概率论与数理统计1-基本概念
概率论与数理统计2-基本数据结构
概率论与数理统计3-基本数据处理技术
基本的数据结构
- 数据结构- 数据的逻辑结构- 线性结构- 线性表- 栈(特殊的线性表)- 队列(特殊的线性表)- 字符串- 数组- 广义表- 非线性结构- 树型结构- 图型结构- 数据的存储结构- 顺序存储- 链式存储- 索引存储- 散列存储- 数据的运算- 检索- 排序- 插入- 删除- 修改- 等
线性表
线性表的定义和特点
线性表是具有相同特性的数据元素的一个有限序列\((a_1,a_2,\cdots,a_{i-1},a_i,a_{i+1},\cdots,a_n)\)
线性表的首个元素\(a_1\)称为起始节点,最后一个元素\(a_n\)称为终端结点,中间的任意一个元素\(a_i\)称为结点或数据元素,\(a_i\)的前一个元素\(a_{i-1}\)称为直接前趋,后一个元素\(a_{i+1}\)称为直接后继。最后一个元素的下标为表长\(n\),当\(n=0\)时为空表
同一线性表中的元素必须具有相同特性,数据元素间的关系是线性关系
非空的线性表当中有一个开始结点\(a_1\),它没有直接前趋,仅有一个直接后继\(a_2\);
有且仅有一个终端结点\(a_n\),它没有直接后继,仅有一个直接前趋\(a_{n-1}\);
其余内部结点\(a_i(2\le i\le n-1)\)都有且仅有一个直接前趋\(a_{i-1}\)和一个直接后继\(a_{i+1}\)
线性表是一种典型的线性逻辑结构
例子:一元多项式(顺序线性表,链式线性表),图书信息管理系统(顺序线性表,链式线性表)
线性表抽象数据类型定义
ADT List{数据对象: D={ai|ai属于Elemset,(i=1,2,...,n,n>=0)}数据关系: R{<ai-1,ai>|ai-1,ai属于D,(i=2,3,...,n)}基本操作: initList(&L);操作结果:构造一个空的线性表L。DestroyList(&L);初始条件:线性表L已经存在。操作结果:销毁线性表L。ClearList(&L);初始条件:线性表L已经存在。操作结果:将线性表L重置为空表。ListEmpty(L);初始条件:线性表L已经存在。操作结果:若线性表L为空表,则返回True,否则为False。ListLength(L);初始条件:线性表L已经存在。操作结果:返回线性表L中的数据元素个数。GetElem(L,i,&e);初始条件:线性表L已经存在,1<=i<=ListLength(L)。操作结果:用e返回线性表L中第i个数据元素的值。LoacteElem(L,e,compare());初始条件:线性表L已经存在,compare()是数据元素判定函数操作结果:返回L中第1个与e满足compare()的数据元素的位序。若这样的数不存在则返回值为0。PriorElem(L,cur_e,&pre_e);初始条件:线性表L已经存在。操作结果:若cur_e是L的数据元素,且不是第一个,则用pre_e返回它的前趋,否则操作失败;pre_e无意义。NextElem(L,cur_e,&next_e);初始条件:线性表L已经存在。操作结果:若cur_e是L的数据元素,且不是最后一个,则用pre_e返回它的后继,否则操作失败;pre_e无意义。ListInsert(&L,i,e);初始条件:线性表L已经存在,1<=i<=ListLength(L)+1。操作结果:在L的第i个位置之前插入新的数据元素e,L的长度加一ListDelete(&L,i,&e);初始条件:线性表L已经存在,1<=i<=ListLength(L)。操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减一。ListTraverse(&L,visited())初始条件:线性表L已经存在。操作结果:依次对线性表中每个元素调用visited()
}ADT List
线性表的顺序存储(线性表)
线性表的顺序存储结构:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构。
这样存储的线性表第一个数据元素\(a_1\)的存储位置,称为线性表的起始位置或基地址。
要按照先后顺序存储,同时要依次存储,地址连续,中间没有空出存储单元。这样就决定了线性表顺序存储结构需要占用一片连续的存储空间。知道某个元素的存储位置就可以计算其他元素的存储位置。
线性表顺序存储的特点:以物理位置相邻表示逻辑关系,任一元素均可随机存取。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2#define MaxSize 100 // 顺序表存储空间可能达到的最大长度
typedef int Status;
typedef int ElemType;/*线性表顺序存储模板typedef struct{ElemType elem[MaxSize]; // ElemType 代表elem的类型。elem[MaxSize]数组静态分配,int length;}SqList;typedef struct{ElemType *elem; // ElemType 代表elem的类型。*elem数组动态分配int length;}SqList;
*/
/*线性表顺序存储具体示例typedef struct{ElemType elem[MaxSize]; int length;}SqList;SqList L;// 声明后直接使用即可,声明时会自动创建MaxSize大小的地址
//////////////////////////////////typedef struct { // 图书信息的定义char no[20]; // 图书ISBN号char name[50]; // 图书名float price; // 图书价格}Book;typedef struct{ // 顺序表的定义Book *elem; // 存储空间基址 // *elem数组动态分配int length; // 当前长度}SqList;SqList L; // 声明数据L->elem = (Book*) malloc(sizeof(Book) * MaxSize) // 分配存储空间// malloc(m)函数,开辟m字节长度的地址空间,并返回这段地址的首地址// sizeof(x)函数,计算变量x的长度// free(p)函数,释放指针p所指变量的存储空间,即彻底删除一个变量// 需要加载头文件<stdlib.h>// (ElemType*) 强制转换成ElemType类型的指针
*/typedef struct // 数据元素
{char no[10]; // 数据项char name[20]; // 数据项float price; // 数据项
} Book;typedef struct // 顺序表
{Book *data; // 数据对象int length; // 记录长度
} SqList;/**** @description: 初始化顺序线性表* @return {*} 成功返回OK,否则返回OVERFLOW* @param {SqList} *L 传入顺序线性表的地址*/
static int
InitList_Sq(SqList *L)
{L->data = (Book *)malloc(sizeof(Book) * MaxSize); // 分配空间if (!L->data) exit(OVERFLOW);L->length = 0;return OK;
}/**** @description: 销毁顺序线性表* @return {*}* @param {SqList} *L 传入顺序线性表的地址*/
static void
DestroyList(SqList *L)
{if (L->data)free(L->data); // 释放存储空间
}/**** @description: 清空线性表* @return {*}* @param {SqList} *L 传入顺序线性表的地址*/
static void
ClearList(SqList *L)
{L->length = 0; // 将线性表的长度置为0
}/**** @description: 获取线性表长度* @return {int} 返回长度* @param {SqList} L 传入顺序线性表*/
static int
GetLength(SqList L)
{return (L.length);
}/**** @description: 判断线性表是否为空* @return {int} 返回TRUE或FALSE* @param {SqList} L 传入顺序线性表*/
static int
IsEmpty(SqList L)
{if (L.length == 0)return FALSE;elsereturn TRUE;
}/**** @description: 获取第i个元素* @return {int} 成功返回OK,否则返回ERROR* @param {SqList} L 传入顺序线性表* @param {int} i 传入要获取顺序线性表的位置* @param {Book} *e 传入接受元素的地址*/
static int
GetElem(SqList L, int i, Book *e)
{if (i < 1 || i > L.length)return ERROR;*e = L.data[i - 1];return OK;
}/**** @description: 顺序线性表查找元素* @return {int} 成功返回查找到的位置,否则返回0* @param {SqList} L 传入顺序线性表* @param {Book} e 传入要查找的元素*/
static int
LocateElem(SqList L, Book e)
{// for 语法for (int i = 0; i<L.length; i++){if (strcmp(L.data[i].no, e.no) == 0) return i+1; }return 0;// while 语法// int i = 0;// while (i < L.length && strcmp(L.data[i].no, e.no) != 0)// i++; // 时间复杂度为O(n)// if (i < L.length)// return i + 1;// return 0;
}/**** @description: 顺序线性表插入元素* @return {int} 成功返回OK,否则返回ERROR* @param {SqList} *L 传入顺序线性表的地址* @param {int} i 传入要插入的位置,1~length+1* @param {Book} e 传入要插入的元素*/
static int
ListInsert(SqList *L, int i, Book e)
{if (i < 1 || i > L->length + 1)return ERROR; // 插入位置不合法if (L->length >= MaxSize)return ERROR; // 线性表已满for (int j = L->length - 1; j >= i - 1; j--)// 插入位置之后的元素后移 L->data[j + 1] = L->data[j]; //时间复杂度O(n)L->data[i - 1] = e;L->length++;return OK;
}/**** @description: 顺序线性表删除元素* @return {int} 成功返回OK,否则返回ERROR* @param {SqList} *L 传入顺序线性表的地址* @param {int} i 传入要删除的位置* @param {Book} *e 传入接受删除元素的地址*/
static int
ListDelete(SqList *L, int i, Book *e)
{if (i < 1 || i > L->length)return ERROR; // 删除位置不合法*e = L->data[i - 1]; // 将被删除的元素赋值给efor (int j = i; j < L->length; j++) // 删除位置之后的元素前移L->data[j - 1] = L->data[j]; //时间复杂度O(n)L->length--;return OK;
}/*** * @description: 打印顺序线性表* @return {*}* @param {SqList} L 传入顺序线性表*/
static void
ListPrint(SqList L){for (int i = 0; i < L.length; i++)printf("线性表L|\t长度:%d\t|\tno:%s\t|\tname:%s\t|\tprice%f|\n",GetLength(L), L.data[i].no, L.data[i].name, L.data[i].price);
}int
main()
{Book b1 = {"001", "C语言", 50.0};Book b2 = {"002", "C++", 60.0};Book b3 = {"003", "Java", 70.0};int sub;SqList L;if (InitList_Sq(&L)) //初始化{if (ListInsert(&L, 1, b1)) // 插入{printf("插入成功\n");ListPrint(L); // 打印}else{printf("插入失败\n");}}else{printf("初始化失败\n");return 1;}ClearList(&L);printf("清空线性表\n");ListInsert(&L, 1, b1); // 插入ListInsert(&L, 2, b2); // 插入ListInsert(&L, 3, b3); // 插入ListPrint(L); // 打印if (IsEmpty(L)) // 判断是否为空sub = LocateElem(L, b2); // 查找if (sub){Book b4;GetElem(L,sub,&b4);printf("\n查找的元素|\t位置:%d\t|\tno:%s\t|\tname:%s\t|\tprice%f|\n\n",sub, b4.no, b4.name, b4.price);}else{printf("查找失败\n");}if (ListDelete(&L, 1, &b1))//删除{printf("删除成功\n");ListPrint(L); // 打印}else{printf("删除失败\n");}DestroyList(&L); // 销毁return 0;
}-
查找
如果要计算查找算法时通常使用平均查找长度ASL:\(ASL=\sum_{i=1}^n P_iC_i(P_i=查找成功的概率,C_i=比较的次数,整体代表求期望)\quad\quad当概率相等都为:P_i=\frac1n时,ASL_{SS}=\frac{n+1}2时间复杂度为O(ASL)\)
-
插入
如果要计算插入算法时需要计算平均移动次数:\(E_{ins}=\frac1{n+1}\sum_{i=1}^{n+1}(n-i+1)=\frac n2(n指的是线性表的长度)\)
时间复杂度为\(O(E_{ins})\) -
删除
如果要计算删除算法时需要计算平均移动次数:\(E_{del}=\frac1n\sum_{i=1}^n(n-i)=\frac{n-1}2(n指线性表的长度)\)
时间复杂度为\(O(E_{del})\)
这样的数据结构具有随机存取法即可以快速的计算出来任意一个数据元素的存储地址,访问每个元素所花费的时间相等,逻辑结构和存储结构一致。
顺序存储的线性表的优缺点
-
优点
存储密度大:\(结点本身所占存储量/结点结构所占存储量\)
可以随机存取表中任一元素 -
缺点
在插入、删除某一元素时,需要移动大量元素
浪费存储空间
属于静态存储形式,数据元素个数不能自由扩充
线性表的链式存储(链表)
各结点在存储器中的位置是任意的,逻辑相邻,物理不一定相邻,线性表的链式存储结构又叫非顺序映射或链式映射
线性表链式存储的结点:是由两部分组成【数据域 | 指针域】,链表:由n个结点组成的指针链
链表分为:单链表--只有一个指针域,双链表--有两个指针域,循环链表--首尾相接

链表还分为
-
不带头结点(特殊情况)
-
带头结点(一般情况下)
带头节点的好处:便于首元结点的处理,便于处理空表和非空表
头节点的数据域中可以为空,也可以存储表长度等其他附加信息。
线性表链式存储的特点:物理位置任意,元素顺序存取。
线性表顺序存储的特点:以物理位置相邻表示逻辑关系,任一元素均可随机存取。
单链表

