1 简介
- 最近
Meta发表了一篇图灵奖得主Yann LeCun参与的关于“Augmented Language Models: a Survey/增强语言模型:一篇调查”的综述,系统归纳了语言模型的推理能力以及使用外部工具能力的工作(推理指将复杂任务分解为更简单的子任务,工具包括调用模块等 ),并指出这个方向有可能解决传统语言模型所面临的可解释性,一致性以及扩展性的问题。
于是在这里会对这篇文章做进一步的解读,更深入了解增强语言模型的做法以及特性。(可能是作者水平有限,认为这篇综述有点难懂,读了数遍才有些许头绪,所以后续解读可能有不对的地方,欢迎指正)

- 论文摘要
本调查回顾了语言模型(LMs)与推理技能和使用工具的能力相增强的工作。
前者被定义为将潜在的复杂任务分解为更简单的子任务,而后者包括调用代码解释器等外部模块。
LMs可以通过启发式方法单独或组合地利用这些增强,或者从演示中学习如何这样做。
在坚持标准的缺失标记预测目标的同时,这种增强的lm可以使用各种(可能是非参数的)外部模块来扩展其上下文处理能力,从而脱离纯语言建模范式。
因此,我们将它们称为增强语言模型(ALMs)。
缺失的标记目标允许alm学习推理、使用工具,甚至行动,同时仍然执行标准的自然语言任务,甚至在几个基准测试中优于大多数常规lm。
在这项工作中,在回顾了alm的当前进展之后,我们得出结论,这个新的研究方向有潜力解决【传统lm的常见局限性】,如【可解释性】、【一致性】和【可扩展性】问题
2 背景
-
目前大规模语言模型(LLM)在NLP领域大放异彩,能够以前所未有的性能去执行各种任务,为更多可能的人机交互形式开辟了道路,近期爆火的
ChatGPT就是最好的证明。 -
但是大规模语言模型由于模型幻视等问题在大规模推广时受到限制,很多
LLM的能力随着模型参数量增加到一定限度才会涌现,LLM的模型规模跟数据需求在很多情况下都是不符合实际的。 -
Meta的研究员认为这些问题源于LLM的一个基本缺陷:
a) 单个参数模型
b) 有限的上下文(N个token)。
随着硬件跟软件技术的发展,随着上下文N的长度不断增长,但是大多数LLM仍然只用到较小的上下文尺寸。
于是针对这个问题出现了很多工作,要不通过信息抽取模块获得相关的外部文档,增强语言模型的输入,又或者利用语言模型去调用外部工具,作者将上述语言模型称为增强语言模型ALM(Augmented language models),ALM包括以下几部分
