有许多成熟的机器学习库,如Deeplearning4j、Apache Spark MLlib等。这些库为开发者提供了丰富的工具,用于构建和部署机器学习模型。此外,Java还支持与其他语言的互操作性,例如通过JNI(Java Native Interface)调用C/C++编写的高性能库。 -
性能优化能力
Java在性能优化方面表现出色,尤其是在处理高并发请求时。通过JVM的垃圾回收机制、多线程支持和性能调优工具,Java应用能够高效地运行,满足企业级应用对性能和稳定性的要求。
(三)大模型技术对Java生态的影响
大模型的崛起对Java生态产生了深远的影响。一方面,Java社区积极拥抱大模型技术,推出了多个开源项目和框架,如DJL(Deep Java Library)和LangChain4J等。这些项目不仅为Java开发者提供了与大模型交互的接口,还推动了Java在人工智能领域的应用。另一方面,大模型技术也促使Java不断优化其性能和语法,以更好地适配人工智能的需求。
例如,DJL是一个开源的深度学习框架,它提供了跨语言的接口,支持多种深度学习引擎(如PyTorch、TensorFlow)。通过DJL,Java开发者可以直接加载和使用预训练的大模型,而无需深入了解底层的深度学习框架。这种无缝集成使得Java在人工智能领域的应用变得更加广泛。
三、Java与大模型结合的工具与库
(一)Deeplearning4j
Deeplearning4j是Java原生的深度学习框架,支持自有格式和ONNX格式,可用于基础模型训练。它提供了丰富的神经网络架构和算法,能够满足多种应用场景的需求。Deeplearning4j的优势在于其与Java生态系统的深度集成,开发者可以轻松地将其嵌入到现有的Java项目中。
此外,Deeplearning4j还支持分布式计算,能够利用多台机器的计算资源进行模型训练。这对于处理大规模数据集和复杂的模型训练任务非常有帮助。社区活跃,提供了丰富的文档和示例代码,方便开发者快速上手。
示例代码:
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.Adam;
import org.nd4j.linalg.lossfunctions.LossFunctions;public class Deeplearning4jExample {public static void main(String[] args) {// Define the neural network configurationMultiLayerConfiguration config = new NeuralNetConfiguration.Builder().seed(123).updater(new Adam(0.001)).list().layer(new DenseLayer.Builder().nIn(784).nOut(256).activation(Activation.RELU).build()).layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).activation(Activation.SOFTMAX).nIn(256).nOut(10).build()).build();// Initialize the neural networkMultiLayerNetwork model = new MultiLayerNetwork(config);model.init();// Add a listener to print the score during trainingmodel.setListeners(new ScoreIterationListener(10));// Load and prepare the dataset (e.g., MNIST)DataSetIterator trainData = ...; // Load training dataDataSetIterator testData = ...; // Load test data// Train the modelmodel.fit(trainData, 10);// Evaluate the modelEvaluation eval = model.evaluate(testData);System.out.println(eval.stats());}
}
(二)DJL(Deep Java Library)
DJL是一个跨语言接口,支持PyTorch/TensorFlow等多种深度学习框架。它允许Java开发者直接加载和使用HuggingFace等平台上的预训练模型,而无需深入了解底层的Python代码。DJL的设计目标是为Java开发者提供一个简单、高效且与引擎无关的深度学习框架。
DJL的核心优势在于其跨平台性和灵活性。它支持多种操作系统和硬件架构,能够无缝集成到现有的Java项目中。此外,DJL还提供了丰富的API和工具,用于模型的加载、推理和性能优化。通过DJL,Java开发者可以轻松地将大模型集成到企业级应用中,实现智能化的功能。
