本文是Ollama系列教程的第4篇,在前面的3篇内容中,我们分享了如何在本地安装ollama、运行deepseek等大模型、以及如何在chatbox和cherryStudio中使用本地ollama中的大模型,我们创建了私有的AI对话框和智能体。
Ollama系列教程目录(持续更新中):
- 轻松3步本地部署deepseek
- 快速上手搭建私有的AI对话框和智能体—chatbox版
- 快速上手搭建私有的AI对话框和智能体—cherryStudio
在本篇内容中,我们将分享如何创建和使用知识库,让AI更懂你。
为什么需要AI知识库
知乎版
AI知识库,作为人工智能技术与传统知识库概念的融合,是指利用人工智能算法和技术构建、管理和维护的信息存储系统。它不仅包含了大量的结构化、半结构化和非结构化数据,还具备智能检索、推理分析、自我学习和优化等高级功能。AI知识库通过模拟人类的认知过程,实现了对知识的有效组织和高效利用,为各种应用场景提供了强大的支持。
人话版
知识库是我们的私有数据(你的财务状态、体检报告等),为了让AI生成更准确、更符合我们需求的内容,需要在提问时将内容告诉AI
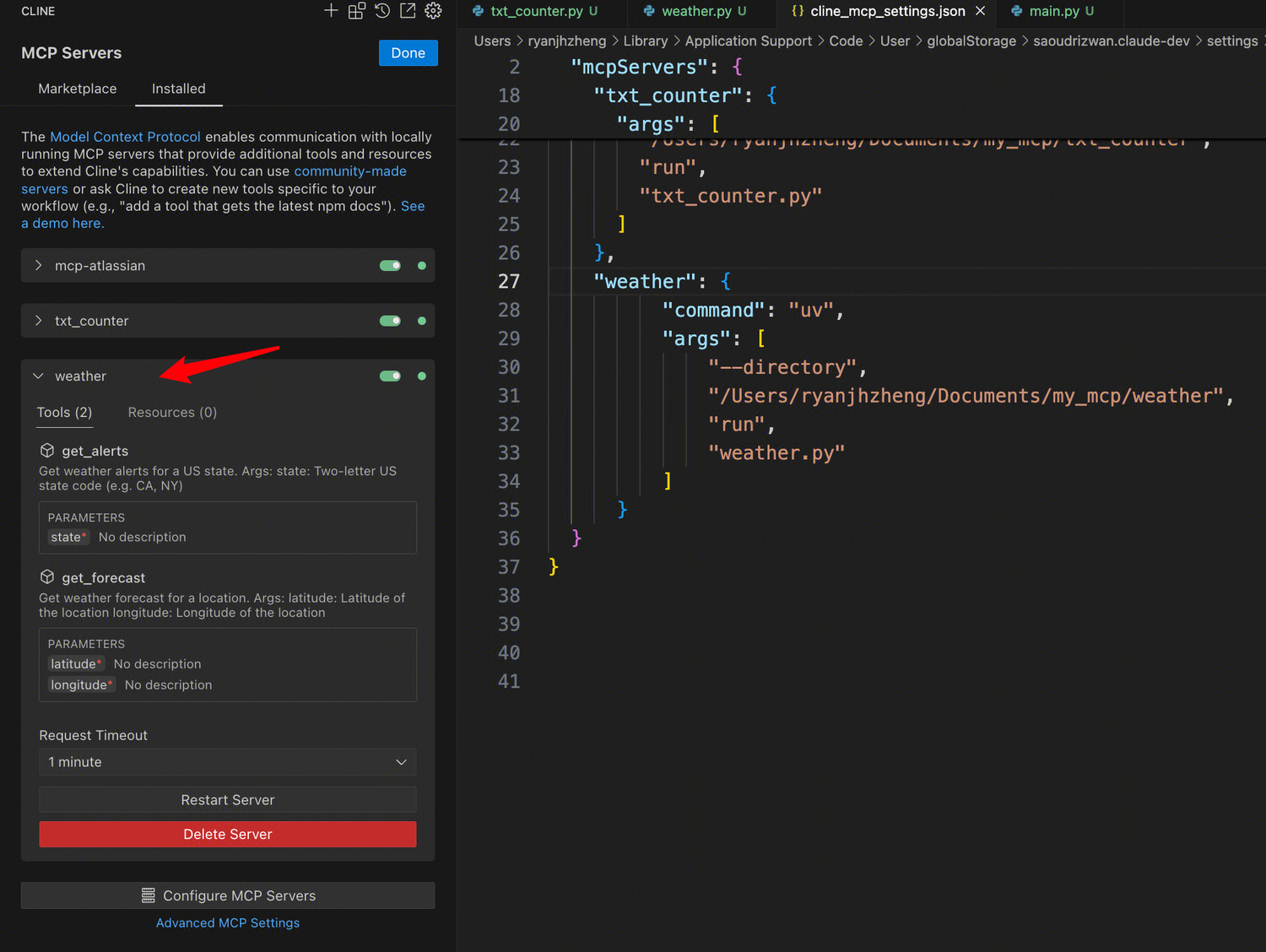
知识库是如何工作的?
