昨晚和几位测试同学交流AI在日常工作中落地的话题,听了好几种不同的落地案例,以及落地过程遇到的问题和当前的进度。这些案例给了我不少启发,今天就来聊聊我对于AI在测试工作场景中落地的思考。
在上述案例中,有同学说他们在推AI生成测试用例,但进展很慢,过程中遇到了很多问题。也有大厂同学说,调研之后直接放弃了利用AI生成测试用例的想法。当然也有同学想尝试在UI自动化测试场景中落地AI,但目前停留在调研阶段。
看到这里,是不是觉得和网上看到的各种资料所说的不一样?老实说,DeepSeek刚出来的时候,我也想过借助它的能力直接在工作中落地应用,但真正深入了解AI大模型的技术原理和特性后,我立马放弃了之前的天真想法。
如果AI真的具备如网上各种自媒体所描述的那种能力,那确实能很快提升个人和团队的工作效率。但不幸的是,当前阶段的各种AI大模型和工具,并不具备开箱即用深度使用的能力。
换个角度来说,不是AI不具备这种能力,而是要达成如大家所想的效果,需要满足一定的前置条件。但这些前置条件是什么,该如何达成,目前并没有很详细的介绍和可参考的落地路径。
很可怕的一点在于,目前很多公司就是很迷信AI的能力,畅想AI能降本增效,大幅增加公司的效率,甚至带来新的营收。
只能说AI大模型出圈的这三年不到的时间,群体认知的泡沫还没挤破。
从原理来说,大模型会根据用户输入不断预测下一个Token,且每个已经生成的Token都会影响下一个Token的生成。
从本质来说,大模型就是一个概率预测机器。同样的Prompt(提示词)会产生不同的答案,这就是所谓的信息幻觉问题。
什么是信息幻觉?简单来说就是:同样的提示词,重复多次后大模型的输出结果是不一样的,即不具备幂等性。甚至为了迎合用户的诉求,大模型甚至会虚构一些不存在的数据给你。
要缓解信息幻觉,当前最通用的方法就是RAG,即结合向量数据库中与用户问题相关的信息,以及Prompt一起投喂给大模型,再生成结果。
这也是为什么很多公司要训练自己的私有大模型的原因。
以目前阶段AI大模型的能力来说,它更擅长解决的是标准的、富有逻辑和清晰边界的问题,而实际的工作场景大多都是不确定性的因素。
在IT互联网行业研发工作为例,我们面临的实际工作场景是什么?一句话需求,技术设计做的很烂,数据结构勉强能看,这种情况下,你又怎么能指望AI帮你解决呢?
AI解决不了人的不专业和沟通成本高昂的问题,这是人的问题,不是技术的问题。
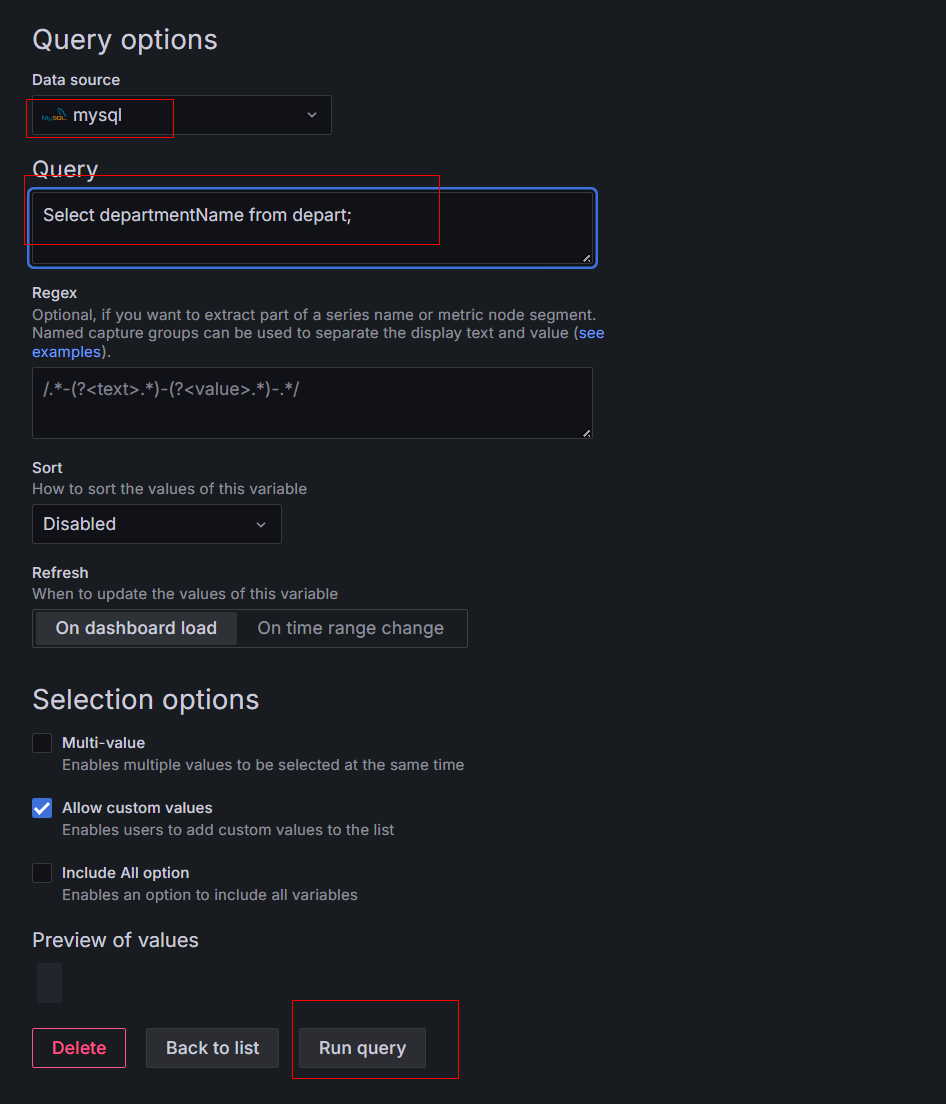
回到本文开篇的问题:AI能生成可用的测试用例吗?答案是可以。
但这个答案的前提在于:标准化的流程、清晰详细的需求文档描述、良好的技术和数据结构设计,只有满足这几点前置要求,才能借助AI的能力生成基本可用的测试用例。
这里的基本可用并不是说可以直接拿来无缝插入日常研发测试环节,而是技术人员需要根据自己的经验和使用场景进行微调之后,才能真正用起来。
当然,以当下的测试工作场景来说,API自动化和单元自动化,AI倒是有很大的可供想象的落地场景。定义好数据结构,设计好API,然后利用AI帮你生成测试数据,或者应用层的自动化测试代码,落地难度并不高。
但这样做可能会出现新的问题,即无法满足领导的大脑自嗨,毕竟领导要的是创新和降本增效。对于这个问题,还有一个更适合向上管理PPT汇报的方式,那就是智能体和工作流。
将日常可以自动化执行的部分,切换为工作流(和自动化本质没区别),替代人工执行。比如代码自动提交、自动化部署流水线等结构化可重复的场景。
将线上监控、容灾自愈、配置热更新等非结构化的复杂场景,进行抽象设计然后整合为Agent。
二者结合使用,智能体可以增强工作流的灵活性(动态调整步骤),工作流可以协调多个智能体完成更复杂的问题。
如此一来,既有落地案例,又有技术创新和汇报材料,何乐而不为。
AI是工具,是锤子,问题是钉子。不能拿着锤子四处敲钉子,而是找到钉子该钉住的位置,然后再敲锤子。