示例代码:
import ai.djl.Model;
import ai.djl.inference.Predictor;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ModelZoo;
import ai.djl.training.util.ProgressBar;import java.nio.file.Paths;public class DJLExample {public static void main(String[] args) throws Exception {// Load a pre-trained model from the model zooCriteria<Image, DetectedObjects> criteria = Criteria.builder().setTypes(Image.class, DetectedObjects.class).optModelName("yolo3").optEngine("PyTorch").optProgress(new ProgressBar()).build();try (Model model = ModelZoo.loadModel(criteria)) {try (Predictor<Image, DetectedObjects> predictor = model.newPredictor()) {// Load an image for inferenceImage image = ImageFactory.getInstance().fromFile(Paths.get("path/to/image.jpg"));// Perform inferenceDetectedObjects detections = predictor.predict(image);// Print the detected objectsfor (DetectedObjects.DetectedObject detection : detections.items()) {System.out.println(detection.getClassName() + ": " + detection.getProbability());}}}}
}
(三)ONNX Runtime Java
ONNX(Open Neural Network Exchange)是一种开放的深度学习模型格式,支持多种框架之间的模型转换和共享。ONNX Runtime Java是ONNX Runtime的Java版本,它提供了一个高性能的推理运行时,支持ONNX格式的模型。
ONNX Runtime Java的优势在于其高性能和广泛的兼容性。它能够高效地加载和运行ONNX格式的模型,同时支持多种硬件加速技术,如GPU和FPGA。此外,ONNX Runtime Java还提供了丰富的API,用于模型的加载、推理和性能优化。通过ONNX Runtime Java,Java开发者可以轻松地将预训练的大模型集成到他们的应用中,实现高效的推理功能。
示例代码:
import ai.onnxruntime.OnnxTensor;
import ai.onnxruntime.OrtEnvironment;
import ai.onnxruntime.OrtSession;
import ai.onnxruntime.OrtSession.Result;import java.nio.FloatBuffer;
import java.util.Collections;public class ONNXRuntimeExample {public static void main(String[] args) throws Exception {// Initialize the ONNX Runtime environmentOrtEnvironment env = OrtEnvironment.getEnvironment();// Load the ONNX modelOrtSession session = env.createSession("path/to/model.onnx");// Prepare the input tensorfloat[] inputArray = new float[1 * 28 * 28]; // Example input for MNISTFloatBuffer inputBuffer = FloatBuffer.wrap(inputArray);OnnxTensor inputTensor = OnnxTensor.createTensor(env, inputBuffer, new long[]{1, 28, 28});// Run inferenceResult result = session.run(Collections.singletonMap("input", inputTensor));// Process the output tensorOnnxTensor outputTensor = (OnnxTensor) result.get("output");float[] outputArray = outputTensor.getFloatArray();// Print the outputSystem.out.println("Output: " + outputArray[0]);// Close the session and environmentsession.close();env.close();}
