说明:
这个小案例主要是访问Microsoft Bing网站去爬取“车牌”图片,代码写的时候不规范,但是效果还行
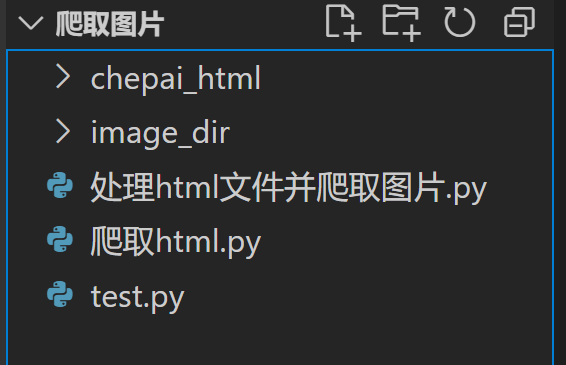
- 文件结构为下图:
- 具体思路
#爬取html.py
import requests
import time
from tqdm import tqdm
import os
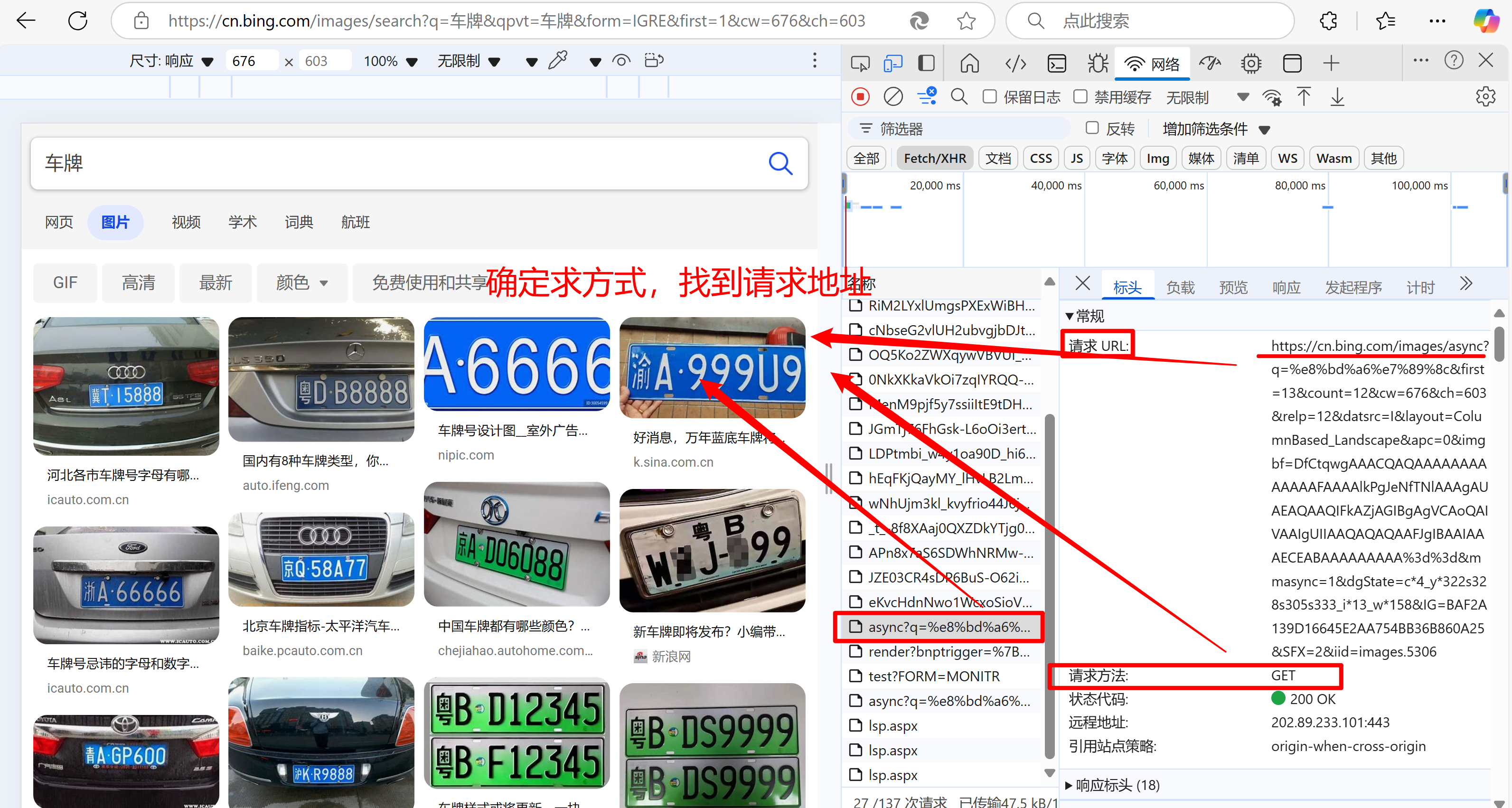
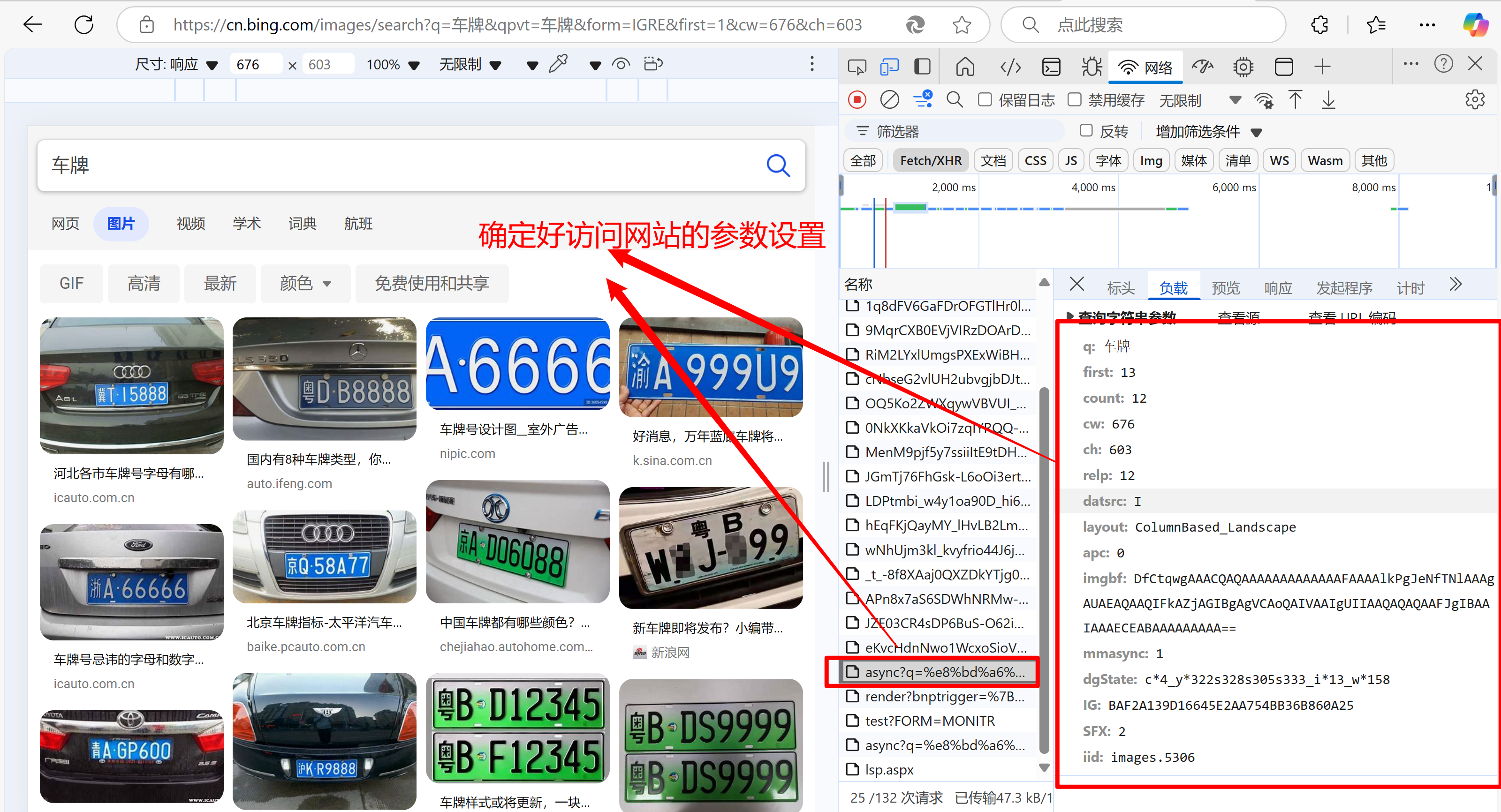
url='https://cn.bing.com/images/async'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Mobile Safari/537.36 Edg/134.0.0.0',}
# first=input('请输入要爬取的图片数量:')
# count=input('请输入要爬取的图片数量:')params={'q':'车牌',
'first': 13,
'count': 12,#爬取图片的数量,不用改动
'cw': 437,
'ch': 603,
'relp': 12,
'datsrc': 'I',
'layout': 'ColumnBased_Landscape',
'apc': 0,
'imgbf': 'DfCtqwgAAACQAQAAAAAAAAAAAAAFAAAAsUuBIONfTNlAgBAASAEAQgAQIFEABiAGIBgAgNDAoQAIUAAIgUYIAAiAQCAAABIiIBgIIAAAACkCAAAAAAAAAA==',
'mmasync': 2,
'dgState': 'c*2_y*725s715_i*13_w*204',
'IG': '32F3E4B3953D4FFCB5B4E5EDB527C8EC',
'SFX': 2,#页数
'iid': 'images.5306',
}
if not os.path.exists('./chepai_html'):os.mkdir('./chepai_html')
for i in tqdm(range(3)):#这里遍历的数字越大爬取的html文件就越多response=requests.get(url=url,headers=headers,params=params)time.sleep(3)chepai_html=response.textwith open(f'./chepai_html/chepai'+f'_{i}'+'.html','w',encoding='utf-8') as fp:fp.write(chepai_html)params['first']+=params['count']params['SFX']+=1params['count']=35#处理html文件并爬取图片.pyfrom lxml import etree
import requests
import os
import re
from tqdm import tqdm
def load_img(html_name):headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Mobile Safari/537.36 Edg/134.0.0.0',}with open(f'./chepai_html/{html_name}',encoding='utf-8') as f:text=f.read()tree=etree.HTML(text)img_src_list=tree.xpath('//img/@data-src')p=re.compile(r'https.*/OIP-C\.(?P<name>.*)\?.*')if not os.path.exists('./image_dir'):os.mkdir('./image_dir')for url in img_src_list:response=requests.get(url,headers=headers).contentwith open('./image_dir/'+p.search(url).group('name')+'.jpg','wb') as f:f.write(response)print('end')for html_name in tqdm(os.listdir('./chepai_html')):load_img(html_name)