 作为一种成功的图像超分辨率 (SR) 深度模型,超分辨率卷积神经网络 (SRCNN) 在速度和恢复质量方面都表现出优于以往手工制作模型的性能。然而,高计算成本仍然阻碍了它需要实时性能 (24 fps) 的实际使用。在本文中,我们旨在加速当前的 SRCNN,并提出一种紧凑的沙漏形 CNN 结构,以实现更快、更好的 SR。我们主要从三个方面重新设计了 SRCNN 结构。首先,我们在网络的末端引入一个反卷积层,然后直接从原始的低分辨率图像(没有插值)学习到高分辨率图像的映射。其次,我们通过在映射之前缩小输入特征维度并在映射之后扩展来重新构建映射层。第三,我们采用更小的滤波器大小,但更多的映射层。所提出的模型实现了 40 倍以上的加速,甚至具有卓越的修复质量。此外,我们还介绍了可以在通用 CPU 上实现实时性能,同时仍保持良好性能的参数设置。还提出了相应的传输策略,用于跨不同放大因子进行快速训练和测试。
作为一种成功的图像超分辨率 (SR) 深度模型,超分辨率卷积神经网络 (SRCNN) 在速度和恢复质量方面都表现出优于以往手工制作模型的性能。然而,高计算成本仍然阻碍了它需要实时性能 (24 fps) 的实际使用。在本文中,我们旨在加速当前的 SRCNN,并提出一种紧凑的沙漏形 CNN 结构,以实现更快、更好的 SR。我们主要从三个方面重新设计了 SRCNN 结构。首先,我们在网络的末端引入一个反卷积层,然后直接从原始的低分辨率图像(没有插值)学习到高分辨率图像的映射。其次,我们通过在映射之前缩小输入特征维度并在映射之后扩展来重新构建映射层。第三,我们采用更小的滤波器大小,但更多的映射层。所提出的模型实现了 40 倍以上的加速,甚至具有卓越的修复质量。此外,我们还介绍了可以在通用 CPU 上实现实时性能,同时仍保持良好性能的参数设置。还提出了相应的传输策略,用于跨不同放大因子进行快速训练和测试。FSRCNN:加速超分辨率卷积神经网络
Accelerating the Super-Resolution Convolutional Neural Network
加速超分辨率卷积神经网络
https://arxiv.org/abs/1608.00367
https://github.com/mrshao520/ReproductionCode/tree/main/FSRCNN/FSRCNN_torch
ECCV 2016
Abstract
- 问题:高计算成本阻碍了SRCNN在需要实时性能(24fps)的实际应用中的应用
- 方法:提出一种紧凑的沙漏形 CNN 结构,以实现更快、更好的 SR
- 在网络的末端引入一个反卷积层,然后直接从原始的低分辨率图像学习到高分辨率图像的映射