#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
/*线性表顺序存储模板typedef struct Lnode{ // 声明结点的类型和指向结点的指针类型ElemType data; // 结点的数据域struct Lnode *next; // 结点的指针域 // 嵌套类型声明}Lnode, *LinkList; // LinkList为指向结构体Lnode的指针类型
*/
/*线性表顺序存储具体示例typedef struct Lnode {char num[8];char name[20];int score;struct Lnode *next;}Lnode, *LinkList;LinkList P; // 定义一个结点指针=Lnode *P;P = (LinkList)malloc(sizeof(Lnode)); // 分配一个结点的存储空间
//////////////////////////////////typedef struct {char num[8];char name[20];int score;} ElemType;typedef struct Lnode {ElemType data;struct Lnode *next;}Lnode, *LinkList;Lnode a1; // 定义一个结点;LinkList L; //定义一个链表L;LinkList P; // 定义一个结点指针=Lnode *P;P = (LinkList)malloc(sizeof(Lnode)); // 分配一个结点的存储空间
*/typedef struct
{char num[8];char name[20];int score;
} ElemType;typedef struct Lnode
{ElemType data;struct Lnode *next;
}Lnode, *LinkList;/*** * @description: 初始化链式线性表* @return {int} 成功返回OK,失败报错* @param {LinkList} *L 传入链式线性表的指针*/
static int
InitLinkList(LinkList *L)
{*L = (LinkList)malloc(sizeof(Lnode)); // 对链式线性表赋值 *L(头结点地址) // c++写法: L=now LNode;if (!(*L))exit(OVERFLOW);(*L)->next = NULL;return OK;
}/*** * @description: 判断链式线性表是否为空* @return {int} 为空返回0,否则返回1* @param {LinkList} L 链式线性表的指针*/
static int
IsLinkListEmpty(LinkList L)
{if (L->next) // 非空return 1;elsereturn 0;
}/*** * @description: 销毁链式线性表* @return {int} 成功返回OK* @param {LinkList} *L 链式线性表的指针*/
static int
DestroyLinkList(LinkList *L)
{Lnode *p;while (*L){p=*L; // 指向头结点L = &((*L)->next); // 移动指针free(p); // c++语法:delete p;} return OK;
}/*** * @description: 清空链式线性表* @return {int} 成功返回OK* @param {LinkList} *L 传入链式线性表的指针*/
static int
ClearLinkList(LinkList *L)
{Lnode *p = (*L)->next, *q; // p指向首原节点while (p){q = p->next; // 移动指针free(p); // c++语法:delete p;p = q;}(*L)->next = NULL;return OK;
}/*** * @description: 获取链式线性表长度* @return {int} 链表长度* @param {LinkList} L 传入链式线性表*/
static int
GetLeng(LinkList L)
{Lnode *p = L->next; // 指向首元节点int i=0;while (p){i++; // 计数p = p->next; // 移动指针}return i;
}/*** * @description: 得到链式线性表的第i个位置上的元素* @return {int} 成功返回OK* @param {LinkList} L 传入链式线性表* @param {int} i 结点位置* @param {ElemType} *e 接收返回的元素*/
static int
LinkListGet_Elem(LinkList L, int i, ElemType *e)
{Lnode *p = L->next; // 初始化int j = 1;while (p && j < i) // 向后扫描,直到p指向第i个元素或p为空{p = p->next; // 时间复杂度O(n)j++;}if (!p || j > i) // 第i个元素不存在return ERROR;*e = p->data; // 取出第i个元素return OK;
}/*** * @description: 获取链式线性表当中e的位置(序号)* @return {int} 找到返回位置,未找到返回0* @param {LinkList} L 传入链式线性表* @param {ElemType} e 要获取位置的数据*/
static int
LocateElemInLinkList_L(LinkList L,ElemType e)
{Lnode *p = L->next;int i = 1;while (p && strcmp(p->data.num, e.num) && strcmp(p->data.name, e.name) &&p->data.score == e.score){p = p->next;i++;}if (p) return i; // 找到返回位置序号else // 链表中不存在该元素return 0; // 未找到返回0
}/*** * @description: 获取链式线性表当中e的位置(地址)* @return {Lnode *} 找到返回地址,未找到返回NULL* @param {LinkList} L 传入链式线性表* @param {ElemType} e 要获取位置的数据*/
static Lnode *LocateElemInLinkList(LinkList L,ElemType e)
{Lnode *p = L->next;while (p && strcmp(p->data.num, e.num) &&strcmp(p->data.name, e.name) &&p->data.score == e.score)p = p->next; // 时间复杂度O(n)return p; // 找到了p指向结点,找不到p指向空
}/*** * @description: 在链式线性表第i个位置前插入* @return {int} 成功返回OK,失败返回ERROR* @param {LinkList} *L 链式线性表的指针* @param {int} i 结点位置* @param {ElemType} e 要插入的元素*/
static int
LinkListInsert_L(LinkList *L, int i, ElemType e)
{Lnode *p = *L, *q = (LinkList) malloc(sizeof(Lnode));q->data = e;int j = 0;while (p && j < i - 1){p = p->next;j++;}if (!p || j > i - 1) // 插入位置不合法return ERROR;q->next = p->next; // 关键步骤p->next = q;return OK;
}/*** * @description: 删除链式线性表的第i个位置上的元素* @return {int} 成功返回OK* @param {LinkList} *L 链式线性表的指针* @param {int} i 结点位置* @param {ElemType} *e 接收返回的元素*/
static int
LinkListDelete_L(LinkList *L, int i, ElemType *e)
{Lnode *p = *L, *q;int j = 0;while (p->next && j < i - 1){p = p->next;j++;}if (!p->next || j > i - 1) // 删除位置不合法return ERROR;q = p->next; // 临时保存删除结点地址p->next = q->next; // 改变删除结点前一个结点的指针域*e = q->data; // 保存删除结点的数据域free(q); // c++语法:delete q;return OK;
}/*** * @description: 链式线性表的创建* @return {int} 成功返回OK,失败报错* @param {LinkList} *L 传入链式线性表的指针* @param {int} n 传入要插入的数量* @param {char} *pattern 传入选择的模式"header"为头茬,其他为尾插*/
static int
CreateLinkList(LinkList *L,int n, char *pattern)
{int pat = strcmp("header",pattern); // 判断使用头插还是尾插if (pat == 0){ // 头插for (int i = 0; i < n; i++){Lnode *newLnode = (LinkList) malloc(sizeof(Lnode));if (!newLnode)exit(OVERFLOW);printf("请输入学生信息:\n输入格式001 张三 90\n");scanf("%s %s %d", newLnode->data.num, newLnode->data.name, &newLnode->data.score);newLnode->next = (*L)->next;(*L)->next = newLnode;}return OK;}else{ // 尾插Lnode *p=*L; // 默认传入的L是空表for (int i = n; i > 0; i--){Lnode *newLnode = (LinkList) malloc(sizeof(Lnode));if (!newLnode)exit(OVERFLOW);printf("请输入学生信息:\n输入格式001 张三 90\n");scanf("%s %s %d", newLnode->data.num, newLnode->data.name, &newLnode->data.score);newLnode->next = NULL;p->next = newLnode; // 插入到表尾p = p->next; // r指向新的尾结点}}
}int main() {LinkList L;ElemType e;int position;// 初始化链表InitLinkList(&L);// 创建链表,使用尾插法CreateLinkList(&L, 3, "tail");// 判断是否为空表if (IsLinkListEmpty(L))printf("链表为空\n");elseprintf("链表不为空\n");// 打印链表长度printf("链表长度: %d\n", GetLeng(L));// 获取链表的第一个元素LinkListGet_Elem(L, 1, &e);printf("第一个元素: %s %s %d\n", e.num, e.name, e.score);// 在链表的第二个位置插入新元素ElemType newElem = {"004", "李四", 95};LinkListInsert_L(&L, 2, newElem);// 打印更新后的链表长度printf("更新后链表长度: %d\n", GetLeng(L));// 获取新插入的元素LinkListGet_Elem(L, 2, &e);printf("新插入的元素: %s %s %d\n", e.num, e.name, e.score);// 删除链表的第三个元素LinkListDelete_L(&L, 3, &e);// 打印删除后的链表长度printf("删除后链表长度: %d\n", GetLeng(L));// 查找特定元素的位置ElemType searchElem = {"002", "王五", 88};position = LocateElemInLinkList_L(L, searchElem);if (position) printf("找到元素 %s %s %d 的位置: %d\n", searchElem.num, searchElem.name, searchElem.score, position);elseprintf("未找到元素 %s %s %d\n", searchElem.num, searchElem.name, searchElem.score);// 清空链表ClearLinkList(&L);// 销毁链表DestroyLinkList(&L);return 0;
}-
查找
查找算法因为链式存储线性表只能顺序存取,因此需要从头节点开始,查找时间复杂度为\(O(n)\)
-
插入和删除
插入算法一般情况下是 \(O(1)\),在不知道位置情况下插入需要查找因此为\(O(n)\)
这样的数据结构具有随机存取法即可以快速的计算出来任意一个数据元素的存储地址,访问每个元素所花费的时间相等,逻辑结构和存储结构一致。
循环链表
遍历终止条件变为判断是否为头指针,因为没有NULL指针域。
经常要操作首尾结点的话,使用尾指针,这样在循环单链表中操作首尾结点的话时间复杂度为O(1),其他位置为O(n)。

两个循环链表的合并
// p存表头结点,tb表头连接到ta表尾,释放tb表头结点,修改指针
LinkList Connect(LinkList Ta,LinkList Tb){p=Ta->next;Ta->next=Tb->next->next;free(Tb->next); // c++语法 delete Tb->nextTb->next=p;return Tb;
}
双向链表
为了解决加快查找前趋结点。
双向链表