知识库工作流程图(来源于CherryStudio Doc):
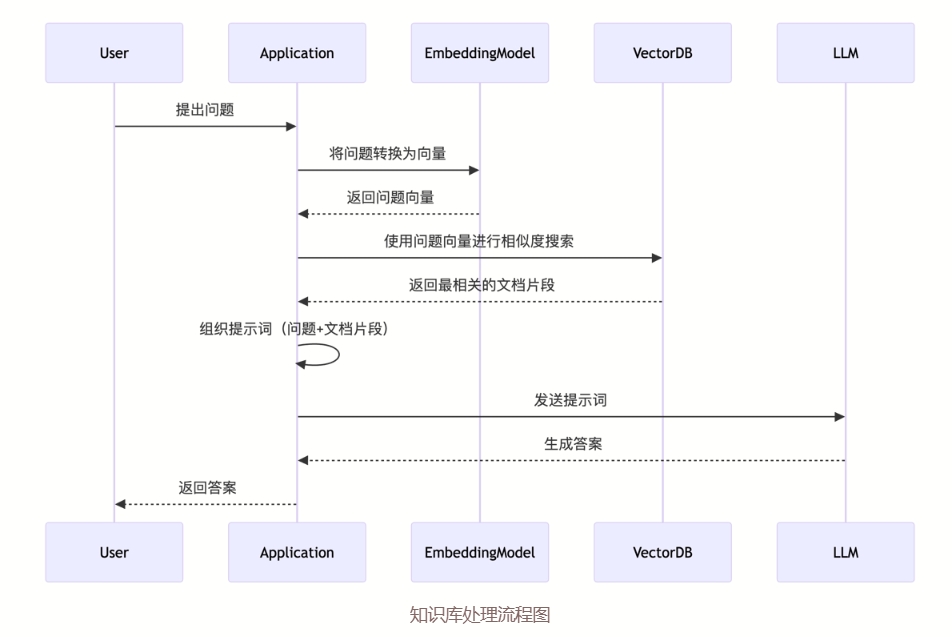
在上面的流程图里,我们可以看到知识库工作的步骤:
- 用户提问时,AI工具先查询知识库里已有的内容
- 将查询到的内容和用户的提问发送给大模型
- 大模型根据提供的内容生成答案
使用知识库增强检索来生成答案的技术有一个专门的名词RAG,这里面涉及到几个概念,如果你感兴趣可以继续深挖(由于本篇内容针对的是入门教程,不做太多概念性的讲解,后面有机会了再专门介绍)
