概率论与数理统计1-基本概念
概率论与数理统计2-基本数据结构
概率论与数理统计3-基本数据处理技术
基本的数据处理技术
查找
查找的基本概念
在哪里找:查找表是由同一类型的数据元素(或记录)构成的集合,集合中的数据元素之间关系松散。
按什么查找:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素或(记录)。
关键字:用来标识一个数据元素(或记录)的某个数据项的值
主关键字:可唯一地标识一个记录的关键字是主关键字;
次关键字:反之,用以识别若干记录的关键字是次关键字。
查找成功否:若查找表中存在这样一个记录,则称“查找成功”。
查找结果给出整个记录的信息,或指示该记录在查找表中的位置。
否则称“查找不成功”。
查找结果给出“空记录”或“空指针”。
查找的目的:查找某个“特定的”数据元素是否在查找表中;
检索某个“特定的”数据元素的各种属性;
插入查找表中某个数据元素的某个数据项;
删除查找表中的某个数据元素。
查找表怎么分类:静态查找表,仅作“查询”(检索)操作的查找表;
动态查找表,作“插入”和“删除”操作的查找表;
如何评价查找算法(查找算法的评价指标):关键字的平均比较次数,也称平均查找长度(ASL Average Search Length)
查找过程中要研究:查找表的各种组织方法及其查找过程的实施。
线性表的查找
顺序查找(线性查找)
应用范围:顺序表或线性链表表示的静态查找表,表内元素之间无序。
数据表的表示 和 数据元素类型定义:
typedef struct {KeyType key; // 关键字域...
}ElemType;typedef struct { // 顺序表结构类型定义ElemType *R; // 表基址int length; // 表长
}SSTable; // Sequential Search TableSSTable ST; // 定义顺序表ST
在顺序表ST中查找值为key的数据元素
int Search_Seq( SSTable ST, KeyType key ){for ( int i = ST.length; i >= 1; --i)if ( ST.R[i].key == key )return i;return 0;
}
/////////////////////////////////改进,这样就可以用一句话表达for句。
int Search_Seq( SSTable ST, KeyType key ){int i = ST.length;for ( ; ST.R[i].key != key && i > 0; --i );if ( i > 0 ) return i;else return 0;
}
//////////////////////////////// 改进:把待查关键字key存入表头(哨兵,监视哨)。
int SEARCH_Seq( SSTable ST, KeyType key ){ST.R[0].key = key; // 监视哨,找不到后会在这里找到。int i = ST.length; // 当ST.length较大时,这样做平均时间几乎减少一半for ( ; ST.R[i].key != key; --i ); // 从后往前查return i
}
比较次数与\(key\)位置有关:
- 查找第\(i\)个元素,需要比较\(n-i+1\)次
- 查找失败,需要\(n+1\)次
时间复杂度为:\(O(n)\)
查找成功时的平均查找长度,设表中各记录查找概率相等,则((20240715145430-n71izn3 "ASL"))=\((n+1)/2\)
空间复杂度为:\(O(1)\)
更多调整
按查找概率高低存储,使得ASL下降;这样做后查找概率越高,比较次数越少
如何测定查找概率——按查找概率动态调整记录顺序
- 在每个记录后设置一个访问频度域。
- 按照非递增有序的次序排列。
- 每次查找后将查找到的记录移至表头,访问频度+1。
优点
算法简单,逻辑次序无要求,且不同存储结构均适用。
缺点
((20240715145430-n71izn3 "ASL"))太长,时间效率太低。
折半查找(二分或对分查找)
查找排序(默认递增)过后的记录,每次将待查记录所在区间缩小一半。
算法过程:
-
设表长为n,low、high和mid分别指向待查元素所在区间的上界、下界和中点,key为给定的要查找的值
-
初始时,令\(low=1,high=n,mid=\lfloor (low+high)/2 \rfloor\)
-
让k与mid指向的记录比较
- 若key==R[mid].key,查找成功
- 若key<R[mid].key,则high = mid - 1
- 若key>R[mid].key,则low = mid + 1
-
重复上述操作,直至low>high时,查找失败
////////////////////////////////非递归
int Search_Bin( SSTable ST, KeyType key ){int low = 1;int high = ST.length; // 置区间初值while ( low <= high ){int mid = (low + high) / 2;if ( ST.R[mid].key == key )return mid; // 找到待查元素else if ( key < ST.R[mid].key ) // 缩小查找区间high = mid - 1; // 继续在前半区间进行查找elselow = mid + 1; // 继续在后半区间进行查找}return 0; // 顺序表中不存在待查元素
}
////////////////////////////////递归
