AutoGLM: 针对Web和手机,基于ChatGLM,具体细节并不清楚。
主要内容
提出AUTOGLM,集成了一套全面的技术和基础设施,以创建适合用户交付的可部署代理系统。首先,为GUI控制设计合适的"intermediate interface"是至关重要的,可以实现规划和定位的分离。其次,开发了一种新颖的渐进式训练框架,该框架能够为AUTOGLM提供self-evolving oneline curriculum reinforcenment learning。
动机和方法
整体动机和方法
- 一个关键的障碍在于缺乏高质量的轨迹数据,这涉及到决策过程。
现有预训练集中决策数据的稀缺性。虽然互联网包含了大量的人类知识,但它主要由静态信息组成,不能充分捕获人类决策和环境交互。构建有能力的基础Agent需要通过与真实世界环境的直接交互或从合成的轨迹中学习来丰富他们的动态知识。 - Agent是为了增强而不是取代人类的能力。
- 具体方法论文并没有讨论。
1. Important Techniques
-
预训练:关于agent预训练数据很少,且主流方法基于visual instruction tuning。因此,在预训练中适当地利用现有的具有弱监督决策信号的在线数据将有实际的帮助。此外,对于多模态感知来说,高分辨率的视觉输入是非常重要的(Cogagent),尤其对于SoM prompting定位策略。
-
多模态大模型:相比于,Robotic Process Automation (RPA)中的传统方法OCR,LMMs可以执行模糊匹配和长远规划,这得益于其对预训练中的常识和GUI环境的强大把握。尽管如此,LMMs仍然需要大量的训练来获得Agent任务所必需的强大的规划和推理能力。
-
SFT:收集标注的轨迹很耗时耗力,agent只学习一步一步地模仿专家的行为,而不完全理解其目标。且难以学习从错误中改正的能力。
-
Curriculum Learning:Agent任务的难度通常大不相同,课程学习是明智的。依次采用单步任务、简单的少步任务和复杂的长时间跨度任务进行训练。DigiRL还提出了一种简单的课程设置,根据一定时间戳对应的代理能力,从一组固定的指令中筛选出合适的任务(对于复杂任务十分有用)。
-
Reward Modeling:大多RL agent的reward function的任务受限,基于特定的规则,与LLM,LMM基座训练目标冲突。具体来说,RMs可以分为结果监督的ORM和过程监督的PRM,它们提供了不同的有效监督粒度。
-
Reinforcement Learning:将RL应用于基础Agent训练的挑战在于环境中采样的低效率。解决方法:模拟器+采样多样性。由于输出的内容是确定的格式(基于function的动作),导致过拟合,即便推理采用较高的temp,生成的结果依然很单一。
-
基础模型上扩展RL和后期训练对于建立强大的agent是至关重要的,
2. Insight 1: Intermediate Interface Design
中间界面设计对于分离Agent中的规划和定位行为至关重要。将其分离为不同的模块,可以在不受干扰的情况下,从灵活性和准确性两个维度进行改进。(可以单独对于规划模型进行优化RL等,提高规划能力?定位模型只需要优化grounding准确度。)这样的改进对于基于API的agent同样很有效果。
文章中说"While the planning could still be significantly improved, a majority of current errors arise from incorrect element identification in the grounding period",定位错误虽然严重,是否是由于规划问题导致的呢?