构建私有知识库
接下来我们通过cherryStudio来构建私有的知识库。
首先打开cherryStudio,点击左侧的知识库:
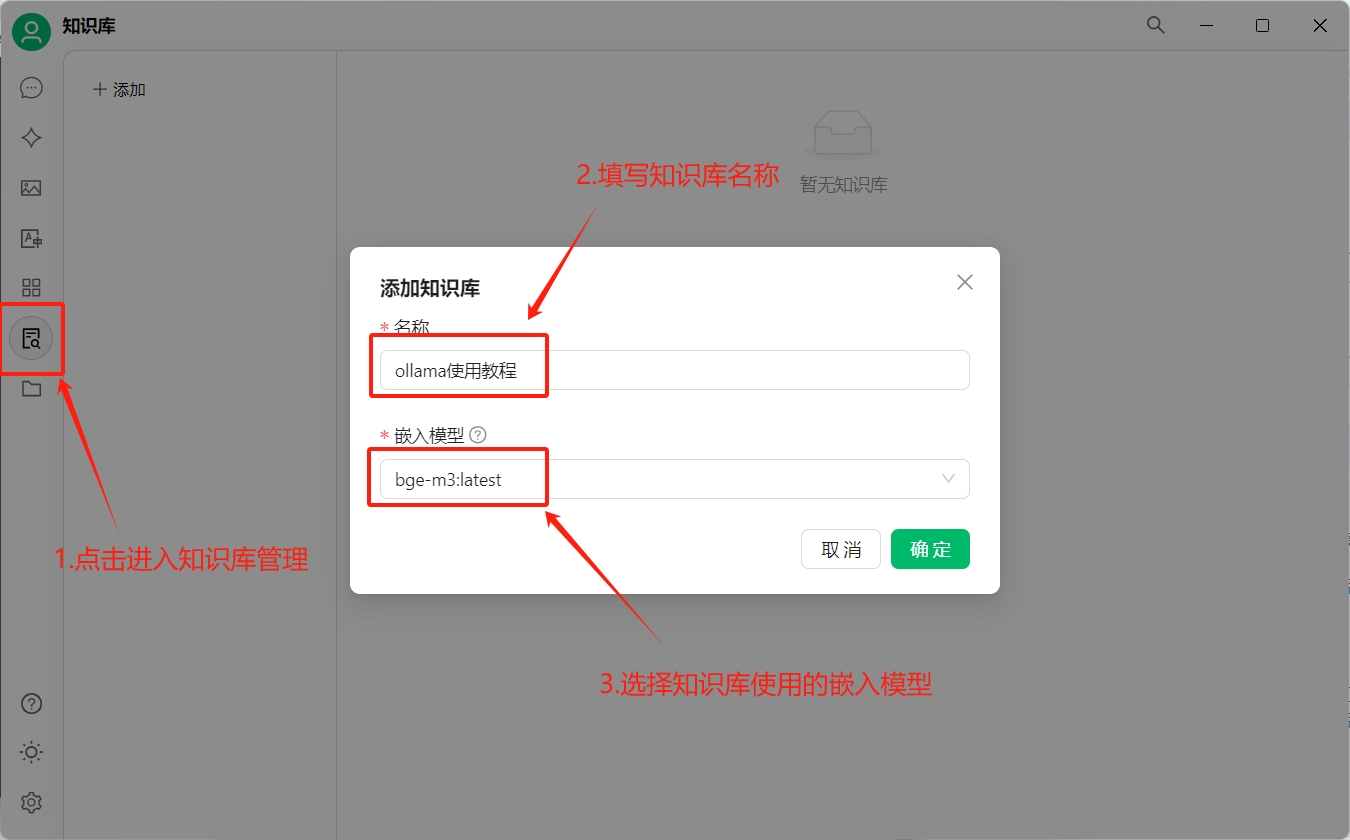
获取嵌入模型
在构建知识库的过程中,需要选择要使用的嵌入模型。嵌入模型的主要功能是将用户的文本、图片等内容生成向量数据,用作向量搜索的。
在ollama中有很多嵌入模型供我们选择使用。我这里使用的是bge-m3,你可以通过下面的指令获取:
