Hadoop
Hadoop是一个能够对大量数据进行分布式处理的软件框架
HDFS
HDFS(Hadoop Distributed File System,Hadoop的分布式文件管理系统),是Hadoop的两大核心之一,用于管理数据和文件
Hadoop安装
Hadoop可以在Window系统上运行,但其官方支持的操作系统只有Liunx,所以先要准备好虚拟机
虚拟机准备好,可以创建一个hadoop用户,以便于今后使用
sudo useradd -m 用户名 -s /bin/bash #创建用户
sudo passwd 用户名 #设置密码,需要输入两次
sudo adduser 用户名 sudo #增加管理员权限
创建完成后,注销现用户,改用hadoop用户登录虚拟机
接下来正式安装hadoop
java安装
hadoop是由Java编写的,所以需要安装jdk
你可以先使用java -version来查看你的jdk版本,如果能显示java version信息,说明你已经安装了,跳过这一节
如果你没有安装,请遵循以下步骤
1.选择正确的JDK
首先,请选择与Hadoop版本相匹配的JDK版本,这里使用的是Hadoop3.3.6,匹配JDK1.8
tips:JDK8和JDK1.8是一个东西,原因是JDK在5版本以前都叫做1.x,后面就直接叫JDK5,JDK6了
Hadoop版本相匹配的JDK版本百度一下就知道了
2.安装java环境
在/usr/lib目录下创建jvm文件夹 ,用于存储JDK文件,命令如下
cd /usr/lib #进入lib目录
sudo mkdir jvm #此命令为创建文件夹命令
然后百度搜索JDK Download,进入oracle官网,下载名字类似于此文件的压缩包:
jdk-8u202-linux-x64.tar.gz
jdk-版本号-操作系统-系统位数.tar.gz,jdk8,liunx系统,64位,.tar.gz是压缩包的后缀名,类似于zip,rar
注意,下载到你的虚拟机上,别下你的主机里
默认的下载位置是主文件夹/下载(或Download)
进入该文件夹,打开终端,使用一下命令解压压缩包
sudo tar -zxvf 你的压缩包名称 -C /usr/lib/jvm
# tar为压缩包命令 -zxvf表示解压.tar.gz后缀的压缩包 , -C和目录,表示解压到该目录下,这里直接解压到jvm目录下,你手动移动也可以
然后添加环境变量,打开~/下的.bashrc文件,用VIM也可以,用文本编辑器也可以,添加以下变量
export JAVA_HOME=/usr/lib/jvm/你的jdk文件夹名
export JRE_HOME=S{JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:${PATH}
保存,退出,使用以下命令刷新配置
source ~/.bashrc
然后输入java -version,查看是否出现java版本,出现成功
Hadoop下载
Apache Hadoop←Hadoop官网
进去,点击Download
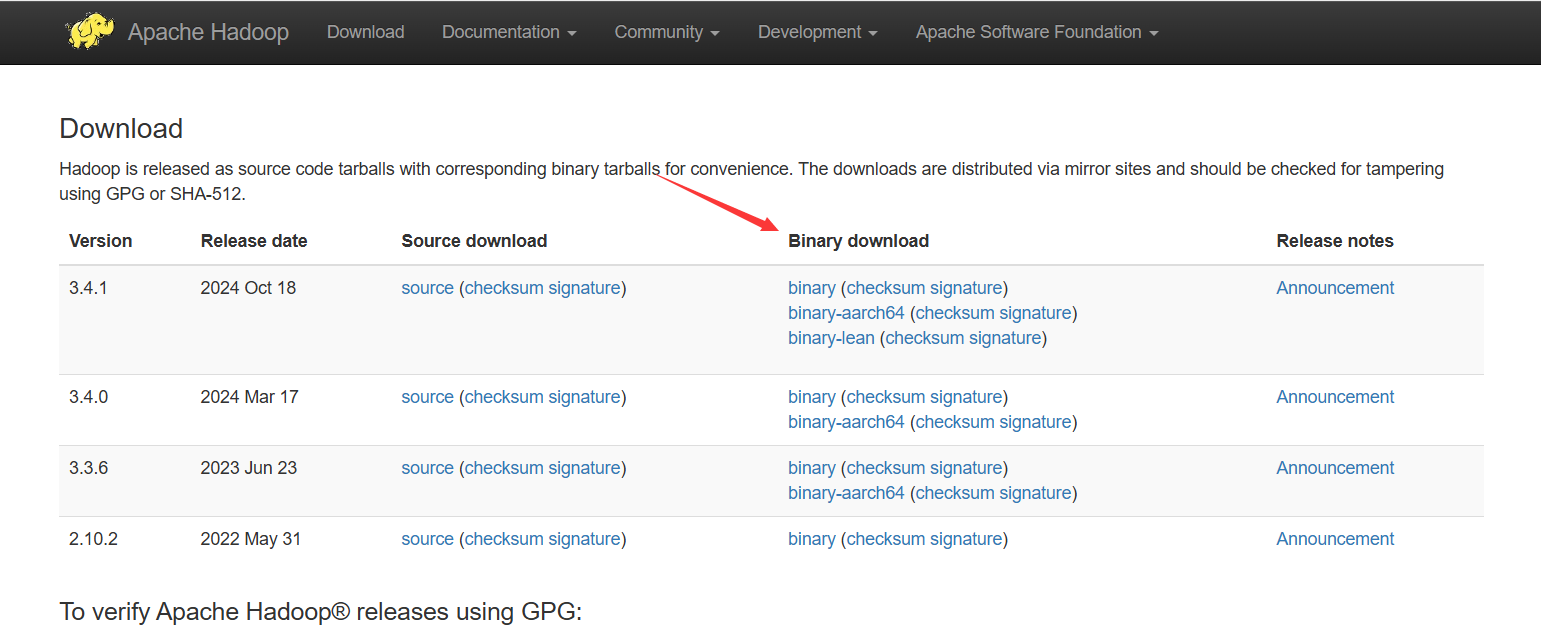
选择你要下载的版本,点BinaryDownload那栏的binary,进去后,点击最上面的带有.tar.gz后缀的连接,下载Hadoop压缩包
下载完成后,解压到/usr/local/目录下,解压命令为 tar -zxvf 压缩包名,上面解压JDK说过了
如果你下载的对的话,解压后的Hadoop文件夹应该是这样的
解压完成后,在/usr/local/目录下打开终端,输入以下命令
sudo mv ./你的hadoop文件夹名 ./hadoop #将你的hadoop文件夹名修改为hadoop
sudo chown -R hadoop ./hadoop #修改目录权限
然后再去~/.bashrc文件下添加环境变量