- 在映射之前缩小输入特征维度并在映射之后扩展来重新构建映射层
- 采用更小的滤波器大小,但更多的映射层
- 结果:所提出的模型实现了 40 倍以上的加速,甚至具有卓越的修复质量
- 主要贡献:
- 我们制定了一个紧凑的沙漏形 CNN 结构,用于快速图像超分辨率。通过一组转置卷积过滤器的协作,网络可以学习原始 LR 和 HR 图像之间的端到端映射,而无需进行预处理。
- 所提出的模型实现了比SRCNN快至少40倍的速度,同时保持卓越的性能。
- 我们转移所提出网络的卷积层,以便跨不同的放大因子进行快速训练和测试,而不会损失恢复质量。
输入图像:\(n \times n\)
输出图像:\(o \times o\)
过滤器 :\(f \times f\)
padding :\(p \times p\)
step :\(s\)
卷积:
转置卷积:
1. 简介
限制运行速度的两种因素:
- 作为预处理步骤,需要使用双三次插值将原始 LR 图像上采样到所需的大小以形成输入。因此,SRCNN 的计算复杂度随着 HR 图像(而不是原始 LR 图像)的空间大小呈二次方增长。对于放大因子 \(n\) ,与插值 LR 图像进行卷积的计算成本将是原始 LR 图像的\(n^{2}\)倍。
- 第二个限制在于非线性映射步骤。在 SRCNN 中,输入图像块被投影到高维 LR 特征空间上,然后进行复杂的映射到另一个高维 HR 特征空间。
- 通过采用更宽的映射层可以显着提高映射精度,但代价是运行时间。
解决方法:
- 对于第一个问题,在网络末端放置转置卷积层,则计算复杂度仅与原始LR图像的空间大小成正比。
- 对于第二个问题,我们在映射的开头和结尾分别添加收缩层和扩展层,以限制低维特征空间中的映射。此外,我们将单个宽映射层分解为具有具有固定过滤器大小 3 x 3 的多个层。新结构的整体形状像个沙漏,整体对称,两端厚,中间薄。
FSRCNN 还有另一个吸引人的特性,可以促进跨不同升级因素的快速训练和测试。具体来说,在FSRCNN中,所有卷积层(除转置卷积层之外)都可以由不同放大因子的网络共享。在训练过程中,使用训练有素的网络,我们只需针对另一个放大因子微调转置卷积层,几乎不会损失映射精度。在测试过程中,我们只需要进行一次卷积操作,并使用相应的转置卷积层将图像上采样到不同的尺度。
2. 相关工作
高级视觉问题(high-level problems):图像分类、目标检测
低级视觉问题(lower-level problems):SR
SR的深度模型不包含全连接层,卷积过滤器将严重影响性能。
3. Fast Super-Resolution by CNN(FSRCNN)