int Search_Bin( SSTable ST, KeyType key, int low, int high ){if ( low > high )return 0; //查找不到时返回int mid = (low + high)/2;if ( key == ST.R[mid].key )return mid;else if ( key < ST.R[mid].key )Search_Bin(ST, key, low, mid - 1);elseSearch_Bin(ST, key, mid + 1, high);
}折半查找根据判定次数可以构成判定树
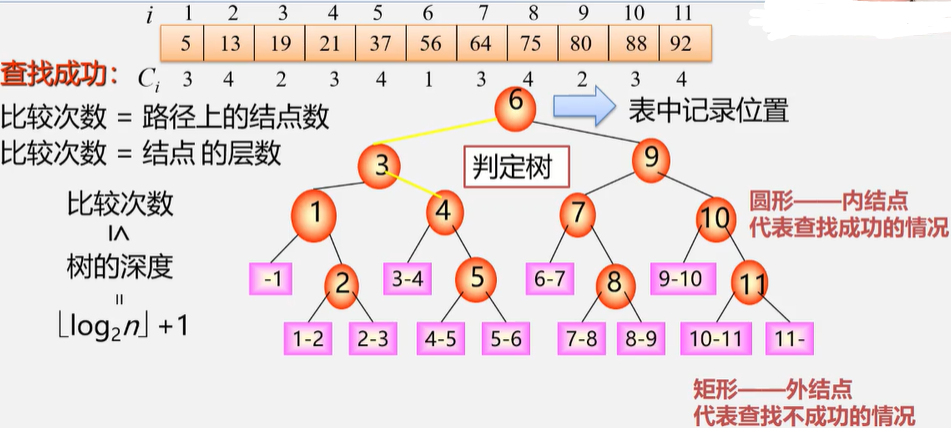
查找成功:比较次数\(\le\)树的深度=\(\lfloor\log_2n\rfloor+1\)
查找不成功:比较次数=路径上内部结点数\(\le\lfloor\log_2n\rfloor+1\)
查找概率相等,平均查找长度((20240715145430-n71izn3 "ASL"))=\(\frac{n+1}n\log_2(n+1)-1\approx\log_2(n+1)-1(n>50)\)
优点
效率比顺序查找高
缺点
只适用于有序表,且限于顺序存储结构(对线性链表无效)。
分块查找(索引顺序查找)
将表分成几块,且表有序或分块有序。建立“索引块”(每个结点含有最大关键字域和指向本块第一个结点的指针)
查找过程:先确定待查记录所在块(顺序或折半查找),再在块内查找(顺序查找)
查找效率((20240715145430-n71izn3 "ASL"))=\(L_b+L_W\)=\(\log_2(\frac{n}s+1)+\frac{s}2\quad(\log_2n\le ASL\le\frac{n+1}2)\)
适用于线性表既要快速查找又要经常动态变化。
优点
插入和删除比较容易,无序进行大量移动
缺点
要增加一个索引表的存储空间并对初始索引表进行排序运算。
查找方法比较
| 顺序查找 | 折半查找 | 分块查找 | |
|---|---|---|---|
| ASL | 最大 | 最小 | 中间 |
| 表结构 | 有序表、无序表 | 有序表 | 分块有序 |
| 存储结构 | 顺序表、线性链表 | 顺序表 | 顺序表、线性链表 |
树表的查找
动态查找表,表结构在查找过程中动态生成;对给定的key,查找成功返回记录,查找时报插入关键字等于key的记录。
这些特殊的树有:二叉排序树,平衡二叉树,红黑树,B-树,B+树,键树。
二叉排序树(二叉搜索树、二叉查找树)
二叉排序树可以是空树,否则满足
- 若其左子树非空,则左子树上所有结点的值均小于根结点的值;
- 若其右子树非空,则右子树上所有结点的值均大于等于根结点的值;
- 其左右子树本身又各是一棵二叉排序树
二叉排序树按照中序遍历后,得到是排序过后的数据
typedef struct {KeyType key; // 关键字项InfoType otherinfo; // 其他数据域
}ElemType;
typedef struct BSTNode{ELemType data; // 数据域struct BSTNode *lchild, *rchild; // 左右孩子指针
}BSTNode, *BSTree;BSTree T; // 定义二叉排序树T
查找算法思路
-
若二叉排序树为空,则查找失败,返回空指针。
-
若二叉排序树非空,将给定值key与根结点的关键字T->data.key进行比较:
- 若key等于T->data.key,则查找成功,返回根节点地址;
- 若key小于T->data.key,查其左子树
- 若key大于T->data.key,查其右子树
BSTree SearchBST( BSTree T, KeyType key ){if ( !T || key == T->data.key )return T;else if ( key < T->data.key )return SearchBST(T->lchild, key) // 在左子树中继续查找elsereturn SearchBST(T->rchild, key) // 在右子树中继续查找
}
二叉排序树的平均查找长度
最好情况:树的深度=\(\lfloor\log_2n\rfloor+1\),((20240715145430-n71izn3 "ASL"))=\(\log_2(n+1)-1\),\(O(\log_2n)\)
最坏情况:树的深度=\(n\),ASL=\((n+1)/2\),\(O(n)\)
更多调整
对形态不均衡的二叉排序树做“平衡化”处理。
二叉排序树的插入
-
若二叉排序树为空,则插入结点作为根结点插入到空树中
-
若二叉排序树不为空,则在左右子树上查找,树中已有,不再插入
- 树中已有,不再插入
- 树中没有,查找至某个叶子结点的左子树或右子树为空为止,插入其中
BSTree InteBST( BSTree T, ElemType e ){if ( !T ){T = (BSTree)malloc(sizeof(BSTNode));T->data = e;T->lchild = T->rchild = NULL;}else if ( e.key < T->data.key ) T->lchild = InteBST(T->lchild, e);else T->rchild = InteBST(T->rchild, e);return T;
}
二叉排序树的删除
-
被删除的结点是叶子结点:直接删除结点
-
被删除的结点只有左子树或只有右子树:用其左子树或右子树替换
-
被删除的结点既有左子树也有右子树:
- 以中序前趋值替换,再删除该前趋结点(左子树最大值)。
- 以中序后继值替换,再删除该后继结点(右子树最小值)。