双向循环链表
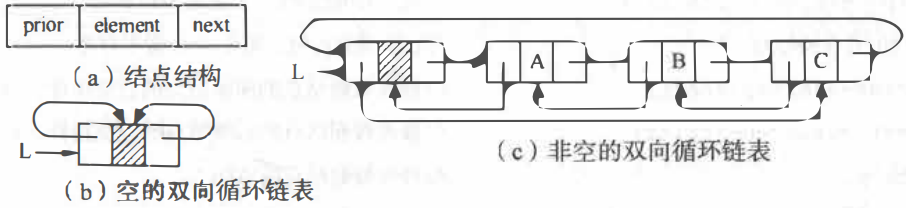
双向链表结构的对称性p->prior->next = p = p->next->prior
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2typedef struct {int data;
}Elemtype;typedef struct DuLNode {Elemtype data;struct DuLNode *next, *prior;
}DuLNode, *DuLinkList;/*** * @description: 双向链表的插入* @return {*} * @param {DuLinkList} *l 传入要插入的链表 * @param {int} i 传入插入的位置* @param {Elemtype} e 传入要插入的元素*/
static void
LinstInsert_DuL(DuLinkList *l, int i, Elemtype e)
{DuLNode *p;if (!(p=GetElemP_DuL(l,i)))return ERROR;DuLNode *s = (DuLinkList)malloc(sizeof(DuLNode)); // new DuLNode; s->data = e; s->prior = p->prior; // 双向链表修改四个指针p ->prior->next = s;s->next = p; p->prior = s;}/*** * @description: 双向链表的删除* @return {*}* @param {DuLinkList} *l 传入要删除的链表* @param {int} i 传入要删除的位置* @param {Elemtype} *e 返回要删除的元素*/
static void
ListDelete_DuL(DuLinkList *l, int i, Elemtype *e)
{DuLNode *p;if (!(p=GetElemP_DuL(l,i))) // 时间复杂度O(n)return ERROR;*e = p->data;p->prior->next = p->next;p->next->prior = p->prior;free(p);
}
链式存储的线性表的优缺点
| 查找表头结点(首元节点) | 查找表尾结点 | 查找结点*p的前驱结点 | |
|---|---|---|---|
| 带头结点的 单链表L |
L->next时间复杂度O(1) |
从L->next依次向后遍历时间复杂度为O(n) |
通过p->next无法查找到其前趋 |
| 带头结点的 仅设头指针L的 循环单链表 |
L->next时间复杂度O(1) |
从L->next依次向后遍历时间复杂度为O(n) |
通过p->next可以找到其前趋时间复杂度为O(n) |
| 带头结点的 仅设尾指针R的 循环单链表 |
R->next->next时间复杂度O(1) |
R时间复杂度O(1) |
通过p->next可以找到其前趋时间复杂度为O(n) |
| 带头节点的 双向循环链表L |
L->next时间复杂度O(1) |
L->prior时间复杂度O(1) |
p->prior时间复杂度O(1) |
优点:
- 结点空间可以动态申请和释放
- 数据元素的逻辑次序依靠结点指针来表示,插入和删除时不需要移动数据元素
缺点:
- 存储密度较小,每个结点的指针域都需要额外占用存储空间。
存储密度:\(存储密度 = \frac{结点数据本身占用的空间}{结点占用的总空间}\) - 链式存储结构是非随机存取结构,对结点操作需要从头指针依指针链查找到该结点,增加算法复杂度
顺序表和链表的比较
| 顺序表 | 链表 | ||
|---|---|---|---|
| 空间 | 存储空间 | 预先分配,会导致空间空闲或溢出现象 | 动态分配,不会出现存储空间闲置或溢出现象 |
| 存储密度 | 不用为表示结点间的逻辑关系而增加额 外的存储开销,存储密度等于1 |
需要借助指针来体现元素间的逻辑关系,存储 密度小于1 |
|
| 时间 | 存取元素 | 随机存取,按位置访问元素的时间复杂 度为O(1) |
顺序存取,按位置访问元素时间复杂度为O(n) |
| 插入、删除 | 平均移动约表中一半元素,时间复杂度 为O(n) |
不需要移动元素,确定插入、删除位置后,时 间复杂度为O(1) |
|
| 适用情况 | ①表长变化不大,且能事先确定变化的 范围。 ②很少进行插入或删除操作,经常按元 素位置序号访问数据元素。 |
①长度变化较大 ②频繁进行插入或删除操作 |
线性表的应用
线性表的合并
两个线性表La和Lb分别表示两个集合A和B,现在要求一个新的集合\(A=A\cup B\)
void union(List &La,List &Lb){ // 通用算法,具体问题具体分析La_len = ListLength(La); // 获取La的长度Lb_len = ListLength(Lb); // 获取Lb的长度for (i=1;i<=Lb_len;i++){ // 遍历LbGetElem(Lb,i,e); // 通过下标获取Lb的值if (!LocateElem(La,e)) // 如果La中不存在上述获取到的值ListInsert(&La,++La_len,e); // 将该值加入到La当中,La_len长度+1}
}
// 算法时间复杂度为O(ListLength(La)*ListLength(Lb))
已知线性表La和Lb中的数据元素按值非递减有序排列,现在要求将La和Lb归并为一个新的线性表Lc,且Lc中的元素仍然按值非递减有序排列。
// 顺序表实现
void MergeList_Sq(SqList LA, SqList LB, SqList &LC){pa = LA.elem;pb = LB.elem; // 指针pa和pb的初值分别指向两个表的第一个元素LC.length = LA.length+LB.length; // 新表的长度为待合并两表的长度之和LC.elem = (ElemType*)malloc(LC.length * sizeof(ElemType)); // 为合并后的新表分配一个数组空间pc = LC.elem; // 指针pc指向新表第一个元素pa_last = LA.elem+LA.length-1; // 指针pa_last指向LA表最后一个元素pb_last = LB.elem+LB.length-1; // 指针pb_last指向LB表最后一个元素while(pa <= pa_last && pb <= pb_last){ // 两表都非空if (*pa <= *pb) // 取两表当中的最小值放入pc当中*pc++ = *pa++;else*pc++ = *pb++;}while(pa <= pa_last) // LB表已经到表尾,将LA表中剩余的元素加入LC*pc++=*pa++;while(pb <= pb_last) // LA表已经到表尾,将LB表中剩余的元素加入LC*pc++=*pb++;
}
// 算法的时间复杂度为O(ListLength(La)+ListLength(Lb))
// 算法的空间复杂度为O(ListLength(La)+ListLength(Lb))
// 链表实现
void MergeList_Sq(SqList &Lb, SqList &Lb, SqList &Lc){pa = La->next;pb = Lb->next;pc = Lc = La; // 用La的头结点作为Lc的头节点while(pa && pb){if (pa->data <= pb->next){pc->next = pa;pc = pa;pa = pa->next;}else{pc->next = pb;pc = pb;pb = pb->next;}}pc->next = pa?pa:pb; // 插入剩余段if (pa) pc->next=pa; else pc->next=pb;free(Lb); // 释放Lb的头节点
}
// O(ListLength(La)+ListLength(Lb))
一元多项式运算
可以转换成两个线性表之间的运算
只需将两个顺序存储的线性表进行合并就是两个多项式相加
#include<stdio.h>
#include<stdlib.h>typedef struct{int coef;
} Pformula;int main()
{Pformula *p1=0,*p2=0;p1=(Pformula*)malloc(sizeof(Pformula)*10);p2=(Pformula*)malloc(sizeof(Pformula)*10);// 向p1中插入4个数据p1[0].coef=10;p1[1].coef=5;p1[2].coef=-4;p1[3].coef=3;p1[4].coef=2;// 向p2中插入4个数据p2[0].coef=-3;p2[1].coef=8;p2[2].coef=4;p2[3].coef=0;p2[4].coef=-5;p2[5].coef=7;p2[6].coef=-2;// 输出p1和p2printf("p1:");for(int i=0;i<5;i++){printf("%dx^%d+ ",p1[i].coef,i);}printf("\n");printf("p2:");for(int i=0;i<6;i++){printf("%dx^%d+ ",p2[i].coef,i);}printf("\n");Pformula *p3=0;p3=(Pformula*)malloc(sizeof(Pformula)*10);for(int i=0;i<10;i++){p3[i].coef=p1[i].coef+p2[i].coef;}printf("p3:");for(int i=0;i<10;i++){printf("%dx^%d+ ",p3[i].coef,i);}printf("\n");return 0;
}
稀疏多项式运算
用顺序存储结构的化会出现空间复杂度高,存储空间分配不够灵活;
使用链式存储结构更为符合;
#include <stdio.h>
#include <stdlib.h>typedef struct PNode{float coef;int index;struct PNode * next;
} PNode, * Polynomial;int CreatePolyn(Polynomial *P, int n){ // 输入m项的系数和指数,建立表示多项式的有序链表P*P = (Polynomial)malloc(sizeof(PNode)); (*P)->next = NULL; // 先建立一个带头节点的单链表Polynomial s, q, r; int i;float c;for(i = 0; i < n; i++){ // 依次输入n个非零项s = (Polynomial)malloc(sizeof(PNode)); // 生成新结点printf("请输入第%d个系数和指数:", i + 1); scanf("%f%d", &(s->coef), &(s->index));printf("\n");q = *P; // 用于保存r的前驱,初始值为头节点r = (*P)->next; // r初始化,指向首原节点while (r&&r->index < s->index) // 找到第一个大于输入项指数的项*r{q = r;r = r->next;}s->next = r; // 将输入项s插入到r之前q->next = s;}
}// 多项式相加
int AddPolyn(Polynomial *Pa, Polynomial Pb){Polynomial p1, p2, p3, p4;p1 = (*Pa)->next; // 指向首原节点p2 = Pb->next; // 指向首原节点p3 = *Pa; // 指向头结点p4 = Pb->next; // 指向头结点while(p1&&p2){if (p1->index == p2->index){p1->coef += p2->coef;if (p1->coef != 0){p3->next = p1;p3 = p1;p1 = p1->next;p2 = p2->next;free(p4);p4=p2;}else{p1 = p1->next;p2 = p2->next;free(p3->next);p3->next = NULL;free(p4);p4=p2;}}else if (p1->index > p2->index){p3->next = p2;p3 = p2;p2 = p2->next;p4=p2;}else{p3->next = p1;p3 = p1;p1 = p1->next;}}if (p1){p3->next = p1;}if (p2){p3->next = p2;}free(Pb);return 0;
}int main(){Polynomial Pa, Pb;CreatePolyn(&Pa,4);CreatePolyn(&Pb,6);AddPolyn(&Pa,Pb);Show(Pa);return 0;
}
图书信息管理
使用顺序存储,不经常插入删除操作,经常通过序号查找书
使用链式存储,经常插入删除书信息
栈
栈的定义和特点
栈的特点:限定插入和删除只能在表的“端点”进行的线性表
栈的特点是只能插入和删除表尾的元素。
数制转换、括号匹配的检测、行编辑程序、迷宫求解、表达式求值、八皇后问题、函数调用、递归调用的实现
存储方式:同一般的线性表的顺序存储结构完全相同。利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,栈底一般在低地址端;另设top指针,指向栈顶元素在顺序栈中的位置。设base指针,指向栈底元素在顺序栈中的位置。
栈(stack)是一个特殊的线性表,限定在一端(通常是表尾)插入和删除操作,LIFO后进先出
可操作的一端称为栈顶Top,不可操作的一端称为栈底Base;插入元素称为入栈PUSH,删除元素称为出栈POP
- 定义:限定只能在表的一端进行插入和删除运算的线性表。
- 逻辑结构:与线性表相同,仍为一对一关系。
- 存储结构:用顺序栈或链栈存储均可,但以顺序栈更为常见。
- 运算规则:只能在栈顶运算,且访问结点时依照后进先出(LIFO)的原则。
- 实现方式:关键是编写入栈和出栈函数,具体实现依据顺序栈或链栈的不同而不同。
与一般的线性表的区别仅在于运算规则不同。
栈抽象数据类型定义
ADT Stack{数据对象: D = { ai | ai ∈ ElemSet, i=1,2,...,n, n>=0 }数据关系:R1 = { <ai-1, ai> | ai-1, ai∈D, i=2,...,n }约定an端为栈顶,a1端为栈底基本操作: 初始化、进栈、出栈、取栈顶元素等;InitStack(&S) 初始化操作操作结果: 构造一个空栈S。DestroyStack(&S) 销毁栈操作初始条件: 栈S已存在。操作结果: 栈S被销毁。StackEmpty(S) 判定S是否为空栈初始条件: 栈S已存在。操作结果: 若栈S为空,则返回TRUE,否则返回FALSE。StackLength(S) 求栈的长度初始条件: 栈S已存在。操作结果: 返回S的元素个数,即栈的长度。GetTop(S,&e) 取栈顶元素初始条件: 栈S已存在且非空。操作结果: 用e返回S的栈顶元素。ClearStack(&S) 栈置空操作初始条件: 栈S已存在。操作结果: 将S清为空栈。Push(&S,e) 入栈操作初始条件: 栈S已存在。操作结果: 插入元素e为新的栈顶元素。Pop(&S,&e) 出栈操作初始条件: 栈S已存在且非空。操作结果: 删除S的栈顶元素an,并用e返回其值。
}ADT Stack
栈的顺序存储(栈)
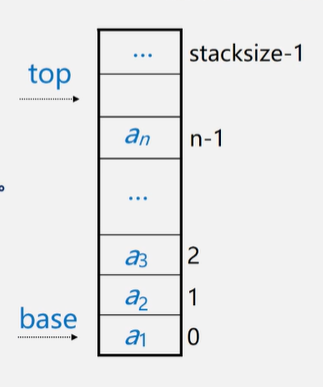
为了方便操作,通常情况下top指针指向的是栈顶元素之上的下表地址。stacksize表示栈可使用的最大容量。
空栈:base==top是栈空标志;空栈继续出栈叫下溢出
栈满:top-base == stacksize;栈满时处理方式:1. 报错返回操作系统2.分配更大的空间,作为栈的存储空间,将原栈移入。
上溢(overflow):栈满还要压入元素,一般认为这是一种错误,使问题的处理无法进行。
下溢(underflow):栈空还要出站,一般认为这是一种结束条件,问题处理的结束。
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 100typedef struct {int key;char data[20];
}SElemType;typedef struct {SElemType *base; // 栈底指针 SElemType *top; // 栈顶指针int stacksize; // 栈可用最大容量
}SqStack;int InitStack(SqStack * S){S->base = (SElemType *)malloc(MaxSize*sizeof(SElemType)); //c++语法 S.base=new int[MaxSize];if (!S->base){exit(0);}S->top = S->base;S->stacksize = MaxSize;return 1;
}int StackEmpty(SqStack S){if (S.top == S.base)return 1;elsereturn 0;
}int StackLength(SqStack S){return S.top - S.base;
}int ClearStack(SqStack * S){if (S->base){S->top = S->base;}return 1;
}int DestroyStack(SqStack * S){if (S->base){free(S->base); // c++语法 delete[] S.base;S->base = NULL;S->base = S->top = NULL;S->stacksize = 0;}return 1;
}int StackPush(SqStack * S, int e){if (S->top - S->base == S->stacksize){ // 上溢return 0;}*S->top++ = e; //*S->top = e;S->top++;return 1;
}int StackPop(SqStack * S, int * e){if (S->top == S->base){ // 下溢return 0;}*e = *--S->top; // S->top--;*e=*S->top;return 1;
}int main(){SqStack S;InitStack(&S);int i;for (i = 0; i < 10; i++){StackPush(&S, i);}printf("length of stack is %d\n", StackLength(S));int e;while (!StackEmpty(S)){StackPop(&S, &e);printf("%d ", e);}printf("\n");DestroyStack(&S);return 0;
}
栈的链式存储(链栈)
链栈是运算受限的单链表,只能在链表头部操作。
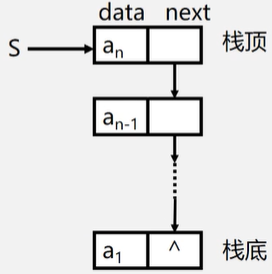
链栈中的指针方向是前趋元素。
- 链表的头指针就是栈顶
- 不需要头节点
- 基本不存在栈满的情况
- 空栈相当于头指针指向空
- 插入和删除仅在栈顶处执行
#include <stdio.h>
#include <stdlib.h>typedef struct StackNode{int data;struct StackNode *next;
}StackNode, *LinkStack;int InitStack(LinkStack *S){S = NULL;return 1;
}int StackEmpty(LinkStack S){if (S == NULL) return 1;else return 0;
}int StackPush(LinkStack *S, int e){StackNode *p = (StackNode *)malloc(sizeof(StackNode)); //生成新结点c++语法p=new StackNodep->data = e; // 将新结点数据域置为ep->next = *S; // 将新结点插入栈顶*S = p; // 修改栈顶指针return 1;
}int StackPop(LinkStack *S, int *e){if (*S == NULL) return 0;StackNode *p = *S;*e = (*S)->data;*S = (*S)->next;free(p);return 1;
}int GetTop(LinkStack S){if (S == NULL) return 0;return S->data;
}
栈的应用
栈用于递归
递归的定义:若对象部分地包含它自己,或则用它自己给自己定义,则称这个对象是递归的;若一个过程直接地或间接地调用自己,则称这个过程是递归的过程。
递归求n的阶乘
long Fact(long n){if (n==0) return 1;else return n * Fact(n-1);
}
常用到的递归方法的情况:
- 递归定义的数学函数:阶乘函数,2阶Fibonaci数列;
- 具有递归特性的数据结构:二叉树(左子树-root-右子树),广义表(A=(a,A));
- 可递归求解的问题:迷宫问题,Hanoi塔问题;
递归问题-用分治法求解:分治法:对于一个较为复杂的问题,能够分解成几个相对简单的且解法相同或类似的子问题来求解。
- 条件一:能将一个问题转变为一个新的问题,且新问题的解决方法与原本问题的解决方法相同,只是处理的对象不同,且处理对象的变化是有规律的。
- 条件二:可同过上述转换使问题简化。
- 条件三:必须有一个明确的递归出口,或称为递归的边界。
分治法求解递归问题算法的一般形式
void p(参数表){if (递归结束条件) 可直接求解步骤; // --基本项else p (较小的参数); // -- 归纳项
}
/////////////////////例子
long Fact(long n){if (n==0) return 1; // --基本项else return n * Fact(n-1); // -- 归纳项
}
复习——函数调用的过程:
调用前,系统完成:
- 将实参,返回地址等传递给被调用函数
- 为被调用函数的局部变量分配存储区
- 将控制转移到被被调用函数的入口
调用后,系统完成:
- 保存被调函数的计算结果
- 释放被调用函数的数据区
- 依照被调用函数保存的返回地址将控制转移到调用函数
递归函数调用的实现:
“层次”:主函数-0层,第一次调用-1层,...,第i次调用-i层
“递归工作栈”:递归程序运行期间使用的数据存储区
“工作记录”:实际参数,局部变量,返回地址。
递归的优缺点:
优点:结构清晰,程序易读。
缺点:每次调用要生成工作记录,保存状态信息,入栈;返回时要出栈,恢复状态信息,时间开销大。
对时间效率要求比较高的时候需要将:
-
尾递归、单项递归-转变为->循环结构
尾递归->循环结构
long Fact(long n){if (n == 0) return 1;else return n * Fact(n-1); } long Fact(long n){int t = 1;for (int i = 1; i <= n; i++)t = t * i;return t; }单项递归->循环结构(单项递归:有一处以上递归调用语句,各调用语句的参数只与主调函数有关,调用语句处于算法最后)
long Fib(long n){if (n == 1 || n == 2) return 1;else return Fib(n - 1) + Fib(n - 2); } long Fib(long n){if (n == 1 || n == 2) return 1;else{int t1 = 1, t2 = 1;for (n = 3; i <= n; i++){t3 = t1 + t2;t1 = t2; t2 = t3;}return t3;} } -
自己用栈模拟系统的运行时栈
递归程序在执行时需要系统提供栈来实现;
仿照递归算法执行过程中递归工作栈的状态变化可写出相应的非递归程序
改写后的非递归算法与原来的递归算法相比,结构不清晰,可读性较差,有的还需要经过一系列优化- 设置一个工作栈存放递归工作记录(包括实参,返回地址及局部变量等)
- 进入非递归调用入口(即被调用程序开始处)将调用程序传来的实在参数和返回地址入栈(递归程序不可以作为主程序,因而可认为初始是被某个调用程序调用)。
- 进入递归调用入口:当不满足递归结束条件时,逐层递归,将实参、返回地址及局部变量入栈,这一过程可用循环语句来实现——模拟递归分解的过程。
- 递归结束条件满足,将到达递归出口的给定常数作为当前的函数值。
- 返回处理:在栈不空的情况下,反复退出栈顶记录,根据记录中的返回地址进行题意规定的操作,即逐层计算当前函数值,直至栈空为止——模拟递归求值过程。
其他案例
-
进制转换:十进制整数转换成d(二,八,十六)进制。
转换法则:除以d进制,得到的余数逆序放置。 -
括号匹配检测:左压右弹,不能交叉,不多不少。
-
表达式求值:利用运算符的优先级来求解表达式。包含有操作数,运算符,界限符。
需要设置两个栈,OPTR用于寄存运算符,OPND用于寄存运算数和运算结果。过程为从左到右扫描表达式的每一个字符
- 当扫描到运算数时压入栈OPND
- 当扫描到是运算符时,若比OPTR栈顶的运算符优先级高,则入栈OPTR,继续向后扫描。
- 当扫描到是运算符时,若比OPTR栈顶的运算符优先级低,则从OPND栈中弹出两个运算数,从栈OPTR中弹出栈顶运算符进行运算,并将运算结果压入栈OPND,再将当前运算符入栈OPTR,继续向后扫描。
- 当扫描到结束符时,弹出OPND栈顶运算数,即为运算结果。
队列
队列的定义和特点
队列的特点:限定插入和删除只能在表的“端点”进行的线性表
队列的特点是只能插入表尾和删除表头元素。
脱机打印、系统排队调用、用户优先级、实时控制信号、电文传递
队列(Queue)是仅在表尾进行插入操作,在表头进行删除操作的线性表。
表尾即an端,称为队尾;表头即a1端,称为队头。这是一种先进先出(FIFO)的线性表。
队列\(Q=(a_1,a_2,a_3,...,a_{n-1},a_n)\),这里的\(a_1\)为队头,\(a_n\)为队尾
插入元素称为入队;删除元素称为出队。
队列的存储结构:链队,顺序队(常用循环顺序队)
队列(queue)是一种特殊的线性表,限定在一端插入(表尾)另一端删除(表头)操作,FIFO先进先出
- 定义:只能在表的一端进行插入运算,在表的另一端进行删除运算的线性表。(头插尾删)
- 逻辑结构:与线性表相同,仍为一对一关系。
- 存储结构:顺序队或链队,以循环顺序队列更常见。
- 运算规则:只能在队首或队尾运算,且访问结点时依照先进先出(FIFO)的原则
- 实现方式:关键是掌握入队和出队操作,具体实现依顺序队或链队的不同而不同
使用有限资源的时候,多个用户使用资源都需要用到队列。
队列抽象数据类型定义
ADT Queue{数据对象: D = { ai | ai ∈ ElemSet, i = 1,2,...,n, n >= 0 }数据关系: R = { <ai-1,ai> | ai-1,ai ∈ D, i = 2,...,n }约定a1端为队头,an端为队尾基本操作:InitQueue(&Q) 初始化操作操作结果: 够造空队列Q。DestroyQueue(&Q) 销毁队列操作初始条件: 队列Q已存在。操作结果: 队列Q被销毁。ClearQueue(&Q) 清空队列初始条件: 队列Q已存在。操作结果: 队列Q清空QueueLength(Q) 求队列长度初始条件: 队列Q已存在操作结果: 返回Q的元素个数,即队长GetHead(Q,&e) 获取队头元素初始条件: 队列Q为非空队列操作结果: 用e返回Q的队头元素EnQueue(&Q,e) 入队操作初始条件: 队列Q已存在操作结果: 插入元素e为Q的队尾元素DeQueue(&Q,&e) 出队操作初始条件: 队列Q为非空队列操作结果: 删除Q的队头元素,用e返回值......还有将队列置空、遍历队列等操作......
}ADT Queue
队列的顺序存储(顺序队列)
当出现rear=MAXQSIZE这样的情况是就发生了溢出
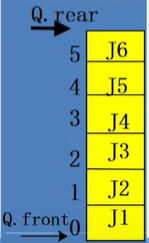 真溢出,front=0,rear=MAXQSIZE
真溢出,front=0,rear=MAXQSIZE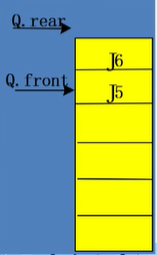 假溢出,front$\ne$0,rear=MAXQSIZE
假溢出,front$\ne$0,rear=MAXQSIZE
解决假溢出情况:
-
将队中元素依次向队头方向移动。(浪费时间,每移动一次,队中所有元素都要移动)
-
将队空间想象为循环的表,这样又可以从头使用空着的空间。若rear+1=MAXQSIZE,则(rear+1)%MAXQSIZE=0;
但是这样引入一个新问题,队空和队满的条件都为front==rear
- 另外设置一个标识区别队空队满
- 另外设置一个变量,记录元素个数
- 少用一个元素,空一格,这样队空为front=rear,队满为(rear+1)%MAXQSIZE=front
#include <stdio.h>
#include <stdlib.h>#define MAXQSIZE 100
typedef int QElemType;typedef struct {QElemType * base; // 初始化的动态分配存储空间int front; // 头指针 静态指针int rear; // 尾指针
}SqQueue;int InitQueue(SqQueue * Q) {Q->base = (QElemType *)malloc(MAXQSIZE * sizeof(QElemType)); // c++语法 Q.base = new QElemType[MAXQSIZE];if (!Q->base) exit(0);Q->front = Q->rear = 0;return 1;
}int QueueLength(SqQueue Q) {return (Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}int EnQueue(SqQueue * Q, QElemType e) {if ((Q->rear + 1) % MAXQSIZE == Q->front) return 0; // 队满Q->base[Q->rear] = e; // 新元素入队Q->rear = (Q->rear + 1) % MAXQSIZE; // 队尾指针+1return 1;
}int DeQueue(SqQueue * Q, QElemType * e) {if (Q->front == Q->rear) return 0; // 队空*e = Q->base[Q->front]; // 队头元素出队Q->front = (Q->front + 1) % MAXQSIZE; // 队头指针+1return 1;
}QElemType GetHead(SqQueue Q) {if (Q.front == Q.rear) return 0; // 队空return Q.base[Q.front]; // 队头元素
}int main(){SqQueue Q;InitQueue(&Q);printf("Q长度为:%d\n",QueueLength(Q));for(int i=1;i<=10;i++){EnQueue(&Q,i);}printf("Q长度为:%d\n",QueueLength(Q));printf("队头元素为:%d\n",GetHead(Q));QElemType e;while(DeQueue(&Q,&e)){printf("%d ",e);}return 0;
}
队列的链式存储(链式队列)
无法估计所用队列的长度,就使用链队列。
 链式队列
链式队列
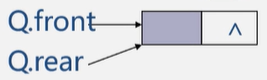 空队列
空队列
 入队后的情况
入队后的情况
#include <stdio.h>
#include <stdlib.h>#define MAXQSIZE 100
typedef int QElemType;typedef struct QNode {QElemType data;struct QNode* next;
}QNode, *QueuePtr;typedef struct {QueuePtr front;QueuePtr rear;
}LinkQueue;int InitQueue(LinkQueue * Q){Q->front = Q->rear = (QueuePtr)malloc(sizeof(QNode));if(!Q->front) exit(0);Q->front->next = NULL;return 1;
}int DestroyQueue(LinkQueue * Q){while (Q->front){Q->rear = Q->front->next; free(Q->front);Q->front = Q->rear;}/*while (Q->front){QNode * p = Q->front;p = Q->front->next;free(Q->front);Q->front = p;}*/return 1;
}int EnQueue(LinkQueue * Q, QElemType e){ // 链式队列要入队在队尾,尾插法QueuePtr p = (QueuePtr)malloc(sizeof(QNode));if(!p) exit(0);p->data = e;p->next = NULL;Q->rear->next = p;Q->rear = p;return 1;
}int DeQueue(LinkQueue * Q, QElemType * e){ // 链式队列要出队在队头,头删法if(Q->front == Q->rear) return 0;QNode * p = Q->front->next;*e = p->data;Q->front->next = p->next;if(Q->rear == p) Q->rear = Q->front;free(p);return 1;
}int GetHead(LinkQueue * Q, QElemType * e){ // 链式队列要取队头元素,头删法if(Q->front == Q->rear) return 0;*e = Q->front->next->data;return 1;
}int main(){LinkQueue Q;InitQueue(&Q);EnQueue(&Q, 1);EnQueue(&Q, 2);EnQueue(&Q, 3);QElemType e;while(GetHead(&Q, &e)){printf("%d ", e);DeQueue(&Q, &e); }return 0;
}
队列的应用
- 舞伴问题:构造两个队列,依次将队头元素出队配成舞伴,若某队为空,则另一队等待,且第一个获得舞伴的人等待时间短
字符串
串是内容受限制的线性表,内容只能是字符。
串的定义和特点
串(String)又叫做字符串,是零个或多个任意字符组成的有限序列
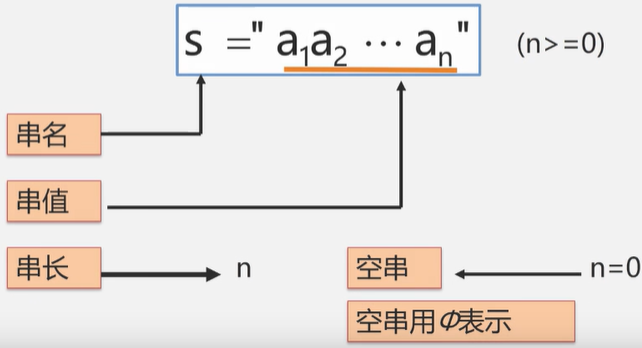 串名,串值,串长,空串的定义
串名,串值,串长,空串的定义
子串:串中任意个连续字符组成的子序列(含空串)称为该串的子串。真子串是指不包含自身的所有子串。
主串:包含子串的串响应的称为主串。
字符位置:字符在序列中的序号为该字符在串中的位置。
子串位置:子串第一个字符在主串中的位置
空格串:由一个或多个空格组成的串,与空串不同
串相等:当且仅当两个串的长度相等并且各位置对应的字符都相等时,这两各串才相等。所有的空串是相等的。
串抽象数据类型定义
ADT String{数据对象: D = { ai | ai ∈ CharacterSet, i = 1,2,...,n, n >= 0 }数据关系: R1 = { <ai-1,ai> | ai-1,ai ∈ D, i = 1,2,...,n }基本操作:StrAssign(&T,chars) 串赋值StrCompare(S,T) 串比较StrLength(S) 求串长Concat(&T,S1,S2) 串连结SubString(&Sub,S,pos,len) 求子串StrCopy(&T,S) 串拷贝StrEmpty(S) 串判空ClearString(&S) 清空串Index(S,T,pos) 子串的位置(重点)Replace(&S,T,V) 串替换StrInsert(&S,pos,T) 子串插入StrDelete(&S,pos,len) 子串删除DestroyString(&S) 串销毁初始条件: 操作结果:
}ADT String
串的顺序存储(顺序串)
#define MAXLEN 255
typedef struct{char ch[MAXLEN+1]; // 存储串的一维数组,静态分配 0~255的下表,只使用1~255下表,0弃用,可使得算法简化。int length; // 串的当前长度
}SString;串的链式存储(块链)

