一、模块的介绍
(1)python模块,是一个python文件,以一个.py文件,包含了python对象定义和pyhton语句
(2)python对象定义和python语句
(3)模块让你能够有逻辑地组织你的python代码段。
(4)把相关的代码分配到一个模块里能让你的代码更好用,更易懂
(5)模块能定义函数,类和变量,模块里也能包含可执行的代码
二、模块的导入
注意点:
(1)一个模块只要导入一次,不管你执行多少次import,一次就可以
(2)模块不调用时是置灰状态
(3)导入的方法:
a. import 模块名

b. from 包名.模块名 import * (*表示所有的函数)
c.导入具体函数:from 包名.模块名 import hs

三、模块的运用
(1)time模块


import time#1970年到现在经过的秒数
print(time.time()) #1651200498.799537
print(time.ctime()) #固定格式的当前时间
time.sleep(3)) # 休眠,也是强制等待
print(time.asctime()) #转化为asc码显示当前时间
print(time.strftime(“%H-%M-%S”)) 时分秒
print(time.strftime(“ %y-%m-%d”)) 年月日
print(time.strftime(“%H-%M-%S %y-%m-%d”)) #时间戳:按照格式输出内容: 时分秒,年月日
(2)random模块
生成随机浮点数,帧数,字符串,甚至帮助你随机选择列表中的一个元素,打乱一组数据等;
from random import *
print(random()) #生成0-1之间的浮点数,但是能取到0,不能取到1
print(randint(1,100)) #生成指定范围内整数,包括开始值和结束值
print(randrange(1,100,2)) # 生成指定范围内的奇数 ,包含开始值,不包含结束值
print(randrange(0,100,2)) #生成指定范围内的偶数,包含开始值,不包含结束值
f=[1,2,3,6,7,2]
print(sample(f,3)) #生成从一个固定集合中选n个数随机 ,3显示个数
print(choice(f)) #随机生成一个字符
shuffle(f) print(list(f))