BSTree DeleteBST( BSTree T, KeyType key ){if ( !T ) return NULL; // 空树if ( key < T->data.key ) // 搜索删除的结点T->lchild = DeleteBST(T->lchild, key);else if ( key > T->data.key ) T->rchild = DeleteBST(T->rchild, key);else{ // key == T->data.key 搜索到要删除的结点if ( T->lchild && T->rchild ){ // 结点有两个孩子BSTree s = T->lchild; // 在左子树中查找最右结点while ( s->rchild ) // 搜索到最右结点s = s->rchild;T->data = s->data; // 用s的数据域覆盖T的数据域T->lchild = DeleteBST(T->lchild, T->data.key); // 在右子树中删除s结点}else if ( T->lchild )T = T->lchild;else if ( T->rchild )T = T->rchild;elsefree(T);}return T;
}
平衡二叉树(AVL树)
将二叉排序树进行平衡化,平衡二叉树(AVL树)
特点:
- 这是一个二叉排序树
- 左子树与右子树的高度之差的绝对值小于等于1
- 左子树和右子树也是平衡二叉排序树
为了方便起见,给结点附加一个数字,给出该结点的左子树与右子树的高度差,这个数字称为结点的平衡因子(BF)。
\(平衡因子=结点左子树的高度-结点右子树的高度\),平衡因子只能是\(-1、0、1\)
对于一棵有\(n\)个结点的AVL树,其高度保持在\(O(\log_2n)\)数量级,ASL也保持在\(O(\log_2n)\)量级
失衡调整
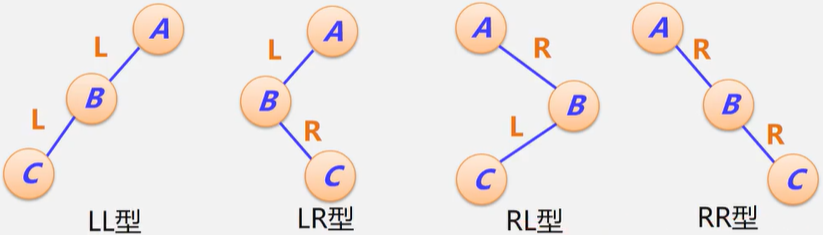
平衡调整的四种类型:LL型,LR型,RL型,RR型
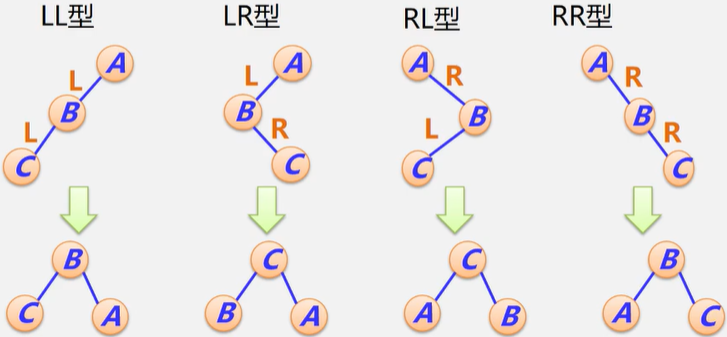
调整原则:
- 降低高度
- 保持二叉排序树性质
LL型:B结点带左子树一起上升,A结点成为B的右子树,B结点原来的右子树作为A结点的左子树
RR型:B结点带右子树一起上升,A结点成为B的左子树,B结点原来的左子树作为A结点的右子树
LR型:C结点穿过A、B结点上升,B成C的左子树,A成C的右子树,C原来的左子树成B的右子树,C原来的右子树成A的左子树。
RL型:C结点穿过A、B结点上升,A成C的左子树,B成C的右子树,C原来的左子树成A的右子树,C原来的右子树成B的左子树。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int KeyType;
typedef char InfoType;typedef struct {KeyType key;InfoType otherinfo;
}ElemType;typedef struct AVLNode{ElemType data;struct AVLNode *lchild,*rchild;int height;
}AVLNode,*AVLTree;int GetHeight(AVLTree T){return T ? T->height : 0;
}int GetBF(AVLTree T){ // 获取平衡因子if (!T) return 0;return GetHeight(T->lchild) - GetHeight(T->rchild);
}void UpdateHeight(AVLTree T){ // 更新树的深度(高度)int lchildheight = GetHeight(T->lchild);int rchildheight = GetHeight(T->rchild);T->height = (lchildheight > rchildheight ? lchildheight : rchildheight) + 1;
}void R_Rotate(AVLTree *T){ // 右旋AVLTree lc = (*T)->lchild;(*T)->lchild = lc->rchild;lc->rchild = *T;UpdateHeight(*T);UpdateHeight(lc);*T = lc;
}
void L_Rotate(AVLTree *T){ // 左旋AVLTree rc = (*T)->rchild;(*T)->rchild = rc->lchild;rc->lchild = *T;UpdateHeight(*T);UpdateHeight(rc);*T = rc;
}AVLTree InsertAVL(AVLTree T, ElemType e){if ( !T ){T = (AVLTree)malloc(sizeof(AVLNode));T->data = e;T->lchild = T->rchild = NULL;}else if (e.key < T->data.key)T->lchild = InsertAVL(T->lchild, e);else if (e.key > T->data.key)T->rchild = InsertAVL(T->rchild, e);elsereturn T;UpdateHeight(T); // 更新树的高度int BF = GetBF(T); // 获取平衡因子if (BF > 1 && e.key < T->lchild->data.key) // LL{R_Rotate(&T);}else if (BF < -1 && e.key > T->rchild->data.key) // RR{L_Rotate(&T);}else if (BF > 1 && e.key > T->lchild->data.key) // LR{L_Rotate(&T->lchild);R_Rotate(&T);}else if (BF < -1 && e.key < T->rchild->data.key) // RL{R_Rotate(&T->rchild);L_Rotate(&T);}return T;