优点:操作方便,存储密度较低,存储密度=\(\frac{串值所占的存储}{实际分配的存储}\)
解决存储密度较低的方法是:一个结点中存放多个字符,在串中一个结点称为块。

#define CHUNKSIZE 80 // 定义块的大小
typedef struct Chunk{char ch[CHUNKSIZE];struct Chunk *next;
}Chunk;typedef struct {Chunk *head,*tail; // 串的头指针和尾指针int curlen; // 串的当前长度
}LString; // 字符串的块链结构
串的应用
串的模式匹配算法:确定主串中所含子串(模式串)第一次出现的位置(定位)(搜索引擎、拼写检查、语言翻译、数据压缩)
BF算法
BF算法(Brute-Force,又称古典的、朴素的、穷举的)简单匹配法
主串:正文串,子串:模式串
主串设置指针i,子串设置指针j,同向进行匹配,匹配失败i=i-j+2,j=1。匹配成功的条件是j=NULL。返回位置为i-t.length。
将主串的第一个pos个字符和模式串的第一个字符比较,
若相等,继续逐个比较后续字符;
若不等,从主串的下一个字符起,重新与模式串的第一个字符比较。
static int
Index_BF(SString S, SString T, int pos) // 下标从pos开始,pos=1时从头开始
{int i = pos, j = 1;while (i <= S.length && j <= T.length)//时间复杂度最好情况O(n+m),最坏情况O(n*m),平均情况下为O(n*m){if (S.ch[i] == T.ch[j]) // 主串和子串依次匹配下一个字符{i++;j++;}else{ // 主串、子串指针回溯重新开始下一次匹配i = i - j + 2;j = 1;}}if (j > T.length)return i - T.length; // 匹配成功返回第一个字符的下表elsereturn 0; // 模式匹配不成功
}
KMP算法
KMP算法是由三个大佬共同提出的,算法比BF算法有较大的改进,算法效率提高。
主要优化:主串i指针不再回溯,子串j指针不从1开始回溯,时间复杂度提高到了O(n+m)
KMP算法需要对子串(模式串)先计算出next集,根据next集设置j指针回溯位置。
\(next[j]=\begin{cases} max\{k|1<k<j,且"p_1,...,p_{k-1}"="p_{j-k+1},...,p_{j-1}"\} & 当此集合非空时 \\ 0 & 当j=1时 \\ 1 & 其他情况 \end{cases}\)
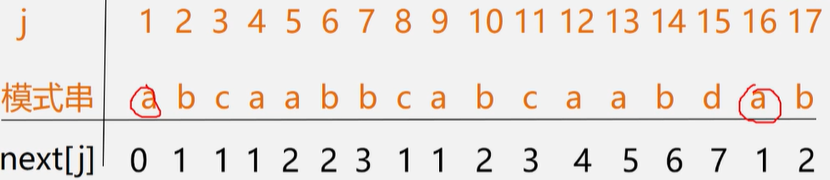
static int
get_next(SString T, int next[])
{next[1] = 0;int j = 1, k = 0;while (j < T.length){if (k == 0 || T.ch[j] == T.ch[k]){j++;k++;next[j] = k;}else{k = next[k];}}return 1;
}static int
Index_KMP(SString S, SString T, int pos)
{int i = pos, j = 1;int next[MAXLEN] = {0};get_next(T, next);// 这里没有完全明白,为什么视频没有加等号,可能设置的length都+1了while (i <= S.length && j <= T.length){if (j == 0 || S.ch[i] == T.ch[j]){i++;j++;}else{j = next[j];}}if (j > T.length)return i - T.length;elsereturn 0;
}
改进KMP算法
改进KMP算法:KMP算法+nextval值
- 第一位的nextval值必定为0,第二位如果于第一位相同则为0,如果不同则为1
- 第三位的next值为1,那么将第三位和第一位进行比较,相同,则第三位的nextval值为第一个位的next值,为0
- 第四位的next值为2,那么将第四位和第二位进行比较,不同,则第四位的nextval值位其next值,为2
- 第五位的next值为2,那么将第五位和第二位进行比较,相同,第二位的next值位1,则继续将第二位与第一位进行比较,不同,则第五位的nextval值为第二位的next值,为1
- 第六位的next值为3,那么将第六位和第三位进行比较,不同,则第六位的nextval值为其next值,为3
- 第七位的next值为1,那么将第七位和第一位进行比较,相同,则第七位的nextval值为0
- 第八位的next值为2,那么将第八位和第二位进行比较,不同,则第八位的nextval值位其next值,为2
static int
get_nextval(SString T, int nextval[])
{int i = 1, j = 0;nextval[1] = 0;while (i < T.length){if (j == 0 || T.ch[i] == T.ch[j]){i++;j++;if (T.ch[i] != T.ch[j])nextval[i] = j;elsenextval[i] = nextval[j];}else{j = nextval[j];}}
}
static int
Index_KMP(SString S, SString T, int pos)
{int i = pos, j = 1;int nextval[MAXLEN] = {0};get_nextval(T, next);// 这里没有完全明白,为什么视频没有加等号,可能设置的length都+1了while (i <= S.length && j <= T.length){if (j == 0 || S.ch[i] == T.ch[j]){i++;j++;}else{j = nextval[j];}}if (j > T.length)return i - T.length;elsereturn 0;
}
数组
数组是线性表的推广,内容可以是另一个数组。
数组的定义和特点
数组:按一定格式排列起来的,具有相同类型的数据元素的集合。
一维数组:若线性表中的数据元素为非结构的简单元素,则称为一维数组。
一维数组的逻辑结构:线性结构。定长的线性表
声明格式:数据类型 变量名称[长度];,例如:int num[5]={0,1,2,3,4};
二维数组:若一维数组中的数据元素又是一维数组结构,则称为二维数组。
二维数组的逻辑结构:\(\begin{cases} 非线性结构 & 每一个数组元素即在行表中,又在列表中\\ 线性结构(定长的线性表) & 该线性表的每个数据元素也是一个定长的线性表 \end{cases}\)
声明格式:数据类型 变量名称[行数][列数];,例如:int num[5][8];
在c语言当中可以使用typedef elemtyper array1[n]; typedef array1 array2[m];这样就定义了n个一维元素的m个二维数组。
三维数组:若二维数组中的元素又是一个一维数组,则称作三维数组。
n维数组:若n-1维数组中的元素又是一个一维数组结构,则称作n维数组。
结论:线性表结构是数组结构的一个特例,数组结构是线性表结构的扩展。
数组特点:结构固定——定义后,维度和维界不再改变。
数组基本操作:除了结构的初始化和销毁之外,只有取元素和修改元素值的操作。
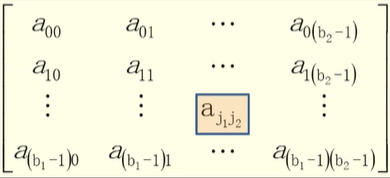
数组抽象数据类型定义
n维数组的抽象数据类型
ADT Array{数据对象:Ji=0,...,bi-1,i=1,2,...,nD = { aj1j2..jn | aj1j2...jn ∈ ElemSet }数据关系:R1 = { <aj1...ji...jn, aj1...ji+1...jn> | 0 <= jk <= bk - 1, 且k ≠ i, 0 <= ji <= bk - 2, aj1...ji...jn,aj1...ji+1...jn ∈ D, i = 2,...n }基本操作:InitArray(&A, n, bound1, ..., boundn) 构造数组A DestroyArray(&A) 销毁数组AValue(A, &e, index1, ..., indexn) 取数组元素值Assign(A, &e, index1, ..., indexn) 给数组元素赋值初始条件: 操作结果:
}ADT Array2维数组的抽象数据类型
n=2(维数为2,二维数组),b1第一维长度(行数),b2第二维长度(列数),
aj1j2:第一维下表为j1,第二维下标为j2。
ADT Array{数据对象:D = { aij | 0 <= j1 <= b1 - 1, 0 <= j2 <= b2 - 1 }数据关系:R = { ROW, COL }ROW = { <aj1,j2, aj1+1,j2> | 0 <= j1 <= b1 -2, 0 <= j2 <= b2 - 1 }COL = { <aj1,j2, aj1,j2+1> | 0 <= j1 <= b1 -1, 0 <= j2 <= b2 - 2 }
}ADT Array
数组的顺序存储
数组特点:结构固定——维数和维界不变。
数组的基本操作:初始化、销毁、取元素、修改元素怒值。一般不做插入和删除操作。
数组一般情况下采用顺序存储。
一维数组存储,求第i个元素的位置,每个元素站用L字节,\(\begin{cases} LOC(i)=a & i = 0 \\ LOC(i-1)+L = a+i*L & i>0\end{cases}\)
二维数组存储,两种顺序存储方式
-
以行序为主序(低下表优先)C、JAVA、BASIC。COBOL和PASCAL
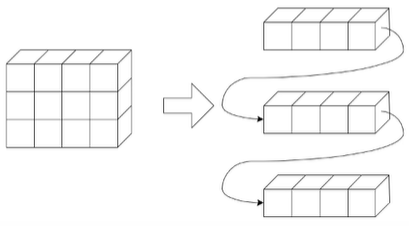
数据元素a[i][j]的存储位置是:LOC(i,j) = LOC(0,0)+(n*i+j)*L
-
以列序为主序(高下标优先)FORTRAN

