Elasticsearch 的搜索功能
建议阅读顺序:
- Elasticsearch 入门
- Elasticsearch 搜索(本文)
1. 介绍
使用 Elasticsearch 最终目的是为了实现搜索功能,现在先将文档添加到索引中,接下来完成搜索的方法。
查询的分类:
-
叶子查询:叶查询子句在特定字段中查找特定值,例如
match、term或range查询。-
精确查询:根据精确词条值查找数据,一般是查找 keyword、数值、日期、boolean 等类型字段。例如:
-
ids:根据文档 ID 查找文档
-
range:返回包含指定范围内的文档,比如:查询年龄在 10 到 20 岁的学生信息。
-
term:根据精确值(例如价格、产品 ID 或用户名)查找文档。
-
-
全文检索查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
-
match_query:对一个字段进行全文检索
-
multi_match_query:对多个字段进行全文检索
-
-
-
复合查询:以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
1.1 精确查询
1.1.1 term
语法:
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}
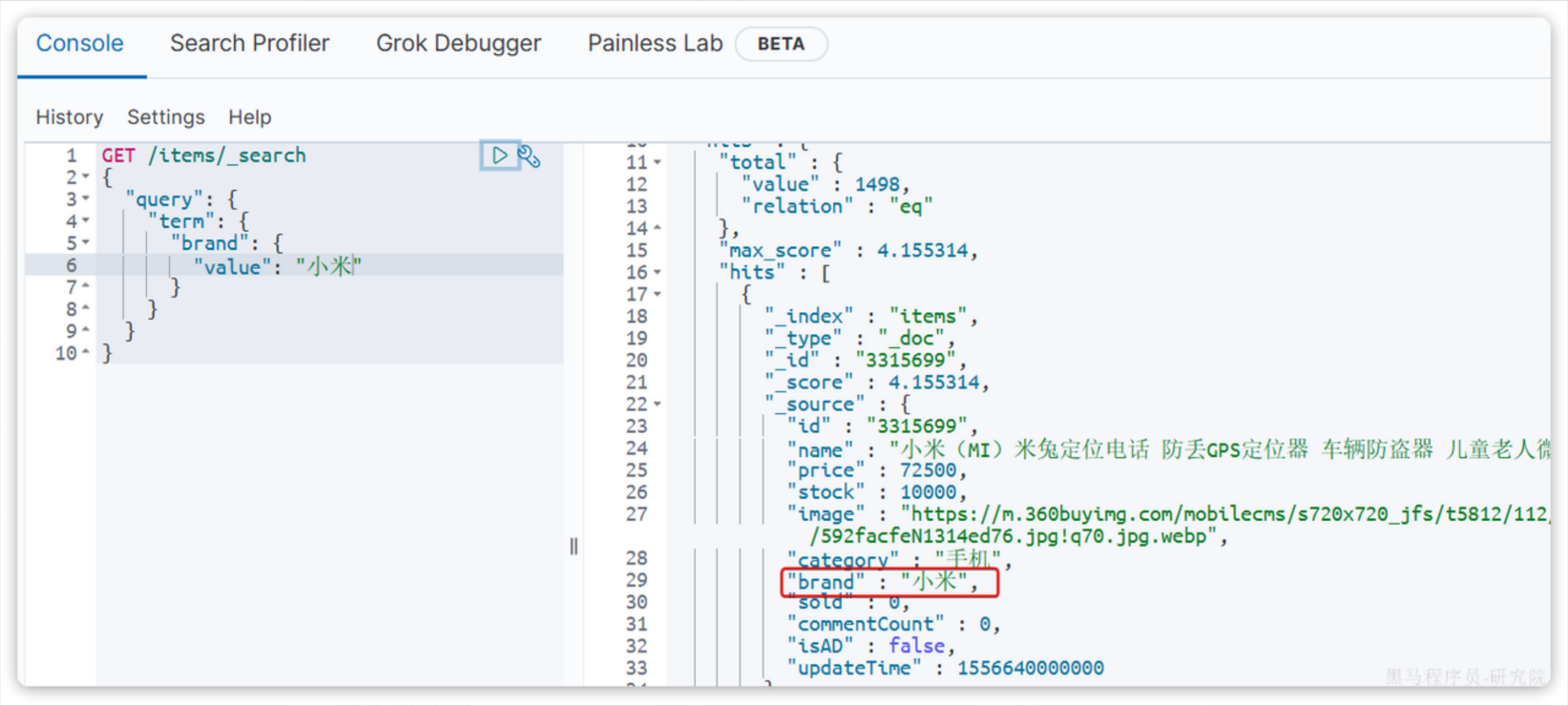
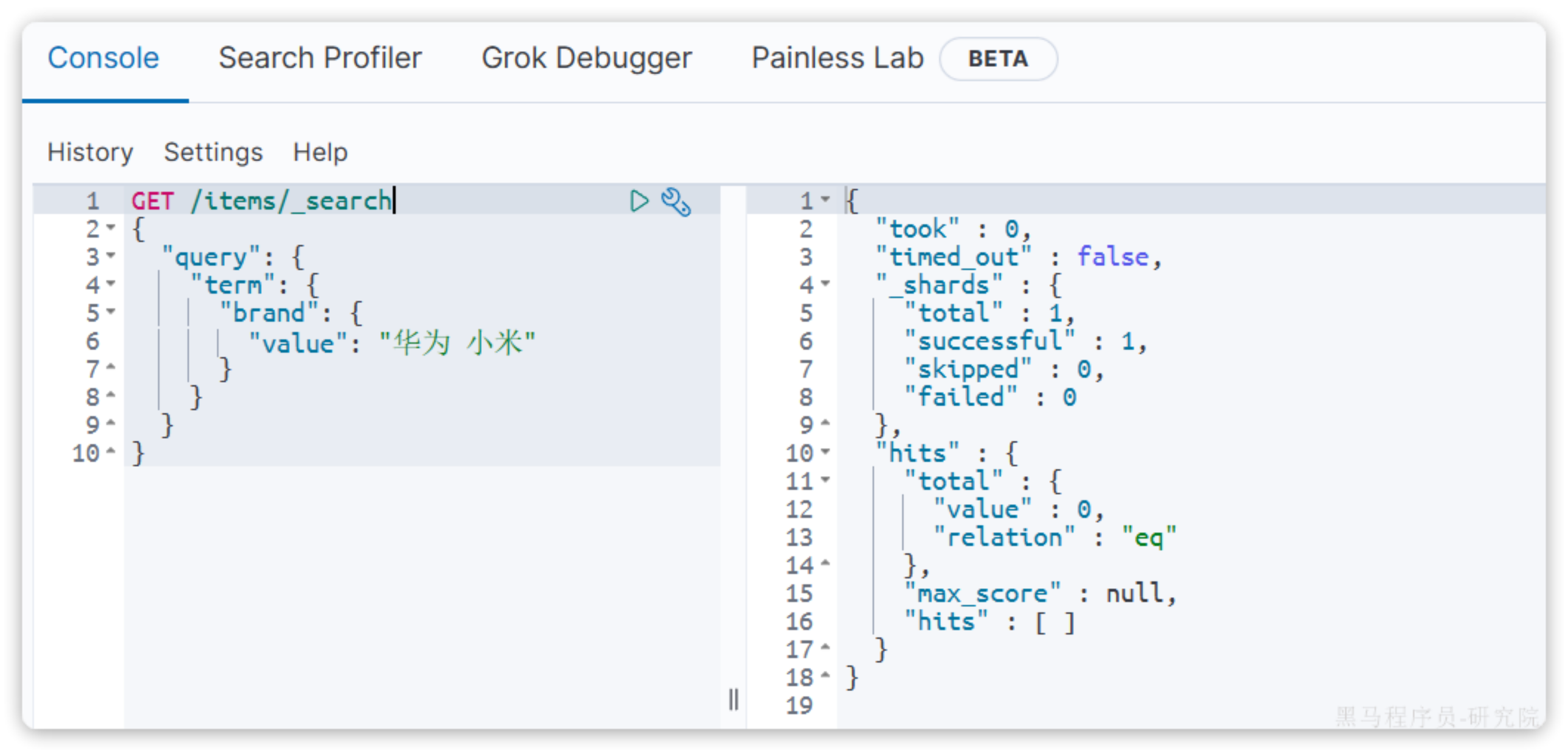
当输入的搜索条件不是词条,而是短语时,由于不做分词,反而搜索不到:
1.1.2 range
语法:
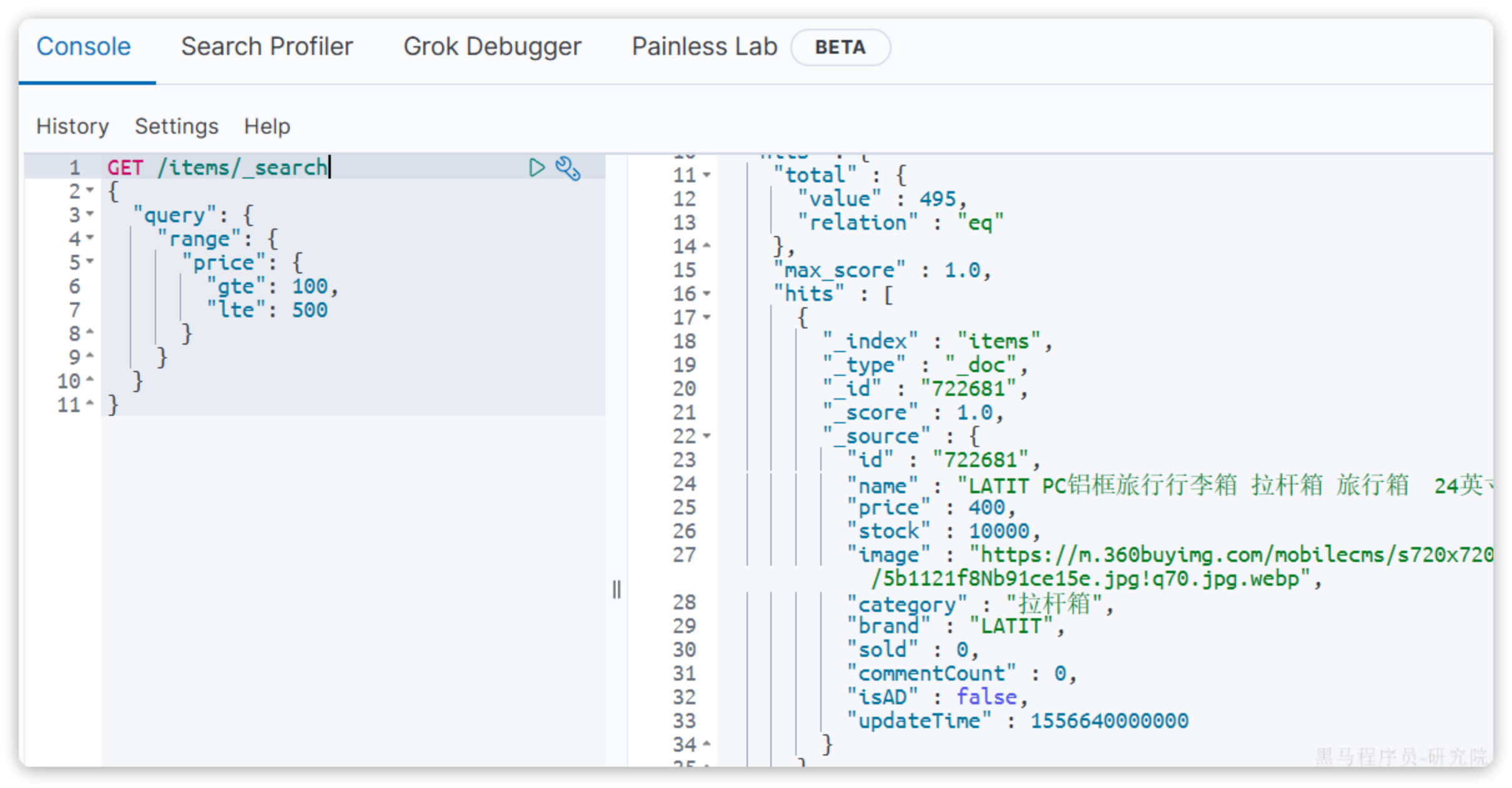
GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}
range 是范围查询,对于范围筛选的关键字有:
gte:大于等于gt:大于lte:小于等于lt:小于
1.2 全文检索
会对搜索条件进行拆分。
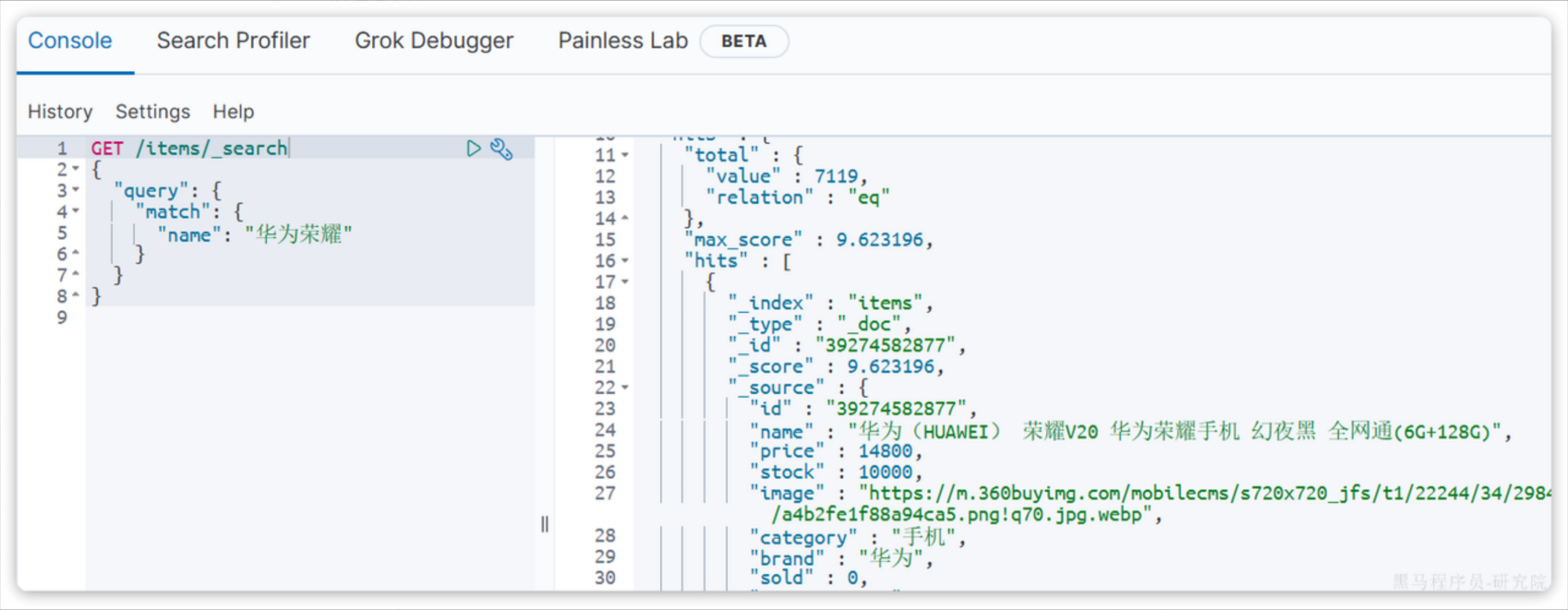