}// 中序遍历
void InOrder(AVLTree T){ if (T) { InOrder(T->lchild); printf("%d:%d_%d ", T->data.key, GetBF(T),GetHeight(T)); InOrder(T->rchild); }
}int main(){AVLTree T = NULL;srand((unsigned)time(NULL));for (int i = 0; i < 10; i++){ElemType e = {rand() % 100, 'a'};T = InsertAVL(T, e);InOrder(T);printf("\n");}return 0;
}
B-树
一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足以下性质:
- 根结点至少有两个孩子
- 每个分支结点都包含\(k-1\)个关键字和\(k\)个孩子,其中\(ceil(m/2)\le k \le m\),\(ceil\)是向上取整函数
- 每个叶子结点都包含\(k-1\)个关键字,其中\(ceil(m/2)\le k \le m\)
- 所有的叶子结点都在同一层
- 每个结点中的关键字从小到大排列,结点中\(k-1\)个元素正好是\(k\)个孩子包含的元素的值域划分
- 每个结点的结构为:\((n,A_0,K_1,A_1,K_2,A_2,...,K_n,A_n)\)其中,\(K_i(i\le i \le n)\)为关键字,
且\(K_i<K_{i+1}(1\le i \le n-1)\) 。\(A_i(0\le i \le n)\)为指向子树根结点的指针,且\(A_i\)所指子树所有结点中的关键字均小于\(K_{i+1}\)。\(n\)为结点中关键字的个数,满足\(ceil(m/2)-1\le n \le m-1\)
B+树
红黑树
散列表的查找
基本思想:记录的存储位置与关键字之间存在对应关系(hash函数)Loc(i)=H(keyi)
优点:查找效率高\(O(1)\),缺点:空间效率低
散列方法(杂凑法):选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放;
散列函数(杂凑函数):散列方法中使用的转换函数。H(key)=k
散列表(杂凑表):按上述思想构造的表。
冲突:不同的关键码映射到同一个散列地址,\(key1\ne key2\)但\(H(key1)=H(key2)\),冲突不可避免,只能减少。
同义词:具有相同函数值的多个关键词。
散列存储:选取某个函数,依该函数按关键字计算元素的存储位置。
构造散列函数需要考虑的因素:①执行速度(计算散列函数所用时间)②关键字长度③散列表大小④关键字分布情况⑤查找频率
根据元素集合特性构造:①希望地址空间尽量小②均匀存储元素,避免冲突。
散列表的构建
构造散列函数使用的方法:
- 直接定址法:\(Hash(key)=a\times key+b\)
优点:以关键码key的某个线性函数值为散列地址,不会产生冲突。
缺点:要占用连续地址空间,空间效率低。 - 数字分析法:
- 平方取中法
- 折叠法
- 除留余数法:\(Hash(key)=key\mod p(p是一个整数)\)
设表长为m,取\(p\le m\)且为质数 - 随机数法
解决冲突问题方法:
-
开放定址法(开地址法):有冲突时寻找下一个空的散列地址
如:除留余数法\(H_i=(Hash(key)+d_i)\mod m(d_i为增量序列)\)- ——线性探测法:\(d_i\)为\(1,2,...,m-1\)线性序列
- ——二次探测法:\(d_i\)为\(1^2,-1^2,2^2,-2^2,...,q^2\)二次序列
- ——伪随机探测法:\(d_i\)为伪随机数序列
-
链地址法(拉链法):相同散列地址的记录链成一单链表,将表头指针存储起来,形成动态结构
优点:非同义词不会冲突,无“聚集”现象。链表上结点空间动态申请,更适合于表长不确定的情况 -
再散列法(双散列函数法)
-
建立一个公共溢出区
散列表的查找
线性探测再测散列处理冲突,即\(Hi=(H(key)+d_i)\mod m\)
((20240715145430-n71izn3 "ASL"))=\((1*n_1+2*n_2+3*n_3+...+n*n_n)/n\)
链地址法处理冲突
((20240715145430-n71izn3 "ASL"))=\((1*n_1+2*n_2+3*n_3+...+n*n_n)/n\)
散列表平均查找长度ASL取决于:1.散列函数2.处理重复方法3.散列表装填因子\(\alpha\)(\(\alpha=\frac{表中填入的记录数}{哈希表的长度}\)越大发生冲突的可能越大)
拉链法ASL\(\approx 1+\frac\alpha2\)
线性探测法ASL\(\approx\frac12(1+\frac1{1-\alpha})\)
随机探测法ASL\(\approx-\frac1\alpha\ln(1-\alpha)\)
结论:
- 散列表技术具有很好的平均性能,优于一些传统的技术
- 链地址法优于开地址法
- 除留余数法作散列函数优于其他类型函数
排序
| 类别
| 排序方法
| 时间复杂度
| | | 空间复杂度 | 稳定性
|
| 最好情况 | 最坏情况 | 平均情况 | 辅助存储 | |||
|---|---|---|---|---|---|---|
