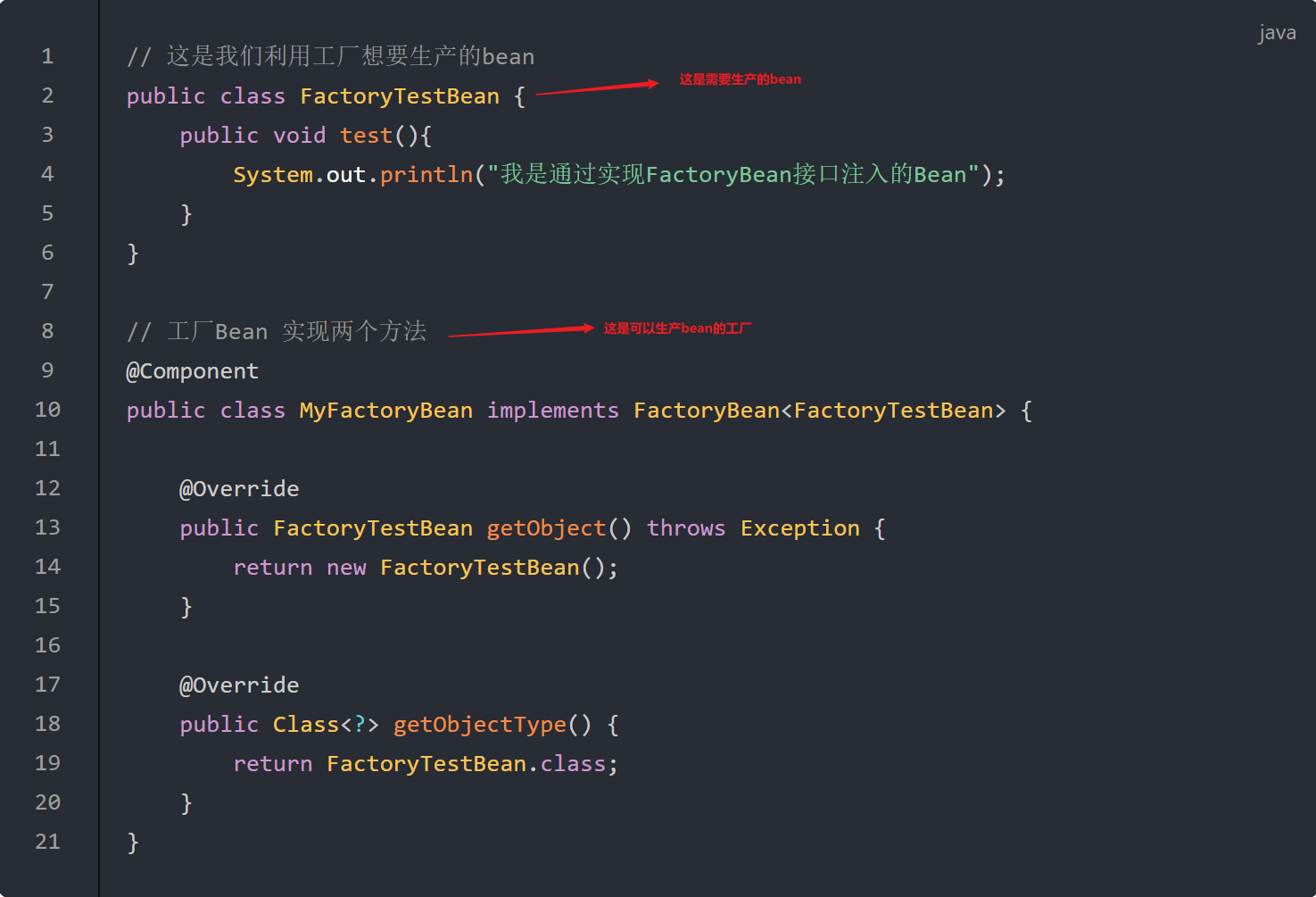
在强化学习中,SARSA和Q-Learning是两种经典的时间差分(TD)控制算法,用于优化智能体的策略。它们的核心区别在于目标Q值的计算方式,分别对应在线策略(On-Policy)和离线策略(Off-Policy)的学习范式。以下是两者的详细介绍和对比:
一、Q-Learning 算法
1. 核心思想
- 离线策略:学习的是最优策略的Q值(即假设下一步采取当前认为的最优动作,无论实际策略如何选择动作)。
- 更新公式:
[
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_t + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right]
]
其中:- ( \alpha ) 是学习率,( \gamma ) 是折扣因子;
- ( \max_{a'} Q(s_{t+1}, a') ) 表示下一状态 ( s_{t+1} ) 的最优动作值。
2. 特点
- 探索与利用:通常结合 ( \epsilon )-贪心策略(以 ( \epsilon ) 概率随机探索,( 1-\epsilon ) 概率选择当前最优动作)。
- 收敛性:在有限状态-动作空间下,Q-Learning 收敛到最优策略的Q值(前提是所有状态-动作对被无限次访问)。
- 应用场景:适合环境模型未知且需要直接优化最优策略的场景(如Atari游戏、围棋等)。
二、SARSA 算法
1. 核心思想
- 在线策略:学习的是当前策略的Q值(即下一步实际采取的动作 ( a_{t+1} ) 由当前策略生成)。
- 更新公式:
[
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_t + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) \right]
]
其中:- ( a_{t+1} ) 是根据当前策略(如 ( \epsilon )-贪心)选择的下一动作。
2. 特点
- 策略一致性:更新依赖于当前策略生成的动作序列(( s_t, a_t \rightarrow s_{t+1}, a_{t+1} )),因此更保守。
- 收敛性:收敛到当前策略(如 ( \epsilon )-贪心策略)的Q值,而非最优策略。