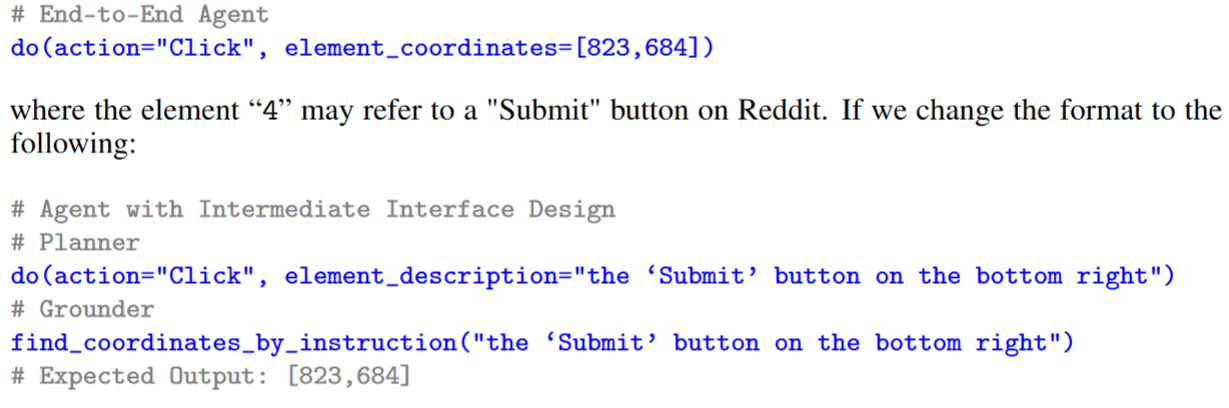
3. Insight 2: Self-Evolving Online Curriculum RL
现有的许多文献中的Agent工作都是基于专有的LLM / LMM API,其规划能力无法通过训练得到提高。本文开发了一个Self-Evolving Online Curriculum RL -- WebRL,用于从头训练规划模型。task data scarcity and policy distribution drift是很困难的问题。
- 用自演化技术来增加在线推出过程中失败的任务指令,使指令变得更复杂或更简单。这些自我进化的指令被critic过滤,然后用于下一个迭代训练阶段的输出。
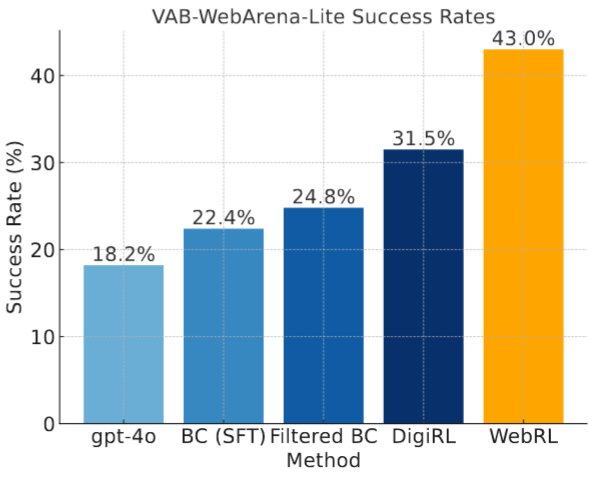
- 课程学习的一个重要问题是递进式课程安排中的policy分布漂移。
实验分析
Web数据集
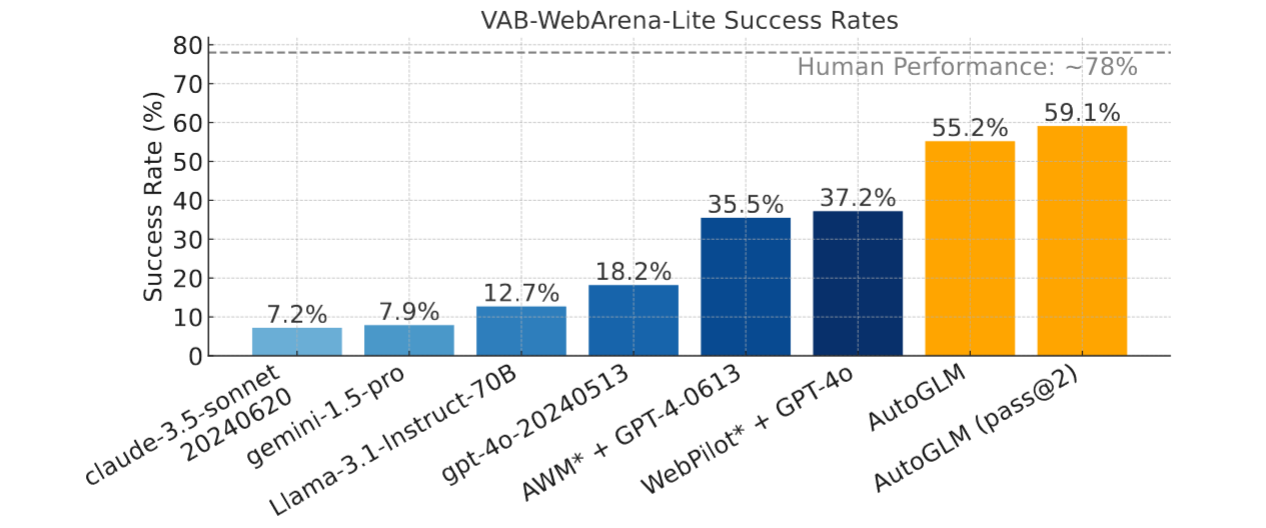
- VAB-WebArena-Lite:VAB - WebArena - Lite1是原始812 - task WebArena 的一个改进的165 - task子集,具有人工验证答案和判断功能。其设计意图是加快对WebArena的评价,保证判断的正确性。
