Assignment 1: Performance Analysis on a Quad-Core CPU
Environment Setup
-
CPU信息
Architecture: x86_64CPU op-mode(s): 32-bit, 64-bitAddress sizes: 46 bits physical, 57 bits virtualByte Order: Little Endian CPU(s): 160On-line CPU(s) list: 0-159 Vendor ID: GenuineIntelModel name: Intel(R) Xeon(R) Platinum 8383C CPU @ 2.70GHzCPU family: 6Model: 106Thread(s) per core: 2Core(s) per socket: 40Socket(s): 2Stepping: 6CPU max MHz: 3600.0000CPU min MHz: 800.0000BogoMIPS: 5400.00 -
install the Intel SPMD Program Compiler (ISPC) available here: http://ispc.github.io/
wget https://github.com/ispc/ispc/releases/download/v1.26.0/ispc-v1.26.0-linux.tar.gztar -xvf ispc-v1.26.0-linux.tar.gz && rm ispc-v1.26.0-linux.tar.gz# Add the ISPC bin directory to your system path. export ISPC_HOME=/home/cilinmengye/usr/ispc-v1.26.0-linux export PATH=$ISPC_HOME/bin:$PATH -
The assignment starter code is available on https://github.com/stanford-cs149/asst1
Program 1: Parallel Fractal Generation Using Threads (20 points)
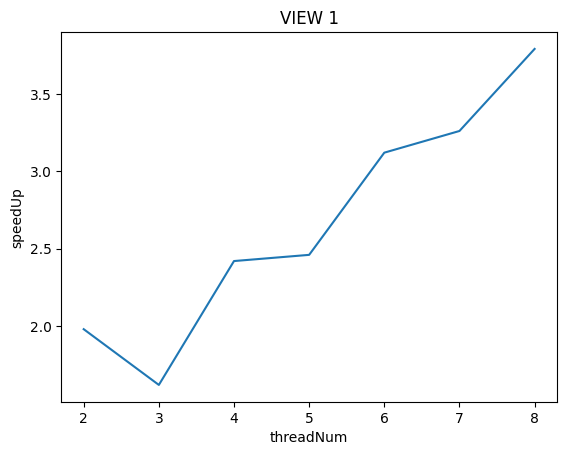
**Is speedup linear in the number of threads used? **
In your writeup hypothesize why this is (or is not) the case?
(you may also wish to produce a graph for VIEW 2 to help you come up with a good answer. Hint: take a careful look at the three-thread datapoint.)
To confirm (or disprove) your hypothesis, measure the amount of time each thread requires to complete its work by inserting timing code at the beginning and end of workerThreadStart()
VIEW 1:
[mandelbrot thread 0]: [333.949] ms
[mandelbrot thread 1]: [356.226] ms[mandelbrot thread 0]: [131.044] ms
[mandelbrot thread 2]: [154.097] ms
[mandelbrot thread 1]: [428.861] ms[mandelbrot thread 0]: [62.530] ms
[mandelbrot thread 3]: [83.256] ms
[mandelbrot thread 1]: [291.673] ms
[mandelbrot thread 2]: [292.539] ms[mandelbrot thread 0]: [28.683] ms
[mandelbrot thread 4]: [50.483] ms
[mandelbrot thread 1]: [193.241] ms
[mandelbrot thread 3]: [193.720] ms
[mandelbrot thread 2]: [288.939] ms[mandelbrot thread 0]: [17.357] ms
[mandelbrot thread 5]: [37.675] ms
[mandelbrot thread 1]: [134.275] ms
[mandelbrot thread 4]: [134.862] ms
[mandelbrot thread 2]: [223.723] ms
[mandelbrot thread 3]: [224.468] ms[mandelbrot thread 0]: [13.236] ms
[mandelbrot thread 6]: [32.660] ms
[mandelbrot thread 1]: [95.954] ms
