 多线程允许程序同时执行多个任务,提升效率和响应性。线程分为新建、就绪、运行、阻塞和死亡五种状态。Python的GIL锁限制多线程并行执行,适合I/O密集型任务。生产者-消费者模型通过共享缓冲区和条件变量实现线程协作,解决数据共享问题。
多线程允许程序同时执行多个任务,提升效率和响应性。线程分为新建、就绪、运行、阻塞和死亡五种状态。Python的GIL锁限制多线程并行执行,适合I/O密集型任务。生产者-消费者模型通过共享缓冲区和条件变量实现线程协作,解决数据共享问题。一文速通 Python 并行计算:01 Python 多线程编程-基本概念、切换流程、GIL 锁机制和生产者与消费者模型

摘要:
多线程允许程序同时执行多个任务,提升效率和响应性。线程分为新建、就绪、运行、阻塞和死亡五种状态。Python的GIL锁限制多线程并行执行,适合I/O密集型任务。生产者-消费者模型通过共享缓冲区和条件变量实现线程协作,解决数据共享问题。

关于我们更多介绍可以查看云文档:Freak 嵌入式工作室云文档,或者访问我们的 wiki:https://github.com/leezisheng/Doc/wik
原文链接:
FreakStudio的博客
往期推荐:
学嵌入式的你,还不会面向对象??!
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
全网最适合入门的面向对象编程教程:56 Python字符串与序列化-正则表达式和re模块应用
全网最适合入门的面向对象编程教程:57 Python字符串与序列化-序列化与反序列化
全网最适合入门的面向对象编程教程:58 Python字符串与序列化-序列化Web对象的定义与实现
全网最适合入门的面向对象编程教程:59 Python并行与并发-并行与并发和线程与进程
一文速通Python并行计算:00 并行计算的基本概念
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一文搞懂 CM3 单片机调试原理
肝了半个月,嵌入式技术栈大汇总出炉
电子计算机类比赛的“武林秘籍”
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
Avnet ZUBoard 1CG开发板—深度学习新选择
工程师不要迷信开源代码,还要注重基本功
什么?配色个性化的电机驱动模块?!!
什么?XIAO主控新出三款扩展板!
手把手教你实现Arduino发布第三方库
万字长文手把手教你实现MicroPython/Python发布第三方库
文档获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc
该文档是一份关于 并行计算 和 Python 并发编程 的学习指南,内容涵盖了并行计算的基本概念、Python 多线程编程、多进程编程以及协程编程的核心知识点:
正文
1.多线程的基本概念
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
(1)使用线程可以把占据长时间的程序中的任务放到后台去处理;
(2)用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度;
(3)程序的运行速度可能加快
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
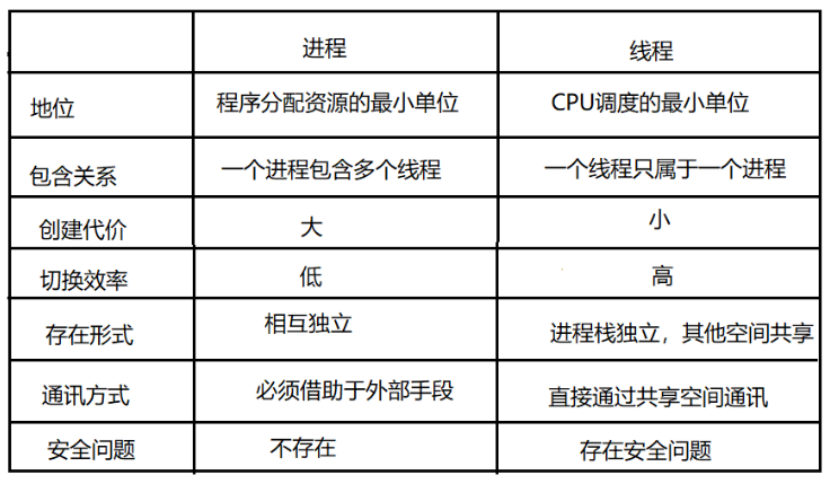
线程在执行过程中与进程还是有区别的。每个独立的进程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
2.Python 中的多线程
2.1 基本概念
线程,有时被称为轻量进程,是程序执行流的最小单元。一个标准的线程由线程 ID,当前指令指针(PC),寄存器集合和堆栈组成。线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程不拥有私有的系统资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。
线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派 CPU 的基本单位指令运行时的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。Python 多线程用于 I/O 操作密集型的任务,如 SocketServer 网络并发,网络爬虫。
2.2 线程的不同状态和切换流程
程序中包含多个线程时,CPU 不是一直被特定的线程霸占,而是轮流执行各个线程。那么,CPU 在轮换执行线程的过程中,即从创建到消亡的整个过程,可能会历经 5 种状态,分别是新建、就绪、运行、阻塞和死亡。
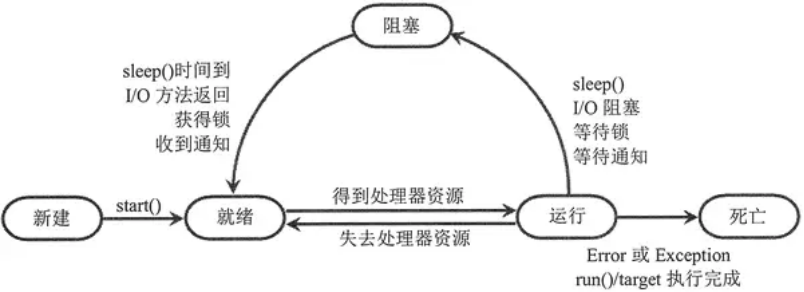