1.2.1 match
语法:
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}
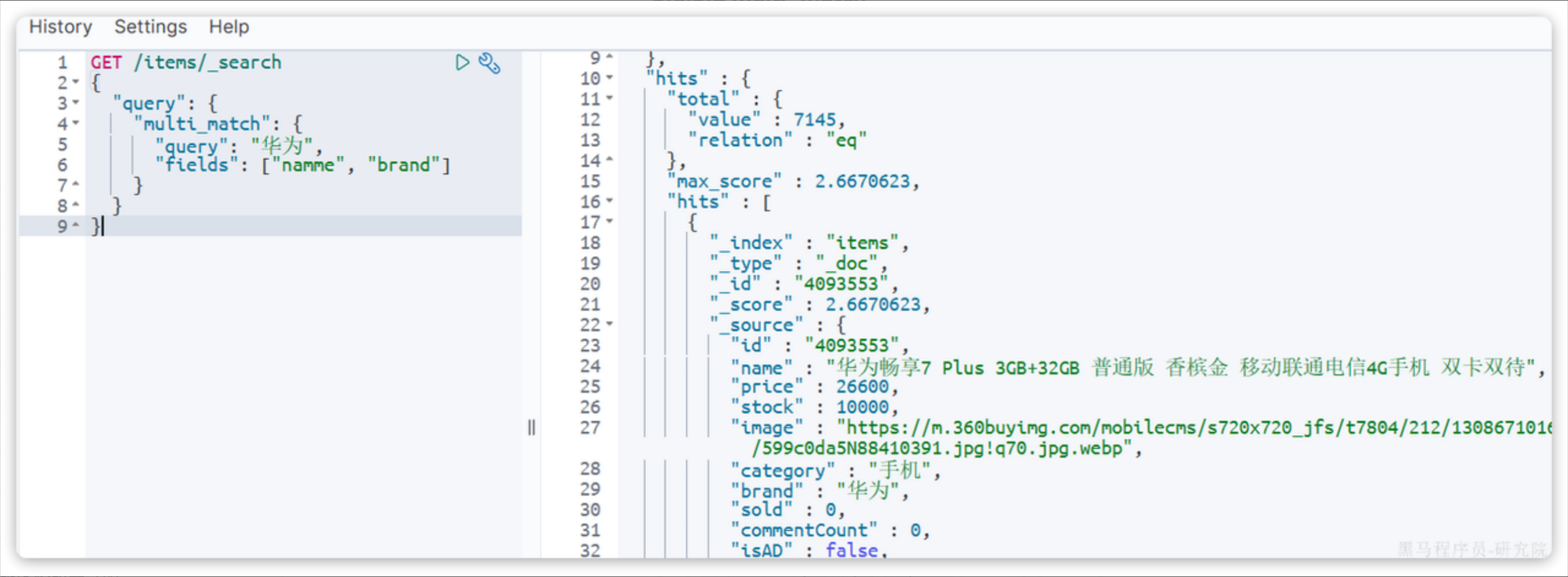
1.2.2 multi_match
同时对多个字段搜索,而且多个字段都要满足,语法:
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}
1.3 排序
语法:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}
如果按照商品价格排序:
GET /items/_search
{"query": {"match_all": {}},"sort": [ { "price": { "order": "desc" } } ]
}
1.4 分页查询
elasticsearch 默认情况下只返回 top10 的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch 中通过修改 from、size 参数来控制要返回的分页结果:
from:从第几个文档开始size:总共查询几个文档
语法:
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [ { "price": { "order": "desc" } } ]
}
2. Java Client 实现搜索
2.1 准备
代码:
@SpringBootTest
public class SearchTest {@Autowiredprivate IItemService itemService;private RestClient restClient = null;private ElasticsearchTransport transport = null;private ElasticsearchClient esClient = null;{// 使用 RestClient 作为底层传输对象restClient = RestClient.builder(new HttpHost("192.168.101.68", 9200)).build();ObjectMapper objectMapper = new ObjectMapper();objectMapper.registerModule(new JavaTimeModule());// 使用 Jackson 作为 JSON 解析器transport = new RestClientTransport(restClient, new JacksonJsonpMapper(objectMapper));}// 实现后续操作// TODO@BeforeEachpublic void searchTest() {// 创建客户端esClient = new ElasticsearchClient(transport);System.out.println(esClient);}@AfterEachpublic void close() throws IOException {transport.close();}}
后续代码放在代码的 TODO 处运行即可!!!
