 单图像超分辨率(SISR)的最新进展已经实现了非凡的性能,但计算成本太高,无法应用于边缘设备。为了缓解这个问题,已经提出了许多新颖有效的解决方案。**具有注意力机制的卷积神经网络(CNN)因其效率和有效性而受到越来越多的关注**。但是,卷积运算中仍然存在冗余。在本文中,我们提出了包含两种高效设计的**蓝图可分离残差网络(BSRN)**。**一种是蓝图可分离卷积 (BSConv) 的使用,它取代了冗余卷积操作。二是通过引入更有效的注意力模块来增强模型能力**。实验结果表明,BSRN在现有的高效SR方法中取得了最先进的性能。此外,我们型号 BSRN-S 的较小变体在 NTIRE 2022 Efficient SR Challenge 的模型复杂性赛道中获得了第一名。该代码可在 https://github.com/xiaom233/BSRN 上获得。
单图像超分辨率(SISR)的最新进展已经实现了非凡的性能,但计算成本太高,无法应用于边缘设备。为了缓解这个问题,已经提出了许多新颖有效的解决方案。**具有注意力机制的卷积神经网络(CNN)因其效率和有效性而受到越来越多的关注**。但是,卷积运算中仍然存在冗余。在本文中,我们提出了包含两种高效设计的**蓝图可分离残差网络(BSRN)**。**一种是蓝图可分离卷积 (BSConv) 的使用,它取代了冗余卷积操作。二是通过引入更有效的注意力模块来增强模型能力**。实验结果表明,BSRN在现有的高效SR方法中取得了最先进的性能。此外,我们型号 BSRN-S 的较小变体在 NTIRE 2022 Efficient SR Challenge 的模型复杂性赛道中获得了第一名。该代码可在 https://github.com/xiaom233/BSRN 上获得。BSRN:蓝图可分离残差网络实现高效图像超分辨率
Blueprint Separable Residual Network for Efficient Image Super-Resolution
蓝图可分离残差网络实现高效图像超分辨率
https://arxiv.org/abs/2205.05996
https://github.com/xiaom233/bsrn
CVPRW 2022
Abstract