| 插入排序 |
直接插入排序 | \(O(n)\) | \(O(n^2)\) | \(O(n^2)\) | \(O(1)\) | 稳定 |
| 二分插入排序 | \(O(n)\) | \(O(n^2)\) | \(O(n^2)\) | \(O(1)\) | 稳定 | |
| 希尔排序 | \(O(n)\) |
\(O(n^2)\) | ~\(O(n^{1.3})\) | \(O(1)\) | 不稳定 | |
| 交换排序 |
冒泡排序 | \(O(n)\) |
\(O(n^2)\) | \(O(n^2)\) | \(O(1)\) | 稳定 |
| 快速排序 | \(O(n\log n)\) | \(O(n^2)\) | \(O(n\log n)\) | \(O(\log n)\) | 不稳定 | |
| 选择排序 |
简单选择排序 | \(O(n^2)\) | \(O(n^2)\) | \(O(n^2)\) | \(O(1)\) | 不稳定 |
| 堆排序 | \(O(n\log n)\) | \(O(n\log n)\) | \(O(n\log n)\) | \(O(1)\) | 不稳定 | |
| 归并排序 | 2-路归并排序 | \(O(n\log n)\) | \(O(n\log n)\) | \(O(n\log n)\) | \(O(n)\) | 稳定 |
| 基数排序 | k为待排元素的维数 m为基数的个数 |
\(O(n+m)\) | \(O(k*(n+m))\) | \(O(k*(n+m))\) | \(O(n+m)\) | 稳定 |
基本概念和排序方法概述
什么是排序?将无序序列排成一个有序序列的运算。如果参加排序的数据结点包含多个数据域,那么排序针对的是某个数据域。
排序的分类:
-
按数据存储介质:内部排序和外部排序
- 内部排序:数据量不大、数据在内存,无需内外存交换数据。
- 外部排序:数据量较大、数据在外存(文件排序)。数据分批调用,中间结果存入外存。
-
按比较器个数:串行排序和并行排序
- 串行排序:单处理机(同一时刻比较一对元素)。
- 并行排序:多处理机(同一时刻比较多对元素)。
-
按主要操作:比较排序和基数排序
- 比较排序:用比较的方法(插入排序、交换排序、选择排序、归并排序)。
- 基数排序:不用比较元素的大小,仅根据元素本身的取值确定序列位置。
-
按辅助空间:原地排序和非原地排序
- 原地排序:辅助空间用量为\(O(1)\)的排序方法。(所占的辅助存储空间与参加排序的数据量大小无关)
- 非原地排序:辅助空间用量超过\(O(1)\)的排序方法。
-
按稳定性:稳定排序和非稳定排序
只对结构类型的数据排序有意义,不能衡量一个排序算法的优劣
- 稳定排序:能使任何数值相等的元素,排序以后相对次序不变。
- 非稳定排序:不是稳定排序的方法
-
按自然性:自然排序和非自然排序
- 自然排序:输入数据越有序,排序速度越快的排序方法。
- 非自然排序:不是自然排序
简单的排序方法的时间复杂度\(T(n)=O(n^2)\)
基数排序时间复杂度\(T(n)=O(d.n)\)
先进的排序方法的时间复杂度\(T(n)=O(n\log n)\)
顺序表存储结构
#define MAXSIZE 20 // 记录不超过20个
typedef int KeyType // 关键字类型为整型
typedef char InfoType // 其他数据项typedef struct { // 定义每一个(数据元素)记录的结构KeyType key; // 关键字InfoType otherinfo; // 其他数据项
}RedType; // Record Typetypedef struct { // 定义顺序表的结构RedType r[MAXSIZE+1]; // 存储顺序表的向量,r[0]一般作为哨兵或缓冲区int length; // 顺序表的长度
}SqList
插入排序
插入\(a[i]\)前,数组\(a\)的前半段(\(a[0]~a[i-1]\))是有序段,后半段(\(a[i]~a[n-1]\))是停留输入次序的“无序段”。
插入\(a[i]\)使得\(a[0]~a[i-1]\)有序,也就是要为\(a[i]\)找到有序位置\(j\)(\(0\le j\le i\))
直接插入排序
使用顺序法定位插入位置
- 复制插入元素,可以使用\(L.r[0]\)的哨兵位置使得
L.r[0]=L.r[i]; - 记录后移,查找插入位置
for ( j=i-1; L->r[0].key<L->r[j].key; --j ) L->r[j+1]=L->r[j]; - 插入到正确的位置
L.r[j+1]=L.r[0];
void InsertSort(SqList *L) {int i, j;for ( i = 2; i <= L->length; i++ ) {if ( L->r[i].key < L->r[i-1].key ){ // 待排元素小于最后一个有序元素L->r[0] = L->r[i]; // 复制到哨兵位置for ( j = i-1; L->r[0].key < L->r[j].key; j-- )L->r[j+1] = L->r[j]; // 记录后移L->r[j+1] = L->r[0]; // 插入到正确位置}}
}
最好情况比较次数:\(\sum_{i=2}^n1=n-1\) 最好情况移动次数:0
最坏情况比较次数:\(\sum_{i=2}^ni=\frac{(n+2)(n-1)}2\) 最坏情况移动次数:\(\sum_{i=2}^n(i+1)=\frac{(n+4)(n-1)}2\)
平均情况比较次数:\(\sum_{i=1}^{n-1}\frac{i+1}2=\frac14(n+2)(n-1)\) 平均情况移动次数:\(\sum_{i=1}^{n-1}(\frac{i+1}2+1)=\frac14(n+6)(n-1)\)
