ZipList
基于特殊写法实现的双端链表,由一系列特殊编码的连续内存块组成,可以像deque一样在双端压入/弹出,并且时间复杂度在O(1)
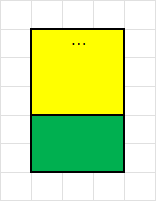
整体ZL结构如下

zlbytes(uint32):当前zl总的byte数。
zltail(uint32):尾结点的offset,指向的是最后一个entry的起始地址。
zllen(uint16):记录entry的个数。4字节最多能记录到UINT16_MAX(65534),后续超过这个值会被记录为65535,此时len就不再是真实节点数量。
zlend(uint8):特殊值,结束标示:0xff。
entry(zipListEntry):第一个entry称为头结点;最后一个entry称为尾结点。
ziplistentry内部存储格式

- previous_entry_length:前一节点的长度,占1个或5个字节。
- 前一节点长度如果小于254byte,则采用1字节保存其长度值
- 前一节点长度如果大于254byte,则采用5字节保存其长度值,第一个字节为0xfe,后续才是真实长度数据
- encoding:编码属性,记录content数据类型与长度,可能占1/2/5个字节
- contents:就是data,可能是字符串或整数
zl是在内存中一块连续的存储空间,并且基于上述结构实现了特殊的双端链表
- 后驱的情况下,我们可以根据当前entry的总长度推出下一个entry的起始地址;
- 前驱的情况下,我们可以通过previous_entry_length获取上一节点的位置。
此外zl会根据编码来存储字符串/整数。
encoding以00,01,10开头时说明存储的是字符串,并且根据其二进制大小来确认字符串长度大小
encoding以11开头说明存储的是整数,并且特别优化的一点是:当整数太小(大概是0~12),content直接存放在encoding即可,不需要再浪费额外空间
问题:当链表过于冗长的时候,查询的性能会很差(因为只能从头到尾遍历或者从尾向头遍历),因此使用zl时需要控制其len的大小
ziplistEntry外部接口
typedef struct {unsigned char *sval; // 指向字符串值的指针unsigned int slen; // 字符串的长度long long lval; // 整数值(当条目是整数时使用) } ziplistEntry;
这是redis内提供给外部使用的ziplistEntry源码。这个结构体让使用者不需要具体关心zl的内部实现,即可方便调用,是一种解耦思想。
zipList连锁更新问题(作者也没解决)
zipList中每个entry都包含了一个previous_entry_length用于记录上一个节点大小。(规则在内部存储格式)
:假设有连续多个长度为250~252字节长度的entry,此时每一个previous_entry_length都只用1个字节存储。
但如果头插了一个长度大于等于254字节的entry,会导致原本长度在250~252字节长度的entry需要修改pre_entry_length(由原本的1字节存储变为5字节存储,这会导致entry整体大小超过254)。
而多个长度擦边的entry,会不断向后申请空间
虽然没有解决,但是后续作者提出来用listPack(redis5.0+)替换zipList,但是由于改动过大,并且出现问题概率太小,作者也只是在stream里使用了listPack,正常情况下list、set等还是基于zipList的