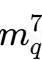全文链接:https://tecdat.cn/?p=40720
原文出处:拓端数据部落公众号
本论文旨在为对空间建模感兴趣的研究人员客户提供使用R-INLA进行空间数据建模的基础教程。通过对区域数据和地统计(标记点)数据的分析,介绍了如何拟合简单模型、构建和运行更复杂的空间模型,以及绘制空间预测和高斯随机场等内容,帮助读者掌握空间建模的基本方法和技能,为进一步的空间数据分析和研究奠定基础。
关键词
空间建模;R-INLA;区域数据;地统计数据;高斯随机场
一、引言
在当今的数据分析领域,空间数据的分析越来越受到关注。许多研究领域,如流行病学、生态学和社会科学等,都涉及到空间数据的处理和分析。空间建模的目的是将数据的空间结构纳入模型中,以更准确地描述和解释数据。R-INLA( Integrated Nested Laplace Approximations)是一个在R语言中用于空间建模的强大工具,它提供了一种高效的方法来估计空间自相关结构和拟合空间模型。
本教程的目标是向读者展示使用R-INLA进行空间数据建模的基本步骤和方法,旨在成为任何对空间建模感兴趣的人的起点。读者将能够掌握以下技能:
- 学会在区域数据上拟合简单模型。
- 了解地统计(标记点)数据建模的基础知识。
- 构建和运行更复杂的空间模型。
- 绘制空间预测和高斯随机场。
二、所需知识和软件包
本文假设读者具备广义线性模型(GLMs)和广义线性混合模型(GLMMs)、贝叶斯统计以及空间数据处理(特别是栅格数据处理)的基础知识。
在开始本教程之前,需要下载并安装一些相关的软件包,包括RColorBrewer、spdep、sp、rgdal、raster和INLA。其中,INLA的安装可能需要一些时间,建议在开始教程之前完成安装。
-
# 添加dep = T表示您还将安装软件包依赖项
-
install.packages("RColorBrewer", dep = T)
-
install.packages("spdep", dep = T)
-
install.packages("sp", dep = T)
-
install.packages("rgdal", dep = T)
-
install.packages("raster", dep = T)
-
# 下载软件包的最新稳定版本
-
install.packages("INLA",
-
repos = c(getOption("repos"),
-
INLA = "https://inla.r-inla-download.org/R/stable"),
-
dep = T)
三、数据集
本文将使用两个数据集,这些数据集来自于进行的实地调查。研究的目的是收集市周围公共绿地中的狐狸粪便(即粪便标记),并分析其中的胃肠道寄生虫。
研究的问题是:绿地面积的数量是否与以下因素显著相关:
- 发现的狐狸粪便数量?
- 每个粪便中发现的寄生虫物种数量(物种丰富度)?
使用的数据包括发现的粪便数量的区域数据(如图中的六边形网格)和每个样本中发现的寄生虫丰富度的点数据。
四、区域数据分析
区域数据通常在流行病学、生态学或社会科学研究中出现。简单来说,区域数据报告每个区域的一个值(通常是疾病的病例数),这些区域可以是行政区,如邮政编码区、议会区、地区等。区域数据的主要特点是每个区域都有明确的邻居,这使得计算自相关结构更加容易。区域数据的一个特殊子集是格网数据,它报告来自规则网格单元的区域数据(就像这里的数据一样)。这种类型的区域数据通常更受欢迎,因为空间被分割成更具可比性的区域,并且空间离散化更加均匀。然而,这种类型的区域数据很少见,因为格网数据通常是专门从点数据构建的(在这种情况下,最好直接使用点数据),而实际的区域数据通常来自于在行政区级别进行的调查,这些区域的形状自然不规则。
在INLA中对区域数据进行建模相对简单(至少与点数据集相比)。这是因为区域已经有明确的邻居(您可以通过查看图形直接判断哪些单元相邻)。这意味着我们需要做的就是将其转换为邻接矩阵,以INLA能够理解的方式指定数据集的邻居系统,然后我们就可以直接拟合模型(这与点数据集的情况完全不同)。
4.1 数据加载和可视化
为了进行空间分析,我们将使用一个经过修改的数据集,该数据集涉及在市进行的为期6个月的每个公共绿地调查中发现的狐狸粪便数量。我们构建了一个覆盖研究区域的格网,并记录了每个区域中发现的粪便数量,以及使用绿地比率。
-
# 加载格网shapefile文件和狐狸粪便数据
-
require(sp) # 用于处理空间数据的软件包
-
require(rgdal) # 用于处理空间数据的软件包
-
# Fox_Lattice是一个空间对象,包含根据数据构建的多边形(通常您会使用行政区)
-
Fox_Lattice <- readOGR("F.shp")
-
#Warning message:
-
# 忽略此警告消息,这是因为没有为每个单元分配z值(我们将响应值作为数据框附加)
-
require(RColorBrewer)
-
# 创建一个颜色调色板用于图形
-
my.palette <- brewer.pal(n = 9, name = "YlOrRd")
-
# 可视化空间中粪便的数量
-
spplot(obj = _La, cuts = 8)