2.2 精准查询
2.2.1 Term 查询
根据 DSL 语句编写 java 代码:
GET /items/_search
{"query": {"term": {"category": { "value": "拉杆箱" }}}
}
代码:
@Test
public void testTermSearch() throws IOException {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items").query(// 精准匹配q -> q.term(t -> t.field("category").value("牛奶"))),// 指定返回类型ItemDoc.class);handleResponse(search);
}
2.2.2 range 查询
GET /items/_search
{"query": {"range": {"price": { "gte": 100000, "lte": 20 }}}
}
代码:
@Test
public void testRangeSearch() throws IOException {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items").query(// 范围匹配,price >= 100000 && price < 200000q -> q.range(t -> t.field("price").gte(JsonData.of(100000)).lt(JsonData.of(200000)))),// 指定返回类型ItemDoc.class);
2.3 全文检索
2.3.1 match 查询
GET /items/_search
{"query": {"match": {"name": "德国进口纯奶"}}
}
代码:
@Test
public void testMatchSearch() throws IOException {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items").query(// 模糊匹配q -> q.match(// 在 name 字段中模糊匹配 "德国进口纯奶"t -> t.field("name").query("德国进口纯奶"))),// 返回值类型ItemDoc.class);handleResponse(search);
}
2.3.2 multi_match 查询
GET /items/_search
{"query": {"multi_match": {"query": "笔记本","fields": ["name", "category"]}}
}
代码:
@Test
public void testMultiMatchSearch() throws IOException {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items").query(// 多字段模糊匹配q -> q.multiMatch(// 匹配字关键字t -> t.query("笔记本")// 匹配字段.fields("name", "category"))),// 指定返回类型ItemDoc.class);handleResponse(search);
}
2.4 排序和分页
GET /items/_search
{"query": {"multi_match": {"query": "绿色拉杆箱","fields": ["name","category"]}},"sort": [{ "price": { "order": "asc" } }],"size": 20,"from": 0
}
代码:
@Test
public void testSortSearch() throws IOException {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items")// 查询条件.query(q -> q.multiMatch(// 匹配字段m -> m.query("绿色拉杆箱").fields("name", "category")))// 排序规则.sort(s1 -> s1.field(// 排序字段f -> f.field("price")// 排序规则.order(SortOrder.Desc)))// 分页.from(0).size(10),// 指定返回类型ItemDoc.class);handleResponse(search);