- 问题:单图像超分辨率 (SISR) 的最新进展取得了非凡的性能,但计算成本太高,无法应用于边缘设备
- 方法:提出了包含两个有效设计的蓝图可分离残差网络 (BSRN)
- 一种是使用蓝图可分离卷积 (BSConv),它代替了冗余卷积操作
- 另一种是通过引入更有效的注意力模块来增强模型能力。
- 结果:BSRN 在现有的高效 SR 方法中取得了最先进的性能
- 主要贡献:
- 我们引入 BSConv 来构建基本构建块,并展示其对 SR 的有效性。
- 我们利用两个有效的注意力模块来增强模型能力,这些模块的额外计算有限。
- 所提出的 BSRN 继承了 BSConv 和有效注意力模块,展示了高效SR的卓越性能。
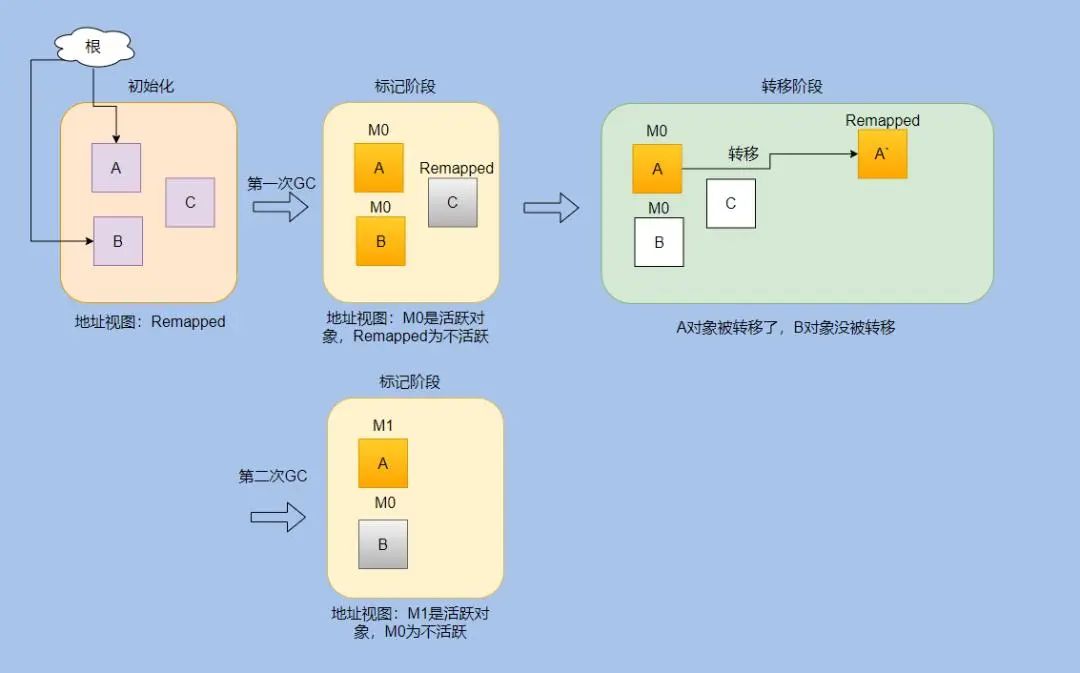
1. 引言
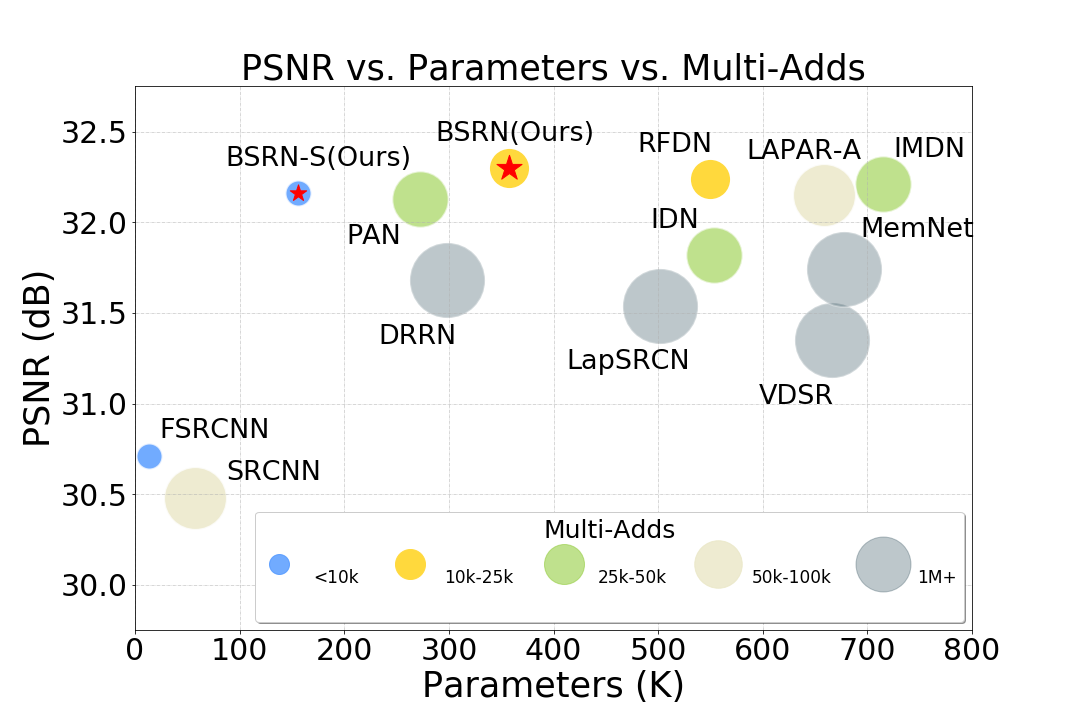
图1:Set5数据集上使用上采样系数X4的性能和模型复杂度比较。
这些SR网络大大提高了恢复图像的质量。他们的成功可以部分归因于庞大的模型容量和密集的计算。但是,这些属性可能会在很大程度上限制它们在注重效率或需要实时实现的实际场景中的应用。为了解决低效问题,已经提出了许多轻量级SR网络。这些方法使用不同的策略来实现高效率,包括参数共享策略,具有分组卷积的级联网络,信息或特征蒸馏机制和注意力机制。虽然它们应用了紧凑的架构并提高了映射效率,但卷积操作中仍然存在冗余。我们可以通过减少冗余计算和利用更有效的模块来构建更高效的SR网络。
在本文中,我们提出了一种新的轻量级SR网络,即蓝图可分离残差网络(Blueprint Separable Residual Network BSRN),它从优化卷积运算和引入有效注意力模块两个角度提高了网络的效率。首先,顾名思义,BSRN通过使用蓝图分离卷积(blueprint separation convolutions BSConv)来构建基本的构建块来减少冗余。BSConv是原始深度可分离卷积(DSConv)的改进变体,它更好地利用核内相关性来实现有效的分离。我们的研究表明,BSConv 有利于高效的 SR。其次,适当的注意力模块已被证明可以提高高效SR网络的性能。