[mandelbrot thread 5]: [97.984] ms
[mandelbrot thread 2]: [166.271] ms
[mandelbrot thread 4]: [167.878] ms
[mandelbrot thread 3]: [214.565] ms[mandelbrot thread 0]: [9.987] ms
[mandelbrot thread 7]: [28.890] ms
[mandelbrot thread 1]: [75.118] ms
[mandelbrot thread 6]: [75.412] ms
[mandelbrot thread 2]: [130.862] ms
[mandelbrot thread 5]: [131.121] ms
[mandelbrot thread 3]: [185.480] ms
[mandelbrot thread 4]: [186.073] ms
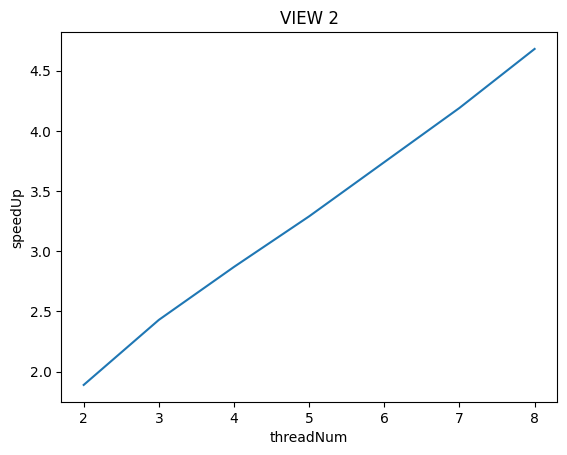
VIEW 2:
[mandelbrot thread 1]: [177.231] ms
[mandelbrot thread 0]: [226.604] ms[mandelbrot thread 2]: [120.581] ms
[mandelbrot thread 1]: [128.685] ms
[mandelbrot thread 0]: [174.056] ms[mandelbrot thread 3]: [98.259] ms
[mandelbrot thread 1]: [101.493] ms
[mandelbrot thread 2]: [102.176] ms
[mandelbrot thread 0]: [147.582] ms[mandelbrot thread 5]: [68.970] ms
[mandelbrot thread 4]: [73.143] ms
[mandelbrot thread 2]: [73.587] ms
[mandelbrot thread 3]: [76.763] ms
[mandelbrot thread 1]: [82.289] ms
[mandelbrot thread 0]: [112.975] ms[mandelbrot thread 6]: [59.428] ms
[mandelbrot thread 2]: [60.442] ms
[mandelbrot thread 4]: [63.801] ms
[mandelbrot thread 5]: [66.606] ms
[mandelbrot thread 3]: [71.558] ms
[mandelbrot thread 1]: [78.108] ms
[mandelbrot thread 0]: [100.265] ms[mandelbrot thread 7]: [53.217] ms
[mandelbrot thread 5]: [57.710] ms
[mandelbrot thread 2]: [57.926] ms
[mandelbrot thread 3]: [61.531] ms
[mandelbrot thread 4]: [62.739] ms
[mandelbrot thread 6]: [63.645] ms
[mandelbrot thread 1]: [77.445] ms
[mandelbrot thread 0]: [90.286] ms
可以通过对比VIEW 1和VIEW 2在不同线程数执行时各个线程的运行时间上看,VIEW 1具有严重的负载不均衡问题。特别是在VIEW 1下用3个线程执行时,thread 1运行时间居然高达428.861ms是其他线程运行时间的4倍!
这导致VIEW 1下用3个线程运行比用2个线程运行的加速比还要低!
VIEW 2显示出来了较为良好的负载均衡
为什么呢?其实我们可以从PPM图中看出:

上图为VIEW 1生成的PPM,按照我的策略,在使用3个线程执行时,从下到上的三个区域分别由thread0,1,2负责.
判断(x,y)坐标是否在mandelbrot集合中是由代码中static inline int mandel(float c_re, float c_im, int count)函数进行计算的。当算出(x,y)坐标越“接近”mandelbrot集合中,那么图中在(x,y)坐标上显示地越白。
关键是(x,y)坐标越“接近”mandelbrot集合,在mandel函数中迭代得越久(最大为256)。从上图中可以看到VIEW 1 thread1负责的区域相对与thread 0, thread 2有大片的空白,说明thread 1的计算量更大。

来看看VIEW 2的图,可以看到白点的分别就均匀许多了。
这里的代码具体参见mandelbrotThreadV1.cpp
Modify the mapping of work to threads to achieve to improve speedup to at about 7-8x on both views of the Mandelbrot set. In your writeup, describe your approach to parallelization and report the final 8-thread speedup obtained.