图1:空间中狐狸粪便的数量
4.2 邻接矩阵计算
如前所述,INLA需要知道哪些区域是相邻的,以便计算空间自相关结构。我们通过计算邻接矩阵来实现这一点。
这个矩阵显示了每个单元的邻居关系。在两个轴上都有单元的数字ID(ZONE_CODE),您可以找到它们与哪些单元相邻(加上对角线表示单元与自身相邻)。例如,您可以用眼睛追踪单元编号50,并查看它的邻居(单元49和51)。每行最多有6个邻居(六边形有6条边),对应于格网单元的邻居数量。请注意,在这种情况下,单元已经按字母顺序排序,因此它们只与名称相似的单元相邻,所以在对角线周围有一组相邻的单元。当使用行政区时,这个矩阵可能会更混乱。
图2:邻接矩阵
4.3 模型公式指定
我们还需要指定模型公式。这个模型将测试绿地比率(GS_ratio)对每个区域中发现的狐狸粪便数量是否有线性影响。我们首先指定模型公式,这实际上并不会运行我们的模型,我们将在下一步运行模型。
-
formula <- Scat_No ~ 1 + GS_Ratio + # 固定效应
-
f(ZONE_CO, # 空间效应:ZONE_CODE是格网中每个区域的数字标识符(不适用于因子)
-
graph = La) # 这指定了格网区域的邻居关系
注意:空间效应使用BYM(Besag, York和Mollie的模型)进行建模,这是通常用于拟合区域数据的模型类型。CAR(条件自回归)和besag模型是其他选项,但在这里我们将重点关注BYM,因为这是在处理区域数据时对空间效应进行建模的合适方法。
4.4 模型运行和结果分析
现在我们准备运行我们的模型!
-
# 最后,我们可以使用inla()函数运行模型
-
Mod_Lattice <- inla(formula,
-
family = "poisson", # 因为我们正在处理计数数据
-
data = Lattice_Data,
-
control.compute = list(cpo = T, dic = T, waic = T))
-
# CPO, DIC和WAIC度量值都可以通过在control.compute选项中指定来计算
-
# 如果您想进行模型选择,这些值可以用于此目的
-
# 查看模型摘要
-
summary(Mod_Lattice)
我们现在已经运行了我们的第一个INLA模型!
在输出中,您可以找到关于模型的一些一般信息:运行时间、固定效应的摘要、模型选择标准(如果您在模型中指定了它们),以及任何随机效应的精度(在这种情况下只是我们的空间组件ZONE_CODE)。重要的是要记住,INLA使用精度(tau = 1/方差),所以精度值越高,方差值越低。
我们可以看到,GS_Ratio对发现的粪便数量有正影响(0.025分位数和0.075分位数不跨越零,所以这是一个“显著”的正影响),并且ZONE_CODE的iid(随机因子效应)的精度比空间效应低得多,这意味着在这种情况下,使用ZONE_CODE作为标准的因子随机效应可能就足够了。
4.5 设置先验
我们还可以通过在公式中指定超参数(先验分布的参数)的先验来设置先验。INLA使用精度(tau = 1/方差),所以默认情况下,非常低的精度对应于非常高的方差。请记住,需要为模型的线性预测器指定先验(因此需要根据数据分布进行转换),在这种情况下,它们遵循对数伽马分布(因为这是一个泊松模型)。
随机(空间)效应的后验均值也可以计算并绘制在格网上。为此,我们需要提取格网中每个单元的空间效应的后验均值(使用emarginal()函数),然后将其添加到原始shapefile中,以便我们可以映射它。
这表示在考虑了模型中包含的协变量后,响应变量在空间中的分布。可以将其视为根据模型的响应变量在空间中的“真实分布”(显然,这仅与我们拥有的模型一样好,如果估计不佳、我们有缺失数据或我们未能在模型中包含重要的协变量,它将受到影响)。
-
# 计算区域数量
-
Nares <- length(Lat_Data[,1])
-
# 选择每个区域的空间随机效应的后验边缘分布
-
# 这些对应于空间随机效应(zeta)的边缘分布的前347个(单元数量)项
-
zone.ix <- Mod_Lat$ZONE_CODE[1:Nareas]
-
# 对每个区域的边缘进行指数运算,以将其返回到原始值(请记住,这是一个泊松模型,因此模型的所有组件都进行了对数变换)
现在我们准备创建一个颜色调色板并制作我们的地图!
-
-
spplot(obj = Fost, zcol