Android数据集
- AndroidLab (VAB-Mobile) AndroidLab是一个支持可重复性评估的交互式Android基准测试环境和开发环境,覆盖了系统和一些离线可部署的英文APP。与现有的一些基准如AITW相比,它的交互特性允许对agent进行更实际的评估,并通过RL进行改进。
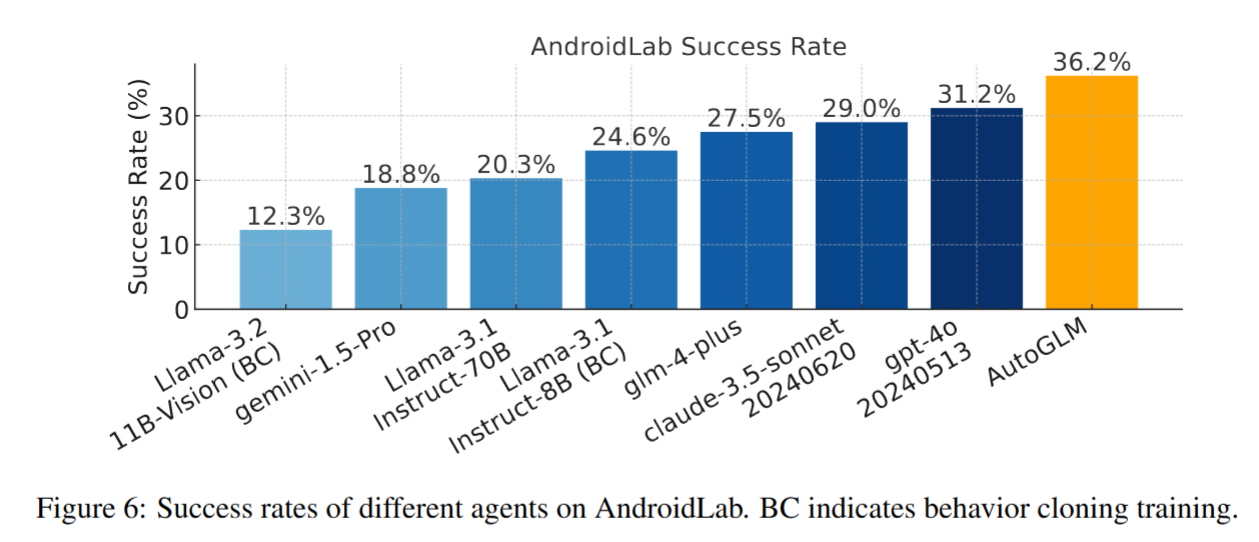
36.2%的SR是不是有点低?离实用还有距离?
-
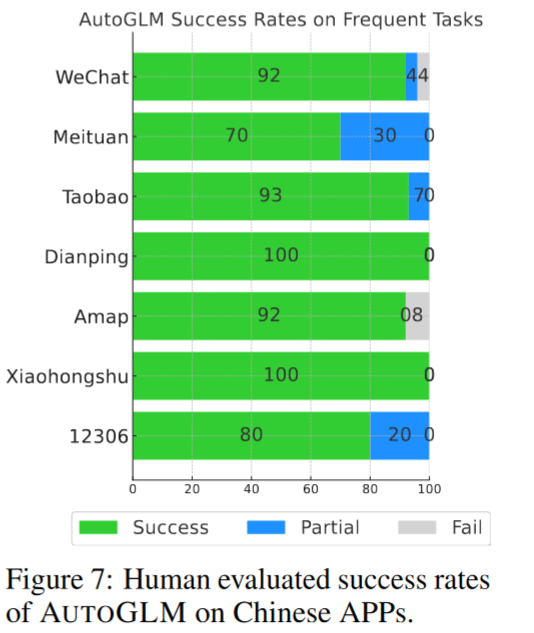
Human Evaluation on Chinese Android APPs. 为了测试面向公众用户部署的AUTOGLM的实用性,我们仔细研究了它在7个常见的中文Android APP上的频繁任务,包括微信、美团、淘宝、大众点评、高德地图、小红书和12306。
使用一个测试查询集( Cf。表2)来评估AUTOGLM在用户交付场景下的实际性能,其中最终的成功率由人工对整个执行轨迹的评估来确定(数量并不是很大)。

![[HDCTF 2023]double_code _wp](https://img2024.cnblogs.com/blog/3599043/202503/3599043-20250309170206785-1506186660.png)