解决存储单元是一维结构,而数组是多维结构,则用连续存储单元存放数组的数据元素就有个次序约定问题
三维数组\(i_1,i_2,i_3\)元素的存储位置:\(LOC(i_1,i_2,i_3) = a+i_1\times m_2 \times m_3 + i_2 \times m_3 +i_3\)
n维数组\(i_1,i_2,...,i_n\)元素的存储位置:\(LOC(i_1,i_2,...,i_n)= a+ i_1\times m_2\times m_3\times ... \times m_n+ i_2\times m_3\times m_4\times ... \times m_n+ ...+ i_{n-1}\times m_n+ i_n=a+(\sum_{j=1}^{n-1}i_j \times \prod_{k=j+1}^nm_k)+i_n\)
数组的链式存储
通常情况下不使用链式存储,只在特殊区域使用。
使用的方法有:三元法,十字链表法等
数组的应用
特殊矩阵的压缩存储
矩阵:一个由\(m\times n\)个元素排列成的m行n列的表。
矩阵的常规存储:将矩阵描述为一个二维数组。
矩阵的常规存储特点:可对元素进行随机存取,矩阵运算简单,存储密度为1。
不适宜常规存储的矩阵:值相同的元素很多且呈某种规律分布;零元素多。
矩阵压缩存储:为多个相同的非零元素怒只分配一个存储空间;对零元素不分配空间。
对称矩阵
对称矩阵上下三角中的元素均为:\(n(n+1)/2\)
使用以行序为主序将元素存放在一个一维数组\(sa[n(n+1)/2]\)中。
主要是求解\(a_{ij}\)的下标\(k\)为几,\(k=1+2+...+(i-1)+j=\frac{i^2-i}2+j\)
三角矩阵
对角线以下(或以上)的数据元素(不包括对角线)全部为常数C。
占用n(n+1)/2+1个元素,空间:sa[n(n+1)/2+1]
上三角矩阵:\(k=\begin{cases} \frac{(i-1)\times(2n-i+2)}2+j-i+1 & i\le j \\ \frac{n(n+1)}2+1 & i>j \end{cases}\)
下三角矩阵:\(k=\begin{cases} \frac{i\times(i-1)}2+j & i\ge j \\ \frac{n(n+1)}2+1 & i<j \end{cases}\)
对角矩阵(带状矩阵)
元素只存在以主对角线为中心的带状区域中,区域外的值为0,称为对角矩阵。
三条对角线的对角矩阵称为三对角矩阵。
以主对角线的长度为存储长度。
以五对角线为例:
占用5n个元素,空间:sa[5n]
计算\(k= \begin{cases} (5-1)/2n+(j-i)n+j & i < j \\ (5-1)/2n+i & i=j \\ (5-1)/2n+(j-i)n+j & i > j \end{cases}\)
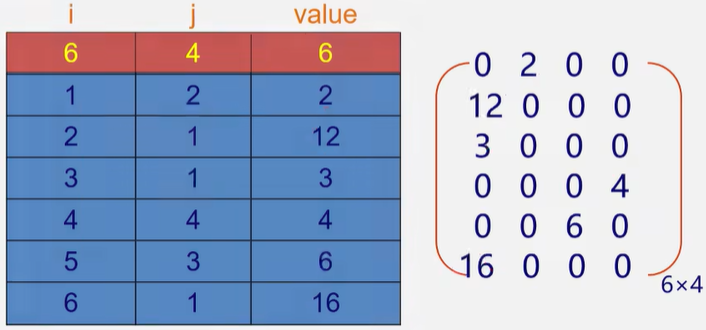
稀疏矩阵
稀疏矩阵:设在\(m\times n\)的矩阵中有t个非零元素,令\(\sigma=\frac t{m\times n}\le0.05\)时称为稀疏矩阵。
-
三元组法:三元组顺序表又称有序的双下标法,使用三元组\((i,j,a_{ij})\)来表示稀疏矩阵当中的元素。
压缩存储原则:存各非零元素的值、行列位置和矩阵的行列数。三元组的不同表示方法可决定稀疏矩阵不同的压缩存储方法。通常在存储三元组时下标为0的三元组存储\((总行数,总列数,非零元素总个数)\)
三元组顺序标的优点:非零元素在表中按行序有序存储,便于进行依行顺序处理的矩阵运算。
三元组顺序表的缺点:不能随机存取。若按行号存取某一行中的非零元素,则需要从头开始进行查找。
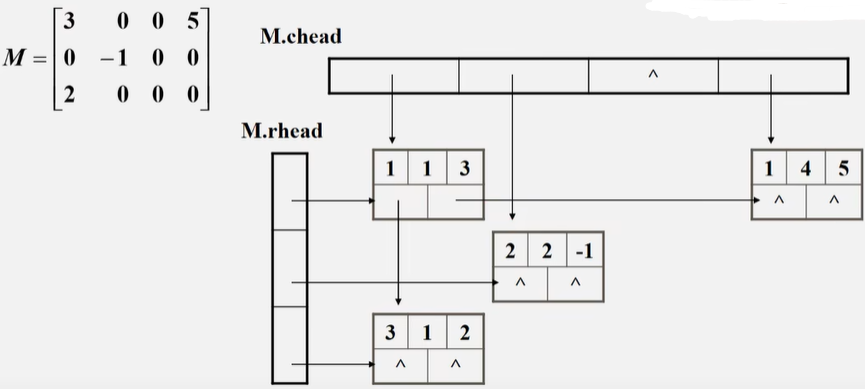
-
十字链表:链式存储结构
优点:能灵活地插入因运算而产生的新的非零元素,删除因运算而产生的新的零元素,实现矩阵的各种运算。
在十字链表中,矩阵的每一个非零元素用一个结点表示,结点为\((row,col,value,down,right)\)
需要设置行头指针数组和列头指针数组。
广义表
广义表也是线性表的推广,内容可以是另一个广义表。
严格来说数组和广义表是非线性结构。
广义表的定义和特点
广义表(又称列表Lists):是\(n\ge0\)个元素\(a_0,a_1,...,a_{n-1}\)的有限序列,其中每一个\(a_i\)是原子或则是一个广义表
线性表当中的元素都是同样类型的单一元素,但是广义表中可以是不同的类型
广义表通常记作:\(LS = (a_1,a_2,...,a_n)\),其中LS为表名,n为表的长度,每一个\(a_i\)为表的元素。习惯上,大写字母表示广义表,小写字母表示原子。
表头:若LS非空(\(n\ge1\)),则其第一个元素\(a_1\)就是表头。记作\(head(LS)=a_1\)。表头可以是原子也可以是子表。
表尾:除表头外的其他元素组成的表。记作\(tail(LS)=(a_2,...,a_n)\)。表尾不是最后一个元素,而是一个子表。
举例子: A = () 空表,长度为0。
B=(()) 长度为1,表头、表尾均为()
C=(a,(b,c)) 长度为2,表头为a,表尾为((b,c))
D=(x,y,z) 长度为3,表头为x,表尾为(y,z)
E=(C,D) 长度为2,表头为C,表尾为(D)
F=(a,F) 长度为2,表头为a,表尾为(F)
广义表通常使用链式存储
广义表的特点
-
广义表中的数据元素有相对次序;一个直接前趋和一个直接后继
-
广义表的长度定义:为最外层所包含元素的个数
-
广义表的深度定义:为该广义表展开后所含括号的重数;原子深度为0,空表深度为1。
-
广义表可以为其他广义表共享;
-
广义表可以是一个递归的表;长度有限,深度无穷。
-
广义表是一个多层次的结构,广义表的元素可以是单元素,也可以是子表,而子表的元素还可以是子表。
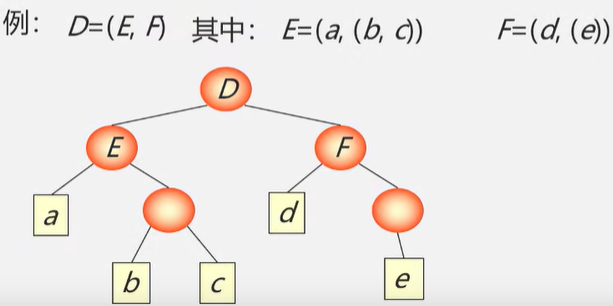
广义表与线性表的区别
广义表可以堪称是线性表的推广,线性表还是广义表的特例。
广义表在某种前提下,可以兼容线性表、数组、树和有向图等常用的数据结构
当二维数组的每行(或每列)作为子表处理时,二维数组即为一个广义表。
广义表抽象数据类型定义
ADT GeneralizedList(广义表){数据对象:D = { ai | ai ∈ ElementSet, i = 1,2,...,n, n >= 0 }数据关系:R = { <ai-1, ai> | ai-1, ai ∈ D, i = 2,...,n }约定a1为广义表的头部,an为广义表的尾部基本操作:InitGeneralizedList(&L) 初始化操作操作结果: 构造一个空的广义表L。DestroyGeneralizedList(&L) 销毁广义表操作初始条件: 广义表L已存在。操作结果: 广义表L被销毁。ClearGeneralizedList(&L) 清空广义表初始条件: 广义表L已存在。操作结果: 广义表L被清空。GeneralizedListLength(L) 求广义表长度初始条件: 广义表L已存在。操作结果: 返回L的元素个数,即广义表的长度。GetHead(L, &h) 获取广义表头部元素初始条件: 广义表L为非空。操作结果: 用h返回L的头元素。EnGeneralizedList(&L, h) 入广义表操作初始条件: 广义表L已存在。操作结果: 将元素h插入到L的尾部,作为新的尾元素。DeGeneralizedList(&L, &h) 出广义表操作初始条件: 广义表L为非空。操作结果: 删除L的头元素,并用h返回其值。......还有将广义表置空、遍历广义表等操作......
}ADT GeneralizedList
广义表的应用
广义表的基本运算
- 求表头GetHead(L):非空广义表的第一个元素,可以是一个原子也可以是一个子表。
- 求表尾GetTail(L):非空广义表除去表头元素以外其它元素所构成的表,表尾一定是一个表
树型结构
结点直接有分支,具有层次关系
常用于:树,家谱,行政机构,用树表示源程序的语法结构,用树组织信息,用树描述执行过程。
树的定义和特点
树(Tree)是n(\(n\ge0\))个结点的有限集。树的定义是一个递归的定义。
若$n=0$,称为<span data-type="text" style="background-color: var(--b3-card-error-background); color: var(--b3-card-error-color);">空树</span>;若n>0,则它满足如下条件1. 有且仅有一个根(root)结点;2.其余结点可分为m($m\ge0$\)个互不相交的有限集T1,T2,...,Tm,每一个集合本身又是树,并称为根的子树(SubTree)。
树还可以使用嵌套集合进行表示,凹入表示,广义表。
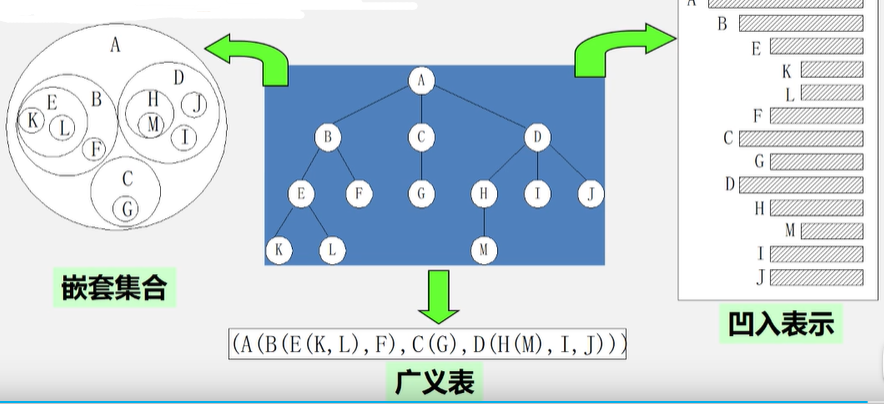
树的基本术语
结点:数据元素以及指向子树的分支。
根结点:非空树中无前驱结点的结点。
结点的度:结点拥有的子树数。A结点的度为3,B结点的度为2,K结点的度为0;
树的度:树内部各结点的度的最大值。
当结点的度为0时,称为叶子结点(终端结点)
当结点的度不为0时,称为分支结点(非终端结点,内部结点)
结点的子树的根称为该结点的孩子,该节点称为孩子的双亲。
堂兄弟:双亲在同一层的结点。
树的深度:树中结点的最大层次。。
有序树:树中结点的各子树从左至右有次序(最左边的为第一个孩子)。
无序树:树中结点的各子树无次序。
森林:是m(\(m\ge0\))棵树互不相交的树的集合,一棵树的一个特殊的森林。树一定是森林,森林不一定是树。
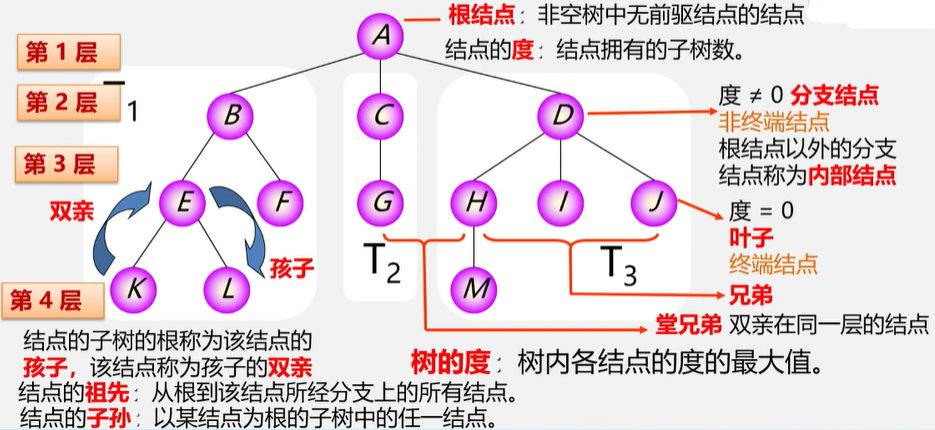
树结构和线性结构的比较
| 线性结构 | 树结构 | ||
|---|---|---|---|
| 第一个数据元素 | 无前趋 | 根结点(只有一个) | 无双亲 |
| 最后一个数据元素 | 无后继 | 叶子结点(可以有多个) | 无孩子 |
| 其他数据元素 | 一个前趋一个后继 一对一 |
其他结点——中间结点 | 一个双亲,多个孩子 一对多 |
二叉树的定义
普通树(多叉树)若不转换成二叉树,则运算比较复杂很难实现。
任何树都能转为唯一对应的二叉树,不失一般性。这样就解决了树的存储结构以及运算中存在的复杂性。
二叉树是n(\(n\ge0\))个结点的有限集,空集(n=0)或者由一个根节点及两棵互不相交的树(这个根的左子树和右子树)的二叉树构成
特点:
- 每个结点最多有两孩子(二叉树中不存在度大于2的结点)。
- 子树有左右之分,次序不能颠倒。
- 二叉树可以是空集合,根可以有空的左子树或空的右子树。
- 二叉树不是树的特殊情况,二叉树需要分左右子树,树不需要区分左右次序。
二叉树抽象数据类型定义
ADT BinaryTree{数据对象D:D是具有相同特性的数据元素的集合。数据关系R:若D=空集,则R=空集;若D非空,则R={H};H是如下二元关系:① root唯一 // 关于根的说明② Dj ∩ Dk = 空集 // 关于子树不相交的说明③ .... // 关于数据元素的说明④ .... // 关于左子树和右子树的说明基本操作P: // 至少20个操作CreateBiTree(&T,definition) 二叉树创建初始条件: definition给出二叉树T的定义。操作结果: 按definition构造二叉树T。PreOrderTraverse(T) 前序遍历初始条件: 二叉树T存在。操作结果: 先序遍历T,对每个结点访问一次。InOrderTraverse(T) 中序遍历初始条件: 二叉树T存在。操作结果: 中序遍历T,对每个结点访问一次。PostOrderTraverse(T) 后续遍历初始条件: 二叉树T存在。操作结果: 后续遍历T,对每个结点访问一次。
}ADT BinaryTree
二叉树的性质
-
在二叉树的第i层上至多有\(2^{i-1}\) 个结点(\(i\ge1\)),第i层至少有1个结点。
-
深度为k的二叉树至多有\(2^k-1\) 个结点(\(k\ge1\)),深度为k时至少有k个结点。
-
对任何一颗二叉树T,叶子数\(n_0\),度为2的结点数\(n_2\),度为1的结点数\(n_1\),总边数B,总结点数n,
\(n_0=n_2+1\\ B=n-1=n_2\times2+n_1\times1\\ n=n_2\times2+n_1\times1+1=n_2+n_1+n_0\) -
满二叉树
在顺序存储方式下可以复原
一棵树深度为k且有\(2^k-1\)个结点的二叉树称为满二叉树
特点:每一层上的节点树都是最大结点树,叶子结点全部在最底层
对满二叉树编号需要从上到下,从左到右。
-
完全二叉树
在顺序方式存储下可以复原
深度为k的具有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号为1~n的结点一一对应时,称为完全二叉树
对满二叉树从最后一个结点开始,连续的去掉任意个结点,即为一棵完全二叉树。
特点:叶子只可能分布在层次最大的两层上。对任一结点,如果其右子树最大层为i,则左子树的最大层次必为i或i+1。
满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
-
具有n个结点的完全二叉树的深度为$\lfloor\log_2n\rfloor+1 \(,这里\)\lfloor x\rfloor$:称为x的底,表示不大于x的最大整数
这一性质表明完全二叉树结点数n与完全二叉树深度k之间的关系。
-
如果对一棵有n结点的完全二叉树(深度为$\lfloor\log_2n\rfloor+1 \()的结点按层序编号(从第1层到第\)\lfloor\log_2n\rfloor+1 \(层,每层从左到右),则对任一结点\)i(1\le i \le n)$,有:
- 如果\(i=1\),则结点\(i\)是二叉树的根,无双亲;如果\(i>1\),则其双亲是结点$\lfloor\frac i2\rfloor $。
- 如果\(2i>n\),则结点\(i\)为叶子结点,无左孩子;否则其左孩子是结点\(2i\)。
- 如果\(2i+1>n\),则结点\(i\)无右孩子;否则,其右孩子是结点\(2i+1\)。
这一性质表明完全二叉树中双亲结点编号与孩子结点编号之间的关系。
二叉树的顺序存储
按满二叉树的结点层次编号,一次存放二叉树中的数据元素
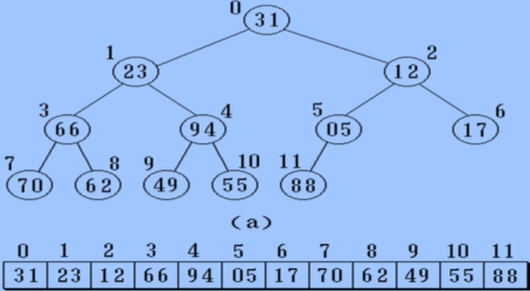
//二叉树顺序存储表示
#define MAXTSIZE 100
typedef TElemType SqBiTree[MAXTSIZE]
SqBiTree bt;
二叉树最坏的存储情况
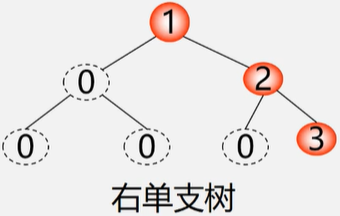 空间密度为\(\frac37\)
空间密度为\(\frac37\)
特点:结点关系蕴含在其存储位置中。浪费空间,使用于满二叉树和完全二叉树
二叉树的链式存储
二叉链表
typedef struct BiNode{TElemType data;struct BiNode *lchild, *rchild; // 左右孩子指针
}BiNode, *BiTree
在n个结点的二叉链表中,有n+1个空指针域。
三叉链表
typedef struct TriTNode{TelemType data;struct TriTNode *lchild, *parent, *rchild;
}TriTNode, *TriTree;
二叉树的应用
遍历二叉树
遍历定义:顺着某一条搜索路径访问二叉树中的结点,使得每个结点均被访问一次,而且仅被访问一次
遍历目的:得到树中所有结点的一个线性排列。
遍历用途:它是树结构插入、删除、修改、查找和排序运算的前提,是二叉树一切运算的基础和核心。
遍历方法:L遍历左子树,D访问根结点,R遍历右子树
- DLR——先(根)序遍历
- LDR——中(根)序遍历
- LRD——后(根)序遍历
- DRL
- RDL
- RLD
| 先序遍历二叉树 | 中序遍历二叉树 | 后续遍历二叉树 |
|---|---|---|
| 若二叉树为空,则空操作 | 若二叉树为空,则空操作 |
若二叉树为空,则空操作 |
| 访问根结点 | 中序遍历左子树 | 后续遍历左子树 |
| 先序遍历左子树 | 访问根结点 | 后续遍历右子树 |
| 先序遍历右子树 | 中序遍历右子树 | 访问根结点 |
根据遍历确定二叉树
先序和中序遍历,或后序和中序遍历,可以确定唯一一棵二叉树。
先序:ABCDEFGHIJ
中序:CDBFEAIHGJ
二叉树: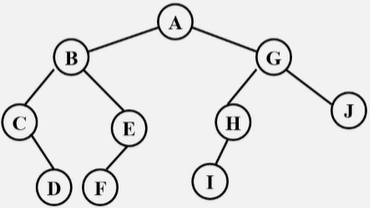
遍历算法实现
时间复杂度:O(n)
空间复杂度:O()
- 先序遍历(其他遍历只需要修改执行次序即可)
Status PreOrderTraverse(BiTree T){if (T == NULL) return OK; // 空二叉树else{ visit(T); // 访问根节点PreOrderTraverse(T->lchild); // 递归遍历左子树,这里系统开了一个栈,用于记录路过但没访问的结点PreOrderTraverse(T->rchild); // 递归遍历右子树}
}
- 中序遍历
Status InOrderTraverse(BiTree T){if (T == NULL) return OK; // 空二叉树else{ InOrderTraverse(T->lchild); // 递归遍历左子树visit(T); // 访问根节点InOrderTraverse(T->rchild); // 递归遍历右子树}
}
- 后续遍历
Status InOrderTraverse(BiTree T){if (T == NULL) return OK; // 空二叉树else{ InOrderTraverse(T->lchild); // 递归遍历左子树InOrderTraverse(T->rchild); // 递归遍历右子树visit(T); // 访问根节点}
}
这三种算法访问路径是相同的,只是访问结点的时机不同。每个结点都被访问了3次。
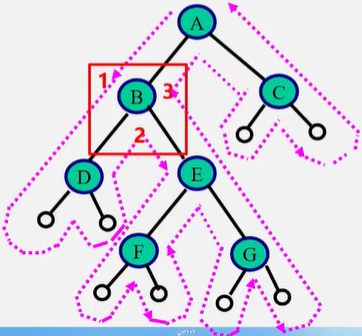 1处访问结点为先序,2处访问结点为中序,3处访问结点为后续。
1处访问结点为先序,2处访问结点为中序,3处访问结点为后续。
非递归遍历算法实现
#include <stdio.h>
#include <stdlib.h>#define MAXSIZE 100
typedef char TElemType;typedef struct BiTNode {TElemType data;struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;typedef struct{BiTNode *base;BiTNode *top;int stacksize;
}SqStack;int InitStack(SqStack *S){S->base = (BiTNode *)malloc(sizeof(BiTNode) * MAXSIZE);if(!S->base) exit(0);S->top = S->base;S->stacksize = MAXSIZE;return 1;
}int StackEmpty(SqStack S){if (S.top == S.base)return 1;elsereturn 0;
}int StackPush(SqStack * S, BiTNode e){if (S->top - S->base == S->stacksize){ // 上溢return 0;}*S->top++ = e; //*S->top = e;S->top++;return 1;
}int StackPop(SqStack * S, BiTree e){if (S->top == S->base){ // 下溢return 0;}*e = *--S->top; // S->top--;*e=*S->top;return 1;
}// 创建二叉树
int CreateBiTree(BiTree *T){TElemType ch;scanf("%c", &ch);if(ch == '#')return NULL;if ( !(T = (BiTree)malloc(sizeof(BiTNode))) )exit(OVERFLOW);T->data = ch;CreateBiTree(T->lchild);CreateBiTree(T->rchild);return T;
}// 中序遍历 -- 递归
int InOrderTraverseRec(BiTree T){if(T == NULL)return 0;PreOrderTraverse(T->lchild);printf("%c ", T->data);PreOrderTraverse(T->rchild);return 1;
}// 中序遍历 -- 非递归(使用栈存储)
int InOrderTraverse(BiTree T){SqStack S;InitStack(&S);BiTree p = T;BiTNode q;while(p || !StackEmpty(S)){if(p){StackPush(&S, *p);p = p->lchild;}else{StackPop(&S, &q);printf("%c ", q.data);p = q.rchild;}}return 1;
}int main(){BiTree T = CreateBiTree();InOrderTraverse(T);return 0;// 输入:ABD##E##CF##G###// 输出:D B E A F C G
}
层次遍历算法
使用队列进行遍历计算
#include <stdio.h>
#include <stdlib.h>#define MAXSIZE 100
typedef char ElemType;typedef struct BiTree
{ElemType data;struct BiTree *lchild, *rchild;
} BiTNode, *BiTree;typedef struct
{BiTree data[MAXSIZE]; // 存放队中元素int front, rear; // 队头指针和队尾指针
} SqQueue; // 顺序循环队列类型// 初始化队列
void InitQueue(SqQueue *Q)
{Q->front = 0;Q->rear = 0;
}// 判断队列是否为空
int QueueEmpty(SqQueue Q)
{return Q.front == Q.rear;
}// 入队
int EnQueue(SqQueue *Q, BiTree e)
{if ((Q->rear + 1) % MAXSIZE == Q->front){printf("队列已满,无法入队。\n");return NULL;}Q->data[Q->rear] = e;Q->rear = (Q->rear + 1) % MAXSIZE;
}// 出队
BiTree DeQueue(SqQueue *Q)
{if (Q->front == Q->rear){printf("队列为空,无法出队。\n");return NULL;}BiTree e = Q->data[Q->front];Q->front = (Q->front + 1) % MAXSIZE;return e;
}// 层序遍历
void LevelOrderTraversal(BiTree T)
{SqQueue Q;InitQueue(&Q);EnQueue(&Q, T);while (!QueueEmpty(Q)){BiTree p = DeQueue(&Q);printf("%c ", p->data);if (p->lchild)EnQueue(&Q, p->lchild);if (p->rchild)EnQueue(&Q, p->rchild);}
}// 创建二叉树
BiTree CreateBiTree()
{ElemType ch;BiTree T;scanf("%c", &ch);if (ch == '#'){return NULL;}else{T = (BiTNode *)malloc(sizeof(BiTNode));T->data = ch;T->lchild = CreateBiTree();T->rchild = CreateBiTree();}return T;
}int main()
{BiTree T = CreateBiTree();LevelOrderTraversal(T);return 0;
}
复制二叉树
int Copy(BiTree T,BiTree *NewT){if (T==NULL){ // 如果是空树则返回0NewT = NULL;return 0;}else{NewT = (BiTree )malloc(sizeof(BiTNode));NewT->data = T->data;Copy(T->lchild, NewT->lchild);Copy(T->rchild, NewT->rchild);}
}
计算二叉树深度
int Depth(BiTree T){if ( T == NULL )return 0;else{m = Depth(T->lchild);n = Depth(T->rchild);if ( m > n )return (m+1);elsereturn (n+1);}}
计算结点总数
int NodeCount(BiTree T){if ( T == NULL )return 0;elsereturn NodeCount(T->lchild) + NodeCount(T->rchild) + 1;
}
计算叶子结点个数
int LeafCount(BiTree T){if (T==NULL)return 0;if (T->lchild == NULL && T->rchild == NULL)return 1;elsereturn LeafCount(T->lchild) + LeafCount(T->rchild)
}
线索二叉树
寻找特定遍历序列中二叉树结点的前趋和后继
利用二叉链表结点的空指针域,左孩子指针域为空,将这个指针域指向前趋,右孩子指针域为空,将这个指针域指向后继。
这种改变指向的指针称为线索。
将正常的二叉树变为线索二叉树,这个过程称为线索化。
增加两个标志域:ltag=0(指向孩子),rtag=1(指向线索)
typedef struct BiThrNode{int data;int ltag, rtag;struct BiThrNode *lchild, *rchild;
}BiThrNode, *BiThrTree;// 先序线索二叉树