图3:根据我们的模型绘制的空间后验均值,显示狐狸粪便的数量
同样,我们可以绘制与后验均值相关的不确定性。与任何建模一样,不仅要考虑均值,还要考虑我们对该均值的信心程度。

图4:根据我们的模型绘制的空间后验均值的不确定性
请注意,后验均值在不确定性最高的地方最高。我们有一些区域,响应变量达到非常高的数值,这是因为这些区域缺少GS数据(GS = 0),所以模型对此进行了补偿;然而,这些区域也是我们不确定性最高的地方,因为模型无法产生准确的估计。
五、地统计(标记点)数据建模
对于本分析,我们将使用地统计数据,也称为标记点数据。这是最常见的空间数据类型之一。它包括点(带有相关坐标),每个点都有一个附加的值,通常是我们感兴趣的响应变量的测量值。其思想是这些点是在空间中无处不在的平滑空间过程的实现,而这些点只是这个过程的样本(我们永远无法对整个过程进行采样,因为在连续空间中有无限个点)。
一个经典的例子是土壤pH值:这是土壤的一种属性,它无处不在,但我们只会在某些位置测量它。通过将我们收集的值与其他测量值联系起来,我们可以发现土壤pH值取决于降水水平或植被类型,并且(有足够的信息)我们可以重建潜在的空间过程。
我们通常对理解潜在过程(哪些变量影响它?它在空间和时间上如何变化?)以及重建它(通过生成模型预测)感兴趣。
在这个例子中,我们将使用与生成空间数据相同的点(狐狸粪便),但我们将关注每个粪便中发现的寄生虫物种数量(Spp_Rich)。数据集包括每个点的位置(每个点都是在调查中发现的粪便),但我们在此感兴趣的是对每个粪便中发现的寄生虫物种数量进行建模。这意味着数据集中的每个点都有一个附加的值(一个标记,因此称为标记点过程),这就是我们感兴趣的建模内容。在这种情况下,点没有明确的邻居,因此我们需要构建空间的人工离散化,并告诉INLA离散化的邻居结构。
数据集还包含与每个样本相关的许多其他变量:
JanDate(收集样本的日期)Site(从哪个公园收集的)Greenspace variability(GS_Var),这是一个分类变量,用于测量不同绿地类型的数量(低、中、高)
在这种情况下,我们将把胃肠道寄生虫的物种丰富度建模为绿地比率的函数,同时考虑空间效应和上述其他协变量。
当将点数据集转换为空间对象时,我们需要指定一个坐标参考系统(CRS)。此数据集的坐标以东坐标/北坐标表示,并使用国家网格(BNG)进行投影。如果您使用多个可能不在同一坐标系统中的shapefile文件,这一点很重要,它们将必须相应地进行投影。
注意:CRS的选择应基于研究区域的范围。
- 小区域:对于小区域(如此处的区域),东坐标 - 北坐标系统是最好的。它们有效地在平面上表示坐标(不考虑地球曲率以及因此投影形状的修改)。
- 中等规模研究:对于中等规模的研究(国家级别/多个国家级别),我们应该使用纬度 - 经度,因为这将考虑更现实的地图形状。
- 大陆和全球规模研究:最后,对于在大陆和全球规模进行的研究,我们应该使用弧度,并在考虑地球曲率的情况下拟合网格。
尝试在同一地图上绘制我们的点和shapefile文件将不起作用,因为它们的坐标表示在不同的系统中,无法直接绘制。