VIEW 1
[mandelbrot thread 0]: [334.905] ms
[mandelbrot thread 1]: [355.082] ms[mandelbrot thread 0]: [223.479] ms
[mandelbrot thread 1]: [244.310] ms
[mandelbrot thread 2]: [244.273] ms[mandelbrot thread 0]: [167.591] ms
[mandelbrot thread 1]: [188.222] ms
[mandelbrot thread 3]: [188.149] ms
[mandelbrot thread 2]: [188.211] ms[mandelbrot thread 0]: [134.268] ms
[mandelbrot thread 1]: [155.675] ms
[mandelbrot thread 4]: [155.588] ms
[mandelbrot thread 3]: [155.652] ms
[mandelbrot thread 2]: [155.684] ms[mandelbrot thread 0]: [111.937] ms
[mandelbrot thread 2]: [132.946] ms
[mandelbrot thread 4]: [132.864] ms
[mandelbrot thread 1]: [132.969] ms
[mandelbrot thread 3]: [132.941] ms
[mandelbrot thread 5]: [132.888] ms[mandelbrot thread 0]: [95.648] ms
[mandelbrot thread 1]: [116.998] ms
[mandelbrot thread 3]: [116.925] ms
[mandelbrot thread 2]: [116.974] ms
[mandelbrot thread 4]: [116.892] ms
[mandelbrot thread 6]: [116.812] ms
[mandelbrot thread 5]: [117.228] ms[mandelbrot thread 0]: [85.144] ms
[mandelbrot thread 1]: [104.262] ms
[mandelbrot thread 4]: [104.145] ms
[mandelbrot thread 2]: [104.286] ms
[mandelbrot thread 3]: [104.250] ms
[mandelbrot thread 7]: [106.611] ms
[mandelbrot thread 5]: [106.744] ms
[mandelbrot thread 6]: [106.666] msVIEW 2
[mandelbrot thread 0]: [191.501] ms
[mandelbrot thread 1]: [212.256] ms[mandelbrot thread 0]: [127.668] ms
[mandelbrot thread 2]: [149.055] ms
[mandelbrot thread 1]: [149.279] ms[mandelbrot thread 0]: [95.970] ms
[mandelbrot thread 1]: [115.653] ms
[mandelbrot thread 3]: [115.783] ms
[mandelbrot thread 2]: [115.902] ms[mandelbrot thread 0]: [76.880] ms
[mandelbrot thread 2]: [97.456] ms
[mandelbrot thread 1]: [97.590] ms
[mandelbrot thread 4]: [97.547] ms
[mandelbrot thread 3]: [97.708] ms[mandelbrot thread 0]: [64.118] ms
[mandelbrot thread 3]: [83.671] ms
[mandelbrot thread 4]: [83.687] ms
[mandelbrot thread 2]: [83.868] ms
[mandelbrot thread 1]: [84.021] ms
[mandelbrot thread 5]: [83.885] ms[mandelbrot thread 0]: [55.046] ms
[mandelbrot thread 6]: [75.713] ms
[mandelbrot thread 5]: [75.799] ms
[mandelbrot thread 4]: [75.939] ms
[mandelbrot thread 3]: [76.110] ms
[mandelbrot thread 2]: [76.357] ms
[mandelbrot thread 1]: [76.464] ms[mandelbrot thread 0]: [48.182] ms
[mandelbrot thread 7]: [68.148] ms
[mandelbrot thread 6]: [68.219] ms
[mandelbrot thread 5]: [68.308] ms
[mandelbrot thread 4]: [68.495] ms
[mandelbrot thread 3]: [68.535] ms
[mandelbrot thread 2]: [68.653] ms
[mandelbrot thread 1]: [68.736] ms
我真的尽量了,写了3种不同的方法对任务分配进行改进:
-
按照行进行划分区域,然后使用轮转的策略让不同线程负责不同的行,如下:
... 2 1 0 2 1 0 2 1 0 -
按照行进行划分区域,然后使用轮转的策略让不同线程负责不同的行,但是不按照固定顺序,如下:
... 1 0 2 0 2 1 2 1 0 -
按照点进行划分区域,然后使用轮转的策略让不同线程负责不同的点,如下
... 0 1 2 0 1 2 0 1 2 0 1 2
但是最终结果在使用8线程V1最多有6.75的加速比,V2最多有6.00的加速比
threadNum = np.array([k for k in range(2, 9)])
speedUpV1 = np.array([1.98, 1.62, 2.42, 2.46, 3.12, 3.26, 3.79])
speedUpV2 = np.array([1.89, 2.43, 2.87, 3.29, 3.74, 4.19, 4.68])
speedUpV1_V1 = np.array([2.00, 2.89, 3.76, 4.55, 5.32, 6.02, 6.67])
speedUpV1_V2 = np.array([1.97, 2.82, 3.58, 4.31, 4.96, 5.54, 6.04])
plt.plot(threadNum, speedUpV1, marker = 'o', label = 'methord1_V1')
plt.plot(threadNum, speedUpV2, marker = 'o', label = 'methord1_V2')
plt.plot(threadNum, speedUpV1_V1, marker = 'o', label = 'methord2_V1')
plt.plot(threadNum, speedUpV1_V2, marker = 'o', label = 'methord2_V2')
plt.xlabel("threadNum")
plt.ylabel("speedUp")
plt.legend()
plt.show()
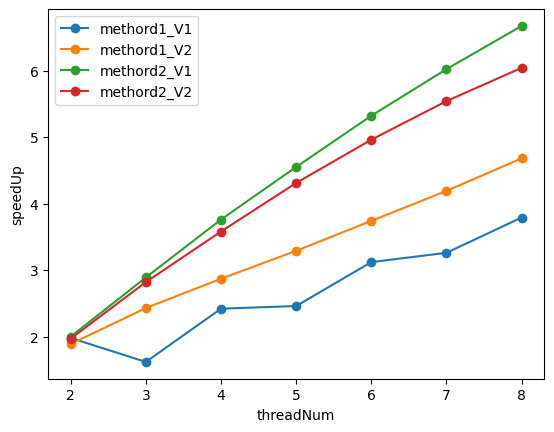
methord1是初始未进行改进的方法,methord2是改进后的方法
Now run your improved code with 16 threads. Is performance noticably greater than when running with eight threads? Why or why not?