为了避免空域,增加一个头节点(左孩子ltag=0,指向根结点;右孩子rtag=1,指向遍历的最后一个结点)
线索二叉树中,左孩子为空或者右孩子为空的结点,指针域指向头结点。这样就把二叉树设置成循环链表。
树和森林的定义和特点
树:树是n()个结点的右限集。
若n=0,则称为空树;
若n>0,则有且仅有一个特定的根结点,其余结点可分为m()个互不相交的有限集。
森林:森林是m()棵互不相交的树的集合。
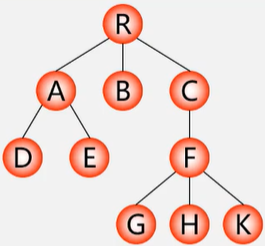
树的顺序存储(双亲表示法)
实现定义结构数组存放树的结点,每个结点含两个域(数据域和双亲域);
数据域:存放结点本身信息。
双亲域:指示本结点的双亲结点在数组中的位置。
特点:找双亲容易,找孩子难
| 地址 | 存储数据 | 双亲地址 |
|---|---|---|
| 0 | R | -1 |
| 1 | A | 0 |
| 2 | B | 0 |
| 3 | C | 0 |
| 4 | D | 1 |
| 5 | E | 1 |
| 6 | F | 3 |
| 7 | G | 6 |
| 8 | H | 6 |
| 9 | K | 6 |
typedef struct PTNode{TElemType data;int parent; // 双亲位置域
}PTNode;# define MAX_TREE_SIZE 100
typedef struct {PTNode nodes[MAX_TREE_SIZE];int r;int n; // 根结点的位置和结点数
}PTree
树的链式存储(孩子链表表示法)
特点:找孩子容易,找双亲难。
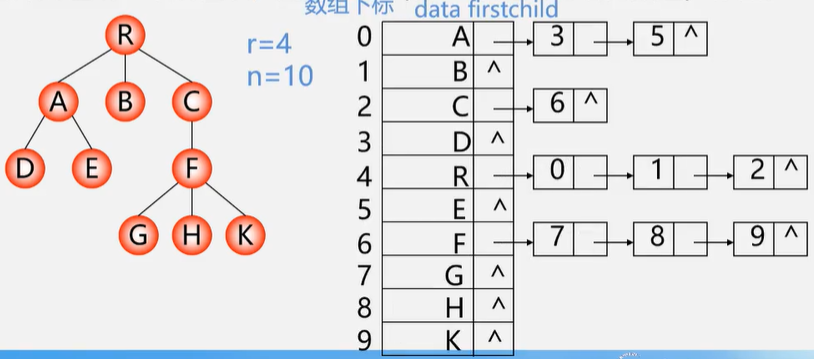
typedef struct CTNode{ // 孩子链表结构int child;struct CTNode *next;
}*ChildPtr;typedef struct { // 结点表元素TElemType data;ChildPtr firstchild; // 孩子链表头指针
}CTBox;typedef struct { // 数结构CTBox nodes[MAX_TREE_SIZE];int n,r; // 结点数和根结点的位置
}CTree;
树的链式存储2(带双亲的孩子链表表示法)
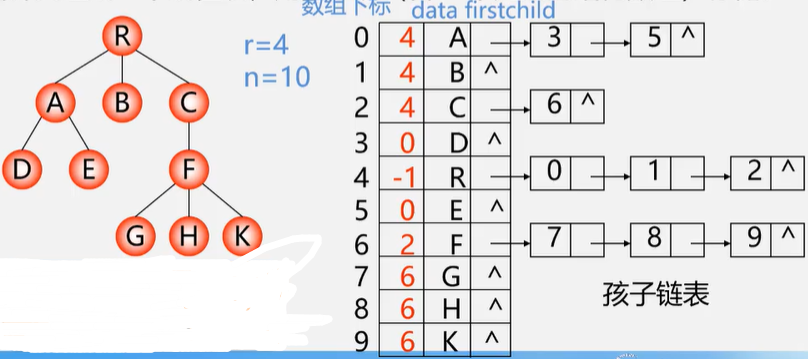
typedef struct CTNode{ // 孩子链表结构int child;struct CTNode *next;
}*ChildPtr;typedef struct { // 结点表元素int parent;TElemType data;ChildPtr firstchild; // 孩子链表头指针
}CTBox;typedef struct { // 数结构CTBox nodes[MAX_TREE_SIZE];int n,r; // 结点数和根结点的位置
}CTree;
树的链式存储3(孩子兄弟表示法)
用二叉链表作树的存储结构,链表中每个结点的两个指针域分别指向其第一个孩子结点和下一个兄弟结点。
typedef struct CSNode{ElemType data;struct CSNode *firstchild, *nextsibling;
}CSNode, *CSTree;
树的应用
树转换成二叉树
因为存储时使用孩子兄弟表示法时,存储方式和二叉树存储方法相同,都为两个指针域+一个数据域,因此将树使用孩子兄弟表示法转换成二叉树。
树变二叉树:兄弟相连留长子。
- 加线:在兄弟之间连线
- 抹线:对每个结点,除了其左孩子外,去除与其余孩子之间的关系
- 旋转:以树根结点为轴心,将整树顺时针转45°
二叉树变树:左孩右右连双亲,去掉原来右孩线。
树的遍历
- 先根(序)遍历
若树不为空,则先访问根节点,然后依次遍历各棵子树。
- 后根(序)遍历
若树不为空,则先依次遍历各棵子树,然后访问根节点。
- 层次遍历
若树不为空,则自上而下自左至右访问树中每个结点。
森林的应用
森林转换二叉树
森林变二叉树:树变二叉根相连。
- 将各棵树分别转换成二叉树
- 将每棵树的根结点用线相连
- 以第一棵树的根结点作为二叉树的根,再以其为轴心,顺时针旋转构成二叉树。
二叉树变森林:去掉全部右孩线,孤立二叉再还原。
- 抹线:将二叉树中根结点与其右孩子连线,及沿右分支搜索到的所有右孩子之间的连线全部抹掉,形成孤立二叉树
- 还原:将孤立的二叉树还原成树。
森林的遍历
- 先序遍历
若森林不为空,则先访问森林中的第一棵树的根节点;先序遍历森林中的第一棵树的子树森林;先序遍历森林中其他的树。
- 中序遍历
若森林不为空,则中序遍历森林中第一棵树的子树森林;访问森林中第一棵树的根节点;中序遍历森林中的其他的树。
相当于依次从左至右对森林中的每棵树进行后根遍历。
哈夫曼树(最优树)
判断树:用于描述分类过程的二叉树。
路径:从树中一个结点到另一个结点之间的分支构成两个结点间的路径。
结点的路径长度:两结点路径上的分支数。
树的路径长度:从树根到每一个结点的路径长度之和,记作TL。
结点数目相同的二叉树中,完全二叉树是路径长度最短的二叉树。
权(weight):将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度:从根节点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:树中所有的叶子结点的带权路径长度之和。\(WPL=\sum_{k=1}^n w_kl_k\)
哈夫曼树(最优树):带权路径长度(WPL)最短的树。
哈夫曼树(最优二叉树):带权路径长度(WPL)最短的二叉树。
满二叉树不一定是哈夫曼树;权越大的叶子结点离根越近;具有相同带权结点的哈夫曼树不唯一。
贪心算法
构造哈夫曼树时首先选择权值最小的叶子结点。
-
根据\(n\)个给定的权重\(\{w_1,w_2,...w_n\}\)构成n棵二叉树的森林\(F=\{T_1,T_2,...,T_n\}\),其中\(T_i\)只有一个带权为\(W_i\)的根结点。
构造森林全是根。
-
在F中选取两根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
选用两小造新树。
-
在F中删除这两棵树,同时将新得到的二叉树加入森林中。
删除两小添新人。
-
重复2,3直到森林中只有一棵树为止,这棵树即为哈夫曼树。
重复2,3剩单根。
哈夫曼树的结点度数为0或2,没有度为1的结点。
包含n个叶子结点的哈夫曼树中共有2n-1个结点。
构造一个哈夫曼树,从森林到树会产生n-1个结点。
typedef struct {int weight;int parent,lch,rch;
}HTNode,*HuffmanTree;int CreatHuffmanTree(HuffmanTree HT, int n){if (n <= 1) return 0;int m = 2*n-1, // 数组共2n-1个元素k = 0;HT = (HuffmanTree)malloc(sizeof(HTNode) * (m+1)); // 不使用0号单元,这样HT[m]就可以表示结点。for (int i = 1; i <= m; ++i){ // 将2n-1个元素的lch,rch,parent设置为0;HT[i].lch = 0;HT[i].rch = 0;HT[i].parent = 0;}for (int i = 1; i <= n; ++i){ // 接收weigth权值scanf("%d",&k);HT[i].weight = k;}for (int i = n+1; i <= m; i++){ // 合并产生n-1个结点-构造Huffman树。Select(HT,i-1,s1,s2); // 选择双亲为0,权值最小的结点,s1,s2返回的是下标HT[s1].parent = i; // 修改结点的双亲HT[s2].parent = i;HT[i].lch = s1; // 修改当前根结点的左右孩子HT[i].rch = s2;HT[i].weight = HT[s1].weight + HT[s2].weight; // 权值}
}
哈夫曼编码
等长编码:ABACCDA->00 01 00 10 10 11 00,14个二进制位
不定长编码:出现次数较多的字符采用尽可能短的编码。ABACCDA->0 00 0 1 1 01 0,9个二进制位
重码:不定长编码会出现解码不唯一情况
前缀编码:设计一种任意字符的编码都不是另一个字符的编码前缀。哈夫曼编码
哈夫曼编码设计操作:
- 统计字符集中每个字符在电文中出现的平均概率(概率越大编码越短)。
- 利用哈夫曼树特点:权重越大叶子离根越近,字符出现的平均概率作为权值。
- 对哈夫曼树每个分支标记为0或1:左分支为0,右分支为1。
- 将根到叶子结点的路径编号连接,作为字符编码。
为什么哈夫曼编码能保证前缀编码?为什么哈夫曼编码能保证字符编码总长最短?
哈夫曼树中没有结点是另一个结点的祖先,因此不可能是后者的前缀。
哈夫曼树中左结点总是比右节点先被选中合并,因此在树中,任何一个结点的左子树路径比右子树路径短,意味着出现概率高的字符编码一定比出现概率低的字符编码要短。
性质1:哈夫曼编码是前缀码。
性质2:哈夫曼编码是最优前缀码。
算法实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>typedef struct {char data;int weight;int parent,lch,rch;
}HTNode, *HuffmanTree;typedef struct {char data;char *code;
}HTCode, *HuffmanCode;int Select_Min(HuffmanTree HT,int n,int *s1,int *s2){int min1, min2;min1 = min2 = INT_MAX; // 初始化for ( int i = n-1; i > 0; --i){if (HT[i].parent == 0 && HT[i].weight < min1){min2 = min1;*s2 = *s1;min1 = HT[i].weight;*s1 = i;}else if (HT[i].parent == 0 && HT[i].weight < min2){min2 = HT[i].weight;*s2 = i;}}
}// 构建哈夫曼树
int CreatHuffmanTree(HuffmanTree *HT, int n){// 判定长度大于2if (n <= 1) return 0;// 初始化前n个元素*HT = (HuffmanTree )malloc(sizeof(HTNode) * (2*n)); // 不使用0号单元,这样HT[m]就可以表示结点。for (int i = 1; i < 2*n; ++i){ // 将2n-1个元素的lch,rch,parent设置为0;if (i <= n){scanf("%c %d",&(*HT)[i].data, &(*HT)[i].weight);getchar();}(*HT)[i].lch = (*HT)[i].rch = (*HT)[i].parent = 0;}// 构造哈夫曼树 数组共2n-1个元素for (int i = n+1; i <= 2*n-1; i++){ // 合并产生n-1个结点-构造Huffman树。int s1,s2;Select_Min(*HT, i, &s1, &s2); // 选择双亲为0,权值最小的结点,s1,s2返回的是下标(*HT)[s1].parent = (*HT)[s2].parent = i;// 修改结点的双亲(*HT)[i].lch = s1; // 修改当前根结点的左右孩子(*HT)[i].rch = s2;(*HT)[i].weight = (*HT)[s1].weight + (*HT)[s2].weight; // 权值(*HT)[i].data = '-'; // 构造一个双亲为0的结点}
}int CreatHuffmanCode(HuffmanTree HT,HuffmanCode *HC, int n){*HC = (HuffmanCode )malloc(sizeof(HTCode) * (n+1));// 第0位置不使用char *cd = (char*)malloc(sizeof(char) * n);cd[n-1] = '\0'; // 末尾位放休止符。for (int i = 1; i <= n; ++i){int start = n - 1, // 倒着数f = HT[i].parent, // 当前结点的双亲c = i; // 存储比对信息while (f != 0){--start; // 倒着数,倒着存,这样方便后续按需分配内存。if (HT[f].lch == c) // 比对左孩子cd[start] = '0';elsecd[start] = '1';c = f; // 存储比对信息f = HT[f].parent; // 更新双亲}(*HC)[i].code = (char*)malloc(sizeof(char) * (n-start)); // 按需分配(*HC)[i].data = HT[i].data; // 复制strcpy((*HC)[i].code, &cd[start]); // 复制}free(cd);
}
int main(){int n = 7;HuffmanTree HT;CreatHuffmanTree(&HT, n);for (int i = 1; i <= 2*n-1; ++i){printf("|%c\t|%d\t|%d\t|%d\t|%d\t|%d\t|\n", HT[i].data, i, HT[i].weight,HT[i].parent, HT[i].lch, HT[i].rch);}HuffmanCode HC;CreatHuffmanCode(HT, &HC, n);for (int i = 1; i <= n; ++i){printf("|%c\t|%s\t|\n", HC[i].data, HC[i].code);}return 0;
}
/*
A 40
B 30
C 15
D 5
E 4
F 3
G 3|A |1 |40 |13 |0 |0 |
|B |2 |30 |12 |0 |0 |
|C |3 |15 |11 |0 |0 |
|D |4 |5 |9 |0 |0 |
|E |5 |4 |9 |0 |0 |
|F |6 |3 |8 |0 |0 |
|G |7 |3 |8 |0 |0 |
|- |8 |6 |10 |7 |6 |
|- |9 |9 |10 |5 |4 |
|- |10 |15 |11 |8 |9 |
|- |11 |30 |12 |10 |3 |
|- |12 |60 |13 |11 |2 |
|- |13 |100 |0 |1 |12 ||A |0 |
|B |11 |
|C |101 |
|D |10011 |
|E |10010 |
|F |10001 |
|G |10000 |*/
文件的编码和解码
编码:
- 输入个字符及其权值。
- 构造哈夫曼树——HT[i]。
- 进行哈夫曼编码——HC[i]。
- 查HC[i],得到各字符的哈夫曼编码。
解码:
- 构造哈夫曼树。
- 依次读入二进制码。
- 读入0,则走左孩子;读入1,则走右孩子。
- 一旦达到某个叶子结点,即可译出字符。
- 再从根出发继续译码,直到结束。
图型结构
图的定义和特点
G = (V,E) Graph=(Vertex,Edge)
V:顶点(数据元素)的有穷非空集合;E:边的有穷集合
有向图:每条边都是有方向的。
无向图:每条边都是无方向的。
完全图:任意两个点都有一条边相连。
稀疏图:有很少边或弧的图(e<nlogn)
稠密图:有较多边或弧的图。
网:边/弧带权的图。
邻接:有边/弧相连的两个顶点之间的关系。
存在(\(v_i,v_j\)),则称\(v_i\)和\(v_j\)互为邻接点;
存在<\(v_i,v_j\)>,则称\(v_i\)邻接到\(v_j\),\(v_j\)邻接于\(v_i\)
关联(依附):边/弧与顶点之间的关系。
存在(\(v_i,v_j\))/<\(v_i,v_j\)>,则称该边/弧关联于\(v_i\)和\(v_j\)
顶点的度:与该顶点相关联的边的数目,记为TD(v)
有向图中,顶点的度等于该顶点的入度与出度之和。
顶点v的入度是以v为终点的有向边的条数,记作ID(v)
顶点v的出度是以v为起点的有向边的条数,记作OD(v)
路径:接续的边构成的顶点序列。
路径长度:路径上边或弧的数目/权重之和。
回路(环):第一个顶点和最后一个顶点路径相同。
简单路径:除路径起点和终点可以相同外,其余顶点均不相同的路径。
简单回路(简单环):除路径起点和终点相同外,其余顶点均不相同的路径。
连通图(强连通图):在无(有)向图G=(V,{E})中,若对任何两个顶点v/u都存在v到u的路径,则称G是连通图(强连通图)。无向图称连通图,有向图称强连通图。
权与网:图中边或弧所具有的相关数称为权。表明从一个顶点到另一个顶点的距离或耗费。带权的图称为网。
子图:有两个图\(G=(V,{E}),G1=(V1,{E1})\),若\(V1\subseteq V\),\(E1\subseteq E\)则称G1是G的子图。
连通分量(强连通分量):
1. 无向图G的极大连通子图称为G的连通分量。
极大连通子图:该子图是G连通子图,将G的任何不在该子图中的顶点加入,子图不再连通。
2. 有向图G的极大强连通子图称为G的强连通分量。
极大强连通子图:该子图是G的强连通子图,将D的任何不在该子图中的顶点加入,子图不再是强连通的。
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边,子图不再连通。
生成树:包含无向图G所有顶点的极小连通子图。
生成森林:对非连通图,由各连通分量的生成树的集合。
图抽象数据类型定义
ADT Graph{数据对象V:具有相同特性的数据元素的集合,称为顶点集。数据关系R:R = {VR}VR = {<v,w>|<v,w>|v,w∈V ^ p(v,w),<v,w>表示从v到w的弧,P(v,w)定义了弧<v,w>的信息}基本操作P:Create_Graph(); // 图的创建操作初始条件: 无操作结构: 生成一个没有顶点的空图G。GetVex(G,v); // 求图中的顶点v的值初始条件: 图G存在,v是图中的一个顶点。操作结果: 获取v顶点的值。CreateGraph(&G,V,VR) // 建立图初始条件: V是图的顶点集,VR是图中弧的集合。操作结果: 按V和VR的定义构造图G。DFSTraverse(G)初始条件: 图G存在。操作结果: 对图进行深度优先遍历。BFSTraverse(G)初始条件: 图G存在。操作结果: 对图进行广度优先遍历。
}ADT Graph
图的顺序存储(邻接矩阵)
使用二维数组表示元素之间的关系,称为数组表示法(邻接矩阵)
建立一个顶点表(记录各个顶点信息)和一个邻接矩阵(表示各顶点之间的关系)。
设图A = (V,E)有n各顶点,则
顶点表Vexs[n],定义为:
| i | 0 | 1 | 2 | ... | n-1 |
|---|---|---|---|---|---|
| Vexs[i] | \(V_1\) | \(V_2\) | \(V_3\) | ... | \(V_n\) |
图的邻接矩阵表示:是一个二维数组A.arcs[n][n],定义为:
| 无向图 | \(v_1\) | $v_2 $ | \(v_3\) | \(v_4\) | \(v_5\) |
|---|---|---|---|---|---|
| \(v_1\) | 0 | 1 | 0 | 1 | 0 |
| \(v_2\) | 1 | 0 | 1 | 0 | 1 |
| \(v_3\) | 0 | 1 | 0 | 1 | 1 |
| \(v_4\) | 1 | 0 | 1 | 0 | 0 |
| \(v_5\) | 0 | 1 | 1 | 0 | 0 |
分析1:无向图的邻接矩阵是对称的;
分析2:顶点i的度=第i行(列)中1的个数;
特别:完全图的邻接矩阵中,对角元素为0,其余为1.
| 有向图 | \(v_1\) |
$v_2 $ | \(v_3\) | \(v_4\) |
|---|---|---|---|---|
| \(v_1\) | 0 | 1 | 1 | 0 |
| \(v_2\) | 0 | 0 | 0 | 0 |
| \(v_3\) | 0 | 0 | 0 | 1 |
| \(v_4\) | 1 | 0 | 0 | 0 |
在有向图的邻接矩阵中,
第i行的含义:以结点v_i为尾的弧(即除度边);
第i列的含义:以结点v_i为头的弧(即入度边);
分析1:有向图的邻接矩阵可能是不对称的。
分析2:顶点的出度 = 第i行元素之和。顶点的入度 = 第i列元素之和。顶点的度 = 第i行元素之和+第i列元素之和。
网(即有权图)的邻接矩阵表示:是一个二维数组A.arcs[n][n],定义为:
| 有向网 | \(v_1\) |
$v_2 $ | \(v_3\) | \(v_4\) | \(v_5\) | \(v_6\) |
|---|---|---|---|---|---|---|
| \(v_1\) | \(\infty\)(or 0) | 5 | \(\infty\) |
7 | \(\infty\) | \(\infty\) |
| \(v_2\) | \(\infty\) |
\(\infty\)(or 0) |
4 | \(\infty\) |
\(\infty\) | \(\infty\) |
| \(v_3\) | 8 | \(\infty\) |
\(\infty\)(or 0) |
\(\infty\) |
\(\infty\) | 9 |
| \(v_4\) | \(\infty\) |
\(\infty\) |
5 | \(\infty\)(or 0) |
\(\infty\) | 6 |
| \(v_5\) | \(\infty\) | \(\infty\) | \(\infty\) | 5 | \(\infty\)(or 0) | \(\infty\) |
| \(v_6\) | 3 | \(\infty\) | \(\infty\) | \(\infty\) | 1 | \(\infty\)(or 0) |
// 邻接矩阵的存储表示:用两个数组分别存储顶点表和邻接矩阵
#include <stdio.h>
#include <stdlib.h>#define MAXInt 32767 // 表示极大值,即∞
#define MVNum 100 // 最大顶点数
typedef char VerTexType; // 设顶点的数据类型为字符型
typedef int ArcType; // 假设边的权值类型为整形。typedef struct{VerTexType vexs[MVNum]; // 顶点表ArcType arcs[MVNum][MVNum]; // 邻接矩阵int vexnum,arcnum; // 图当前点数和边数
}AMGraph; // Adjacency Matrix Graph
/*
1.输入总顶点数和总边数。
2.依次输入点的信息存入顶点表中。
3.初始化邻接矩阵,是每个权值初始化为极大值。
4.构造邻接矩阵。
*/
int LocateVex(AMGraph G, VerTexType u){ // 在图中查找顶点u的位置for (int i = 0; i < G.vexnum; i++)if (G.vexs[i] == u)return i;return -1;// printf("顶点不存在\n");
}int CreateUDN(AMGraph *G){ // 采用邻接矩阵表示法,创建无向网printf("请输入总顶点数和总边数:\n");scanf("%d %d%*c", &G->vexnum, &G->arcnum); // 输入总顶点数和总边数 %*c可以吸附剩余字符printf("请输入顶点信息:\n");for (int i = 0; i < G->vexnum; i++)scanf("%c%*c", &G->vexs[i]); // 依次输入顶点信息for (int i = 0; i < G->vexnum; i++)for (int j = 0; j < G->vexnum; j++)G->arcs[i][j] = MAXInt; // 初始化邻接矩阵,无向(有向)图这里初始为0for (int i = 0; i < G->arcnum; i++){char v1, v2;int w,index1,index2;printf("请输入两顶点及其边的权值:\n",i+1);scanf("%c %c %d%*c", &v1, &v2, &w); // 输入一条边所依附的顶点及边的权值index1 = LocateVex(*G, v1);index2 = LocateVex(*G, v2); // 确定v1和v2在G中的位置G->arcs[index1][index2] = G->arcs[index2][index1] = w; // 插入边 <i,j> 和 <j,i>/*无向图 G->arcs[index1][index2] = G->arcs[index2][index1] = 1;无向网 G->arcs[index1][index2] = G->arcs[index2][index1] = w;有向图 G->arcs[index1][index2] = 1G->arcs[index2][index1] = 1;有向网G->arcs[index1][index2] = w1G->arcs[index2][index1] = w2;*/}return 1;
}int main(){AMGraph G;CreateUDN(&G);return 0;
}
邻接矩阵的优缺点
邻接矩阵的优点:
-
直观、简单、好理解
-
方便检查任意一对顶点间是否存储边
-
方便找任一顶点的所有“邻接点”(有边直接相连的顶点)
-
方便计算任一顶点的“度”(从该点发出的为出度,指向该点的为入度)
- 无向图:对应行(列)非0元素的个数;
- 有向图:对应行非零元素为出度,对应列非零元素为入度
邻接矩阵的缺点:
- 邻接矩阵是一个固定结构,增加或删除操作困难。
- 邻接矩阵空间复杂度为\(O(n^2)\),浪费空间,稀疏图(点多边少)存在大量无效元素,稠密图合适。
- 统计稀疏图中边的个数,浪费时间,时间复杂度为\(O(n^2)\)
图的链式存储(邻接表)
使用链式存储结构表示,多重链表:邻接表,邻接多重表,十字链表。
重点:邻接矩阵(数组)表示法,邻接表(链式)表示法
顶点:按编号顺序将顶点数据存储在一维数组中;
关联同一顶点的边(以顶点为尾的弧):用线性链表存储
无向图