图5:混合不同的坐标系统会导致错误的图形!
然而,如果我们使用spTransform()函数更改Scot_Shape的CRS,我们可以正确地将狐狸粪便点和shapefile文件一起映射。

图6:
现在数据已正确加载,我们可以开始将地统计INLA模型所需的所有组件组合在一起。我们将首先拟合一个简单的基础模型,其中仅包含一个截距和空间效应,然后在此基础上增加模型的复杂性。
5.1 模型的基本组件
模型的绝对必要组件包括:
- 网格(Mesh):与区域数据不同,点数据没有明确的邻居,因此我们必须计算空间中每个可能点之间的自相关结构,这显然是不可能的。因此,第一步是离散化空间以创建一个网格,该网格将创建人工(但有用)的邻居集,以便我们可以计算点之间的自相关。
INLA使用三角形网格,因为它更灵活,可以适应不规则的空间。有几种选项可用于调整网格。
理想情况下,我们的目标是拥有一个规则的网格,内部有一层三角形,没有聚集,并且在外层有一个平滑的、较低密度的三角形。

图7
第三个网格似乎是最规则的,并且适合这个数据集。

图8:这是要使用的最佳网格。
注意:您可以看到网格延伸到海岸线之外进入海洋。由于我们试图评估绿地比率对狐狸寄生虫物种的影响,将属于海洋的区域包含在网格中没有意义。有两种可能的解决方案:第一种是使用这个网格运行模型,然后简单地忽略模型为海洋区域提供的结果。第二种是修改网格以反映海岸线。
5.2 投影矩阵(Projector matrix)
现在我们已经构建了我们的网格,我们需要将数据点与网格顶点相关联。投影矩阵使用网格顶点作为明确的邻居,为模型提供数据集的邻域结构。
如前所述,地统计数据没有明确的邻居,因此我们需要使用网格对空间进行人工离散化。投影矩阵将点投影到网格上,其中每个顶点都有明确指定的邻居。如果数据点落在顶点上(顶点是多边形的每个角点,这里是三角形),那么它将直接与相邻的顶点相关联(就像图中的蓝色点)。然而,如果数据点落在网格三角形内(深红色点),它的权重将根据与每个顶点的接近程度在三个顶点之间分配(带有深色边框的红色、橙色和黄色点)。然后,原始数据点将根据定义三角形的顶点的邻居拥有更多的“伪邻居”,权重的分配方式与这些顶点类似(但是,每个数据点的总权重始终为1)。
图9:投影矩阵如何创建邻居的图形表示。
投影矩阵会自动计算每个点的邻域的权重向量,并通过将网格和数据点的位置提供给函数来计算。
5.3 SPDE
SPDE(随机偏微分方程)是Matérn协方差函数的数学解,它实际上允许INLA有效地计算网格顶点处数据集的空间自相关结构。它计算网格顶点之间的相关结构(然后将通过使用投影矩阵计算的向量进行加权,以计算适用于实际数据集的相关矩阵)。
5.4 拟合基本空间模型
我们将首先拟合一个仅包含截距和空间效应的模型,以展示如何编写此代码。这个模型只是测试空间自相关对寄生虫物种丰富度的影响,而不包括任何其他协变量。
需要记住的一件事是,INLA语法使用格式f(Covariate Name, model = Effect Type)对非线性效应进行编码。对于空间效应,模型名称是您为SPDE指定的名称(在这种情况下为spde1)。
-
#首先,我们指定公式
-
formula_p1 <- y ~ -1 + Intercept +
-
f(spatd1, model = se1) # 这指定了空间随机效应。名称(sield1)由您选择,但需要与您将在模型中包含的名称相同
我们已经有了公式,现在准备运行模型!
我们可以探索固定效应和随机效应的结果。
-
# 我们可以通过使用以下方式访问固定(这里只有截距)和随机效应的摘要
-
round(Mod_Point1$summary.fixed,3)
-
round(Mod_Point1$summary.hyperpar[1,],3)
我们还可以使用emarginal()函数计算随机项的方差(请记住,INLA使用精度,因此我们不能直接提取方差)。