受这些工作的启发,我们还引入了两个有效的注意力模块,增强空间注意力(Enhanced Spatial Attention ESA)和对比感知通道注意力(Contrast-aware Channel Attention CCA),以增强模型能力。所提出的BSRN方法在现有的以效率为导向的SR网络中实现了最先进的性能,如图1所示。我们采用了BSRN-S方法的变体参加了NTIRE 2022 Efficient SR Challenge,并在模型复杂度赛道上获得了第一名。

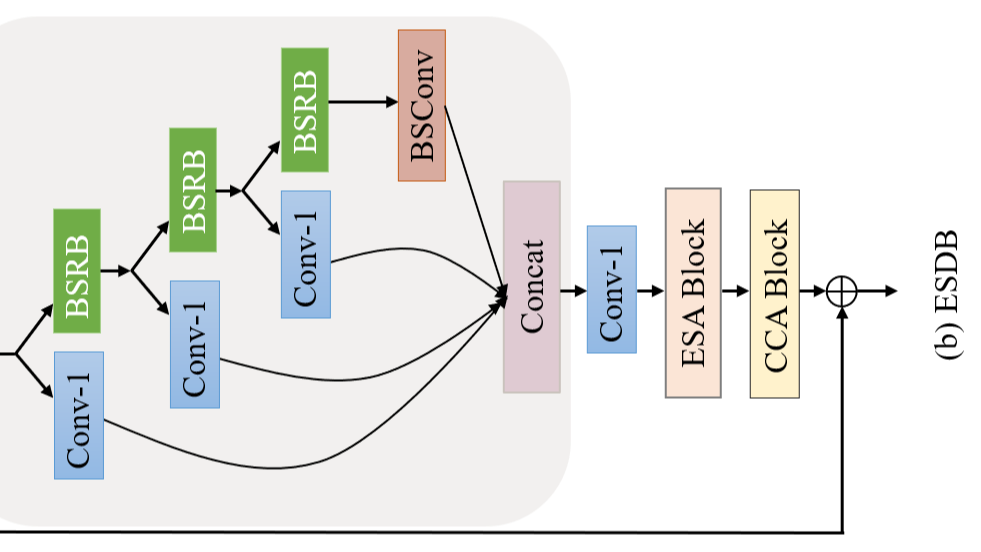
图2:蓝图可分离残差网络(Blueprint Separable Residual Network BSRN)的架构。
2. 相关工作
2.1 SR深度网络
2.2 CNN模型压缩与加速
在过去的几年中,在模型压缩和加速领域取得了巨大进展。一般来说,这些技术可以分为四类:参数剪枝(parameter pruning)、量化(quantization)、低秩分解(low-rank factorization)、知识蒸馏(knowledge distillation)和转移/紧凑卷积滤波器(transferred/compact convolutional filters)。对于参数剪枝和量化方法,旨在探索模型架构的冗余性,并尝试去除或减少冗余参数。低秩因式分解方法使用矩阵/张量分解来估计网络的更多的信息表示。知识蒸馏方法旨在通过学习教师模型的分布,从更大的网络生成更紧凑的学生模型。基于转移/紧凑卷积滤波器设计的方法旨在设计特殊的结构卷积滤波器,以减少模型参数并节省存储计算。
2.3 高效的SR模型
3. 方法
3.1 网络架构

BSRN方法的整体架构如图2所示。它继承自 RFDN 的结构,RFDN是 AIM 2020 高效超分辨率挑战赛的冠军解决方案。它由 浅层特征提取、深层特征提取、多层特征融合和重构 四个阶段组成。
- \(I_{LR}\): 输入图像
- \(I_{SR}\): 输出图像
在预处理中,输入图像首先复制n次。然后我们将这些图像连接在一起
- \(Concat(\cdot)\): 表示沿通道维度的串联运算
- \(n\): 要串联的 \(I_{LR}\) 个数
下一个浅层特征提取部分将输入图像映射到更高维的特征空间,如下所示:
- \(H_{SF}(\cdot)\): 表示浅层特征提取模块