}
(四)Apache Spark MLlib
Apache Spark是一个开源的分布式计算框架,用于处理大规模数据集。MLlib是Spark的机器学习库,提供了丰富的机器学习算法和工具,用于数据预处理、模型训练和评估。
Spark MLlib的优势在于其强大的分布式计算能力,能够高效地处理海量数据。它支持多种机器学习算法,如线性回归、决策树、随机森林等,适用于多种应用场景。此外,Spark MLlib还提供了丰富的API和工具,用于数据预处理和特征工程,使得开发者能够轻松地构建和优化机器学习模型。
通过与Spark的深度集成,MLlib能够充分利用Spark的分布式计算能力,实现高效的模型训练和推理。这对于处理大规模数据集和复杂的机器学习任务非常有帮助。同时,Spark MLlib还支持与其他工具的集成,如Hadoop、Kafka等,能够构建完整的数据处理和分析流程。
示例代码:
import org.apache.spark.ml.classification.LogisticRegression;
import org.apache.spark.ml.classification.LogisticRegressionModel;
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;public class SparkMLlibExample {public static void main(String[] args) {// Initialize Spark sessionSparkSession spark = SparkSession.builder().appName("Spark MLlib Example").master("local").getOrCreate();// Load training dataDataset<Row> trainingData = spark.read().format("libsvm").load("path/to/training_data.libsvm");// Define the logistic regression modelLogisticRegression lr = new LogisticRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8);// Train the modelLogisticRegressionModel lrModel = lr.fit(trainingData);// Make predictionsDataset<Row> predictions = lrModel.transform(trainingData);// Evaluate the modelBinaryClassificationEvaluator evaluator = new BinaryClassificationEvaluator().setLabelCol("label").setRawPredictionCol("prediction").setMetricName("areaUnderROC");double auc = evaluator.evaluate(predictions);System.out.println("Area under ROC: " + auc);// Stop Spark sessionspark.stop();}
}
四、Java访问大模型的方式
(一)远程API方式
远程API方式是Java访问大模型的常用方法之一。通过调用云服务提供商(如OpenAI、DeepSeek等)提供的API接口,Java应用可以将用户输入发送到远程服务器,并获取模型的推理结果。这种方式的优点是简单易用,开发者无需关心模型的训练和部署细节,只需调用API即可实现功能。
例如,OpenAI提供了强大的语言模型API,开发者可以通过HTTP请求将文本发送到OpenAI的服务器,并获取模型生成的文本结果。这种方式适用于需要快速集成大模型功能的应用场景,如智能客服、文档生成等。
除了云服务提供商的API,开发者还可以通过本地服务的方式访问大模型。例如,可以使用Ollama等工具在本地启动大模型服务,并通过HTTP接口与Java应用进行交互。这种方式的优点是能够更好地控制模型的运行环境和性能优化,同时避免了对云服务的依赖。