3.1 SRCNN
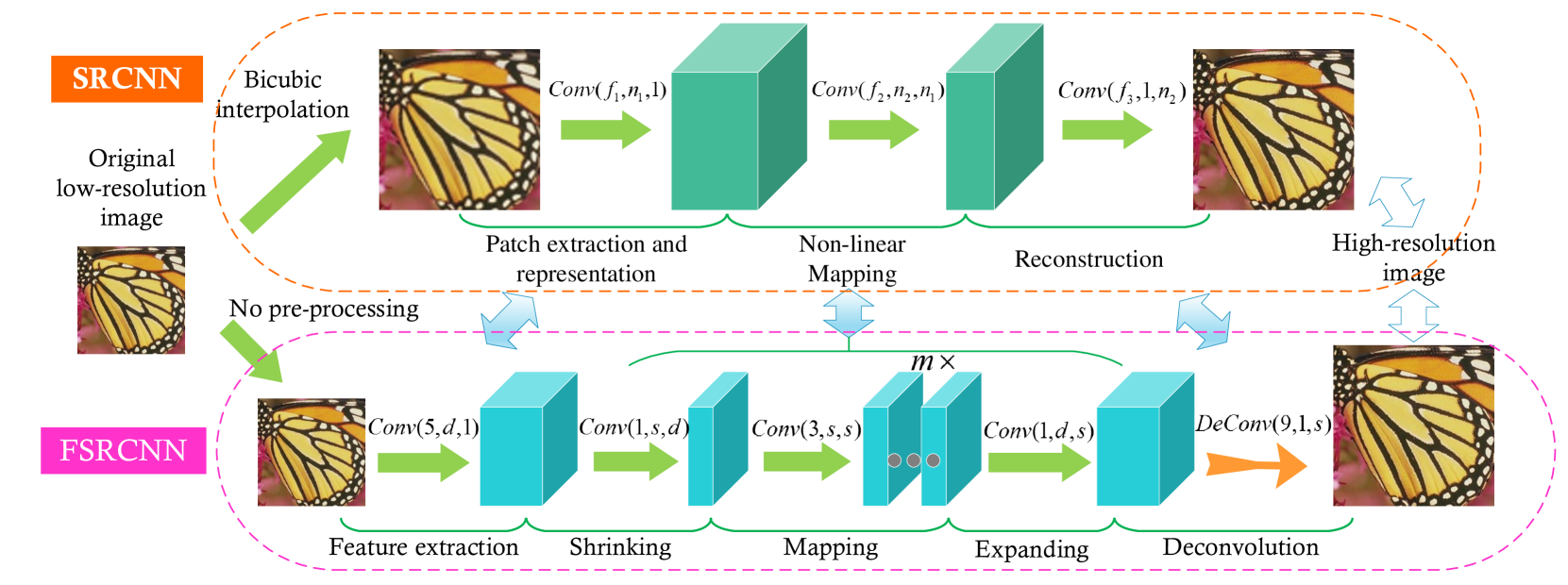
该图显示了SRCNN和FSRCNN的网络结构。所提出的 FSRCNN 与 SRCNN 主要在三个方面有所不同。首先,FSRCNN采用原始低分辨率图像作为输入,不进行双三次插值。在网络末端引入转置卷积层来执行上采样。其次,SRCNN 中的非线性映射步骤被 FSRCNN 中的三个步骤取代,即收缩、映射和扩展步骤。第三,FSRCNN采用更小的滤波器尺寸和更深的网络结构。这些改进为 FSRCNN 提供了比 SRCNN 更好的性能但计算成本更低。
3.2 FSRCNN
FSRCNN可以分解为五个部分—特征提取(feature extractions)、收缩(shrinking)、映射(mapping)、扩展(expending)和转置卷积(dconvolution)。
-
特征提取(feature extractions):通过与第一组过滤器进行卷积,输入的每个块(1像素重叠)被表示为高维特征向量。
- \(nn.Conv2d(in\_channels=1, out\_channels=d, kernel\_size=5)\)
- d:LR特征维度的数量
-
收缩(shrinking):在特征提取层之后添加收缩层来降低LR特征维度 d,将过滤器的大小固定为 \(f_{2} = 1\)。收缩操作是为了提高计算效率而减少LR特征维数。
- 通过采用较小的过滤器数量 \(n_{2}=s<<d\),LR特征维度从\(d\)减小到\(s\)。
- \(nn.Conv2d(in\_channels=d,out\_channels=s,kernel\_size=1)\)
- s:收缩程度
-
非线性映射(non-linear mapping):影响SR性能的最大因素是宽度(即第一层中的过滤器数量)和深度(即层数)的映射层。
- \(m \times Conv2d(in\_channels=s,out\_channels=s,kernel\_size=3)\)
- m:映射层数,决定了映射的精度和复杂性
- 为了保持一致,所有映射层都包含相同数量的过滤去\(n_{3} = s\)
-
扩展(expending):扩展层的作用类似于收缩层的逆过程。收缩操作是为了提高计算效率而减少LR特征维数。然而,如果我们直接从这些低维特征生成HR图像,最终的恢复质量会很差。因此,我们在映射部分之后添加一个扩展层来扩展HR特征维度。
- \(Conv2d(in\_channels=s,out\_channels=d,kernel\_size=1)\)
-