ollama pull bge-m3
注意:嵌入模型保存后不允许修改
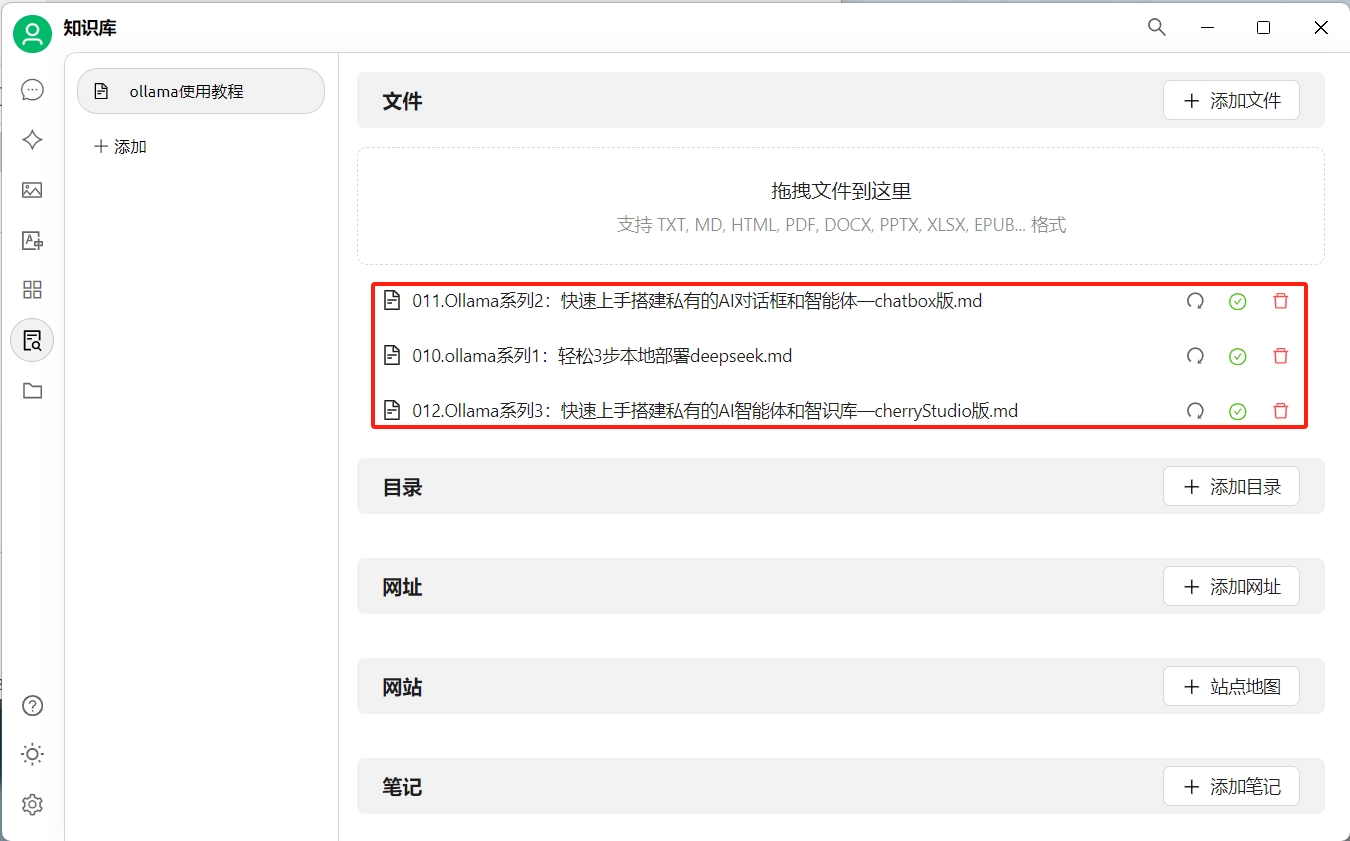
添加知识内容
为了进行演示,我们将本系列教程的前三篇放入知识库中:
然后创建一个新的对话,在对话中选择创建的知识库:
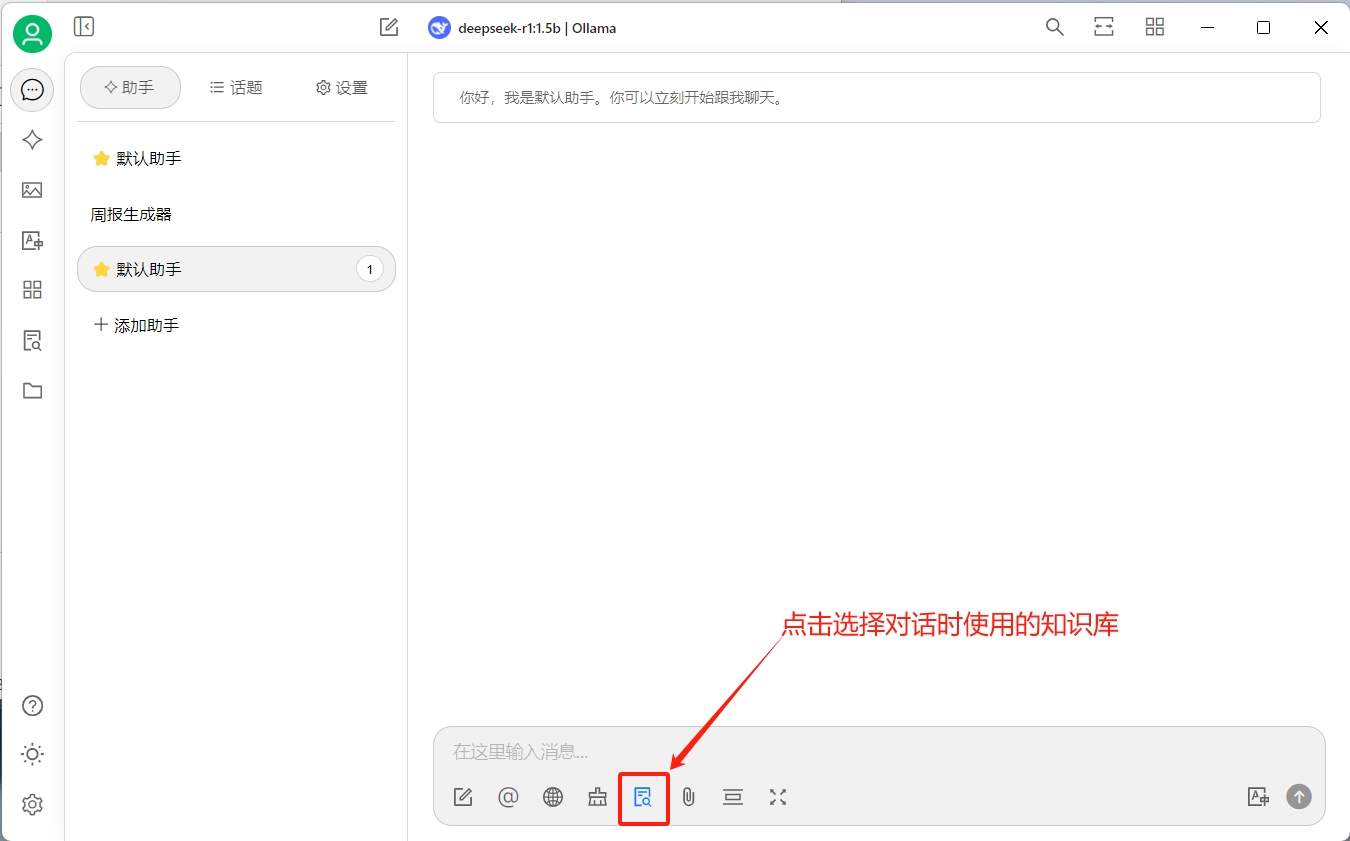
验证一下效果(效果并不理想):
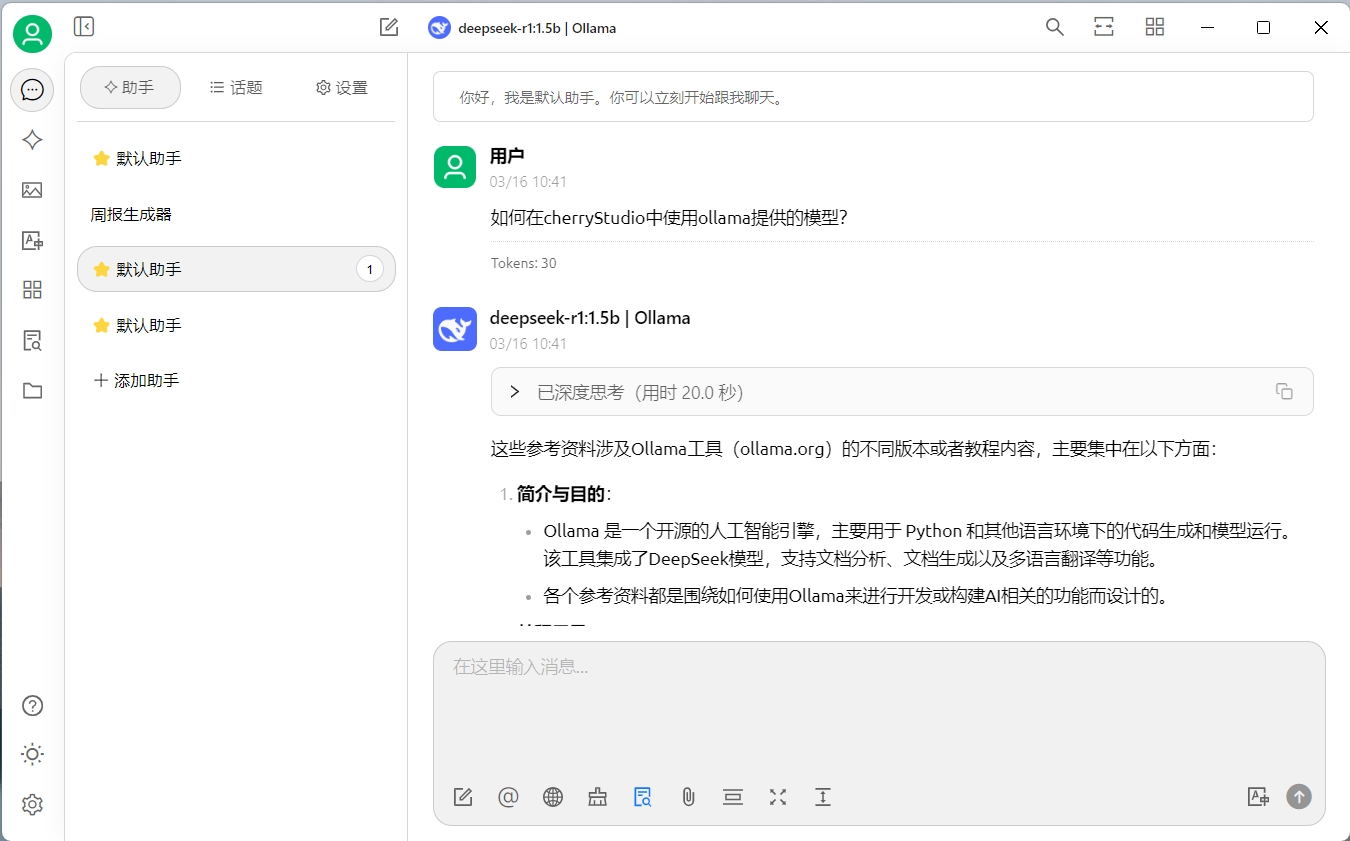
话外音