- 线程的新建状态:无论是通过 Thread 类直接实例化对象创建线程,还是通过继承自 Thread 类的子类实例化创建线程,新创建的线程在调用 start() 方法之前,不会得到执行,此阶段的线程就处于新建状态。
- 线程的就绪状态:当位于新建状态的线程调用 start() 方法后,该线程就转换到就绪状态。所谓就绪,就是告诉 CPU,该线程已经可以执行了,但是具体什么时候执行,取决于 CPU 什么时候调度它。换句话说,如果一个线程处于就绪状态,只能说明此线程已经做好了准备,随时等待 CPU 调度执行,并不是说执行了 start() 方法此线程就会立即被执行。
- 线程的运行状态:当位于就绪状态的线程得到了 CPU,并开始执行 target 参数执行的目标函数或者 run() 方法,就表明当前线程处于运行状态。但如果当前有多个线程处于就绪状态(等待 CPU 调度)时,处于运行状态的线程将无法一直霸占 CPU 资源,为了使其它线程也有执行的机会,CPU 会在一定时间内强制当前运行的线程让出 CPU 资源,以供其他线程使用。**
- 线程的阻塞状态:当 CPU 对多个线程进行调度时,对于获得 CPU 调度却没有执行完毕的线程,就会进入阻塞状态。目前几乎所有的桌面和服务器操作系统,都采用的是抢占式优先级调度策略。即** CPU 会给每一个就绪线程一段固定时间来处理任务,当该时间用完后,系统就会阻止该线程继续使用 CPU 资源,让其他线程获得执行的机会**。对于具体选择那个线程上 CPU,不同的平台采用不同的算法,比如先进先出算法(FIFO)、时间片轮转算法、优先级算法等,每种算法各有优缺点,适用于不同的场景。
除此之外,如果处于运行状态的线程发生如下几种情况,也将会由运行状态转到阻塞状态:
以上 4 种可能发生线程阻塞的情况,解决措施分别如下:
- 线程死亡状态:对于获得 CPU 调度却未执行完毕的线程,它会转入阻塞状态,待条件成熟之后继续转入就绪状态,重复争取 CPU 资源,直到其执行结束。执行结束的线程将处于死亡状态。线程执行结束,除了正常执行结束外,如果程序执行过程发生异常(Exception)或者错误(Error),线程也会进入死亡状态。
对于处于死亡状态的线程,有以下 2 点需要注意:
- ①主线程死亡,并不意味着所有线程全部死亡。也就是说,主线程的死亡,不会影响子线程继续执行;反之也是如此。
- ②对于死亡的线程,无法再调用 start() 方法使其重新启动,否则 Python 解释器将抛出 RuntimeError 异常。
2.3 Pythn 中的 GIL 锁机制
GIL,全称是 Global Interpreter Lock,也叫做全局解释器锁。对于 CPython,所有的 Python 线程都需要在解释器这个虚拟机中运行,而在运行之前都要先获取 GIL 这个锁,然后每执行 100 个字节码,解释器就自动释放 GIL 锁,让别的线程有机会执行。因此即使你有多个 CPU 核,多个线程在同一个 Python 虚拟机中也应该是交替执行的。
这就意味着:同一时间,只能有一个线程在执行的状态。GIL 对单线程程序没有影响,但会成为 CPU 密集和多线程代码的性能瓶颈。即使在多线程结构的代码中,在同一时刻 GIL 也只允许一个线程在执行状态,因此,GIL 成为了 Python 不受欢迎的一个特性。
CPU 密集型程序是指程序运行过程中 CPU 是性能瓶颈,该类程序会涉及大量数学计算,例如矩阵乘法/搜索/图像处理等。I/O 密集型程序是指程序花费了大部分时间来等待 I/O 事件,I/O 事件可能来自用户/文件/数据库/网络等。在从数据源获取到文件之前,I/O 密集型程序需要等待大量的时间;因为在 I/O 事件就绪前,数据源需要进行自己的处理过程。例如:用户花费时间思考向输入提示符输入什么内容(会占用时间),或者数据库在接收到检索请求后运行自己的程序(会占用时间)。
解决 GIL 的方法包括使用多进程、使用其他 Python 解释器或使用 C 扩展模块等。
2.4 生产者-消费者模型
生产者-消费者模式是一种经典的多线程设计模式,用于解决多个线程之间的数据共享和协作问题。在生产者-消费者模式中,有两类线程:生产者线程和消费者线程。它们之间通过共享一个缓冲区(或队列)来协作,生产者将数据放入缓冲区,消费者从缓冲区取出数据并进行处理。
生产者-消费者模式包括以下几个基本要素:
- (1)缓冲区(或队列):用于存储生产者生成的数据,以及消费者待处理的数据。缓冲区可以是有界的(固定容量)或无界的(容量动态增长)。
- (2)生产者:负责生成数据并将数据放入缓冲区。生产者线程通常会等待,如果缓冲区已满,则等待消费者取走数据后继续生产。
- (3)消费者:负责从缓冲区取出数据并进行处理。消费者线程通常会等待,如果缓冲区为空,则等待生产者放入数据后继续消费。
- (4)互斥锁:用于保护对缓冲区的访问,确保同时只有一个线程可以访问缓冲区。
- (5)条件变量:用于实现线程的等待和唤醒机制。生产者线程可以等待缓冲区不满,而消费者线程可以等待缓冲区不空。
下一节中,我们将通过生产者-消费者模型讲解 Python 多线程中的各个概念和应用方法。