(3)string模块
import string
print(string.digits) #0123456789
print(string.hexdigits) #0123456789abcdefABCDEF
print(string.ascii_letters) #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_lowercase) #abcdefghijklmnopqrstuvwxyz
print(string.ascii_uppercase) #ABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.digits+string.ascii_letters) #0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRST
#课堂练习
# 1、使用random模块随机生成手机号码、自己定义手机号码开头的前三位
# 2、用random模块随机生成6位数验证码
# def num():
# first="1"
# second=choice(["3","5","7","8","9"])
# third=str(randint(0,9))
# q=first+second+third
# s="".join(str(randint(0,9)) for _ in range(8))
# return q+s
# print("随机生成的手机号:", num())
#
# def yzm():
# # a=string.digits+string.ascii_letters
# # b="".join(choice(a) for _ in range(6))
# # return b
# # print("混合验证码:",yzm())(4)hashlib模块
在线加解密:
http://encode.chahuo.com/
1.base64
import base64
a=base64.b64encode(b"123456")
print(a)
b=base64.b64decode(b'MTIzNDU2')
print(b)
2.md5加密
(a)md5 是一种算法,可以将一个字符串或文件,md5后,就可以生成一个固定为128bit的串,这个串,基本上唯一;
(b)python2中有md5
(c)python3将MD5 归纳到hash 模块,译作:‘散列’,直译为‘哈希’。
(d)md5 可以把任意长度的输入,通过种hash算法,变换成固定长度的输出,该输出就是散列值,也称摘要值,,该算法就是哈希函数,也称摘要函数
(e)md5 是最常见的摘要算法,速度快,生成结果是固定16字节,通常用32位的16进制字符串表示。
(f)hash模块中包含MD5、sha1 ,sha256 ,sha512等
(g)摘要;hash.digest() 返回摘要,作为二进制数据字符串值; hash.hexdigeest 返回摘要,作为16进制数据字符串值
import hashlib
md5gx=hashlib.md5()
md5gx=hashlib.sha256()
md5gx.update(b"123456")
print(md5gx.hexdigest())
print(md5gx.digest())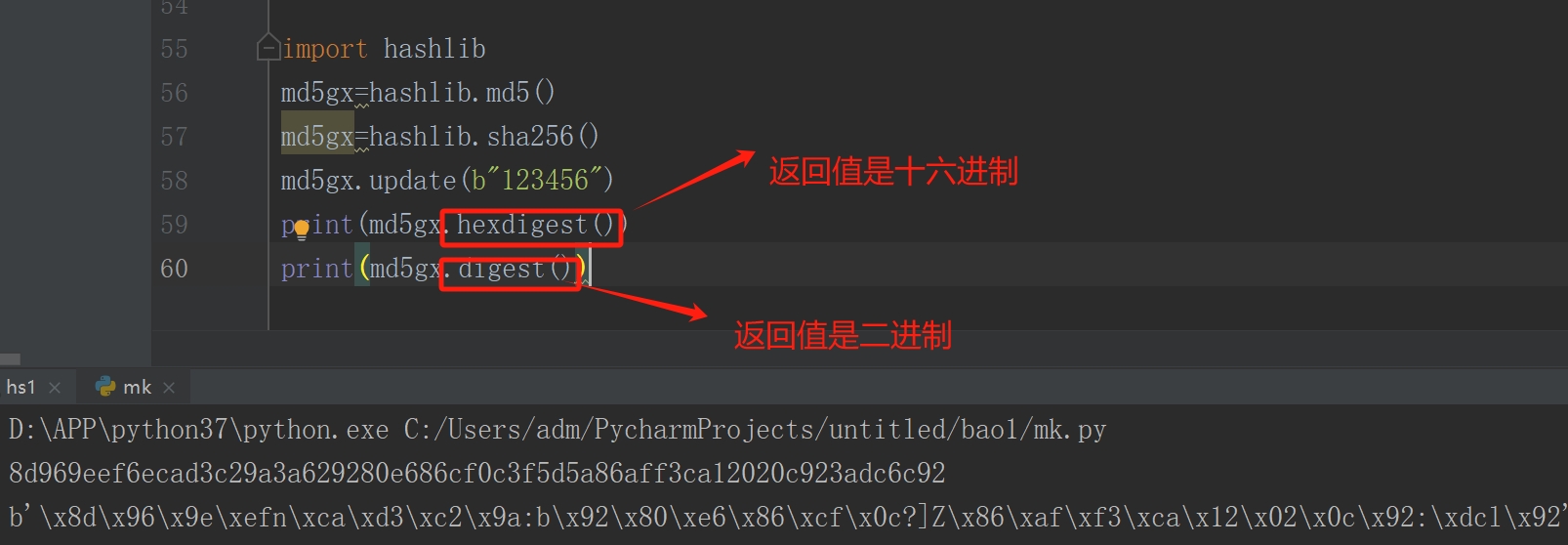
#练习
# 3、通过md5加密算法把随机生成的6应散验证码进行加密返回16进制的字符串
# def md5_jm(b):
# md5gx=hashlib.md5()
# md5gx.update(b.encode("utf-8"))
# return md5gx.hexdigest()
# print("加密后的验证码:",md5_jm(yzm()))(5)os模块
1.os模块提供了多数操作系统的功能接口函数。当os模块被导入后,它会自适 应于不同的操作系统平台,根据不同的平台进行相应的操作,在python编 程时,经常和文件、目录打交道,所以离不了os模块。
2.os模块中常见的方法:
os.getcwd()获取当前执行命令所在目录
import os
print(os.getcwd())
os.path.isfile()判断是否文件
url=r"C:/Users/adm/PycharmProjects/untitled/bao1/mk.py"
url2=r"E:\1"
print(os.path.isfile(url))
print(os.path.isfile(url2))
os.path.isdir() #判断是否是目录

os.path.exists() #判断文件或目录是否存在

os.listdir(dirname) #列出指定目录下的目录或文件

os.path.split(name) #分割文件名与目录

os.path.join(path,name) #连接目录与文件名或目录

os.mkdir(dir) #创建一个目录
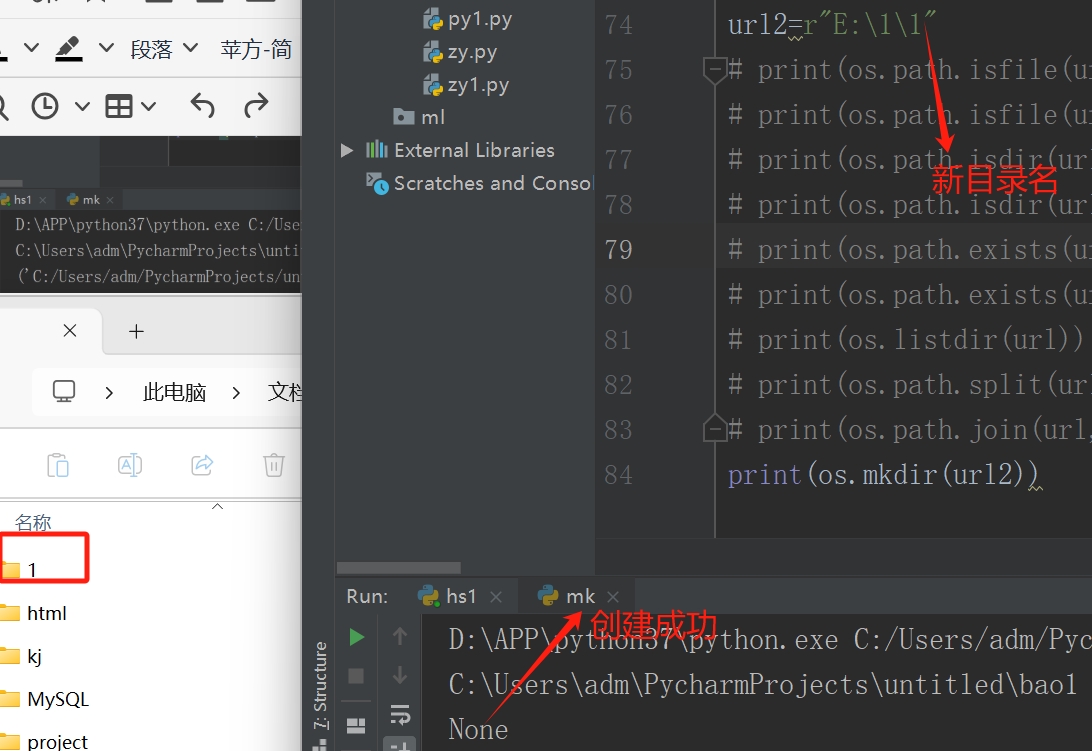
os.rename(old,new) #更改目录名称