Reason: 推理,将潜在复杂任务分解为简单子任务的能力,而这些子任务是语言模型可以自身解决或者调用其他工具解决。
Tool: 工具,语言模型通过规则或者特殊token调用外部模块的能力,包括检索外部信息的检索系统,或者可以调用机器手臂的工具等。
Act:行为,ALM调用的工具会对虚拟或者真实世界产生影响并观测到结果。
3 Reason/推理
- 对于增强语言模型而言,推理能力指的是将潜在的复杂任务分解成更简单的子任务,通过递归或者迭代的方式解决。
目前依旧不能完全理解语言模型是否真的具备这个能力,还是只是简单的生成概率值更高的长文本。
这种方式的问题主要在于很难探索尽可能多的推理路径,以及没办法保证中间过程的可靠性。
关于增强语言模型推理能力的策略有以下几种:
3.1 Eliciting reasoning with prompting/用提示引出推理的
-
传统的
prompting,将下游任务的示例转化为语言模型建模问题,包括zero-shot跟few-shot的方式,其中zero-shot的prompt只用到当前问题的输入,而few-shot的prompt则会在当前问题输入前插入多个下游任务的示例(对应的问题-答案对),也称为in-context learning或者few-shot learning。 -
不同于传统的
prompting,Eliciting reasoning with prompting,利用prompt去诱导模型推理的推理能力,通过prompt鼓励语言模型通过循序渐进的方式去解决问题,并出现多个中间步骤。
对于few-shot场景,具体做法就是在prompt里阐述清楚多个示例的具体推理过程,从而启发语言模型按照示例的推理过程,并最终生成答案;
对于zero-shot场景,具体做法就是在先使用一个启发式prompt指导模型先生成具体的推理过程,然后再将推理过程加入prompt,去生成最终的答案(之前的文章Prompt learning系列之Let’s think step by step就是这种思路)。
类似于人类在处理非常复杂的算法问题,不会一步就算出结果,而是会逐步计算,记录整个解题过程,进而算出最终结果。
具体可见下文的两个few-shot跟zero-shot示例。

图1: few-shot示例

图2: zero-shot示例
3.2 Recursive prompting/递归的提示
- 一种递归prompt的方式,通过prompt的方式将复杂问题分解为多个子问题,以多次prompting的方式去生成多个子问题的答案,最后再通过prompt的方式生成最后的答案。