具体来说,我们使用 BSConv 来实现浅层特征提取。BSConv 的具体架构如图3所示,它由 1x1 卷积和深度卷积组成。
\(F_0\) 通过一堆 ESDB 进行深度特征提取,ESDB 逐渐细化提取的特征。这个过程可以表述为
- \(H_k(\cdot)\): 表示 \(k^{th}\) 个 ESDB
- \(F_{k-1}\):表示 \(k^{th}\) ESDB的输入特征
- \(F_{k}\): 表示 \(k^{th}\) ESDB的输出特征
为了充分利用所有深度的特征,通过 1x1 卷积和 GELU 激活对不同深度生成的特征进行融合和映射。然后,使用 BSConv 来优化特征。多层特征融合的表述为
- \(H_{fusion}\): 表示融合模块
- \(F_{fused}\): 表示聚合模块
为了利用残差学习,引入一个长连接。重建阶段表述为
- \(H_{rec}(\cdot)\): 表示重构模块,它由 3x3 标准卷积层和亚像素卷积层(pixel-shuffle)组成。
利用 \(L_1\) 损失函数对模型进行优化,公式为:
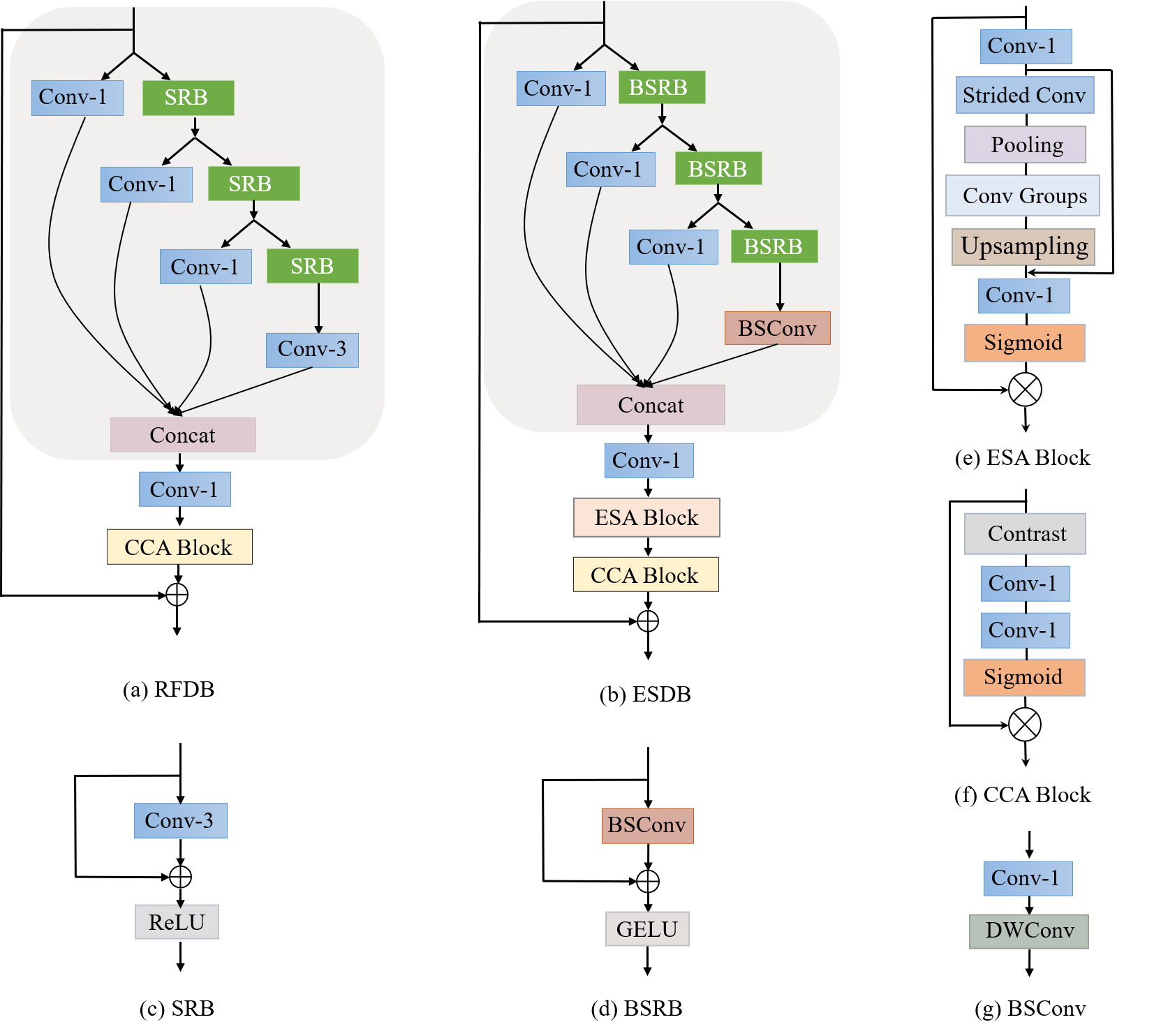
图3:
3.2 高效分离蒸馏块(Efficient Separable Disillation Block)
受RFDN中的RFDB的启发(残余特征蒸馏网络,实现轻量级图像超分辨率 Residual feature distillation network for lightweight image super-resolution.),我们设计了高效的可分离蒸馏块(ESDB),其结构与RFDB相似,但效率更高。ESDB的整体架构如图3(b)所示。ESDB 通常由 3 个阶段组成:
特征蒸馏、特征凝聚和特征增强。
-
特征蒸馏
\[F_{distilled_1},F_{coarse_1} = DL_1(F_{in}),RL_1(F_{in}) \\ F_{distilled_2},F_{coarse_2} = DL_2(F_{coarse_1}),RL_2(F_{coarse_1}) \\ F_{distilled_3},F_{coarse_3} = DL_3(F_{coarse_2}),RL_3(F_{coarse_2}) \\ F_{distilled_4} = DL_3(F_{coarse_2}) \\ \]- \(F_{in}\):输入特征