最坏情况时间复杂度\(Tw(n)=O(n^2)\) 平均时间复杂度\(Te(n)=O(n^2)\)
二分插入排序
使用二分法定位插入位置,将顺序查找法替换成折半查找法
void BInsertSort( SqList *L ){int i, j, low, high, m;for ( i = 2; i <= L->length; i++ ) {L->r[0] = L->r[i]; // 复制到监视哨low = 1; // 二分法最低端high = i-1; // 二分法最高端while ( low <= high ) { // 二分法m = ( low + high ) >> 1;if ( L->r[0].key < L->r[m].key ) high = m-1;else low = m+1;}// 循环结束找到插入位置,high+1for ( j = i-1; high+1 <= j; j-- ) L->r[j+1] = L->r[j]; // 记录后移L->r[high+1] = L->r[0]; // 插入}
}
减少了比较次数,但没有减少移动次数
平均性能优于直接插入排序
时间复杂度\(O(n^2)\)
空间复杂度\(O(1)\)
希尔排序
使用缩小增量多遍插入排序
定义一个增量序列\(D_K:D_M>D_{M-1}>...>D_1=1\),对每个\(D_K\)进行间隔排序
- 第一次移动位置较大,跳跃式接近排序后的位置
- 最后一次只需要少量移动
- 增量排序必须是递减的,最后一个必须是1
- 增量序列应该是互质的
void ShellInsert( SqList *L, int dk ) {// 对顺序表L进行一趟增量dk的希尔插入排序,dk为步长因子int i, j;for ( i = dk+1; i <= L->length; i++ )if ( L->r[i].key < L->r[i-dk].key ) { // 待排元素小于有序元素L->r[0] = L->r[i]; // 复制到监视哨for ( j = i-dk; j > 0 && L->r[0].key < L->r[j].key; j -= dk )L->r[j+dk] = L->r[j]; // 记录后移L->r[j+dk] = L->r[0]; // 插入到正确位置}
}void ShellSort( SqList *L, int dlta[], int t ) {// 按增量序列dlta[0..t-1]对顺序表L作希尔排序for ( int k = 0; k < t; k++ ) // 按增量序列dlta[k]进行希尔排序ShellInsert( &L, dlta[k] );
}
希尔排序算法效率与增量序列取值有关
Hibbard增量序列:\(D_K=2^{k-1}\)—相邻元素互质,
最坏情况\(T_{worst}=O(n^{\frac32})\),平均情况\(T_{avg}=O(n^{\frac54})\)
Sedgewick增量序列:\(\{1,5,19,41,109,...\}=9*4^i-9*2^i+1或4^i-3*2^i+1\),
最坏情况\(T_{worst}=O(n^{\frac43})\),平均情况\(T_{avg}=O(n^{\frac76})\)
时间复杂度是n和d的函数:\(O(n^{1.25})~O(1.6n^{1.25})\)经验公式
空间复杂度为\(O(1)\)
- 选择最佳增量序列D,目前尚未解决
- 最后一个增量值必须为1
- 不宜在链式存储结构上实现
交换排序
两两比较,如果发生逆序则交换,直到所有记录都排好序为止
冒泡排序
时间复杂度为\(O(n^2)\)
有\(n\)个元素,需要进行\(n-1\)趟排序
void bubble_sort( SqList *L ){int i,j,n=L->length;int flag = 1; // 增加一个flag加快结束,某一趟没有出现交换则终止排序for ( i = 1; i < n - 1 && flag == 1; i++ ) { // 总共需要m趟,当flag标识不为1时终止排序flag = 0; for ( j = 1; j <= n - i; j++ ) if ( L->r[j+1].key < L->r[j].key ) { // 发生逆序flag=1; // 发生交换,flag置为1,若本趟没发生交换,flag仍为0L->r[0]=L->r[j]; // 交换L->r[j]=L->r[j+1];L->r[j+1]=L->r[0];}}
}
优点:每趟结束时,挤出一个最大值到最后,还可以部分理顺其他元素;
可以设置当某一趟出现不交换元素时结束排序
最好情况比较次数:\(n-1\) 最好情况移动次数:\(0\)
最坏情况比较次数:\(\sum_{i=1}^{n-1}(n-i)=\frac12(n^2-n)\) 最坏情况移动次数:\(3\sum_{i=1}^n(n-i)=\frac32(n^2-n)\)
快速排序
时间复杂度为\(O(n\log_2n)\)
选取任一一个元素为中心,比它小的元素一律前放,比它大的元素一律后放,形成左右两个子表。
对子表重新选择中心元素并以此规则调整,直至每个子表的元素只剩一个。
int Partition( SqList *L, int low, int hight ){ \\O(n)L->r[0] = L->r[low]; // 用L->r[0]暂存枢轴记录while ( low < hight ) {while ( low < hight && L->r[hight].key >= L->r[0].key)hight--;L->r[low] = L->r[hight]; // 将比枢轴小的记录移到低端while ( low < hight && L->r[low].key <= L->r[0].key)low++;L->r[hight] = L->r[low]; // 将比枢轴大的记录移到高端}L->r[low] = L->r[0]; // 枢轴记录到位return low; // 返回枢轴位置