}
3. 复合查询
3.1 布尔查询
bool 查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool 查询支持的逻辑运算有:
-
must:必须匹配每个子查询,类似 “与”;
-
should:选择性匹配子查询,类似 “或”;
-
must_not:必须不匹配,不参与算分,类似 “非”;
-
filter:必须匹配,不参与算分。
举例:
GET /items/_search
{"query": {"bool": {"must": [ {"match": {"name": "手机"}} ],"should": [{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}],"must_not": [{"range": {"price": {"gte": 2500}}}]}},"sort": [ { "brand": { "order": "desc" } } ]
}
说明:
- 必须条件(
must):- 文档的
name字段必须包含“手机”。
- 文档的
- 可选条件(
should):- 文档的
brand字段应该是 “vivo” 或者 “小米”。只要满足其中一个条件即可。
- 文档的
- 排除条件(
must_not):- 文档的
price字段不能大于等于 2500 元。
- 文档的
- 过滤条件(
filter):- 文档的
price字段必须小于等于 1000 元。
- 文档的
当 should 与 must、must_not 同时使用时 should 会失效,需要指定 minimum_should_match。
3.2 尽量使用 filter
出于性能考虑,与搜索关键字无关的查询尽量采用 must_not 或 filter 逻辑运算,避免参与相关性算分(如:下拉菜单、多级菜单等)。
比如,要搜索 手机,但品牌必须是 华为,价格必须是 900~1599,那么可以这样写:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"filter": [{"term": {"brand": { "value": "华为" }}},{"range": {"price": {"gte": 90000, "lte": 159900}}}]}}
}
3.3 Java Client
@Test
void testBoolQuery() throws Exception {//构建请求SearchRequest.Builder builder = new SearchRequest.Builder();//设置索引builder.index("items");//设置查询条件SearchRequest.Builder searchRequestBuilder = builder.query(// bool 查询,多条件匹配q -> q.bool(// must 连接b -> b.must(m -> m.match(// name 检索mm -> mm.field("name").query("手机"))).should(s1 -> s1.term( t -> t.field("brand").value("小米"))).should(s1 -> s1.term(t -> t.field("brand").value("vivo"))).minimumShouldMatch("1")))// 排序·.sort(sort -> sort.field(f -> f.field("brand").order(SortOrder.Asc)));SearchRequest build = searchRequestBuilder.build();//执行请求SearchResponse<ItemDoc> searchResponse = esClient.search(build, ItemDoc.class);//解析结果handleResponse(searchResponse);
}
4. 高亮显示
4.1 高亮显示原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示。
观察页面源码,你会发现两件事情:
- 高亮词条都被加了
<em>标签 <em>标签都添加了红色样式