存储特点:
- 邻接表不唯一。
- 若无向图中有n个顶点、e条边,则其邻接表需n个头结点和2e个表结点。适用于稀疏图。
- 无向图中顶点\(v_i\)的度为第i个单链表中的结点数。
有向图

存储特点:
-
顶点\(v_i\)的出度为第i个单链表中的结点个数。
-
顶点\(v_i\)的入度为整个单链表中邻接点阈值是\(i-1\)的结点个数
-
找出度容易,找出度难,因此创建两个邻接表,一个存储入度边(邻接表),一个存储出度边(逆邻接表)。
-
逆邻接表中
- 顶点\(v_i\)的入度为第i个单链表中的结点个数。
- 顶点\(v_i\)的出度为整个单链表中邻接点阈值是\(i-1\)的结点个数
#include <stdio.h>
#include <stdlib.h>#define MAXInt 32767 // 表示极大值,即∞
#define MVNum 100 // 最大顶点数
typedef char VerTexType; // 设顶点的数据类型为字符型
typedef int ArcType; // 假设边的权值类型为整形。typedef struct ArcNode{ // 边结点int adjvex; // 该边指向的顶点位置struct ArcNode * nextarc; // 指向下一条边的指针OtherInfo info; // 和边相关的信息
}ArcNode;typedef struct VNode{VerTexType data; // 顶点信息ArcNode * firstarc; // 指向第一条依附该顶点的边的指针
}VNode,AdjList[MVNum]; // AdjList表示邻接表类型 AdjList v; == VNode v[MVNum];typedef struct{AdjList vertices; // vertuces -- vertex的复数 AdjList表示邻接表类型int vexnum,arcnum; // 图的当前结点数和弧数
}ALGraph;/*邻接表创建无向网
1.输入总顶点数和总边数
2.建立顶点表,依次输入点的信息存入顶点表中使每个表头结点的指针域初始化为NULL
3.创建邻接表,依次输入每条边依附的两个顶点,确定两个顶点的序号i和j,建立边结点,将此边结点分别插入到v_i和v_j对应的两个边链表头部
*/
int CreateUDG(ALGraph *G){scanf("%d %d %*c", &G->vexnum, &G->arcnum); // 输入总顶点数,总边数for (int i = 0; i < G->vexnum; i++){ // 输入个点,构造表头结点表scanf("%c %*c",&G->vertices[i].data); // 输入顶点值G->vertices[i].firstarc=NULL; // 初始化表头结点的指针域}for (int k = 0; k < G.arcnum; k++){ // 输入各边,构造邻接表char v1,v2;int i,j;scanf("%c %c %*c", &v1, &v2); // 输入一条边依附的两个顶点i = LocateVex(G, v1);j = LocateVex(G, v2);ArcNode p1 = (ArcNode *)malloc(sizeof(ArcNode)); // 创建边界点*p1p1->adjvex = j; // 邻接点序号为jp1->nextarc = G->vertices[i].firstarc;G->vertices[i].firstarc = p1; // 将新结点*p1插入顶点v_i的边表头部ArcNode p1 = (ArcNode *)malloc(sizeof(ArcNode)); // 创建边界点*p1p2->adjvex = i; // 邻接点序号为ip2->nextarc = G->vertices[i].firstarc;G->vertices[i].firstarc = p2; // 将新结点*p2插入顶点v_j的边表头部}return OK;
}
邻接表的优缺点
邻接表的优点:
-
方便找任一顶点的所有"邻接点"。
-
节约稀疏图的空间。
- 需要N个头指针+2E个结点(每个结点至少两个域)。
-
对无向图而言方便计算任一顶点的"度"。
邻接表的缺点:
- 对有向图而言不方便计算"度",需要添加逆邻接表。
- 不方便检查任意一对顶点是否存储边
图的链式存储3(十字链表)
邻接表表示有向图的改进:方便求结点的度