}void QSort( SqList *L, int low, int hight ){ \\ O(log2n)if ( low < hight ){int pivotloc = Partition(&L, low, hight); // 将L->r[low..hight]一分为二,pivotloc为枢轴位置QSort(&L, low, pivotloc-1); // 对低子表递归排序QSort(&L, pivotloc+1, hight); // 对高子表递归排序}
}
快速排序不适于对原本有序或基本有序的记录序列进行排序。快速排序不是自然排序方法。
选择排序
简单选择排序
在待排序的数据中选出最大(小)的元素放在其最终的位置
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与第一个记录交换;
- 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换;
- 重复上述操作,共进行n-1趟排序后,结束排序。
void SelectSort(SqList *L) {int i, j, k;RedType temp;for (i = 1; i < L->length; i++) {k = i;for (j = i + 1; j <= L->length; j++) if (L->r[j].key < L->r[k].key) k = j; // 找到最小关键字的位置if (k != i) { // 交换最小关键字和第i个记录temp = L->r[i];L->r[i] = L->r[k];L->r[k] = temp;}}
}
最好情况比较次数:\(\sum_{i=1}^{n-1}(n-1)=\frac n2(n-1)\quad O(n^2)\) 最好情况移动次数:\(0\)
最好情况比较次数:\(\sum_{i=1}^{n-1}(n-1)=\frac n2(n-1)\quad O(n^2)\) 最坏情况移动次数:\(3(n-1)\)
简单排序是不稳定排序,但是可以通过稳定化使得算法稳定。
堆排序
堆定义:若n个元素的序列\(\{a_1,a_2...,a_n\}\)满足\(\begin{cases} a_i\le a_{2i} \\ a_i\le a_{2i+1} \end{cases}\)或\(\begin{cases} a_i\ge a_{2i} \\ a_i\ge a_{2i+1} \end{cases}\)则分别称该序列\(\{a_1,a_2...,a_n\}\)为小根堆和大根堆。
堆实质是满足如下性质的完全二叉树:二叉树树中任一非叶子结点均小于(大于)它的孩子结点。
堆排序:堆顶元素与堆底元素交换,剩余的n-1个元素序列重新构建堆,如此反复,得到一个有序序列,这个过程称为堆排序。
堆调整:比较左右孩子的大小,并与其中较小者交换,直到叶子结点;从n/2个元素开始调整。
void HeapAdjust(SqList *L, int s, int m) { // 用于调整r[s],使得s到m成为一个小根堆L->r[0] = L->r[s];for (int j = 2*s; j <= m; j *= 2) {if (j < m && L->r[j].key > L->r[j+1].key) // L->r[j].key > L->r[j+1].key小根堆// L->r[j].key < L->r[j+1].key大根堆j++;if (L->r[0].key <= L->r[j].key) // L->r[0].key <= L->r[j].keyx小根堆// L->r[0].key >= L->r[j].key 大根堆 break;L->r[s] = L->r[j];s = j;}L->r[s] = L->r[0];
}void HeapSort( SqList *L ){int i;for (i = L->length/2; i > 0; i--) // 时间复杂度O(n)HeapAdjust(L, i, L->length); // 建立初始堆for (i = L->length; i > 1; i--) { // 交换堆顶元素和堆底元素 时间复杂度O(nlogn)L->r[0] = L->r[1]; // 将堆顶元素存入临时变量L->r[1] = L->r[i]; // 将堆底元素存入堆顶L->r[i] = L->r[0]; // 将临时变量存入堆底HeapAdjust(L, 1, i-1); // 调整堆}
}
小根堆排完序后是从大到小,大根堆排完序后是从小到大。
堆排序时间复杂度Tw(n)=O(n)+O(nlogn)=O(nlogn)
最好情况或者最坏情况时间复杂度都是O(nlogn),与数据初始状态无关。
对元素个数较多的情况是有效的
归并排序
将两个或两个以上的有序子序列“归并”为一个有序序列。在内部排序中,同常采用的是2-路归并排序。
2-路归并排序
在两个位置相邻的有序子序列\(R[l..m]\)和\(R[m+1..n]\)归并为一个有序序列\(R[l..n]\)
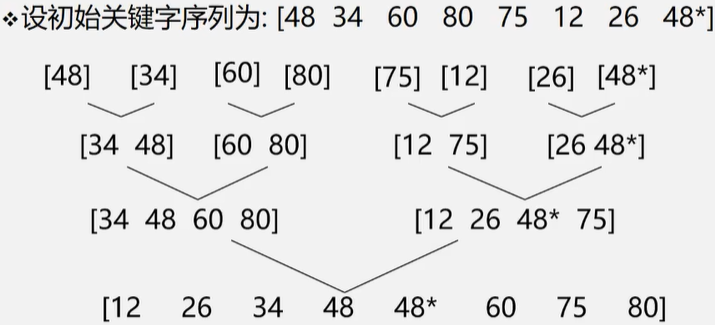
这样构成的树成为归并树。
///////////////递归方法实现