示例代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;public class OpenAIAPIExample {public static void main(String[] args) throws Exception {String apiKey = "YOUR_OPENAI_API_KEY";String prompt = "Tell me a joke.";URL url = new URL("https://api.openai.com/v1/chat/completions");HttpURLConnection connection = (HttpURLConnection) url.openConnection();connection.setRequestMethod("POST");connection.setRequestProperty("Authorization", "Bearer " + apiKey);connection.setRequestProperty("Content-Type", "application/json");connection.setDoOutput(true);String jsonInputString = "{\"model\":\"gpt-3.5-turbo\",\"messages\":[{\"role\":\"user\",\"content\":\"" + prompt + "\"}]}";try (java.io.OutputStream os = connection.getOutputStream()) {byte[] input = jsonInputString.getBytes("utf-8");os.write(input, 0, input.length);}try (BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"))) {StringBuilder response = new StringBuilder();String responseLine;while ((responseLine = br.readLine()) != null) {response.append(responseLine.trim());}System.out.println(response.toString());}}
}
(二)进程JNI方式
JNI(Java Native Interface)是一种编程框架,允许Java代码调用本地编写的代码(如C/C++)。通过JNI,Java应用可以调用底层的高性能库,实现高效的模型推理功能。
例如,llama.cpp是一个用C++编写的高性能大模型推理库,通过JNI,Java开发者可以将其集成到Java应用中,实现高效的推理功能。这种方式的优点是能够充分利用底层库的性能优势,同时保持Java的开发便利性。
AWS的DJL框架也支持JNI方式,允许Java开发者直接调用底层的深度学习引擎(如TensorFlow、PyTorch)。通过这种方式,开发者可以实现高性能的模型推理,同时避免了对Python环境的依赖。
示例代码:
import java.nio.file.Paths;public class JNIExample {static {System.loadLibrary("llama"); // Load the native library}public static void main(String[] args) {// Call the native methodString result = llamaInference("Tell me a joke.");System.out.println("Inference Result: " + result);}// Declare the native methodprivate static native String llamaInference(String prompt);
}
(三)模型转换与加载
在某些情况下,开发者需要将训练好的模型转换为Java支持的格式,以便在Java应用中加载和使用。例如,ONNX格式是一种开放的深度学习模型格式,支持多种框架之间的模型转换和共享。通过将模型转换为ONNX格式,Java开发者可以使用ONNX Runtime Java加载和运行模型,实现高效的推理功能。
此外,DJL框架也支持多种模型格式的加载,包括PyTorch、TensorFlow等。通过DJL,开发者可以直接加载预训练的模型,并在Java应用中进行推理。这种方式的优点是简单易用,开发者无需关心模型的转换细节,只需使用DJL提供的API即可实现功能。
五、Java与大模型结合的典型应用场景
(一)智能客服系统
智能客服系统是Java与大模型结合的典型应用场景之一。通过自然语言处理和文本生成技术,智能客服系统能够自动回答用户问题,提供高质量的客户服务。例如,某互联网公司利用Java和Deeplearning4j框架构建了一款智能客服系统,通过分布式计算能力优化模型训练,最终实现了高性能的客服服务。