转置卷积(deconvolution):最后一部分是转置卷积层,它使用一组转置卷积过滤器对先前的特征进行上采样和聚合。转置卷积可以看作是卷积的逆操作。对于卷积,过滤器以步长\(k\)与图像进行卷积,输出是输入的\(\frac{1}{k}\)倍。相反,如果我们交换输入和输出的位置,输出将是输入的\(k\)倍。
- \(nn.ConvTranspose2d(in\_channels=d,out\_channels=1,kernel\_size=9)\)
-
PReLU:对于每个卷积层之后的激活函数,我们建议使用参数整流线性单元(PReLU)而不是常用的整流线性单元(ReLU)。它们的负数部分的系数不同。对于ReLU和PReLU,我们可以将通用激活函数定义为\(f(x_{i})=max(x_{i},0)+a_{i}min(0,x_{i})\),其中 \(x_{i}\) 是 \(i\) 为负数部分的系数。对于ReLU,参数 \(a_{i}\) 固定为0,但对于PReLU来说是可学习的。我们选择PReLU主要是为了避免ReLU中零梯度造成的死特征。实验表明,PReLU激活网络的性能更加稳定,可以看作是ReLU激活网络的上届。
-
整体结构(Overall structure):
-
\(nn.Conv2d(in\_channels=1, out\_channels=d, kernel\_size=5)\)
-
PReLU
-
\(nn.Conv2d(in\_channels=d,out\_channels=s,kernel\_size=1)\)
-
PReLU
-
\(m \times Conv2d(in\_channels=s,out\_channels=s,kernel\_size=3)\)
-
PReLU
-
\(Conv2d(in\_channels=s,out\_channels=d,kernel\_size=1)\)
-
PReLU
-
\(nn.ConvTranspose2d(in\_channels=d,out\_channels=1,kernel\_size=9)\)
-
LR特征维度d、收缩过滤器的数量s和映射深度m控制性能和速度
-
将FSRCNN网络表示为 FSRCNN(d, s, m)
-
计算复杂度可以计算为:
-
成本函数(Cost function):采用均方误差(MSE)作为成本函数
\[\mathop{min}\limits_{\theta} \frac{1}{n} \sum_{i=1}^{n}{||F(Y^{i}_{s}; \theta) - X^{i}||^{2}_{2}} \]- \(Y^{i}_{s}\) 和 \(X^{i}\) 是训练数据中的第 \(i\) 个LR和HR子图像对