void _MergeSort( SqList *R, int left, int right, SqList temp ){if ( left >= right )return;int mid = (left + right) / 2;_MergeSort(R, left, mid, temp);_MergeSort(R, mid + 1, right, temp);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int i = begin1;while (begin1 <= end1 && begin2 <= end2){if ( R->r[begin1].key <= R->r[begin2].key )temp.r[i++] = R->r[begin1++];elsetemp.r[i++] = R->r[begin2++];}while (begin1 <= end1) temp.r[i++] = R->r[begin1++];while (begin2 <= end2)temp.r[i++] = R->r[begin2++];for (int j = left; j <= right; j++) R->r[j] = temp.r[j];}void MergeSort( SqList *R ){SqList temp;if ( R->length <= 1)return;_MergeSort(R, 1, R->length, temp);
}////////////////////////////////非递归方法实现
void MergeSortNonR(SqList *R)
{//归并排序SqList temp;temp.length = 0;int gap = 1;int size = R->length;while (gap < size){//单趟排序int i;for (i = 1; i < size; i += 2*gap) //一次跨2*gap格,两个数组{int begin1 = i, end1 = i+gap-1; //第一个数组下标区间int begin2 = i+gap, end2 = i+2*gap-1; //第二个数组下标区间,别忘记加上i//数组边界处理if (end1 >= size) //第一个数组越界{break;}if (begin2 >= size) //第二个数组全部越界{break;}if (end2 >= size) //第二个数组部分越界{end2 = size - 1;}//排序合并int j = i; //合并后数组的下标while (begin1 <= end1 && begin2 <= end2){if (R->r[begin1].key <= R->r[begin2].key)temp.r[j++] = R->r[begin1++];elsetemp.r[j++] = R->r[begin2++];}while (begin1 <= end1)temp.r[j++] = R->r[begin1++];while (begin2 <= end2)temp.r[j++] = R->r[begin2++];//拷贝temp数组到原数组(排哪个区间就拷贝哪个区间,end2是闭区间哦)for (j=i; j<=end2; j++){R->r[j] = temp.r[j];}}gap *= 2;}
}
基数排序
分配+收集
也叫桶排序或箱排序:设置若干个箱子,将关键字为k的记录放入第k个箱子,然后再按照序号将非空的连接起来。
基数排序的数字是有范围的,适用于多关键字的排序。不适用于关键字取值范围较大。
时间效率:O(k*(n+m)),k表示关键字个数,m关键字取值范围为m个值。时间复杂度\(T(n)=O(d.n)\)
空间效率:O(n+m)
外部排序
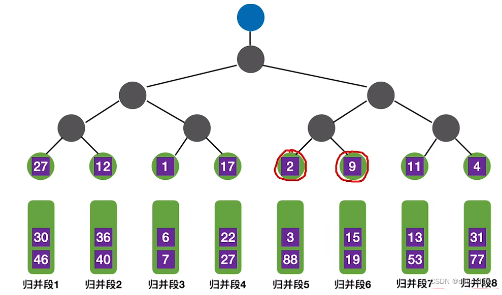
相当于复杂版本的归并排序,可以使用多路归并排序算法加快排序进程。
也可以使用败者树或最佳树来减少归并次数。
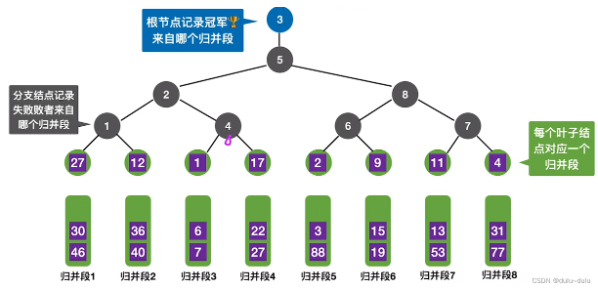
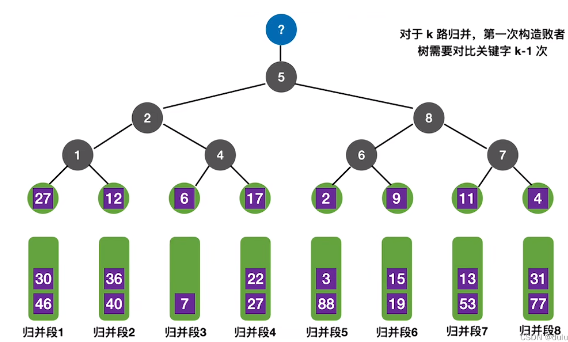
败者树
最佳树
最佳树适用于优化置换-选择排序,将置换-选择排序中读写次数作为权值,构造哈夫曼树,这样得到的哈夫曼树就是最佳树。
根据最佳树路径来进行归并排序。
各种排序方法的综合比较
时间性能
按平均的时间性能来分析,有三类排序方法
-
时间复杂度为\(O(n\log n)\)的方法有:
- 快速排序、堆排序、归并排序,其中以快速排序为最好
-
时间复杂度为\(O(n^2)\)的有:
- 直接插入排序、冒泡排序、简单选择排序,其中以直接插入排序为最好,特别是对哪些关键字近似有序的记录尤为好
-
时间复杂度为\(O(n)\)的有:
- 基数排序,不能对所有的情况都适用。
当待排序记录的关键字顺序有序时:
- 直接插入排序和冒泡排序能达到\(O(n)\);
- 快速排序,时间性能会退化到\(O(n^2)\)
- 简单选择排序、堆排序、归并排序的时间性能不随关键字的分布而改变
空间性能
排序过程中需要的辅助空间大小
- 所有简单排序方法(直接插入排序、冒泡排序、简单选择排序)和堆排序的空间复杂度为\(O(1)\)
- 快速排序空间复杂度为\(O(n\log n)\),使用到了栈因此需要额外的空间
- 归并排序的空间复杂度最多使用了\(O(n)\)
- 链式基数排序需要附设队列首尾指针,空间复杂度为\(O(rd)\)
稳定性能
排序方法的稳定性能,对于两个关键字相等的记录,排序后是否改变相对位置,就是排序的稳定性。
对多关键字记录序列进行LSD方法排序时,必须采用稳定的排序方法。
对不稳定的排序方法只需举例一个实例说明即可。
快速排序和堆排序是不稳定的排序方法。
关于排序方法的时间复杂度的下限
除基数排序外,其他方法基于比较关键字进行排序的排序方法,可以证明这类方法最快的时间复杂度为\(O(n\log n)\)
可以用一颗判定树来描述这类基于比较关键字进行排序的排序方法。