- \(DL\):生成蒸馏特征的蒸馏层
- \(RL\):逐步细化粗特征的精炼层
-
特征凝聚
\[F_{condensed} = H_{linear}(Concat(F_{distilled_1}, \cdots , F_{distilled_4})) \]- 蒸馏的特征 \(F_{distilled_1},F_{distilled_2},F_{distilled_3},F_{distilled_4}\) 被连接在一起,然后通过 \(1 \times 1\) 卷积凝聚在一起。
- \(F_{condensed}\) :凝聚特征
- \(H_{linear}(\cdot)\):\(1\times 1\) 卷积
-
特征增强
\[F_{enhanced} = H_{CCA}(H_{ESA}(F_{condensed})) \]- 为了保持效率的同时增强模型的表示能力,我们引入了一个轻量级增强的空间注意力(ESA)模块和一个对比感知通道注意力(CCA)模块
- \(F_{enhanced}\):增强的特征
- \(H_{ESA}(\cdot)\):从空间角度显式可有效增强模型能力的 ESA 模块
- \(H_{CCA}(\cdot)\):从通道角度显式可有效增强模型能力的 CCA 模块
蓝图浅层残差块(Blueprint Shallow Residual Block BSRB)。ESDB的基本模块是BSRB,如图3所示,它由 BSConv、特征连接(identity connection)、激活单元组成。具体来说,我们使用 GELU 作为激活函数。BSConv 将标准卷积分解为逐点 \(1\times 1\) 卷积和深度卷积,如图 3 所示。它是深度可分离卷积(DSConv)的逆版本。重新思考深度可分离卷积:内核相关性如何导致改进的移动网络 表明 BSConv 在许多情况下在有效分离标准卷积方面表现更好,因此我们在模型中利用了它。对于激活单元,GELU 逐渐成为近期工作的首选,可以看作是 ReLU 的更平滑的变体。在我们的方法中,我们还发现 GELU 比常用的 ReLU和 LeakyReLU表现更好。
