目录
- 名称
- TL;DR
- Method
- Code && Implementation
- Experiment
- 实现细节
- Linear Eval on ImageNet
- Zero-shot Eval on ImageNet
- Dense Prediction
- Related works中值得深挖的工作
名称
Scaling Vision Transformers to 22 Billion Parameters
论文链接
时间:2023.02
作者与单位:Google Research
相关领域:计算机视觉、大规模视觉模型
作者相关工作:PaLM2, Genmini, ViT
被引次数:604
TL;DR
本文展示了将Vision Transformer扩展到220亿参数的研究。这是目前最大的视觉模型,展示了视觉模型也可以像语言模型一样进行大规模扩展,ViT 22B取得了89.5%的ImageNet分类准确率, zero-shot的精度85.9%,蒸馏了ViT-B/16达到88.6%的精度。
Method
解决将模型参数量放大8B之后,训练Loss出现发散的问题,参考其它工作,在QK之后加上LayerNorm。
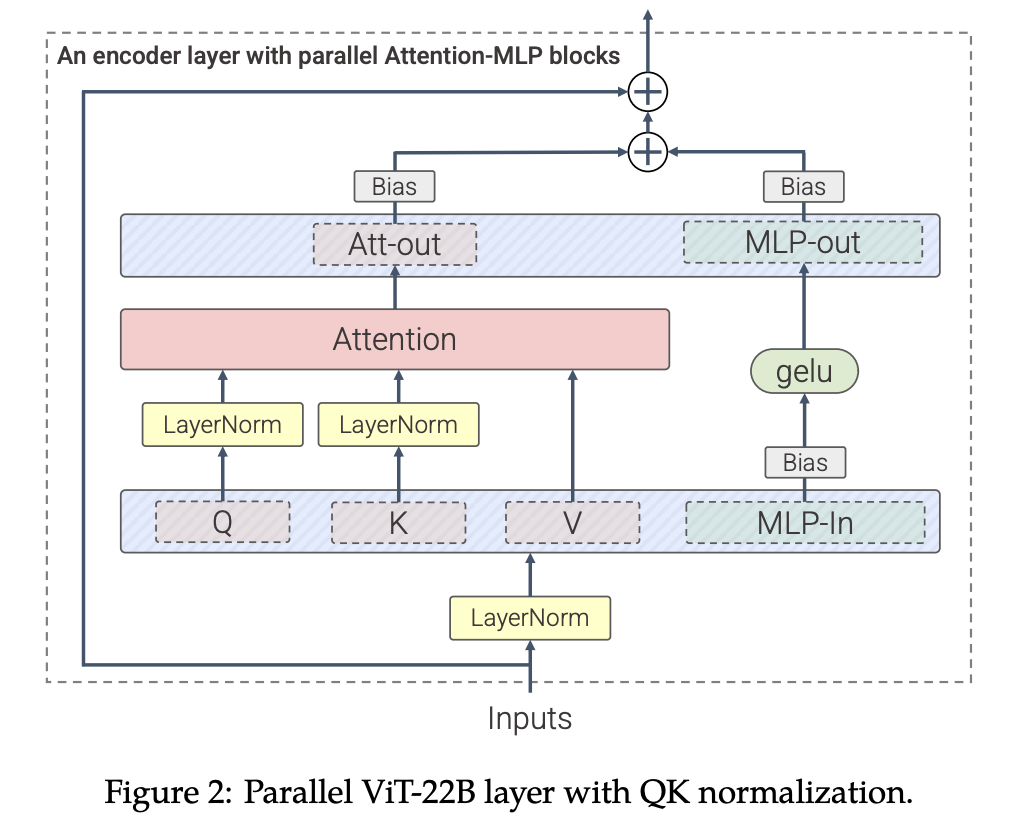
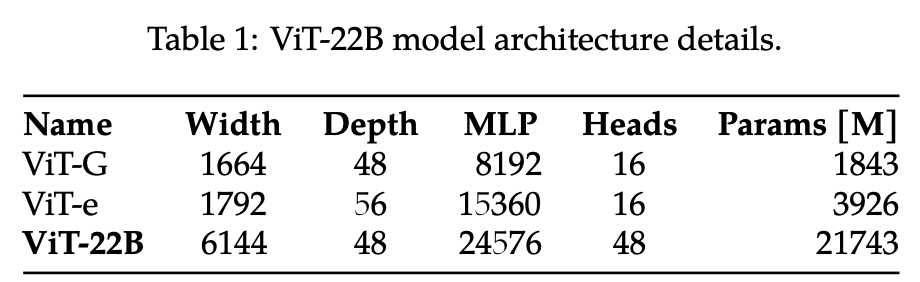
模型架构参数
Code && Implementation
训练数据:
- JFT-4B数据集(40亿图像)
Experiment
实现细节
3epoch, 1024 TPUs
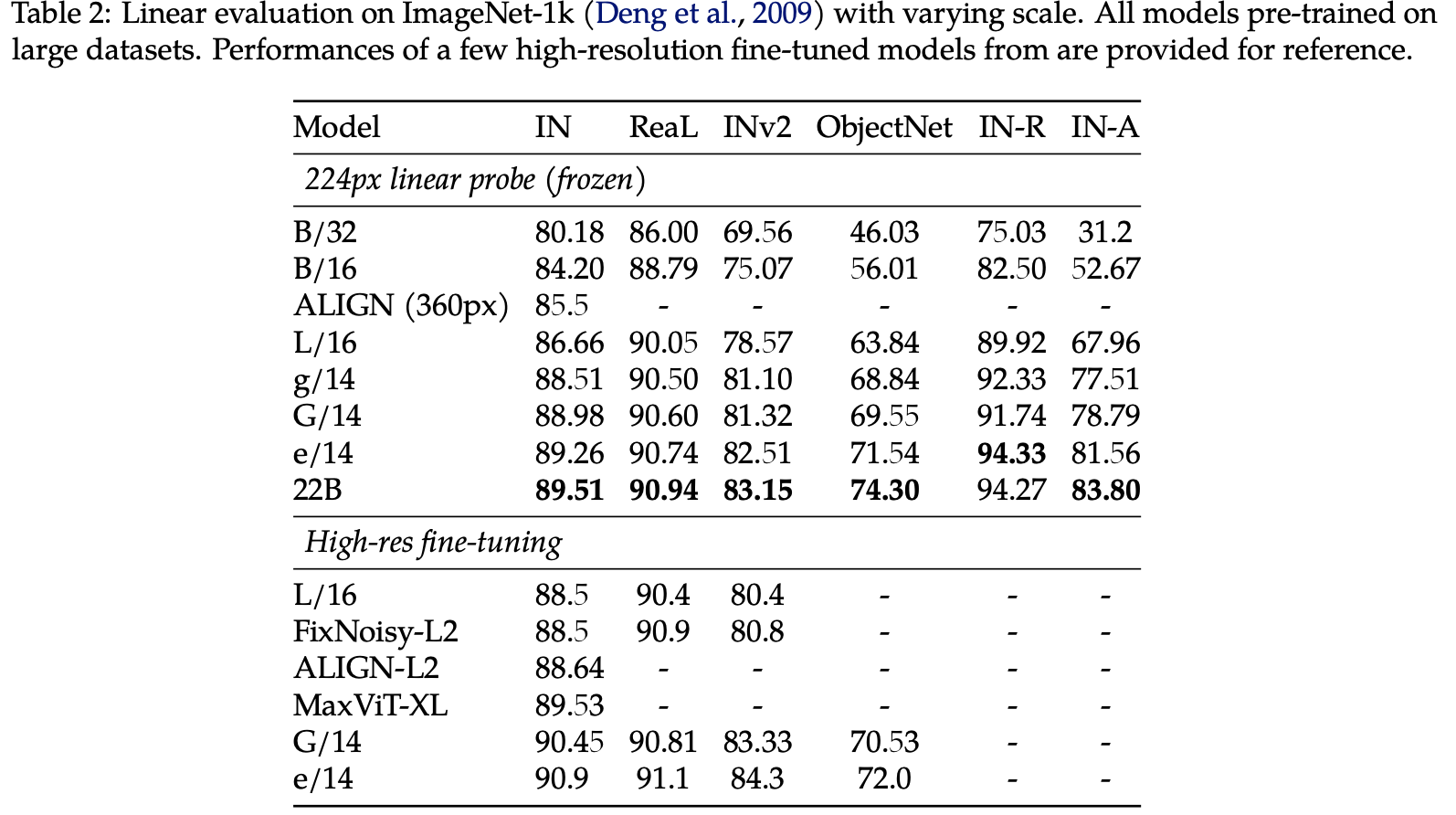
Linear Eval on ImageNet
89.5%
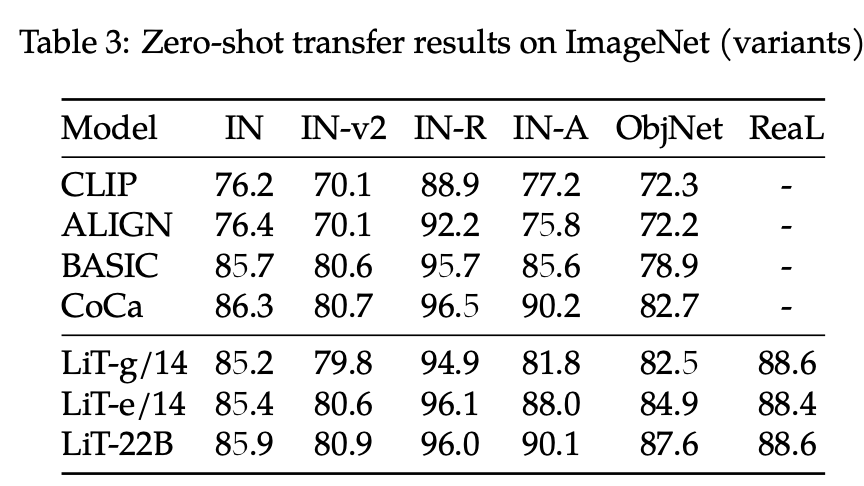
Zero-shot Eval on ImageNet
85.9%
Dense Prediction
仅1200图即可SOTA

Related works中值得深挖的工作
暂无