介绍
(1) 背景

现有的很多基于 LLM 的 APR 方法针对的是 single-line 或者代 hunk-level 的程序修复,但它们通常依靠语句级别的故障定位技术。然而,人们普遍认为,准确识别陈述级的断层基本上可能是代价高昂的,即要求细粒度的输入或强有力的假设,从而有可能限制它们的适用性。另一方面,基于 LLM 的 function-level APR 可能更有前途,即通过将 Buggy 函数提示到 LLM 中来自动地重新注册生成了该错误函数的整个修复版本
function-level APR 的优点:(1) 修复范围大,不仅涉及单行和块级的代码修复,还涉及一个更复杂的任务,可以在功能中维修多个不连续的 lines 或 hunks;(2) 成本效益更高,无需语句级别的精确故障定位,只需定位到函数级别
(2) 挑战
- 现有的基于 LLM 的 APR 技术在 function-level 中表现出明显的性能损失,例如,ChatRepair 降低 33%,而 CodexRepair 降低 36.4%
- 缺乏对某些常用机制对于 function-level APR 的有效性的研究和验证,例如 few-shot learning 以及合并与代码修复相关的辅助信息等等
在本文的研究中,产生和验证了超过 1000 万个补丁,消耗了 8,000 多个GPU和 100,000 个 CPU 小时。据作者描述这是迄今为止对 LLM 的 APR 进行的最大的实证研究
(3) 贡献
- 对 function-level APR 进行了首次的广泛研究
- 发现具有 zero-shot learning 的 LLM 已经具有 function-level APR 的能力,并且合并辅助信息可以大大提升修复性能
- 提出了 SRepair,实现了 SOTA 并且首次实现了多功能错误的修复
实证研究
(1) RQ1: 基于 LLM 的功能级 APR 如何在 zero-shot 和 few-shot 下进行?
进行了 k-shot 的实验,具体实验设置见下图

(2) RQ2: 不同的辅助维修信息如何影响基于 LLM 的功能级 APR 的性能?
不同的辅助信息具体如下图所示,作者在不同设置下进行了实验

方法
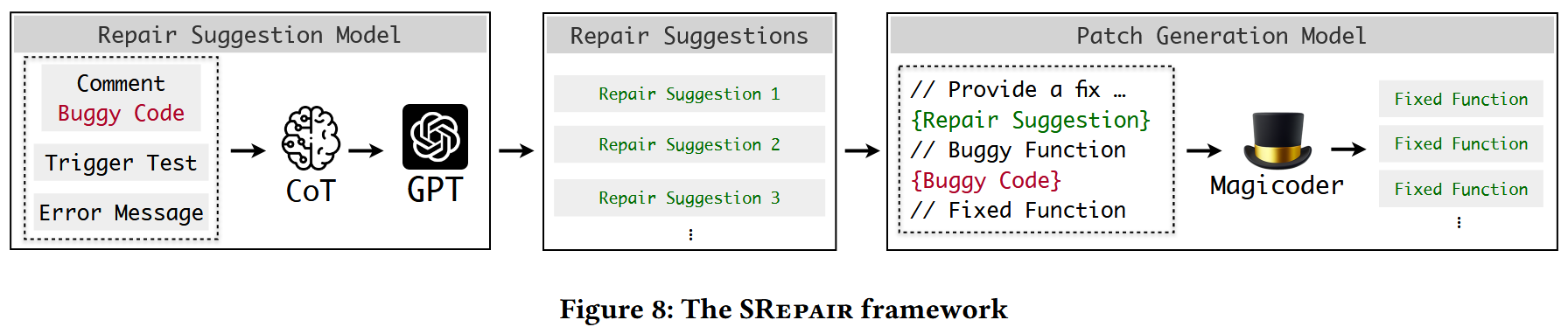
SRepair 提示 LLM 具有错误的功能和辅助维修相关的信息(即触发测试,错误消息和注释),以识别错误的根本原因,并以自然语言相应地生成维修建议。然后再将建议提供给补丁生成模型
总结
主要贡献还是在于 funtion-level APR 的实证研究,提出的 SRepair 方法感觉比较简单朴素

![[AI/GPT] Anything-LLM : (MIT)](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)




![[极客大挑战 2019]Havefun 1](https://img2024.cnblogs.com/blog/3539156/202503/3539156-20250309230559357-1393519121.png)