ESA和CCA注意力模块(Attention modules of ESA and CCA):由于ESA和CCA的有效性已被证明,我们将这两个模块引入我们的方法。ESA模块的具体架构如图3(f)所示。它从 \(1\times 1\) 卷积层开始,以减小输入特征的通道维度。然后,该块使用步幅卷积和跨步最大池化层来减小空间大小。在一组卷积提取特征之后,执行基于插值的上采样以恢复空间大小。请注意,我们的ESA中的卷积也是BSConvs,与原始版本不同,效率更高。结合残差连接,卷积层进一步处理 \(1 \times 1\) 特征以恢复通道大小。最后,通过 Sigmoid 函数生成注意力矩阵,并乘以原始输入特征。在图3(f)所示的ESA模块之后增加了一个CCA模块,这是为SR任务提出的信道注意力模块的改进版本。与使用每个通道特征的平均值计算的传统通道注意力不同,CCA利用包括平均值和标准差之和在内的对比度信息来计算通道注意力权重。
4. 实验
4.1 实验设置
数据集和指标(Datasets and Metrics):训练图像包括来自 Flickr2K 的2650张图像和来自 DIV2K 的800张图像。我们使用 Set5、Set14、B100、Urban100和 Manga109 五个标准基准数据集来评估不同方法的性能。Y通道上(即亮度)的平均峰值信噪比(PSNR)和结构相似性(SSIM)被用作评估指标。
BSRN的实施细节(Implementtation details of BSRN):提出的 BSRN 由 8 个 ESDB 组成,通道数设置为 64 个。所有深度卷积的核大小都设置为 3。采用随机旋转90 ° 、180 ° 、270 °和水平翻转的数据增强方法。小批量大小设置为 64,每个 LR 输入的补丁大小设置为 48 × 48 。该模型由 Adam 优化器使用 \(\beta_1\) = 0.9 , \(\beta_2\) = 0.999 。初始学习速率设置为 \(1\times 10^{-3}\) 余弦学习速率衰减。\(L_1\) 损失用于优化总 \(1\times 10^6\) 次迭代的模型。我们使用 Pytorch 在两个 GeForce RTX 3090 GPU 上实现我们的模型,训练过程大约需要 30 小时。
