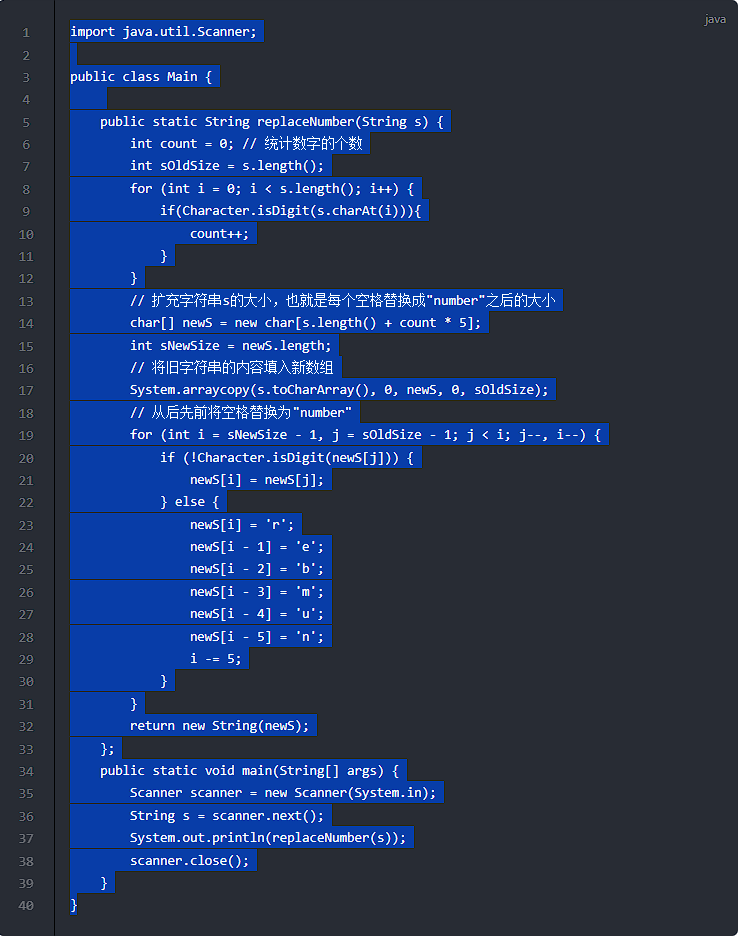
贝尔曼最优方程:
\[\begin{align*}
V^*(s) &= \max_{a\in\mathcal{A}}\left\{r(s,a) + \gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)V^*(s')\right\}\\
Q^*(s,a) &= r(s,a) + \gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)\max_{a'\in\mathcal{A}}Q^*(s',a')
\end{align*}
\]
对公式的解释
-
符号说明:
- \(V^*(s)\):最优状态价值函数,表示在所有可能的策略下,从状态 \(s\) 开始所能获得的期望累计折扣回报的最大值。
- \(Q^*(s,a)\):最优动作价值函数,表示在所有可能的策略下,从状态 \(s\) 执行动作 \(a\) 后,所能获得的期望累计折扣回报的最大值。
- \(\mathcal{A}\):动作空间,即所有可能动作的集合。
- \(\mathcal{S}\):状态空间,即所有可能状态的集合。
- \(r(s,a)\):在状态 \(s\) 执行动作 \(a\) 后所获得的即时奖励。
- \(\gamma\):折扣因子,取值范围是 \([0, 1]\),用于衡量未来奖励的现值,\(\gamma\) 越接近 0,表明智能体越注重即时奖励;\(\gamma\) 越接近 1,则越看重未来的奖励。
- \(p(s'|s,a)\):在状态 \(s\) 执行动作 \(a\) 后转移到状态 \(s'\) 的概率。
-
公式含义:
- 对于 \(V^*(s)\) 的公式:要计算状态 \(s\) 的最优价值,需要遍历在状态 \(s\) 下所有可能的动作 \(a\) 。对于每个动作 \(a\) ,考虑执行该动作后获得的即时奖励 \(r(s,a)\) ,以及后续所有可能转移到的状态 \(s'\) 的最优价值 \(V^*(s')\) (乘以状态转移概率 \(p(s'|s,a)\) 和折扣因子 \(\gamma\) ) ,然后取所有这些计算结果中的最大值,作为状态 \(s\) 的最优价值。
- 对于 \(Q^*(s,a)\) 的公式:计算从状态 \(s\) 执行动作 \(a\) 的最优动作价值时,先考虑执行动作 \(a\) 获得的即时奖励 \(r(s,a)\) 。接着,考虑转移到后续所有可能状态 \(s'\) 的情况,对于每个后续状态 \(s'\) ,在其所有可能的动作 \(a'\) 中选择能使 \(Q^*(s',a')\) 最大的动作(即 \(\max_{a'\in\mathcal{A}}Q^*(s',a')\) ) ,乘以状态转移概率 \(p(s'|s,a)\) 和折扣因子 \(\gamma\) 并求和,最后与即时奖励相加,得到 \(Q^*(s,a)\) 。
这两个公式是强化学习中用于求解最优策略的核心方程,它们通过迭代的方式不断更新最优价值函数,帮助智能体找到能最大化长期回报的行为策略。



![[算法学习记录] [更新中]最短路](https://img2024.cnblogs.com/blog/3485182/202503/3485182-20250318215633327-1698131957.jpg)