(配图:Photo by BoliviaInteligente on Unsplash)
前言:2025 年 3 月 18 日,在美国加州圣何塞举行的 GTC 2025 大会上,NVIDIA CEO 黄仁勋发表了长达两小时的主题演讲,详细介绍了 NVIDIA 的未来路线图。 这场被誉为“AI 超级碗”的盛会,吸引了全球开发者、创新者和行业领导者的广泛关注。 黄仁勋在演讲中宣布了多项重大创新,包括新一代 AI 芯片 Blackwell Ultra 的发布、面向机器人的 GR00T N1 AI 模型的推出,以及与通用汽车在自动驾驶领域的合作。 他还强调,未来 AI 计算需求将呈指数级增长,预计到 2028 年,数据中心资本支出将超过 1 万亿美元。 这次演讲不仅展示了 NVIDIA 在 AI 硬件、软件、机器人和自动驾驶等领域的最新进展,也为行业未来的发展指明了方向。
如果你对 AI 或投资有一点点兴趣,你应该读一下这篇文章。
NVIDIA 的 CEO 黄仁勋昨天在 GTC 大会上做了一场两小时的主题演讲,介绍了 NVIDIA 的未来路线图。这场大会被称为“AI 界的伍德斯托克”。短短两小时,涵盖了三年份的信息,不过大多数人听不懂他用了哪些术语和行业黑话。
那么,真正重要的核心信息是什么?哪些内容会决定这个行业未来的发展?
如果 NVIDIA 打个喷嚏,AI 产业就会感冒。这里是你需要了解的 AI 硬件、软件、机器人和投资的未来。
重大决定已经做出
这次的发布会内容可以分成四个主要的营收板块:
- AI 数据中心硬件业务
- HPC(高性能计算)数据中心业务
- 消费级硬件业务
- 其他收入来源,主要是机器人和自动驾驶
我们从最后一个开始说起。
机器人和自动驾驶
NVIDIA 早就开始高调宣传 AI 机器人,或者说他们叫的“物理 AI”。他们的布局可以分成三部分:
- 他们想要训练控制机器人的 AI 模型
- 他们想要打造机器人训练的虚拟环境
- 他们想要提供训练数据
换句话说,他们要插手 AI 机器人市场的所有环节。
针对第一点,他们发布了 Gr00t N1,一个机器人基础模型。它采用双模型架构,作为机器人运行的大脑。
这个架构和 FigureAI 最近提出的思路类似(我之前在 Medium 上写过相关内容)。本质上,它是一个视觉-语言-动作 AI 模型,能够接收一系列图像帧和机器人状态(机器人在环境中的位置),然后决定下一步动作。
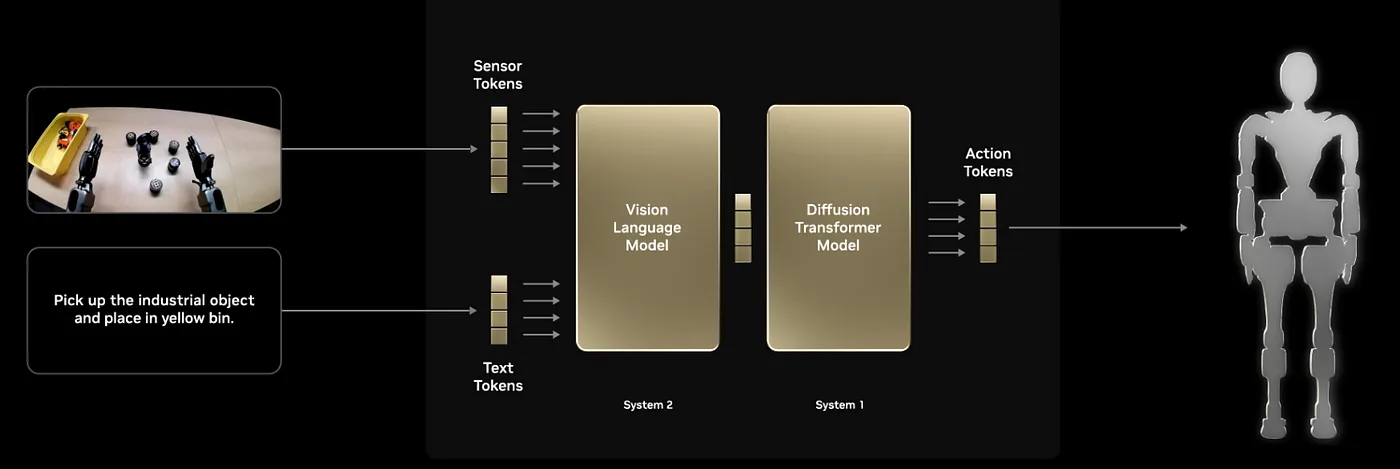
(配图:Source: NVIDIA)
此外,他们计划用 Omniverse 和 Isaac Gym 来提供训练环境。正如我之前解释的,机器人不在现实世界中训练,原因有两个:
- 成本太高
- 训练速度不能加快(你不能让多个机器人同时在物理世界训练)
所以,我们用模拟环境来尽可能接近现实世界,在虚拟环境里训练 AI 模型,然后再一次性部署到真实机器人身上(完全不需要物理训练)。