在开发过程中,开发者首先需要对用户问题进行文本预处理,提取关键信息。然后,通过调用大模型的API接口,将用户问题发送到模型中进行推理,获取模型生成的回答。最后,将回答返回给用户,实现自动化的客户服务。这种智能客服系统不仅能够提高客户服务的效率,还能降低人工客服的成本。
(二)智能文档对话应用
智能文档对话应用是另一个典型的应用场景。通过Java结合Spring AI等框架,开发者可以构建智能文档对话应用,实现文档问答功能。这些应用能够解析不同格式的文档(如PDF、Word等),并根据用户的问题生成相关的回答。
在开发过程中,开发者需要对文档进行向量化处理,提取文档的关键信息。然后,通过调用大模型的API接口,将用户问题和文档向量发送到模型中进行推理,获取模型生成的回答。最后,将回答返回给用户,实现文档问答功能。这种智能文档对话应用不仅能够提高文档的可读性和可用性,还能为用户提供更便捷的信息获取方式。
(三)代码生成与优化
Java开发者可以利用大模型生成高质量的代码片段,并通过工具(如GitHub Copilot、Tabnine)实现智能代码补全和纠错。这种应用不仅可以提高开发效率,还能降低开发成本。
在开发过程中,开发者可以通过调用大模型的API接口,将代码片段发送到模型中进行推理,获取模型生成的优化代码。然后,将优化代码返回给开发者,实现代码的自动优化。此外,开发者还可以利用大模型的代码生成能力,快速生成模板代码、算法实现等,提高开发效率。
(四)图像识别与处理
Java结合深度学习框架(如Deeplearning4j)可用于实现图像识别和处理功能。这种技术在安防、金融、医疗等领域有广泛应用。例如,通过Java开发的图像识别系统可以识别监控视频中的人脸、车牌等信息,实现智能安防功能。
在开发过程中,开发者需要对图像数据进行预处理,提取关键特征。然后,通过调用大模型的API接口,将图像特征发送到模型中进行推理,获取模型生成的识别结果。最后,将识别结果返回给用户,实现图像识别功能。这种图像识别系统不仅能够提高安防系统的效率,还能为用户提供更安全的保障。
六、Java与大模型结合的开发实践案例
(一)智能客服系统开发
以千帆大模型开发与服务平台为例,开发者可以使用Java进行数据预处理,结合Deeplearning4j框架构建深度学习模型,并利用平台的分布式计算能力优化模型训练。
在开发过程中,开发者首先需要对用户问题进行文本预处理,提取关键信息。然后,通过调用Deeplearning4j框架,构建深度学习模型,并进行模型训练。在模型训练过程中,开发者可以利用千帆平台的分布式计算能力,优化模型的性能。最后,将训练好的模型部署到Java应用中,实现智能客服功能。
(二)文档向量化与问答系统
开发者可以通过Java实现文档的向量化处理,并结合向量数据库进行相似性检索,最终通过大模型生成回答。
在开发过程中,开发者需要对文档进行向量化处理,提取文档的关键信息。然后,通过调用向量数据库的API接口,将文档向量存储到数据库中。在用户提问时,通过调用大模型的API接口,将用户问题和文档向量发送到模型中进行推理,获取模型生成的回答。最后,将回答返回给用户,实现文档问答功能。
(三)代码生成与优化工具
开发者可以利用大模型的代码生成能力,快速生成高质量的代码片段,并通过工具(如GitHub Copilot)实现智能代码补全和纠错。
在开发过程中,开发者可以通过调用大模型的API接口,将代码片段发送到模型中进行推理,获取模型生成的优化代码。然后,将优化代码返回给开发者,实现代码的自动优化。此外,开发者还可以利用大模型的代码生成能力,快速生成模板代码、算法实现等,提高开发效率。
七、Java与大模型结合的开源项目与社区支持
(一)LangChain4J
LangChain4J是Java版的LangChain,支持与大模型(如GPT、DeepSeek)集成。它提供了丰富的API和工具,用于构建智能对话应用和文档问答系统。通过LangChain4J,Java开发者可以轻松地将大模型集成到他们的项目中,实现智能化的功能。
LangChain4J的核心优势在于其与大模型的无缝集成。它支持多种大模型平台,如OpenAI、DeepSeek等,开发者可以通过简单的配置实现与这些平台的连接。此外,LangChain4J还提供了丰富的工具,用于对话管理、文档处理和性能优化,使得开发者能够快速构建高质量的应用。
(二)Spring AI
Spring AI是Spring官方推出的AI集成框架,支持多种大模型。它提供了丰富的API和工具,用于构建智能应用和微服务。通过Spring AI,Java开发者可以轻松地将大模型集成到Spring框架中,实现智能化的功能。
Spring AI的核心优势在于其与Spring生态系统的深度集成。它支持多种大模型平台,如OpenAI、DeepSeek等,开发者可以通过简单的配置实现与这些平台的连接。此外,Spring AI还提供了丰富的工具,用于数据预处理、模型推理和性能优化,使得开发者能够快速构建高质量的应用。
(三)开源社区的支持
