背景
如果你想快速实现一个网站的前后端的部署,那么现成的站点模板是必须的,如果我们使用nginx做反向代理可以实现部署静态网站,如果我想相对请求或者页面有一些更新,那么就需要用到后端框架,这里我们使用fastapi去代理静态资源同时将模板的请求根据我们的需求进行动态的返回,可以在网站的模板上进行修改,这样是最快速的建站方式,用fastapi做后台管理
首先是网站的克隆
网站克隆有很多开源的工具,参考我之前的博客,我使用的是Httrack去克隆,这个软件可以完整的克隆站点的所有链接和资源,实现本地化的站点。
然后我们用fastapi去部署,将我们需要自定义的路由去做修改,静态资源部分直接拿文件资源就可以
区别于下载的网站模板,克隆的网站模板很乱,所以不会很严格的按照资源assest。static。img这样去分类,里面只有相对路径。
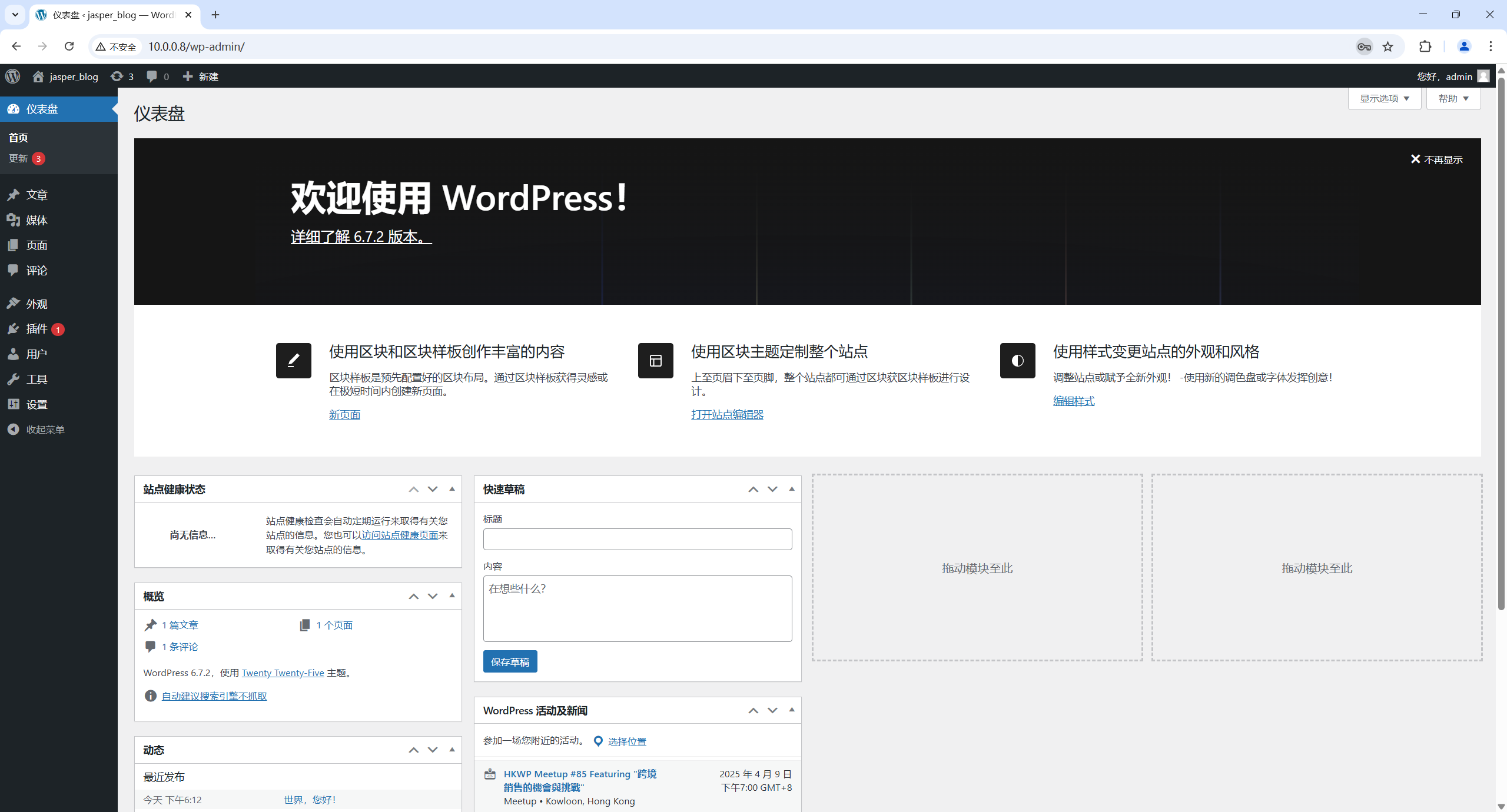
这是我clone的一整个站点的目录
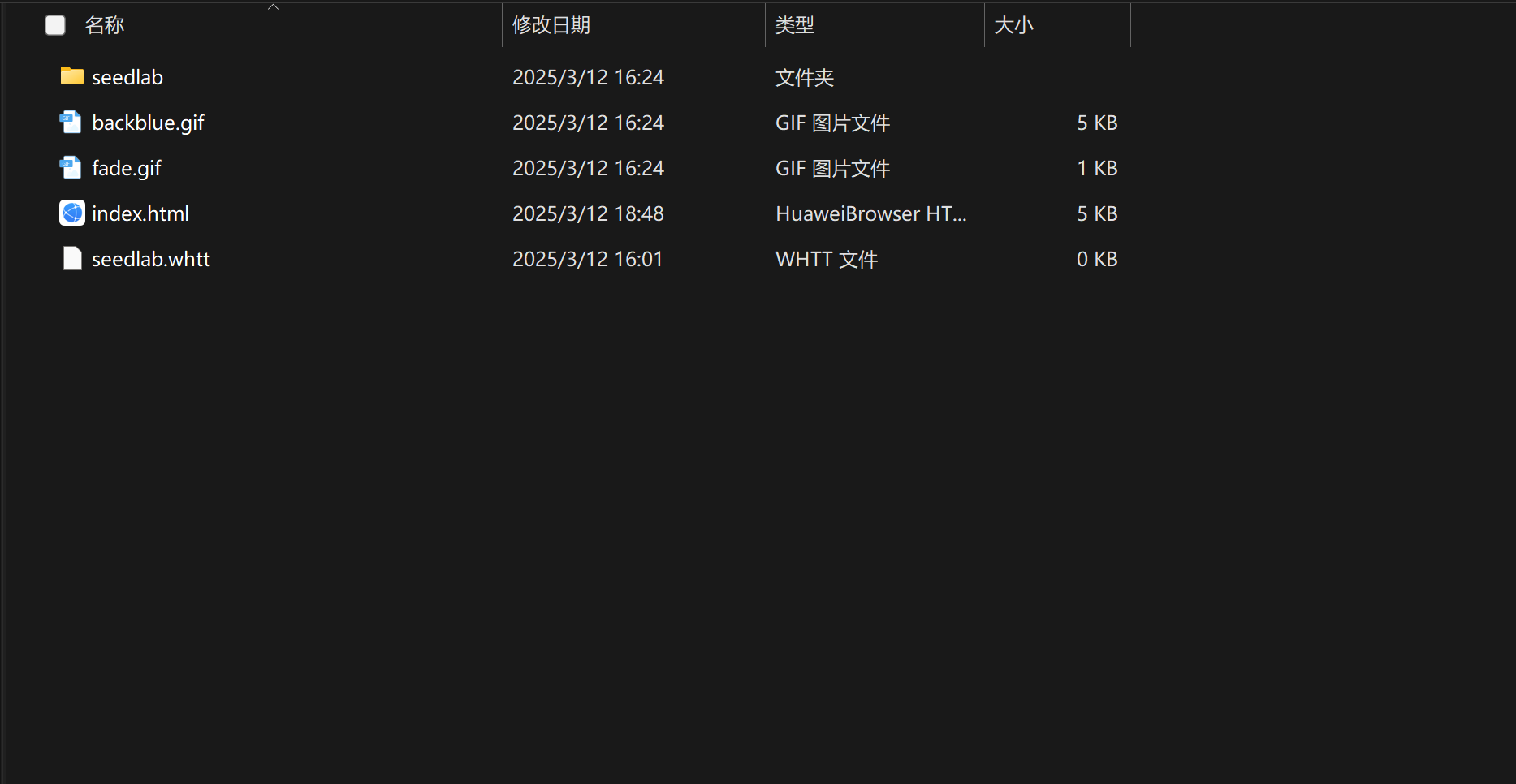
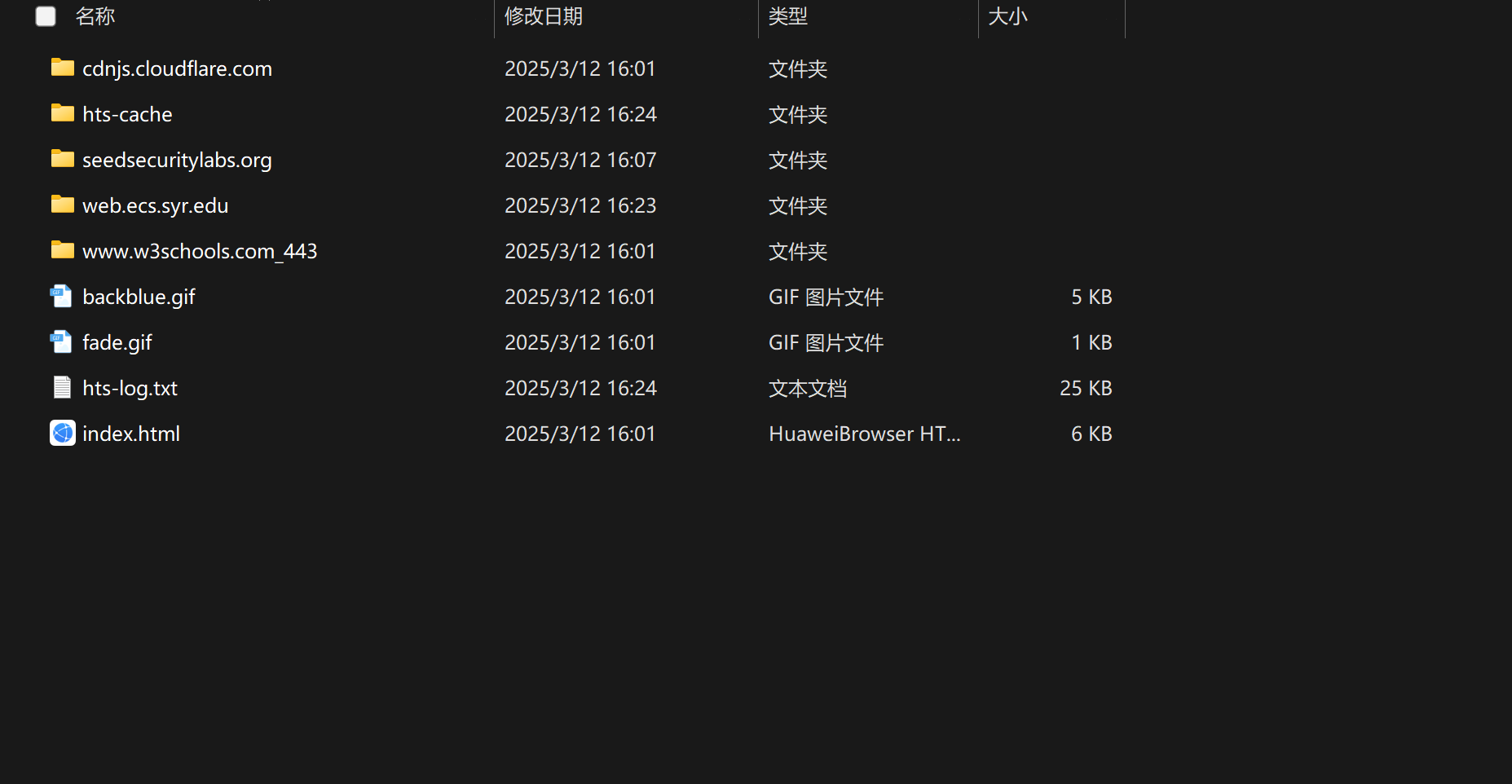
可以看到里面的资源是很乱的,但是在本地是完全可以离线运行的。
实现过程
fastapi文件结构
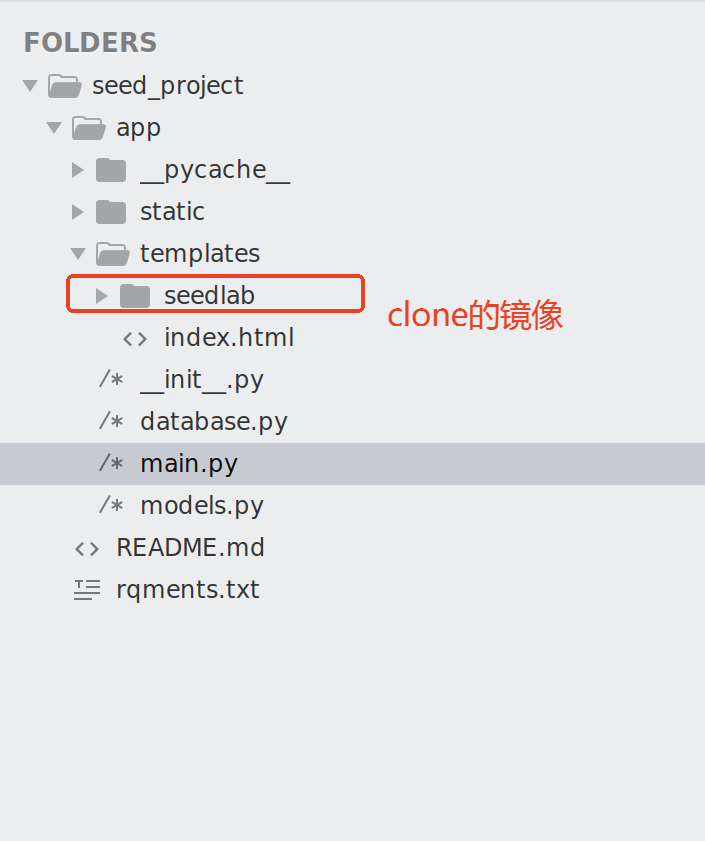
主要是main部分,这一块对静态资源进行分类,防止跳转404,写一个兜底的默认路由,主要是拿静态文件,别的数据库可以没有
核心代码
from fastapi.responses import HTMLResponse, RedirectResponse, FileResponse
from jinja2 import Environment, FileSystemLoader