我的结果是如下:
6.73x speedup from 8 threads
11.16x speedup from 16 threads
因为我的机器有80个核,所以并不会受到核的限制,当增加线程到16时,看起来加速比也提高了1.67倍左右。
但是原作业中只有8核,用16个线程是会启用到超线程的,但是超线程本质上是两个逻辑线程共用同一组计算部件,肯定性能上比一个core上运行一个线程要差。
BUG1: 浮点数计算的精度问题
若需精确控制小数位数,应避免直接依赖浮点数,改用高精度库或字符串处理。
在框架代码中,有检查serial版本和thread版本最终output结果是否相同的判断,但是在浮点数计算中可能遇到浮点数精度问题导致的数值最终不一样的问题,比如框架代码中:
for (int j = startRow; j < endRow; j++) {for (int i = 0; i < width; ++i) {float x = x0 + i * dx;float y = y0 + j * dy;int index = (j * width + i);output[index] = mandel(x, y, maxIterations);}}
serial版本和thread版本中,dy,dx的值分别一样,但是在serial中,当 y0 = -1, j = 601时, 计算出来的y 和 在thread中, 当 y0 = -1 + 600 * dy, j = 1时, 计算出来的y,都结果不一样。
所以thread版本需要让y0,x0以及i,j与serial版本一样才能最保证结果相同。
Program 2: Vectorizing Code Using SIMD Intrinsics (20 points)
Run
./myexp -s 10000and sweep the vector width from 2, 4, 8, to 16. Record the resulting vector utilization. You can do this by changing the#define VECTOR_WIDTHvalue inCS149intrin.h. Does the vector utilization increase, decrease or stay the same asVECTOR_WIDTHchanges? Why?
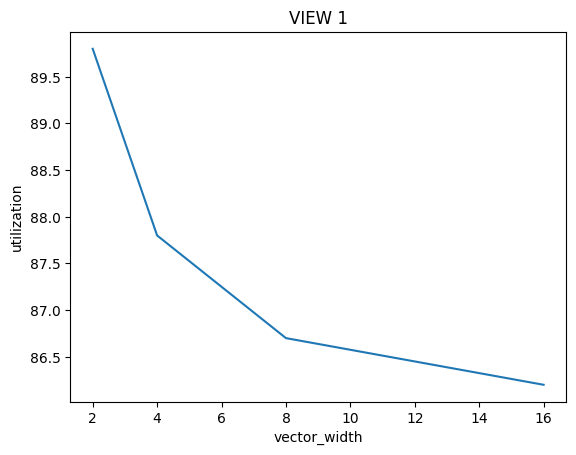
结果看起来是decrease的,首先我们要搞清楚Vector Utilization的计算方式:
\(Vector \ Utilization = \frac{Utilized \ Vector \ Lanes}{Total \ Vector \ Lanes}\)
\(Total \ Vector \ Lanes = Total \ Vector \ Instructions * Vector \ Width\)
同时有很多因素导致在一次Vector指令操作时,Vector Lanes不能得到充分利用:
- 分支判断if
- 循环while
这些语句总是会导致lane会有停用等待的情况,当Vector Width成倍数增长时,Total Vector Instructions并非成倍数的下降,Utilized Vector Lanes也并非成倍数的上升