注意:INLA提供了许多函数来处理后验边缘。在本教程中,我们仅使用emarginal()(它计算函数的期望,并用于将精度转换为方差等),但值得知道的是,有一整套用于边缘操作的函数,例如从边缘采样、转换它们或计算摘要统计信息。
现在回到提取我们的随机项方差。
我们可以在此提取的两个最重要的东西是范围参数(kappa)、标称方差(sigma)和范围(r,自相关降至0.1以下的半径)。这些是空间自相关的重要参数:Kappa越高,空间自相关结构越平滑(并且范围越高)。较短的范围表示紧密相邻的点之间自相关的急剧增加和更强的自相关效应。
5.5 构建和运行更复杂的空间模型
通常,我们感兴趣的是拟合包含协变量的模型,并且关注这些协变量在考虑空间自相关的情况下如何影响响应变量。在这种情况下,我们需要在模型构建中添加另一个步骤。我们将保留之前使用的相同网格(Mesh3)和投影矩阵(A_point),并在此基础上继续进行。我将简要提及对模型的各种自定义(例如时空建模)。
现在,我们将扩展我们的模型以包含所有可用组件:
- 网格
- 投影矩阵
- 相关结构说明符(SPDE),包括对空间结构的PC先验
- 空间索引
- 堆叠(Stack)
- 公式
5.5.1 指定PC先验
我们可以为空间项提供先验。一种特殊类型的先验(惩罚复杂度或PC先验)可以施加在SPDE上。这些先验被广泛使用,因为它们(正如其名称所示)惩罚模型的复杂性。实际上,它们使空间模型向基础模型(没有空间项的模型)收缩。为此,我们应用弱信息先验,惩罚小范围和大方差。有关PC先验如何工作的更详细理论解释,请查看Fulgstad等人(2018)的论文。
5.5.2 空间索引
一个有用的步骤包括构建空间索引。这将为SPDE模型提供所有必需的元素。这并不是严格必要的,除非您想要创建多个空间场(例如特定年份的空间场)。重复的数量将产生iid(独立同分布)的重复(方差将在各个级别上均匀分布,这相当于GLM中的标准因子效应),而组的数量将产生相关的重复(组的每个级别将依赖于前一个/后一个级别)。
以下显示的是索引的默认设置(未指定重复或组):
5.5.3 堆叠
堆叠因其特别难以处理而闻名,但简而言之,它提供了将在模型中使用的所有元素。它包括数据、协变量(包括线性和非线性协变量)以及每个协变量的索引。需要记住的一件事是,堆叠不会自动包含截距,因此需要明确指定。
注意:在这种情况下,截距被拟合为在空间中是常数(它与空间效应一起拟合,这意味着在网格的每个n.spde顶点处它始终为1)。不一定是这种情况,如果您想拟合截距在整个数据集中是常数(并因此受到空间效应的影响),您可以将其与其他协变量的列表一起编码,但请记住,然后您需要将截距指定为Intercept = rep(1, n.dat),其中n.dat是数据集中的数据点数量(而不是网格顶点的数量)。
5.5.4 拟合模型
在公式中,我们指定每个协变量应该具有的效应类型。线性变量以标准GLM方式指定,而随机效应和非线性效应需要使用f(Cov Name, model = Effect Type)格式指定,类似于我们到目前为止看到的空间效应项。
最后,我们准备运行模型。这包括堆叠(要包含哪些数据)、公式(如何对协变量进行建模)以及模型的详细信息(例如计算模型选择工具或进行预测)。此模型测试GS_ratio(绿地比率)和GS变异性对寄生虫物种丰富度的影响,同时考虑空间自相关、时间自相关以及样本采集的地点(以考虑重复采样)。
现在我们可以制作一些图来可视化我们感兴趣的一些变量的影响。
绿地的数量(GS Ratio)显然与物种丰富度呈正相关,但效果相当线性,所以我们可能希望在下一个模型中考虑将其拟合为线性效应(这样做我们不会丢失太多信息)。
-
plot(Modummary.ranDate[,1:2],
-
type = "l",
-
lwd = 2,