- 根据解决子问题的方式可以分为串行跟并行两种,串行的方式每个子问题相互依赖,前面子问题的答案会加入到后续子问题的prompt中,生成后续子问题的答案,而并行的方式则各个子问题的答案生成是独立的,最后再将多个子问题的答案融合到一起。
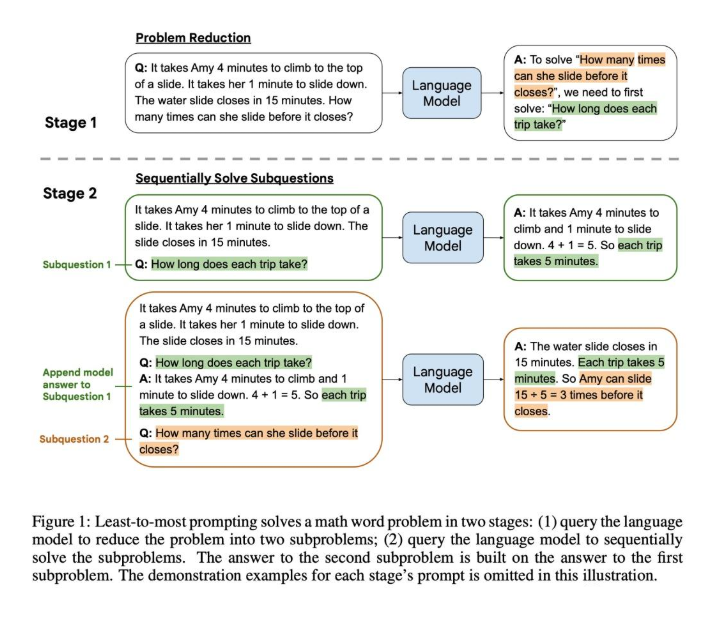
图3: 串行recursive prompting
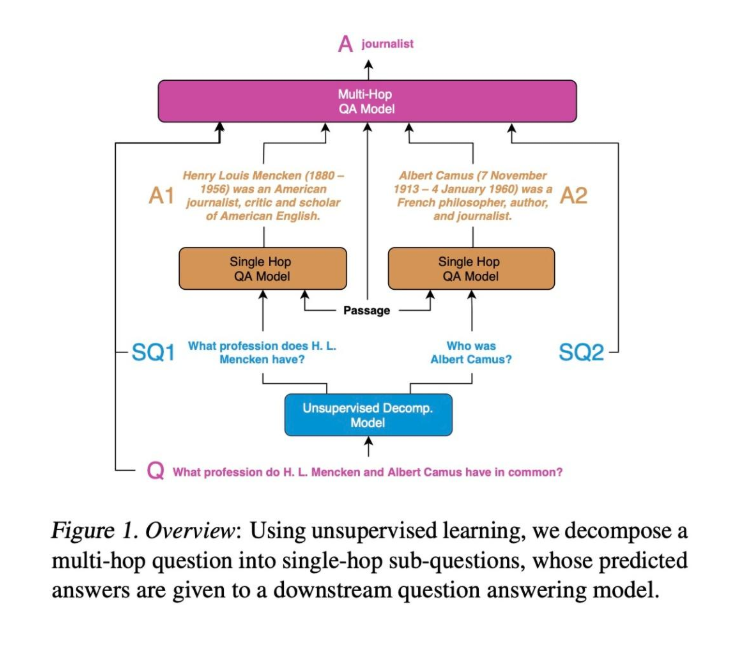
图4: 并行prompting
3.3 Explicitly teaching language models to reason/明确地教授语言模型来进行推理
- 直接教模型学习推理,主要有两种方式:
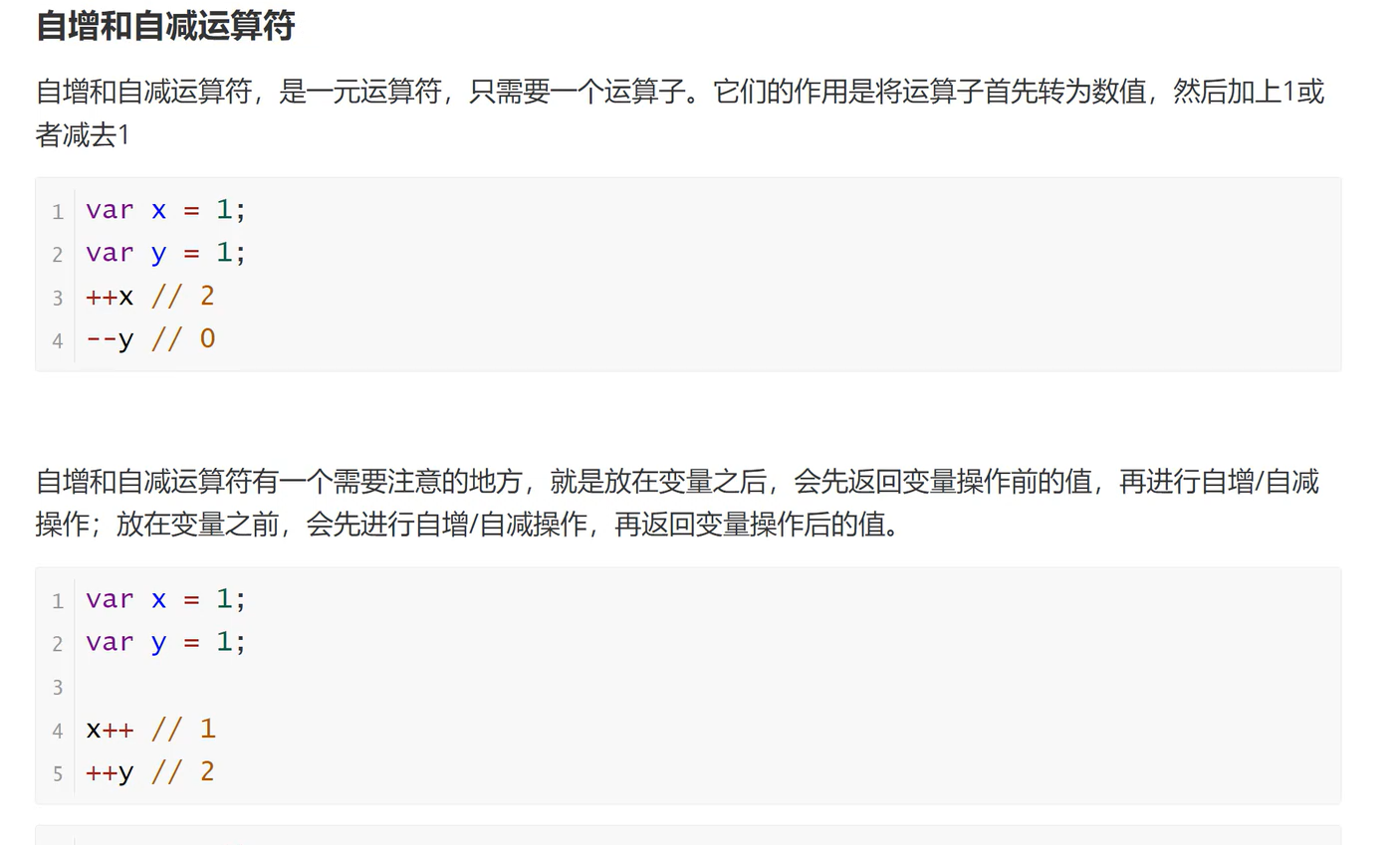
- 第一种方式: 利用working memory,目前有工作建议训练语言模型像人类一样样去使用working memory对于正确处理那些需要多步计算的复杂任务很有帮助。在多步推理过程中引入缓存器的概念,或者像Galactia利用特殊token来模拟中间过程的working memory。
- 另一种方式: 通过·fine tune·去提升模型推理能力。

图5: Galactia示例
4 Using Tools and Act/使用工具和行动
目前有不少工作研究如何让语言模型去获取模型权重本身不具备的知识
例如,调用外部模块
python解释器或者搜索引擎去进行准确的计算或者信息检索,也可以说是,语言模型执行了某个行动,当工具对外部世界有影响时。
a) 工具可以是语言模型本身也可以是其他神经网络,通过迭代调用或者融入其他模态信息。
b)信息检索系统,引入外部知识源,避免模型生成非事实跟过时信息。
c)符号模块跟代码解释器,处理一些需要大量或者复杂算术运算。
d)对虚拟世界跟真实世界采取行动,控制虚拟代理,或者控制现实机器人。
关于如果赋予语言模型推理跟使用工具的能力,可以通过监督学习跟强化学习的方式实现。
5 总结
- 让语言模型的权重存储所有信息是不现实的,在很多情况下还是需要外部工具的,重要的是如何让ALM学习决定是否使用外部工具。
- 或许ALM才是通向通用人工智能的一条路子。
Y 推荐文献
- Augmented Language Models: a Survey/增强语言模型:一篇调查 - arxiv.org
X 参考文献
- 增强语言模型(ALM)之综述篇 - Zhihu