BSRN-S for NTIRE2022 Challenge 的实施细节。BSRN-S 是 BSRN 的一个小变体,专为挑战而设计,它要求参与者设计一个高效的网络,同时在 DIV2K 验证数据集上保持 29.00dB 的 PSNR。具体来说,我们将 ESDB 的数量减少到 5 个,通道数减少到 48 个。CCA 模块被替换为可学习的通道权重。在训练过程中,输入补丁大小设置为 64 × 64,小批量设置为 256。训练迭代次数增加到 \(1.5\times 10^6\) 个。

图4:BSRN与 x4 SR上最先进方法的视觉比较
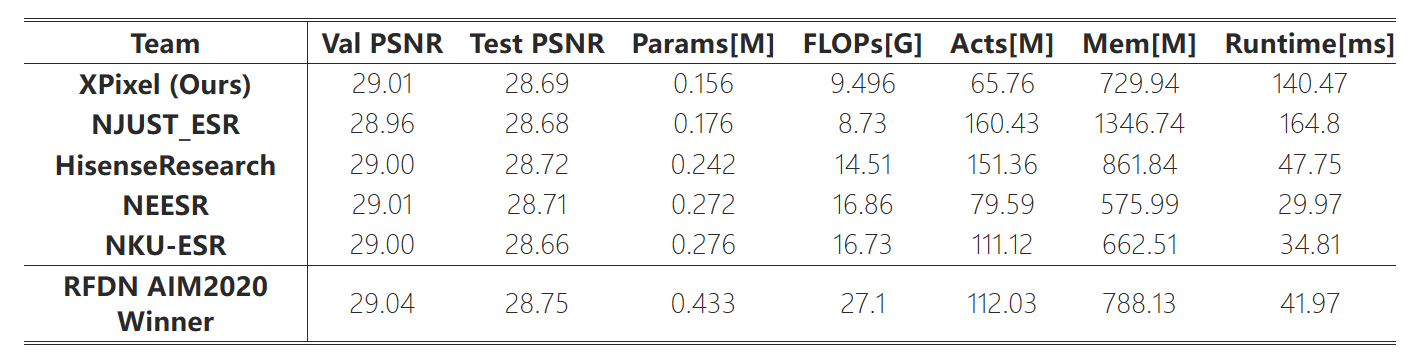
表6:NTIRE 2022高效超分辨率子轨道1的结果:模型复杂性
4.2 消融实验
在本节中,我们首先介绍了不同卷积分解方法的效果。然后,我们演示了两个注意力模块的有效性,并比较了不同激活函数的效果。最后,我们进一步展示了所提出的架构的有效性。
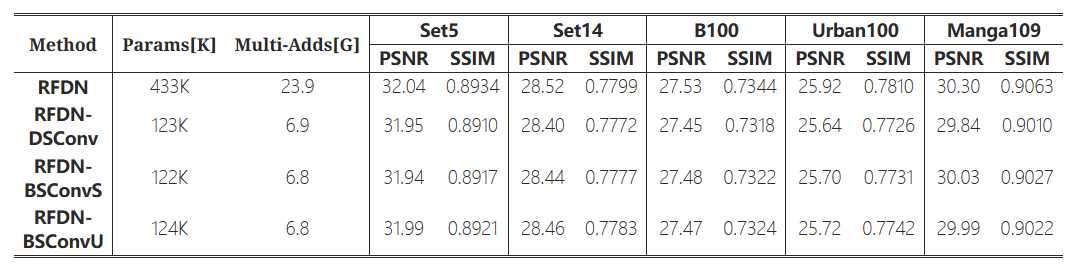
不同卷积分解的影响(Effects of different convolution decompositions): 我们通过实验来展示基于RFDN的不同卷积分解方式的影响。实验结果见表1。DSConv表示原始的深度可分离卷积。DSConv表示原始的深度可分离卷积。BSConvU 和 BSConvS 代表了 《重新思考深度可分离卷积》 中提出的 BSConv 的两种变体。我们可以观察到,在执行卷积分解时,性能会明显下降,计算量会显著下降。在三种分解策略中,BSConvU 表现最好,因此我们选择在模型中使用它。
表1:不同卷积分解方法的定量比较。BSConvU在我们的方法中被称为BSConv。
Effectiveness of ESA and CCA:我们还进行了消融研究,以验证 ESA 和 CCA 两个注意力模块的有效性。没有ESA的BSRN参数下降约9%,性能明显下降。与没有 CCA 的 BSRN 相比,完整的 BSRN 在 Set5、Urban100 和 Manga109 数据集上获得了 0.5dB 的性能提升。结果表明,ESA和CCA可以有效增强模型容量。
表2:ESA和CCA的消融研究