图11:根据我们的模型结果可视化效应
现在我们可以提取关于空间场的一些进一步信息。
我们可能也有兴趣可视化高斯随机场(GRF)。如前所述,GRF表示在考虑模型中的所有协变量后,响应变量在空间中的变化。它可以被视为“响应变量在空间中的真实分布”。
然而,这也可能反映模型中缺少重要的协变量,检查GRF的空间分布可以揭示缺少哪些协变量。例如,如果海拔与响应变量呈正相关,但未包含在模型中,我们可能会在海拔较高的区域看到较高的后验均值。熟悉地形的研究人员将能够识别这一点并相应地改进模型。
我们需要为GRF的均值和方差创建空间对象。
xmean_ras和xsd_ras是栅格项,可以使用writeRaster()函数在R之外(包括在GIS软件中)导出、存储和操作。
现在我们可以绘制GRF(我使用了与区域数据相同的配色方案):

图12:高斯随机场的均值和方差
六、绘制空间预测和高斯随机场
最后,我将展示如何从INLA模型生成空间预测。这将涉及一些栅格和矩阵的操作。本质上,这归结为创建一个我们没有值但希望使用模型估计为响应变量生成预测的空间坐标网格(考虑数据的空间自相关结构)。

图13:绿地
为了使用INLA生成预测,我们需要生成一个数据集(在我们希望预测的位置附加坐标),并为其附加一系列缺失的观测值(在R中编码为NA)。当缺失的观测值在响应变量中时,INLA会自动计算相应线性预测器和拟合值的预测分布。
使用INLA语法,可以通过拟合一个响应变量设置为NA的堆叠,然后将此堆叠与估计堆叠(与我们到目前为止使用的类似)连接来生成模型预测。然后,我们可以提取预测响应变量的值,并使用inla.mjector()函数将这些值投影到网格顶点上(就像我们之前绘制GRF时所做的那样)。
首先,我们将绿地数量(GS ratio)的栅格值转换为矩阵,然后将坐标重新分配到一个ncol X nrow单元的矩阵中(列数和行数)。
接下来,我们需要创建一个ncol X nrow单元的网格,其中包含我们希望投影模型预测的点的坐标。
-
Seqid <- seq(from = GS_Prnt@xmin,
-
to = GS_Pred
现在我们已经有了预测的坐标网格,接下来要创建一个新的堆叠用于预测,这个堆叠将包含预测点的信息以及与估计模型相同的结构(协变量等)。
现在我们可以使用连接后的堆叠来运行模型并获取预测结果。
接下来,我们将预测的均值和标准差转换为栅格对象,以便进行可视化。
现在我们可以绘制预测的均值和标准差的栅格图,以直观地展示寄生虫物种丰富度的预测情况。
-
# 绘制预测均值的栅格图
-
par(mfrow = c(1, 1), mar = c(2, 2, 1, 1))
-
plot(prean

通过以上步骤,我们完成了从构建模型到生成预测以及可视化预测结果的整个过程。这些预测结果可以帮助我们更好地理解在不同空间位置上寄生虫物种丰富度的可能情况,同时考虑了空间自相关和其他协变量的影响。
七、结论
在本文中,我们深入探讨了使用INLA(集成嵌套拉普拉斯近似)在R中进行空间数据建模的过程,特别是针对地统计(标记点)数据。我们从数据加载和准备开始,详细介绍了如何处理坐标参考系统,确保数据的正确投影和可视化。
我们构建了空间模型的基本组件,包括网格、投影矩阵和SPDE,通过逐步演示,展示了如何根据数据特点选择合适的参数来构建这些组件。在模型拟合方面,我们先从一个简单的仅包含截距和空间效应的基础模型入手,逐步扩展到包含多个协变量的复杂模型,包括如何指定PC先验、空间索引和堆叠等关键步骤。
在模型结果的分析和可视化方面,我们不仅展示了如何提取固定效应和随机效应的摘要信息,还介绍了如何计算随机项的方差,以及如何可视化非线性效应、高斯随机场和空间预测结果。这些可视化工具帮助我们直观地理解模型的输出,发现变量之间的关系以及空间上的变化模式。