第三个亮点是他们提出了一个非常有趣的想法:用 AI 生成新的合成数据(由其他 AI 生成的数据)来训练机器人。通过 Cosmos 世界模型,这个 AI 可以生成机器人没有经历过的替代场景(也是在模拟环境里),让机器人接触更多的情况,学到更多东西。
值得注意的是,Cosmos 世界模型和这种用合成数据继续训练 AI 的方法,也是自动驾驶技术训练的关键。因此,NVIDIA 也借此宣布了与通用汽车的合作,接手 GM 刚刚放弃的 Cruise 机器人出租车业务,为他们的自动驾驶车队提供技术支持。
核心结论 #1: 机器人市场可能会是 AI 最大的市场,NVIDIA 正在巩固自己的领先地位(先是在模拟环境,现在是 AI 模型和合成数据)。
但目前,这个业务板块的收入基本为零,所以对投资者来说,它仍然是一个高风险/高回报的赌注。
NVIDIA 笔记本和工作站
虽然 NVIDIA 现在大力押注分布式计算(后面会详细说),但他们也在积极进军消费级硬件市场。
他们发布了两款新设备:
- NVIDIA DGX 工作站,一台台式计算机,拥有惊人的 789GB 内存(其中 288GB 是 HBM 内存,市场上最快的带宽),FP4 计算性能达到 20 Petaflops(每秒 2 万万亿次计算),内存带宽 8TB/s。
- NVIDIA DGX Spark,一个可以连接到笔记本的便携计算设备,计算性能达到 1000 TOPS,拥有 128GB 统一内存,但带宽只有 276GB/s。
简单来说,这些都是为 AI 任务设计的个人电脑,算是 NVIDIA 对苹果上周发布的 Mac Studio M4 Max 和 M3 Ultra 电脑的回应。
它们有什么共同点?
计算能力强、内存大、内存传输速度快,这些特性对 AI 任务来说很重要(说实话,除了 AI 任务之外,普通用户用不上)。
核心结论 #2: NVIDIA 又开辟了一个新收入板块。随着小型基础模型的进步,越来越多 AI 从业者会选择本地运行开源模型,这个市场可能会有很大增长空间。
不过目前来看,除了苹果,可能也就 NVIDIA 能在这个市场里分一杯羹了(至于市场有多大,还是个未知数,因为这些设备太贵了)。
HPC 数据中心业务
这里就开始有点让人失望了。NVIDIA 毫不犹豫地把 HPC(高性能计算)市场拱手让给 AMD。接下来的 GPU 产品会减少 FP64 ALU 单元的比例,而是更多地转向低精度计算。
简单来说,HPC 和 AI 计算的核心区别是 精度:
• AI 计算更倾向于 低精度(每个参数占用的内存更少)
• HPC 计算(比如复杂的物理模拟)需要 高精度,比如 FP64(每个参数占 8 字节内存)
但问题是,芯片的面积有限,NVIDIA 选择把 FP64 计算单元减少,把更多面积留给 AI 计算(FP16/FP8/INT4)。
这一策略实际上是在告诉 AMD:“HPC 市场归你了,我们去赚 AI 的钱。”
AMD 现在需要做出选择:是继续在 AI 领域跟 NVIDIA 硬碰硬,还是专注于 HPC 领域,放弃 AI 市场的竞争力?