os.remove() 删除文件

(6)re模块
(一)re正则匹配基本介绍
正则匹配:使用re模块实现
1、什么是正则表达式?
正则表达式是一种对字符和特殊字符操作的一种逻辑公式,从特定的字符中,用正则表达字符来过滤的逻辑。
2、正则表达式是一种文本模式;
3、正则表达式可以帮助我们检查字符是否与某种模式匹配
4、re模块使pyhton语言用有全部的表达式功能
5、re表达式作用?
(1)快速高效查找和分析字符比对自读,也叫模式匹配,比如:查找,比对,匹配,替换,插入,添加,删除等能力。
(2)实现一个编译查看,一般在处理文件时用的多
1、findall
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[]
import re
s="abcdefghijkaaaklde2"
f=re.findall("a",s)
print(f)
2、match
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败得到一个none值
注意:如果规则带了’+’,则匹配1次或者多次,无’+'只匹配一次 #显示结果是索引位:(0, 1)

3、compile(不考虑)
编译模式生成对象,找到全部相关匹配为止,找不到返回一个列表[]
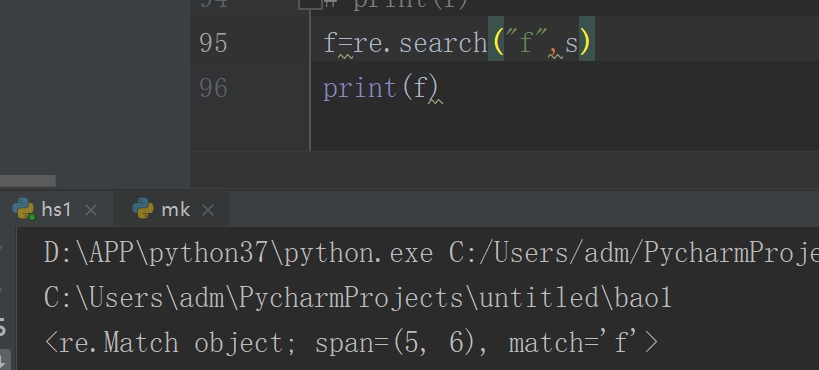
4、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则报错(返回值是一个none)
group 以str 形式返回对象中match元素
span 以tuple形式返回范围
(二)认识正则表达式中的特殊元素?
\d:数字0-9
s="abcfdef045ghijkfaaaklde2"
f=re.findall("\d",s)
print(f)\D:非数字
s="abcfdef045ghijkfaaaklde2"
f=re.findall("\D",s)
print(f)\s:空白字符

\n:换行符
s="abcfdef04 \n5ghijkfa\naaklde2"
f=re.findall("\n",s)
print(f)\w 匹配字母数字
s="abcfdef045ghijkfaaaklde2"
f=re.findall("\w",s)
print(f)\W 匹配非字母数字
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("\W",s)
print(f)^:表示的匹配字符以什么开头
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("^a",s)
print(f)$:表示的匹配字符以什么结尾
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("2$",s)
print(f)*:匹配前面的字符0次或n次 eg:ab (* 能匹配a 匹配ab 匹配abb )
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("a*",s)
print(f)+:匹配+前面的字符1次或n次
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("a+",s)
print(f)?:匹配?前面的字符0次或1次
s="abcfdef045ghij#$^|||//kfaaaklde2"
f=re.findall("a?",s)
print(f){m}:匹配前一个字符m次
s="abcfdeaaaaaaaf045ghij#$^|||//kfaaaklde2"
f=re.findall("a{2}",s)
print(f){m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
s="abcfdeaaaaaaaf045ghij#$^|||//kfaaaklde2"
f=re.findall("a{3,5}",s)
print(f)