Java社区一直积极推动开源文化和生态系统的繁荣。在大模型领域,Java社区推出了多个开源项目和框架,如Deeplearning4j、DJL等。这些项目不仅为开发者提供了丰富的资源,还推动了Java在人工智能领域的应用。
此外,Java社区还通过举办技术交流活动、发布技术博客和教程等方式,为开发者提供了丰富的学习资源。通过这些资源,开发者可以快速掌握Java与大模型结合的技术,提升自己的开发能力。
八、Java与大模型结合的挑战与应对策略
(一)性能优化挑战
大模型的推理过程通常需要大量的计算资源,这对Java应用的性能提出了挑战。例如,在高并发请求下,Java应用可能会出现性能瓶颈,影响用户体验。
为了解决这个问题,开发者可以通过以下策略进行性能优化:
- 使用高性能的推理框架:选择合适的推理框架,如ONNX Runtime Java或DJL,能够显著提高模型推理的效率。
- 优化模型结构:通过模型压缩、量化等技术,减少模型的计算量和存储需求,提高推理速度。
- 利用硬件加速:使用GPU、FPGA等硬件加速技术,能够显著提高模型推理的效率。
- 优化Java代码:通过优化Java代码的性能,如减少垃圾回收、优化线程池等,能够提高应用的整体性能。
(二)模型部署与管理挑战
大模型的部署和管理是一个复杂的过程,涉及到模型的训练、转换、加载和更新等多个环节。在实际应用中,开发者可能会遇到模型部署失败、模型更新困难等问题。
为了解决这些问题,开发者可以通过以下策略进行优化:
- 使用模型管理工具:使用模型管理工具,如ModelDB、MLflow等,能够实现模型的版本管理、部署和更新。
- 自动化部署流程:通过自动化部署工具,如Jenkins、GitLab CI等,能够实现模型的自动化部署和更新。
- 监控模型性能:通过监控工具,如Prometheus、Grafana等,能够实时监控模型的性能,及时发现和解决问题。
(三)数据安全与隐私挑战
大模型的应用涉及到大量的用户数据,数据安全和隐私保护是一个重要的问题。在实际应用中,开发者需要确保用户数据的安全,防止数据泄露和滥用。
为了解决这些问题,开发者可以通过以下策略进行优化:
- 数据加密:对用户数据进行加密处理,确保数据在传输和存储过程中的安全性。
- 访问控制:通过访问控制机制,限制对用户数据的访问权限,确保数据的安全性。
- 数据匿名化:对用户数据进行匿名化处理,确保数据在使用过程中的隐私性。
- 遵守法律法规:遵守相关的法律法规,如GDPR、CCPA等,确保数据的合法使用。
九、未来展望
(一)技术优化与创新
随着大模型技术的不断发展,Java将在多个方面进行优化和创新,以更好地适配大模型的需求。例如,Java可能会进一步优化其性能和语法,支持更高效的并行计算和分布式处理。此外,Java社区可能会推出更多与大模型相关的开源项目和框架,为开发者提供更丰富的资源。
(二)跨领域融合与应用
Java与大模型的结合将不仅仅局限于现有的应用场景,还将拓展到更多领域。例如,在物联网领域,Java可以结合大模型实现智能设备的自动化控制和故障诊断;在金融领域,Java可以结合大模型实现风险预测和投资决策。这种跨领域的融合将为Java和大模型带来更广阔的发展空间。
(三)开源社区的推动作用
开源社区将继续在Java与大模型的结合中发挥重要作用。通过推出更多的开源项目和框架,开源社区将为开发者提供丰富的资源和学习机会。此外,开源社区还将通过举办技术交流活动、发布技术博客和教程等方式,推动Java与大模型技术的普及和发展。
(四)企业级应用的深化
随着企业对智能化需求的不断增加,Java与大模型的结合将在企业级应用中得到更广泛的应用。例如,企业可以通过Java开发的智能应用,实现客户服务的自动化、生产流程的优化和决策支持的智能化。这种企业级应用的深化将为Java和大模型带来更多的商业机会。
十、Java与大模型结合的行业案例分析
(一)金融行业:智能风险预测与决策支持
在金融领域,Java与大模型的结合为风险预测和决策支持提供了强大的工具。金融机构可以利用Java开发的智能系统,结合大模型的预测能力,对市场趋势、信用风险和投资组合进行分析和优化。
例如,某银行利用Java和Deeplearning4j构建了一个智能风险预测系统。该系统通过分析大量的历史数据和实时市场信息,利用大模型的预测能力,为银行提供信用风险评估和市场趋势预测。通过这种方式,银行能够更准确地识别高风险客户,优化投资组合,提高风险管理效率。此外,该系统还通过Java的高性能和稳定性,确保了在高并发场景下的可靠运行。
(二)医疗行业:智能诊断与辅助治疗
在医疗领域,Java与大模型的结合为智能诊断和辅助治疗提供了新的可能性。医疗机构可以利用Java开发的智能系统,结合大模型的图像识别和文本生成能力,对医学影像、病历记录等进行分析和处理。
例如,某医院利用Java和DJL框架构建了一个智能诊断系统。该系统通过分析患者的医学影像(如X光、CT等),利用大模型的图像识别能力,快速识别病变区域并生成初步诊断报告。同时,系统还可以结合患者的病历记录,利用大模型的文本生成能力,为医生提供详细的诊断建议和治疗方案。通过这种方式,医院能够提高诊断效率,减少误诊率,提升医疗服务水平。