- \(F(Y^{i}_{S}; \theta)\) 是网络带有参数 \(\theta\) 的 \(Y^{i}_{s}\) 的输出。
- 所有参数均使用随机梯度下降和标准反向传播进行优化。
3.2.1 PReLU
torch.nn.PReLU(num_parameters=1, init=0.25, device=None, dtype=None)
-
参数
- num_parameters(int):要学习的 \(a\) 数量,只有两个合法值:输入的通道数 或 1。默认值为 1。
- init(float):\(a\) 的初始值。默认值: 0,25
-
变量
- weight(Tensor):权重
- 这里的\(a\)是一个可学习参数。当不带参数调用时,nn.PReLU() 在所有输入通道中使用单个参数 \(a\)。如果使用 nn.PReLU(nChannels)调用,则每个输入通道将使用单独的 \(a\)。

Example:
m = nn.PReLU()
input = torch.randn(2)
output = m(input)
3.2.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass FSRCNN(nn.Module):def __init__(self, upscale_factor, feature_dimension, shrinking, mapping_layers) -> None:"""feature_dimension: LR特征维度的数量shrinking: 收缩程度mapping_layers: 映射层数"""super().__init__()# feature_extractionsself.model_seq = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=feature_dimension,kernel_size=5, padding=2),nn.PReLU(feature_dimension))# shrinkingself.model_seq.extend([nn.Conv2d(in_channels=feature_dimension,out_channels=shrinking, kernel_size=1),nn.PReLU(shrinking)])# non-linear mappingfor i in