- 应用场景:适合连续动作空间或需要严格遵循当前策略的场景(如机器人控制、路径规划等)。
三、对比:SARSA vs. Q-Learning
| 维度 | Q-Learning | SARSA |
|---|---|---|
| 策略类型 | 离线策略(学习最优策略) | 在线策略(学习当前策略) |
| 目标Q值 | 下一状态的最优动作值(( \max Q(s', a') )) | 下一状态的实际动作值(( Q(s', a') )) |
| 探索方式 | 基于最优动作的估计(可能过度乐观) | 基于当前策略的动作(更谨慎) |
| 收敛目标 | 最优Q值(( Q^*)) | 当前策略的Q值(( Q^\pi )) |
| 样本效率 | 较低(依赖最优估计的偏差) | 较高(样本与策略一致) |
| 风险偏好 | 更冒险(追求潜在最优) | 更保守(避免未知风险) |
四、总结
- Q-Learning:通过“想象”最优动作来更新,适合探索未知环境并直接优化最优策略。
- SARSA:通过“执行”当前策略的动作来更新,适合需要策略一致性的场景(如安全敏感任务)。
一句话记忆:
- Q-Learning:“看着最好的路走”(离线最优)。
- SARSA:“沿着自己的路走”(在线策略)。
五、示例(表格更新对比)
假设状态 ( s ),动作 ( a ),奖励 ( r ),下一状态 ( s' ):
| 算法 | 动作选择(当前策略) | 更新目标(下一状态Q值) | 公式简写 |
|---|---|---|---|
| Q-Learning | ( \epsilon )-贪心 | ( \max_a Q(s', a) ) | ( Q(s,a) \leftarrow r + \gamma \max Q' - Q ) |
| SARSA | ( \epsilon )-贪心 | ( Q(s', a') )(实际选择的 ( a' )) | ( Q(s,a) \leftarrow r + \gamma Q' - Q ) |
六、应用案例
- Q-Learning:Atari游戏(如《太空侵略者》)、棋盘游戏(如井字棋)。
- SARSA:机器人导航(连续动作空间)、经典控制问题(如悬崖行走)。
通过选择合适的算法,智能体可以在探索与利用之间平衡,逐步优化策略以最大化累积奖励。两者均为强化学习的基础算法,后续的改进(如深度强化学习中的DQN、SAC等)均基于这些思想扩展而来。