图的链式存储2(邻接多重表)
邻接表表示无向图的改进:原本需要存储两遍边,现在只需要存储一次。

邻接矩阵和邻接表的关系

-
联系:
- 邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数。
-
区别:
- 对任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链表次序与顶点编号无关)。
- 邻接矩阵的空间复杂度为\(O(n^2)\),而邻接表的空间复杂度为\(O(n+e)\)。
-
用途:
- 邻接矩阵多用于稠密图。
- 邻接表多用于稀疏图。
图的应用
图的遍历
遍历的实质:找每个顶点的邻接点的过程。
图的特点:图中可能存在回路,可能回到了曾经访问过的顶点。
解决回路:设置辅助数组\(visited[n]\),用来标记每个被访问过的顶点,初始状态\(visited[i]=0\),被访问后\(visited[i]=1\)
深度优先搜索
深度优先搜索Depth_First Search-DFS
- 在访问图中某一起始顶点\(v\)后,由\(v\)出发,访问它的任一邻接顶点\(w_1\)。
- 再从\(w_1\)出发,访问与\(w_1\)邻接但还未被访问过的顶点\(w_2\)。
- 然后再从\(w_2\)出发,进行类似的访问,如此进行下去直到达到所有的邻接顶点都被访问过的顶点\(u\)为止。
- 接着,回退一步,退到前一次刚访问过的顶点,看是否还有其他没有被访问的邻接点。
- 如果有,则访问此顶点,之后再从此顶点出发,进行上述操作。
- 如果无,则再回退一步,进行搜索,直到连通图中所有顶点都被访问。

邻接矩阵的深度优先搜索
int DFS(AMGraph G,int v){ // G为邻接矩阵int visited[v] = true; // 访问第v个顶点,起始顶点。for (int w = 0; w < G.vexnum; w++) // 依次检查邻接矩阵v所在的行if ( (G.arcs[v][w] != 0) && (!visited[w]) )DFS(G, w) // w是v的邻接点,如果w未被访问,则递归调用DFS,通过递归实现自动栈,也可以手动栈来替代递归
}
DFS算法效率
- 用邻接矩阵表示图,时间复杂度为\(O(n^2)\)
- 用邻接表表示图,时间复杂度为\(O(n+e)\),\(e\)为结点个数,在邻接表当中有\(2e\)个表结点
- 结论:稠密图适合在邻接矩阵上进行深度遍历,稀疏图适合在邻接表上进行深度遍历
广度优先搜索
广度优先搜索Breadth_Frist Search-BFS
- 从图的某一结点出发,首先依次访问该结点的所有邻接结点\(v_{i_1},v_{i_2},...v_{i_n}\)再按这些顶点被访问的先后次序依次访问与它们相邻接的所有未被访问的顶点
- 重复此过程,直至所有顶点均被访问为止。

邻接表的广度优先搜索
int BFS(Graph G, int v){ // 按广度优先非递归遍历连接图Gint visited[v] = true; // 访问第v个顶点InitQueue(Q); // 辅助队列Q初始化,置空EnQueue(Q, v); // v进队while ( !QueueEmpyty(Q) ){ // 队列非空DeQueue(Q, u); // 对头元素出队并置为u for ( int w = FirstAdjVex(G, v); w >= 0; w = NextAdjVex(G, u, w) ) if ( !visited[w] ){ // w为u的尚未访问的邻接顶点visited[w] = true; EnQueue(Q, w); // w进队}}
}
生成树
生成树:所有顶点均由边连接在一起,但不存在回路的图。一个图可以有许多棵不同的生成树。
生成树的特点:
- 生成树的顶点个数与图的顶点个数相同;
- 生成树是图的极小连通子图,去掉一条边则非连通;
- 一个有\(n\)个顶点的连通图的生成树有\(n-1\)条边;
- 在生成树中再加一条边必然形成回路;
- 生成树中任意两个顶点间的路径是唯一的;
- 含有\(n\)个顶点\(n-1\)条边的图不一定是生成树;
无向图的生成树
深度优先生成树

广度优先生成树

最小生成树
最小生成树:给定一个无向网络,再该网的所有生成树中,使得各边权值之和最小的那颗生成树称为该网的最小生成树,也叫最小代价生成树。
典型应用,城市间建立通信网,权值代表路的经济成本,\(n\)个城市最多有\(\frac{n(n-1)}2\)条路,最少\(n-1\)条路。
构造最小生成树(MST)性质:设\(N=(V,E)\)是一个连通网,\(U\)是顶点集\(V\)的一个非空子集,若边\((u,v)\)是一条具有最小权值的边,其中\(u\in U,v\in V-U\),则必存在一棵包含边\((u,v)\)的最小生成树
构建最小生成树的算法1:普里姆(Prim)算法
算法思想:
- 设\(N=(V,E)\)是连通网,\(TE\)是\(N\)上最小生成树中变的集合。
- 初始化令\(U=\{u_0\},(u_0\in V),TE=\{\}\)。
- 在所有的\(u\in U,v\in V-U\)的边\((u,v)\in E\)中,找一条代价最小的边\((u_0,v_0)\)。
- 将\((u_0,v_0)\)并入集合\(TE\),同时\(v_0\)并入\(U\)。
- 重复上述操作直至\(U=V\)为止,则\(T=(V,TE)\)为\(N\)的最小生成树。
构建最小生成树的算法2:克鲁斯卡尔(Kruskal)算法
算法思想:
- 设连通网\(N=(V,E)\),令最小生成树初始状态为只有\(n\)个顶点而无边的非连通图\(T=(V,\{\})\),每个顶点自成一个连通分量。
- 在\(E\)中选取代价最小的边,若该边依附的顶点落在\(T\)中不同的连通分量上(不形成环),则将此边加入到\(T\)中,否则舍去,选取下一条代价最小边。
- 依次类推,直至T中所有顶点都在同一连通分量上。
两种算法比较
| 算法名 | 普里姆算法 | 克鲁斯卡尔算法 |
|---|---|---|
| 算法思想 | 选择点 | 选择边 |
| 时间复杂度 | \(O(n^2)(n为顶点数)\) | \(O(eloge)(e为边数)\) |
| 适应范围 | 稠密图 | 稀疏图 |
最短路径
典型应用:交通网络的问题,最短路线。
问题抽象:在有向网中A点(源点)到达B点(终点)的多条路径中,寻找一条各边权值之和最小的路径,即最对路径。
最短路径不需要包含\(n\)个顶点,也不一定有\(n-1\)条边。
两点间最短路径
知道源点和终点,找到最短的路径。
某源点到其他各点最短路径
从源点到其他各结点的各结点路径。
单源最短路径,迪杰斯特拉(Dijkstra)算法
贪心策略
-
初始化:先找出从源点\(v_0\)到各终点\(v_k\)的直达路径\((v_0,v_k)\),即通过一条弧到达的路径。若无则设置为无穷大。
-
选择:从这些路径中找出一条长度最短的路径\((v_0,u)\)。
-
更新:然后对其余各条路径进行适当调整:
- 若在图中存在弧\((u,v_k)\),且\((v_0,u)+(u,v_k) < (v_0,v_k)\),则以路径\((v_0,u,v_k)\)代替\((v_0,v_k)\)。
在调整后的各路径中,再找长度最短的路径,依次类推。
两点间最短路径问题的算法时间复杂度\(O(n^2)\)
某源点到其他各点最短路径问题的算法时间复杂度为\(O(n^3)\)
所有顶点的最短路径,弗洛伊德(Floyd)算法
动态规划
算法思想:逐个顶点试探,从\(v_i\)到\(v_j\)的所有可能存在的路径中选出一条长度最短的路径。
-
初始化:初始化两个矩阵,不同顶点可以直达其他顶点的矩阵,矩阵大小为\(n\times n\),不可直达的顶点记为无穷大,自身标记为0.
-
加入:依次向下加入各顶点,使得\(v_i\)到\(v_j\)路过该结点。
-
更新:然后对其余各条路径进行适当调整:
- 若在图中存在弧\((u,v_k)\),且\((v_0,u)+(u,v_k) < (v_0,v_k)\),则以路径\((v_0,u,v_k)\)代替\((v_0,v_k)\)。
对两个问题的时间算法复杂度为\(O(n^3)\)
拓扑排序
有向无环图:无环的有向图,简称DAG图,有向树。
通常使用有向无环图来描述一个工程或系统的进行过程,一个工程可以分为若干个子工程,完成子工程可以导致工程的总完成。
AOV网
用一个有向图表示一个工程的各子工程及其相互制约的关系,其中以顶点表示活动,弧表示活动之间的优先制约关系,这种有向图称为顶点表示活动的网,简称AOV网。使用拓扑排序技术
AOV网的特点
- 若从i到j有一条有向路径,则i是j的前趋;j是i的后继。
- 若<i,j>是网中有向边,则i是j的直接前驱;j是i的直接后继。
- AOV网中不允许有回路,因为如果有回路存在,则表明某项活动以自己为先决条件。
如何判别AOV网是否有回路:拓扑排序
拓扑排序:在AOV网没有回路的前提下,我们将全部活动排列成一个线性列,使得若AOV网中有弧\(<i,j>\)存在,则在这个序列中,\(i\)一定排在\(j\)的前面,具有这种性质的线性序列称为拓扑有序序列,相应的拓扑有序排序的算法称为拓扑排序。
拓扑排序的方法:
-
在有向图中选一个没有前驱的顶点且输出。
-
从图中删除该顶点和所有以它为尾的弧。
-
重复上述两步,直至全部顶点输出;或图中不存在无前趋的顶点为止。
一个AOV网的拓扑序列不唯一
拓扑排序检测AOV网是否存在环的方法:对有向图构造其顶点的拓扑有序序列,若网中所有顶点都在它的拓扑有序序列中,则AOV网必定不存在环;否则必定存在环。
AOE网
用一个有向图表示一个工程的各子工程及其相互制约的关系,以弧表示活动,以顶点表示活动的开始或结束事件,称这种有向图为边表示活动的网,简称AOE网。使用关键路径技术
AOE网的顶点表示活动的结束和下一个活动的开始,源点表示整个工程的开始,汇点表示整个工程的结束。
关键路径:路径长度最长的路径;路径长度——路径上各活动持续时间之和。
关键路径的描述量:
- \(ve(vj)\)——表示事件\(vj\)的最早发生时间
- \(vl(vj)\)——表示事件\(vj\)的最晚发生时间
- \(e(i)\)——表示活动\(ai\)的最早开始时间
- \(l(i)\)——表示活动\(ai\)的最晚开始时间
- \(l(i)-e(i)\)——表示完成活动\(ai\)的时间余量
- 关键活动——关键路径上的活动,即\(l(i)==e(i)\)(\(l(i)-e(i)=0\))的活动
如何寻找关键活动
-
设活动\(ai\)用弧\(<j,k>\)表示,其持续时间记为\(W_{j,k}\)

-
\(e(i)=ve(j)\)
-
\(l(i)=vl(k)-W_{j,k}\)
-
从\(ve(1)=0\)开始向前递推,\(ve(j)=\max_i\{ve(i)+W_{i,j}\}, <i,j>\in T, 2\le j\le n\)其\(T\)是所有以\(j\)为头的弧的集。
-
从\(vl(n)=ve(n)\)向后递推,\(vl(i)=\max_j\{vl(j)-W_{i,j}\}, <i,j>\in S, 1\le i\le n-1\)其\(S\)是所有以\(i\)为尾的弧的集。
-
将上述得到的点和其弧就是关键路径



![[扫描线] 数据结构测试(2025.3.22)](https://nh.51goc.com/static/problemImage/26242/1742616827806.png/)