range(mapping_layers):self.model_seq.extend([nn.Conv2d(in_channels=shrinking, out_channels=shrinking,kernel_size=3, padding=1),nn.PReLU(shrinking)])# expendingself.model_seq.extend([nn.Conv2d(in_channels=shrinking, out_channels=feature_dimension, kernel_size=1),nn.PReLU(feature_dimension)])# deconvolutionself.last_seq = nn.Sequential(nn.ConvTranspose2d(in_channels=feature_dimension, out_channels=1, kernel_size=9, stride=upscale_factor, padding=4,output_padding=upscale_factor-1))def forward(self, x):x = self.model_seq(x)x = self.last_seq(x)return xif __name__ == '__main__':model = FSRCNN(3, 56, 12, 4)print(f'model ---------\n{model}')x = torch.randn((1, 1, 7, 7))x = model(x)print(f'x shape : {x.shape}')print(f'x : {x}')
3.3 与SRCNN的区别:从SRCNN到FSRCNN
- upscale_factor = 3
- 91个图像数据集上训练的性能
- Set5 上的平均 PSNR

首先,我们用转置卷积层替换SRCNN-Ex的最后一个卷积层,然后整个网络将在原始LR图像上执行,计算复杂度与\(S_{LR}\)成正比。由于学习到的转置卷积核比单个双三次核更好,因此性能大约提高了 0.12 dB。其次,将单个映射层替换为收缩层、4个映射层和扩展层的组合。总体来说,多了5层,但参数从58,976减少到17,088。另外,这一步之后的加速度是最突出的 30.1 X 。人们普遍认为,深度是影响性能的关键因素。在这里,我们使用四个“窄”层来代替单个“宽”层,从而以更少的参数获得更好的结果(33.01 dB)。最后,我们采用更小的过滤器尺寸和更少的过滤器(例如,从 \(Conv(9,64,1)\)到\(Conv(5,56,1)\) ),并获得 41.3X 的最终速度。当我们删除一些冗余参数时,网络的训练效率更高,并实现了另外 0.05 dB 的改进。