from fastapi import FastAPI, Request, HTTPException
from typing import Union
import logging
import os
current_dir=os.path.dirname(os.path.abspath(__file__))
logging.basicConfig(level=logging.INFO)
app = FastAPI()# 设置 Jinja2 模板环境
templates = Environment(loader=FileSystemLoader("templates"))# 定义一个类型,用于匹配任何路径
AnyPath = Union[str, int]@app.get("/", response_class=HTMLResponse)
async def read_root(request: Request):return templates.get_template("index.html").render()@app.get("/labs", response_class=HTMLResponse)
async def read_labs(request: Request):logging.info(f"Request path: {request.url.path}")return templates.get_template("seedlab/index.html").render()@app.get("/books", response_class=HTMLResponse)
async def read_books(request: Request):return templates.get_template("books.html").render()@app.get("/lectures", response_class=HTMLResponse)
async def read_lectures(request: Request):return templates.get_template("lectures.html").render()@app.get("/emulator", response_class=HTMLResponse)
async def read_emulator(request: Request):return templates.get_template("emulator.html").render()@app.get("/contact", response_class=HTMLResponse)
async def read_contact(request: Request):return templates.get_template("contact.html").render()@app.get("/news", response_class=HTMLResponse)
async def read_news(request: Request):return templates.get_template("news.html").render()# 定义一个兜底路由来处理所有未明确定义的路径
@app.get("/{any_path:path}")
async def catch_all(any_path: str):print("path",any_path)# 获取文件扩展名_, ext = os.path.splitext(any_path)media_type = get_media_type(ext)if media_type=="text/html":try:# 尝试根据路径渲染模板template=templates.get_template(f"seedlab/{any_path}").render()return HTMLResponse(content=template)except Exception as e:# 如果模板不存在,返回 404 错误raise HTTPException(status_code=404, detail="Page not found")else:return FileResponse(os.path.join(current_dir,f"templates/seedlab/{any_path}"), media_type=media_type)# 如果文件和模板都不存在,返回 404 错误raise HTTPException(status_code=404, detail="Page not found")def get_media_type(ext: str):"""根据文件扩展名返回对应的媒体类型"""media_types = {'.html': 'text/html','.htm': 'text/html','.css': 'text/css','.js': 'application/javascript','.json': 'application/json','.jpg': 'image/jpeg','.jpeg': 'image/jpeg','.png': 'image/png','.gif': 'image/gif','.svg': 'image/svg+xml','.ico': 'image/x-icon','.ttf': 'font/ttf','.woff': 'font/woff','.woff2': 'font/woff2',}return media_types.get(ext, 'application/octet-stream')
一定要注意,FileResponse为绝对路径