核心结论 #3: NVIDIA 相当于和 HPC 说了声“我们不合适”,然后头也不回地奔向 AI,因为 AI 现在是最热门的领域。
AI 数据中心业务
这里才是最关键的部分,NVIDIA 的策略透露出了两点信息:
- 摩尔定律不再适用了
- 我们正在进入一个“推理为主”的世界
科技正逼近自然极限
虽然听起来有点夸张,但 NVIDIA 确实正撞上“自然的墙”。
就像前面说的,我们正在逼近 功率密度的极限,也就是说,每单位面积的计算能力已经接近极限。
由于芯片制造工艺的限制,NVIDIA 现在只能通过 芯粒(chiplet) 架构来提升算力,把多个计算单元封装在一起。
然而,Blackwell GPU 已经把 两个最大尺寸的芯片封装到一起 了,也就是说,NVIDIA 已经几乎摸到这个架构的天花板。
这时候,NVIDIA 其实只有两个方向可以提升计算能力: - 缩小晶体管尺寸 —— 计算是靠逻辑电路和晶体管完成的,晶体管越小,计算单元就能塞进越多。
- 增加芯片封装数量 —— 虽然单个芯片的大小受限,但理论上可以一直往一起拼芯片(但这也是工程界最难的挑战之一)。
理解了这一点,我们再来看 NVIDIA 的 AI 计算路线图。
当计算不再是主角
NVIDIA 现在全力押注推理计算。
简单来说,NVIDIA 认为 AI 计算的主要负载将是推理(运行 AI 模型),而不是训练。
他们的最新 GPU 产品就反映了这一趋势。
首先,他们发布了 Blackwell Ultra NVL72 服务器机架,特点包括:
• 1.1 Exaflops 的 FP4(半字节精度)推理算力(1 Exaflop = 每秒 1 百万万亿次计算)
• 专门针对 AI 注意力机制优化的计算单元(AI 模型的核心)
• 20TB 的 HBM 内存 + 40TB 的高速存储,比上一代 Blackwell 增加 1.5 倍
• 14.4TB/s 的内存带宽

为什么说这次发布的产品专注于推理计算?主要有两个原因:
- 它们的算力比当前 Blackwell 提高了 50%,但完全放弃了 FP64 计算单元,意味着 HPC 彻底被放弃,全面转向 AI 计算(低精度计算)。
- 他们把单个 GPU 的 HBM 内存从 192GB 提高到 288GB,主要是为了适配更大的模型,并且支持更大的 KV Cache(缓存 AI 推理过程中的关键数据,减少重复计算)。
但如果我们再往未来看,这个趋势就更明显了。
他们还公布了下一代 AI 计算平台:Vera Rubin(以发现暗物质的天文学家命名)。
相比 Blackwell Ultra,Vera Rubin:
• 计算能力提高 3.3 倍,其中一部分是因为晶体管从 4nm 缩小到 3nm,提升了功率密度。
• 每块 GPU 仍然使用相同的 HBM 堆叠,但升级到了 HBM4,内存带宽提升 2 倍。

不过,最令人震惊的还是下一款产品: 一台服务器机架塞进了 576 块 GPU,计算能力是 Blackwell Ultra 的 14 倍(而 Blackwell Ultra 现在都还没开始量产)。

在这个版本中,NVIDIA 把单个 GPU 的封装数量从 2 个提升到了 4 个,总共 1TB 的内存,比当前 Blackwell 增加 6 倍。
注意这个模式了吗?
核心结论 #4:
NVIDIA 不仅在增加计算能力(通过增加 GPU 数量、缩小晶体管尺寸来提升功率密度),更重要的提升在于内存,因为推理计算的最大瓶颈是内存带宽。
这一点说明 NVIDIA 认为AI 推理将成为计算负载的核心。
但为什么内存对推理计算这么重要?
简单来说,推理计算比训练计算的算术强度(arithmetic intensity)更低。
(算术强度 = 计算过程中用于真正计算的能量 vs. 用于数据传输的能量)
换句话说,如果你的算术强度低,那 GPU 会花更多的能量在数据搬运上,而不是计算上。
因此,NVIDIA 正在努力提升内存性能,从两个方向:
- 增加内存容量(能支持更大的 AI 模型和更大的缓存,从而提升处理能力)
- 提升内存传输速度(减少数据传输时间,让 GPU 的计算单元尽可能少“闲着”)
NVIDIA 的战略透露了什么?
综合来看,NVIDIA 其实已经告诉了我们他们的核心判断,而这些决定了 AI 产业未来的走向。
主要有五个关键点:
- NVIDIA 认为 AI 模型会继续变大
但这一点我持保留意见。虽然确实有越来越多的大模型,但它们主要是用来训练更小的模型,而不是直接部署。NVIDIA 能否让更大的模型成本降低到可以广泛应用,还是个未知数。 - 功率密度的极限已近,突破越来越难
他们已经快碰到物理极限,所以只能依靠更小的晶体管和更复杂的封装技术。 - 他们全力押注“推理 AI”
下一代 AI 模型主要依赖更强的推理能力,也就是“想得更久、算得更多”来提升智能。如果推理 AI 失败,那 NVIDIA 的路线图就会彻底崩塌。(不过我个人认为推理 AI 不会失败。) - 他们相信注意力机制仍然是 AI 的核心
NVIDIA 在计算单元中加入了专门优化注意力机制的 ALU(受到 Etched.AI 等创业公司的影响)。这一点说明,他们认为 AI 未来不会有太大的算法革新,而是会基于当前的 Transformer 框架继续演进。 - AMD 该怎么应对?
AMD 现在有两条路:
o 继续在 HPC 市场深耕,放弃 AI 计算的部分市场(因为 NVIDIA 基本独占 AI 硬件市场)。
o 跟 NVIDIA 正面刚,全面优化 AI 计算性能。
但 AMD 在 AI 计算的硬件网络层面不如 NVIDIA,所以他们可能会选择 继续稳住 HPC,同时针对小规模 AI 推理市场做优化(我个人也认为小规模推理会非常普遍)。
总结
从 NVIDIA 这次的发布会可以看出,他们的战略核心是:
• AI 计算会以推理为主
• 硬件发展会越来越依赖内存,而不是纯粹的计算能力
• 算力增长的瓶颈在于芯片封装和功率密度
• NVIDIA 认为 AI 的核心算法已经基本定型,不会再有大变化
我个人比较认可 NVIDIA 的判断。
但你怎么看?