感觉deepseek又开始一本正经的胡说八道了,这可能和我们选择的模型有关,我们当前使用的是1.5b的模型,如果你的硬件允许,可以尝试下载更大的模型进行测试
我换了一个deepseek-r1:7b的模型重新验证了一下,效果比上面的要好一些:
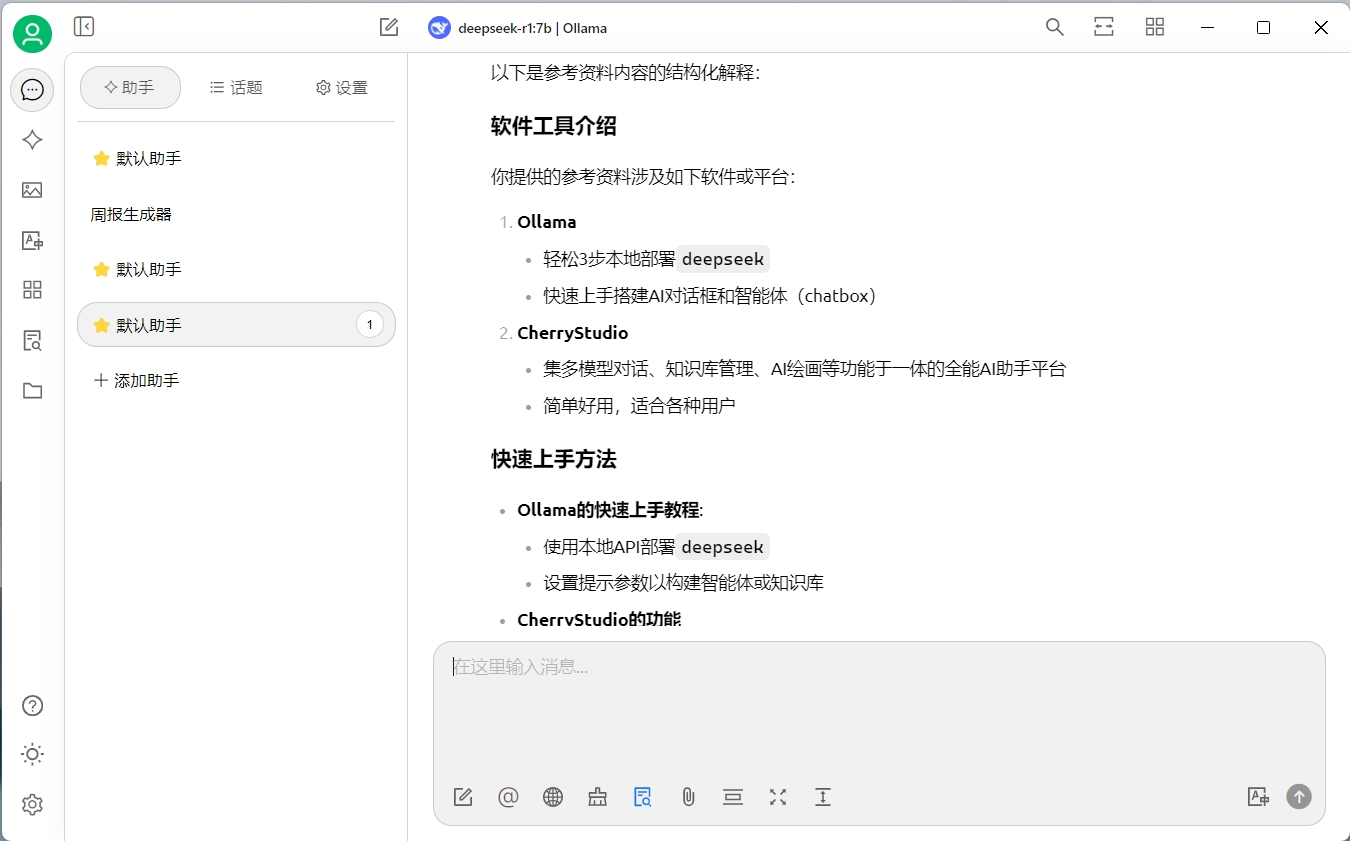
影响知识库的因素
通过上面的例子我们可以看到,当切换了模型之后,生成内容的准确性有所提高。这说明我们需要尝试不同的模型,来达到自己满意的效果。
通常来说影响知识库输出质量的因素有:
- 文档的质量
- 嵌入模型的能力
- 向量数据库的检索
- 文档相关性排序能力
- 系统Prompt质量
- 大模型生成能力
当我们在进行实践时,切记一定要先进行验证,验证满意后再进行大规模的实施。
总结
本文分享了在cherryStudio中使用本地ollama提供的模型来构建私有知识库的功能,在文章的末尾我们讨论了影响知识库输出质量的一些因素,在接下来的章节中,我们将讨论如何优化知识库输出质量,让AI给出我们更好的答案。
如果你对这些内容感兴趣,关注[拓荒者IT]公众号,获取最新的文章内容。
👉 持续分享AI工具,AI应用场景,AI学习资源 ❤️

📢 创作不易,如果这篇文章对你有帮助,欢迎❤️关注、👍点赞支持,并️转发给那些需要的朋友!关注 [拓荒者IT] 获取更多精彩内容!



![[算法学习记录] [更新中]最短路](https://img2024.cnblogs.com/blog/3485182/202503/3485182-20250318215633327-1698131957.jpg)