Exploration of different activation functions:以前的大多数SR网络都采用ReLU或LeakyReLU作为激活函数。然而,GELU正逐渐成为近期作品中的主流选择。因此,我们还研究了各种激活函数,以探索我们方法的最佳选择。表3的结果表明,不同的激活函数会明显影响模型的性能。在这些激活函数中,GELU获得了显著的性能提升,尤其是在Urban100数据集上。因此,我们选择 GELU 作为模型中的激活函数。
表3:不同激活函数的定量比较。

Effective of the proposed architecture:我们设计了BSRN的两种变体来证明所提出的架构的有效性。我们将BSRN的深度和宽度设置为与RFDN相同作为BSRN-1,将模型容量扩大到与RFDN类似作为BSRN-2。我们在相同的训练设备下训练比较模型,以便进行公平的比较。如表 4 所示,我们可以观察到 BSRN-1 在计算量较少的情况下优于 RFDN。此外,与 RFDN 相比,BSRN-2 获得了显着的性能提升,尤其是在 Manga109 数据集上。实验结果表明了所提架构的优越性。
表4:两种BSRN变体与RFDN的定量比较。BSRN-1的深度和宽度与RFDN相同,而BSRN-2的计算复杂度与RFDN相似。

4.3 与最先进方法的比较
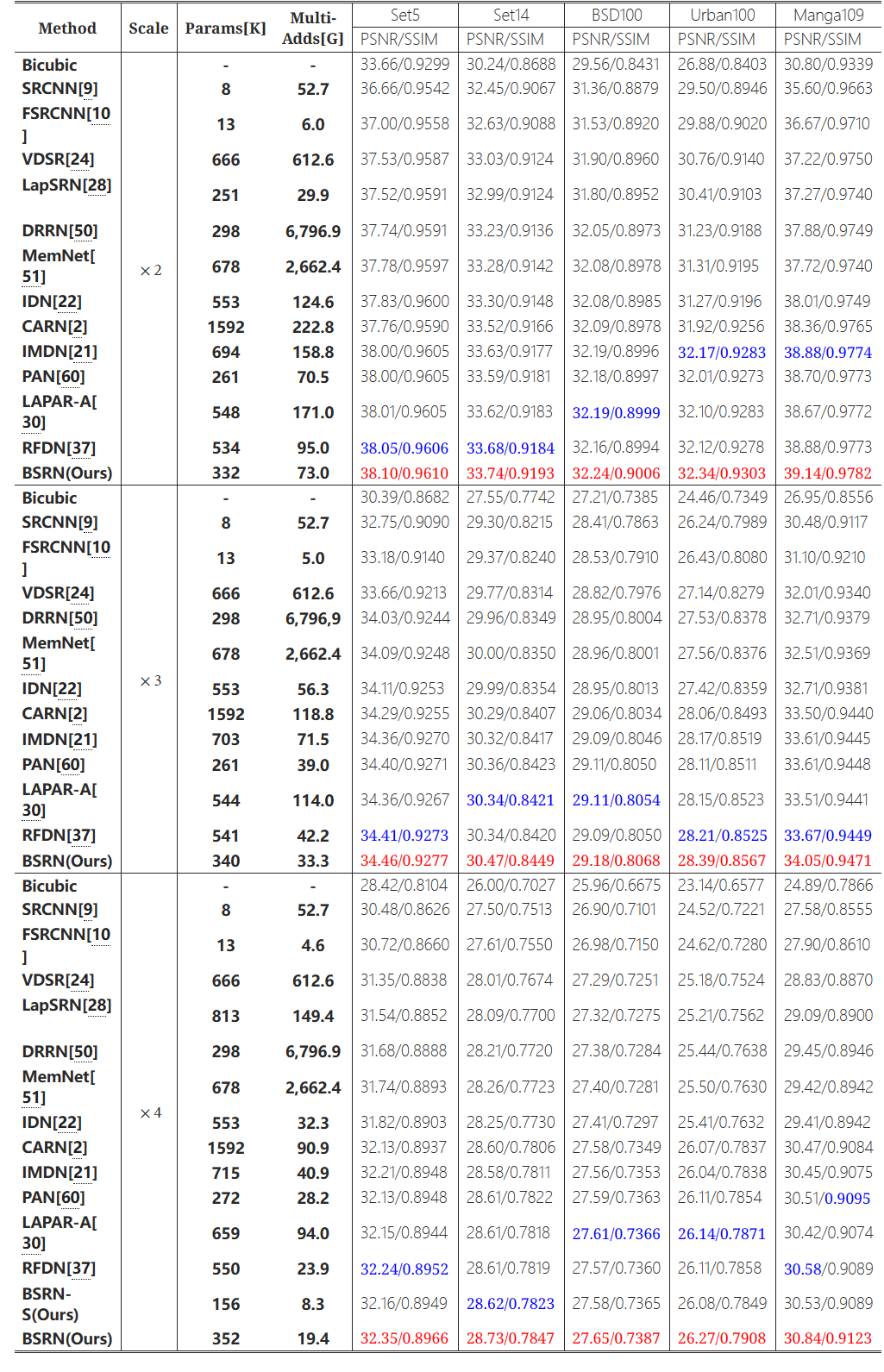
表5:在基准数据集上与最先进方法的定量比较。最一和第二的性能分别是红色和蓝色。“Multi-Adds”是使用 1280 × 720 GT 图像计算的。
5 结论
在本文中,我们提出了一种用于单图像超分辨率的轻量级网络,称为蓝图可分离残差网络(BSRN)。BSRN 的设计灵感来自残差特征蒸馏网络 (RFDN) 和蓝图可分离卷积 (BSConv)。我们采用了与RFDN类似的架构,但引入了更高效的蓝图浅残差块(BSRB),在RFDN的浅残差块(SRB)中用BSConv替换了标准卷积。此外,我们使用有效的ECA模块和CCA模块来增强模型的代表性。大量的实验表明,与最先进的高效SR方法相比,我们的方法以更少的参数和Multi-Adds实现了最佳性能。此外,我们的解决方案在 NTIRE 2022 高效超分辨率挑战赛的模型复杂性赛道中获得了第一名。