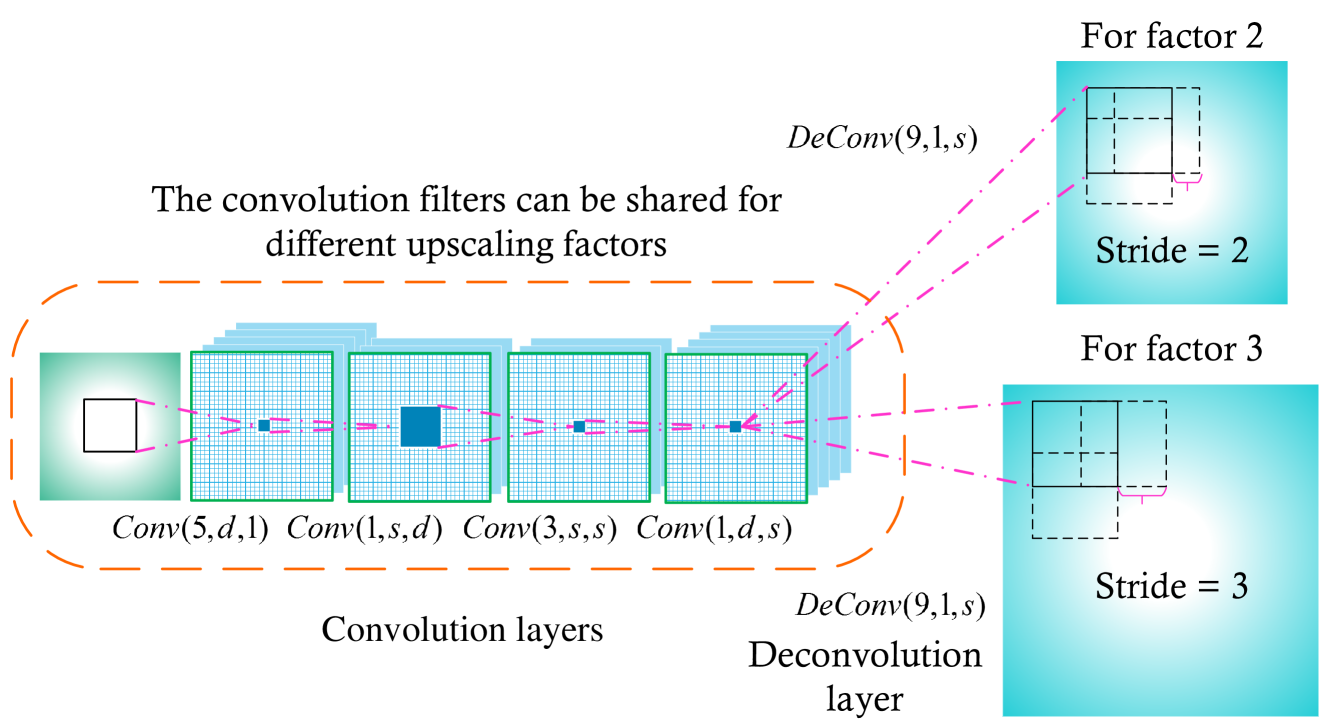
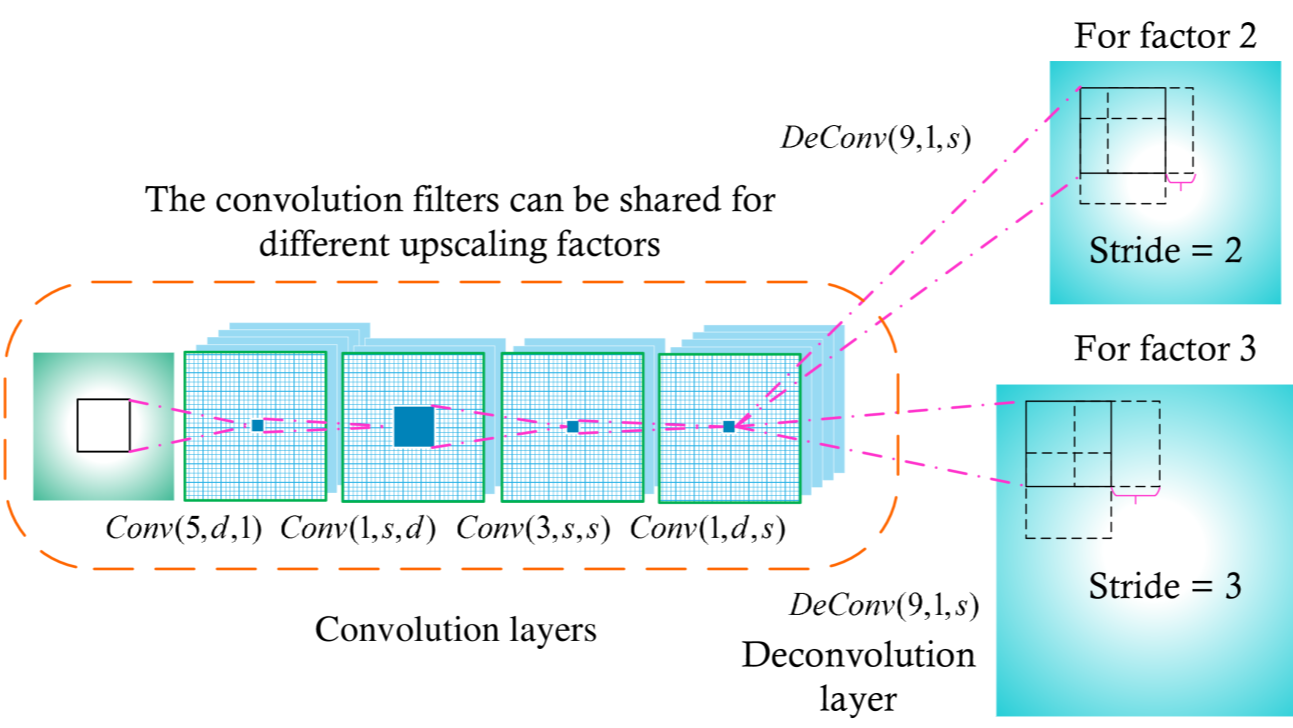
FSRCNN由卷积层和转置卷积层组成。可以针对不同的放大因子共享卷积层。针对不同的放大因子训练特定的转置卷积层。
3.4 不同的放大因子的SR
FSRCNN 的另一个优点是 FSRCNN 可以实现跨不同放大因素的快速训练和测试。具体来说,我们发现所有卷积层总体上都充当LR图像的复杂特征提取器,并且只有最后一个转置卷积层包含放大因子的信息。这也被实验证明了,其中对于不同的放大因子,卷积过滤器几乎是相同的 。利用这个特性,我们可以转移卷积过滤器以进行快速训练和测试。
在实践中,我们提前训练一个放大因子的模型。然后在训练过程中,我们仅针对另一个放大因子微调转置卷积层,并保持卷积层不变。微调速度很快,并且性能与从头开始训练一样好。在测试过程中,我们执行一次卷积运算,并使用相应的转置卷积层将图像上采样到不同的尺寸。
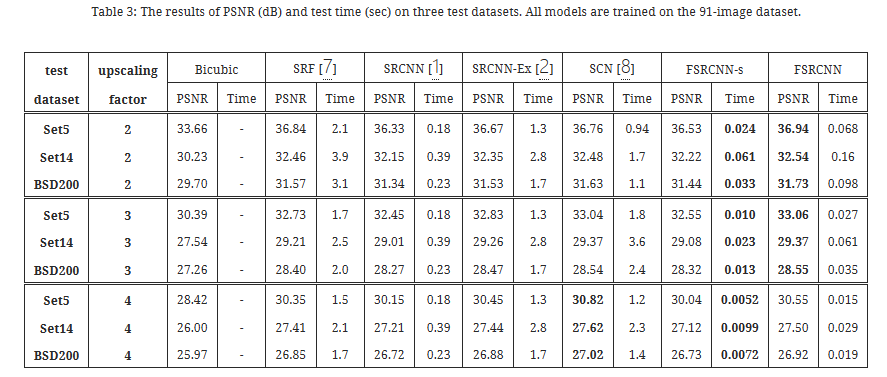
4. 实验
4.1 实施细节
数据集:
- JPEG格式对于SR任务来说并不是最佳的
- General-100数据集,其中包含100个bmp格式图像(无压缩)
- 大小范围从710x704(大)到131x112(小)
- 它们的质量都很好,边缘清晰,但平滑区域较少(例如天空和海洋),因此非常适合SR训练
为了充分利用数据集,采用数据增强:
- 缩放:每个图像按因子0.9、0.8、0.7和0.6缩小
- 旋转:每张图像旋转90°、180°和270°
测试和验证数据集:
使用Set5、Set14和BSD200数据集进行测试。从 BSD500 数据集的验证集中选择另外 20 个图像进行验证。
训练样本:
首先按需要的缩放因子 n 对原始训练图像进行下采样,以形成LR图像。然后,我们将LR训练图像裁剪为一组 \(f_{sub} \times f_{sub}\) 像素子图像,步幅为 \(k\) 。相应的HR子图像(大小为 \((n \times f_{sub})^2\) )也从真实有效的图像中裁剪出来。这些 LR/HR 子图像对是主要训练数据。
对于填充问题,我们凭经验发现填充输入或输出映射对最终性能影响不大。因此,我们根据过滤器的大小在所有层中采用零填充。这样,就不需要针对不同的网络设计改变子图像的大小。
影响子图像大小的另一个问题是反卷积层。当我们使用 Caffe 包 训练模型时,其转置卷积滤波器将生成大小为 \((nf_{sub}-n+1)^2\)而不是\((nf_{sub})^2\)的输出。因此,我们还裁剪 HR 子图像上的 \((n-1)\) 像素边框。最后,对于 x2, x3, x4,我们将LR/HR子图像对的大小设置为 \(10^2/19^2\)、\(7^2/19^2\) 和 \(6^2/21^2\)。