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#将path修改为下面的
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${PATH}
输入hadoop version,查看hadoop版本,如果出现,成功
伪分布式安装
Hadoop对数据存储使用的是HDFS,在实际生产环境下是采用完全分布式模式的,HDFS在不同的机器上有不同的节点
对于初学者使用伪分布式即可,即HDFS只有一个节点,也就是你的虚拟机
无论哪种方式,都需要修改配置文件来对各组件的合作进行配置。伪分布式安装需要我们配置core-site.xml和hdfs-site.xml两个文件
这两个文件里默认是只有一些注释的,在文件的末尾添加以下配置
core-site.xml:
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value></property><!--配置HDFS的地址和端口号--><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value> </property>
</configuration>
hdfs-site.xml:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop/tmp/dfs/data</value></property></configuration>
配置完成后,回到你的hadoop文件夹,执行以下命令
cd /usr/local/hadoop #回到hadoop文件夹
./bin/hdfs namenode -format
这一步是初始化HDFS,如果出现successfully formatted成功
错误情况
如果在初始化时出现ERROR:Unable to wirte in /usr/local/hadoop/logs. Aborting.,说明权限不够,有两种情况:
1.用户权限不够
2.文件权限不够
解决方案如下:
在命令前添加sudo前缀,使用root用户
设置SSH免密登录
Hadoop没有提供输入密码形式的SSH登录,所以要设置SSH免密登录
首先安装SSH,ubuntu默认安装了客户端,所以这里只需要安装服务器端
sudo apt-get install openssh-server
安装后,使用下命令登录本机
ssh localhost
执行改命令后会让你输入密码,就是你用户的密码
登录成功后,输入exit退出,打开/etc/ssh/sshd_config,修改一下配置文件
#将以下三个属性修改为yes,可以用ctrl+f查找
PubkeyAuthentication yes
PasswordAuthentication yes
PermitRootLogin yes
修改完后,输入以下命令来设置免密
cd ~/.ssh #进入ssh文件夹
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
执行ssh localhost登录本机,如果不需要密码就登陆成功了,说明免密登录成功
root用户设置免密
这一步请跳过,后面出现错误时会指引你回来的
root用户设置免密和普通用户一样,只是进入root用户下在进行上面的免密操作即可
sudo su #进入root用户
同样的使用ssh localhost来测试在root用户下是否可以免密成功
启动HDFS
进入/usr/local/hadoop执行以下命令
./sbin/start.dfs.sh #启动sbin目录下的start.dfs.sh脚本,用于启动hdfs
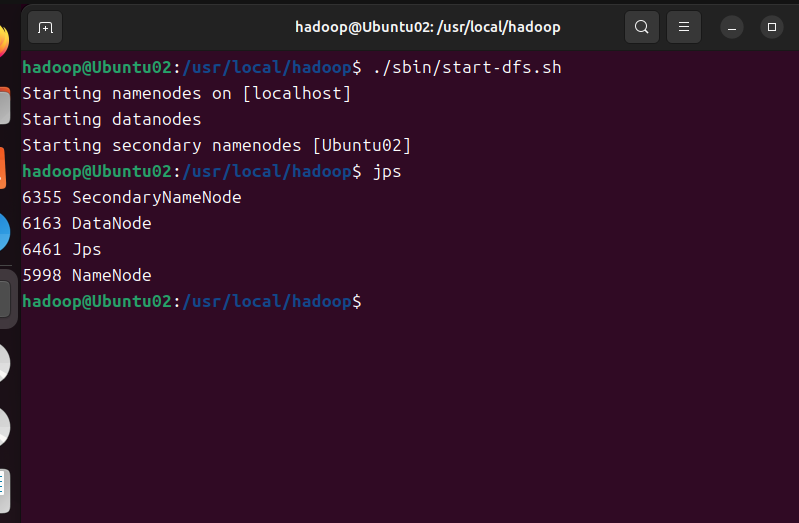
启动后如这样形式,输入jps后存在datenode和Namenode,代表HDFS启动成功
可以通过访问localhost:9870来验证并查看Hadoop的信息