(三)制造业:智能设备监控与故障预测
在制造业,Java与大模型的结合为智能设备监控和故障预测提供了强大的支持。制造企业可以利用Java开发的智能系统,结合大模型的预测能力,对生产设备的运行状态进行实时监控和故障预测。
例如,某制造企业利用Java和Spark MLlib构建了一个智能设备监控系统。该系统通过收集生产设备的运行数据(如温度、压力、振动等),利用大模型的预测能力,实时监测设备的运行状态,并预测潜在的故障风险。通过这种方式,企业能够提前采取措施,减少设备停机时间,提高生产效率。同时,该系统还通过Java的高性能和稳定性,确保了在大规模生产环境下的可靠运行。
十一、Java与大模型结合的教育与培训
(一)高校与职业院校的课程设置
随着大模型技术的普及,越来越多的高校和职业院校开始将Java与大模型的结合纳入课程体系。这些课程不仅涵盖了Java编程基础和大模型理论,还结合了实际开发案例,帮助学生掌握Java与大模型结合的技术。
例如,某高校开设了“Java与人工智能应用开发”课程,课程内容包括Java编程基础、深度学习理论、Deeplearning4j框架的使用以及大模型的实际应用开发。通过理论与实践相结合的教学方式,学生能够快速掌握Java与大模型结合的技术,并具备开发智能应用的能力。
(二)在线教育平台的作用
在线教育平台也在推动Java与大模型结合的教育普及。这些平台提供了丰富的课程资源和实战项目,帮助开发者快速提升技术水平。
例如,Coursera、Udemy等在线教育平台推出了多门关于Java与大模型结合的课程。这些课程涵盖了从基础到高级的多个层次,适合不同水平的学习者。通过在线学习和实践项目,开发者可以在短时间内掌握Java与大模型结合的技术,并应用到实际开发中。
(三)企业内部培训与知识共享
企业也在积极推动Java与大模型结合的内部培训和知识共享。通过组织内部培训课程、技术分享会和项目实践,企业能够提升员工的技术水平,推动技术创新。
例如,某科技企业定期组织Java与大模型结合的内部培训课程,邀请行业专家和内部技术骨干进行授课和分享。通过这种方式,企业能够快速提升员工的技术水平,推动Java与大模型技术在企业内部的应用和推广。
十二、Java与大模型结合的伦理与社会影响
(一)数据隐私与伦理问题
随着Java与大模型结合的应用越来越广泛,数据隐私和伦理问题也日益凸显。例如,在智能客服系统中,用户的个人信息可能会被收集和分析,这引发了数据隐私的担忧。此外,在医疗和金融领域,大模型的决策可能会对用户产生重大影响,这也引发了伦理问题的讨论。
为了应对这些问题,企业和开发者需要遵守相关的法律法规,如GDPR(欧盟通用数据保护条例)和CCPA(加州消费者隐私法案)。同时,企业和开发者还需要采取技术手段,如数据加密、匿名化处理等,保护用户的隐私和权益。
(二)社会影响与责任
Java与大模型结合的应用对社会产生了深远的影响。例如,在医疗领域,智能诊断系统的应用提高了医疗服务的效率和质量,但也可能引发对医生职业的替代担忧。在金融领域,智能风险预测系统的应用提高了金融机构的风险管理能力,但也可能引发对金融市场稳定的担忧。
因此,企业和开发者需要承担社会责任,确保Java与大模型结合的应用能够为社会带来积极的影响。例如,企业和开发者可以通过公开透明的方式,向用户解释大模型的工作原理和决策依据,增强用户对技术的信任。同时,企业和开发者还可以通过与政府部门、社会组织和用户的合作,共同制定技术应用的规范和标准,确保技术的健康发展。
十三、Java与大模型结合的全球趋势与国际合作
(一)全球技术趋势
在全球范围内,Java与大模型的结合已经成为一种重要的技术趋势。许多国家和地区的科技企业都在积极探索Java与大模型结合的应用场景和技术优化。例如,在美国,科技巨头如谷歌、亚马逊等正在利用Java开发大模型驱动的企业级应用;在欧洲,金融机构正在利用Java与大模型结合的技术,优化风险管理和客户服务;在中国,互联网企业和科技公司也在积极探索Java与大模型结合的应用,推动技术创新和产业升级。
(二)国际合作与交流
国际合作与交流在推动Java与大模型结合的发展中发挥了重要作用。通过国际合作,各国企业和开发者可以共享技术资源和经验,推动技术的快速发展。例如,国际开源社区通过推出开源项目和框架,如Deeplearning4j、DJL等,为全球开发者提供了丰富的技术资源。同时,国际学术会议和技术研讨会也为各国企业和开发者提供了交流和合作的平台,促进了技术的创新和应用。
(三)技术标准与规范的制定
随着Java与大模型结合的应用越来越广泛,制定统一的技术标准和规范成为了一个重要的任务。通过制定技术标准和规范,可以确保不同企业和开发者开发的应用能够兼容和互操作,推动技术的健康发展。例如,国际标准化组织(ISO)和国际电工委员会(IEC)正在制定相关的技术标准和规范,以确保Java与大模型结合的应用能够符合国际标准。

![P3629 [APIO2010] 巡逻](https://img2024.cnblogs.com/blog/3259522/202503/3259522-20250306172619253-1849040612.webp)