训练策略:
当使用91张图像数据集进行训练时,卷积层的学习率为 \(10^{-3}\) ,转置卷积层的学习率为 \(10^{-4}\) 。然后在微调时,所有层的学习率都降低一半。
4.2 不同设置的调查
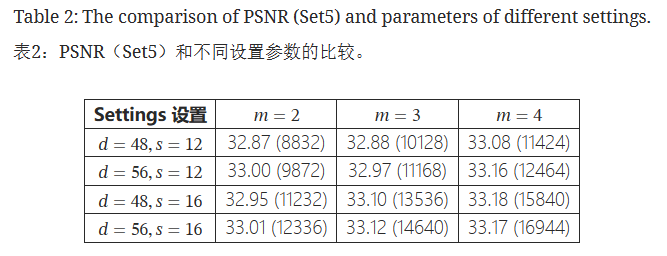
为了测试FSRCNN结构的性能,我们设计了一组具有不同值的三个敏感变量的控制实验——LR特征维度 d 、收缩滤波器的数量 s 、和映射深度 m 。具体来说,我们选择 d = 48 , 56 、 s = 12 , 16 和 m = 2 , 3 , 4 ,因此我们用不同的组合进行了总共 2 × 2 × 3 = 12 次实验。
这些实验在Set5数据集上的平均PSNR值如表所示。我们从表中的水平和垂直两个方向分析结果。首先,我们修复d , s 并检查 m 的影响。显然, m = 4 比 m = 2 和 m = 3 产生更好的结果。其次,我们修复 m 并检查 d 和 s 的影响。一般来说,更好的结果通常需要更多的参数(例如,更大的 d 或 s ),但更多的参数并不总是保证更好的结果。从所有结果中,我们找到了性能和参数之间的最佳权衡——FSRCNN (56,12,4),它以适度数量的参数实现了最高结果之一。
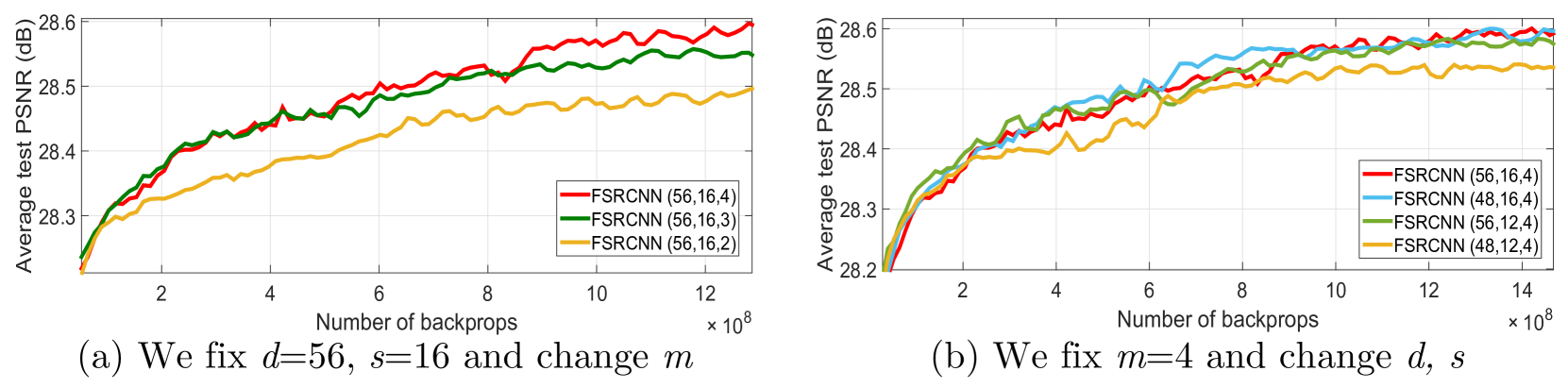
4.3 利用FSRCNN实现实时SR
4.4 不同放大因子的实现
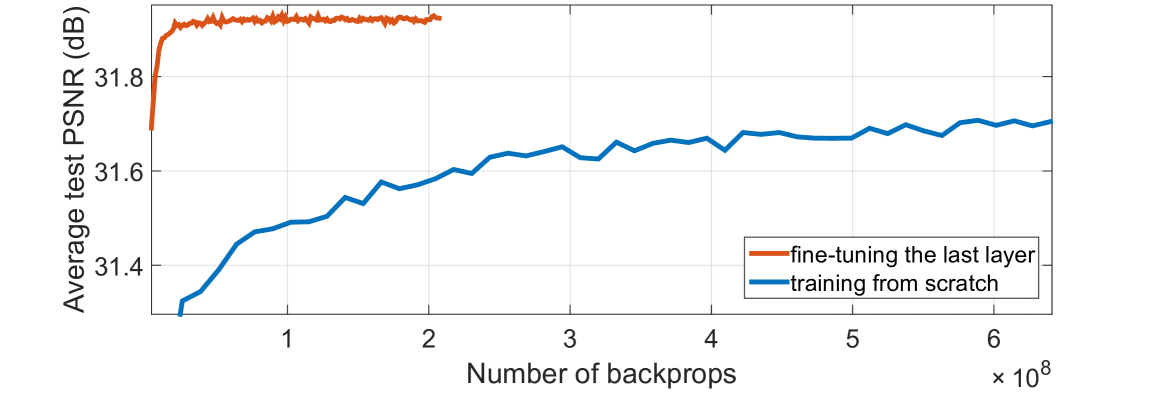
与需要从头开始针对不同缩放因子训练网络的现有方法不同,所提出的 FSRCNN 通过传输卷积滤波器具有跨缩放因子学习和测试的灵活性。我们在本节中展示了这种灵活性。我们选择 FSRCNN (56,12,4) 作为默认网络。由于我们在放大因子 3 下获得了训练有素的模型,因此我们在 × 3 的基础上训练 × 2 的网络。具体来说,训练好的模型中所有卷积过滤器的参数都转移到 × 的网络中。 2.在训练过程中,我们只在91图像和General-100图像上微调转置卷积层 × 2 的数据集。为了进行比较,我们也为 × 2 训练另一个网络,但从头开始。这两个网络的收敛曲线如图所示。显然,通过传递参数,网络收敛得非常快(仅几个小时),并且具有与从头开始训练相同的良好性能。
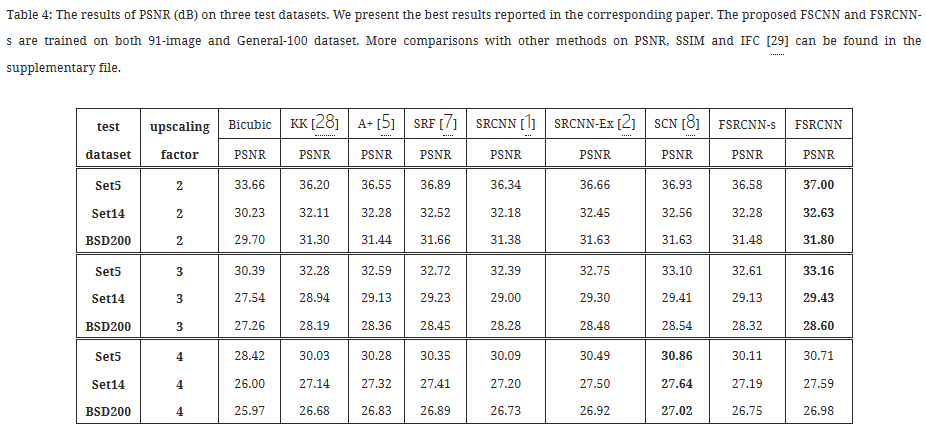
4.5 与现有技术的比较
5. 结论