因此实现高亮的思路就是:
- 用户输入搜索关键字搜索数据
- 服务端根据搜索关键字到 elasticsearch 搜索,并给搜索结果中的关键字词条添加
html标签 - 前端提前给约定好的
html标签添加CSS样式
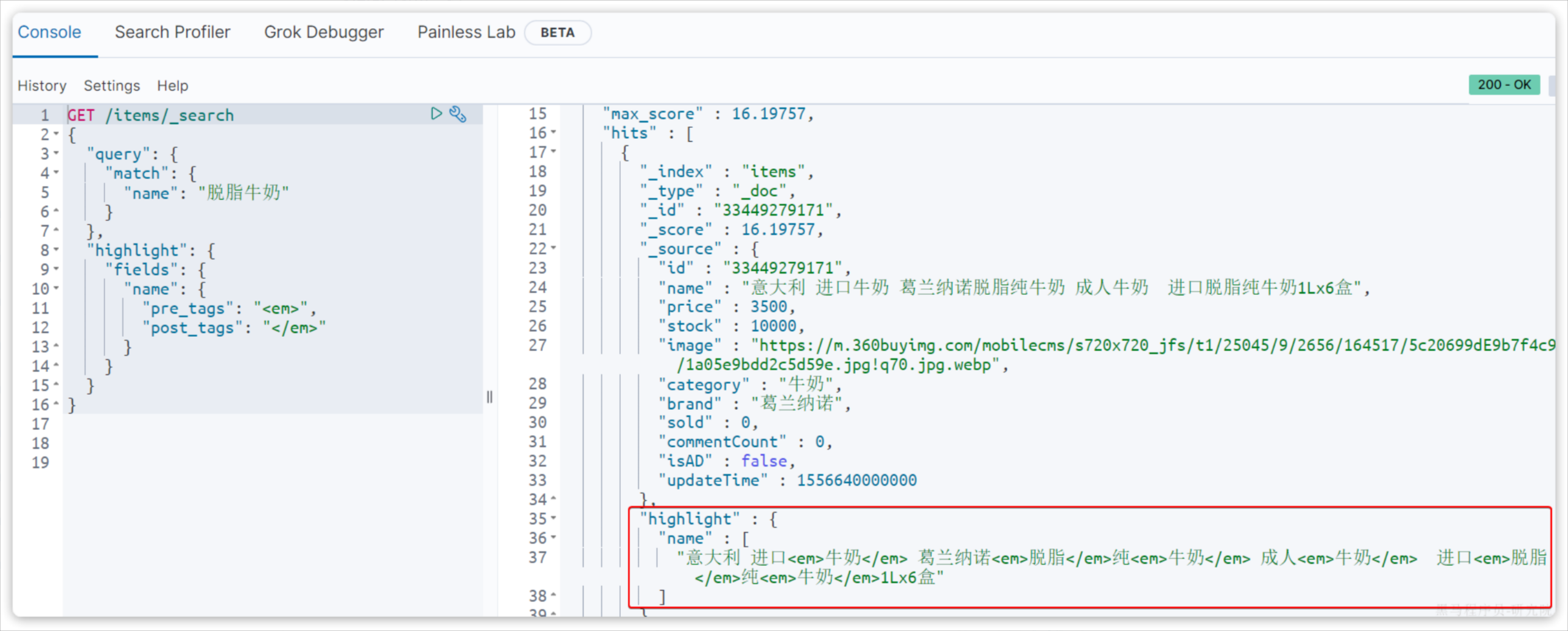
4.2 实现高亮
语法:
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}},"require_field_match": "true"}
}
注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match; - 参与高亮的字段必须是
text类型的字段; - 默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match = false。
代码:
@Test
public void testHighLightSearch() throws Exception {SearchResponse<ItemDoc> search = esClient.search(// 搜索索引s -> s.index("items").query(// 匹配字段q -> q.match(// 匹配字段m -> m.field("name").query("笔记本")))// 高亮.highlight(h -> h.fields("name", f -> f)// 高亮标签,前后缀.preTags("<b style='color:red'>").postTags("</b>")//.requireFieldMatch(false)),ItemDoc.class);long total = search.hits().total().value();System.out.println("total = " + total);List<Hit<ItemDoc>> hits = search.hits().hits();hits.forEach(hit -> {ItemDoc source = hit.source();// 高亮数据Map<String, List<String>> highlight = hit.highlight();List<String> highlightName = highlight.get("name");if(highlightName != null && !highlightName.isEmpty()){String s = highlightName.get(0);source.setName(s);System.out.println("s = " + s);}});
}
5. 数据聚合
5.1 介绍
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。
应用场景:
- 对数据进行统计
- 在搜索界面显示符合条件的品牌、分类、规格等信息
聚合常见的有三类:
- 桶(
Bucket)聚合:用来对文档做分组
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(
Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等
- 管道(
pipeline)聚合:其它聚合的结果为基础做进一步运算
5.2 Bucket 聚合
5.2.1 语法
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category 值一样的放在同一组,属于 Bucket 聚合中的 Term 聚合。
基本语法如下:
GET /items/_search
{"size": 0, "aggs": {"category_agg": {"terms": {"field": "category","size": 20,"order": { "_count": "desc" }}}}
}
属性说明:
aggregations:定义聚合
-
category_agg:聚合名称,自定义,但不能重复-
terms:聚合的类型,按分类聚合,所以用term-
field:参与聚合的字段名称 -
size:希望返回的聚合结果的最大数量设置
size为 0,查询 0 条数据即结果中不包含文档,只包含聚合 -
order:对聚合结果排序
-
-
5.2.2 多级聚合
同时对品牌分组统计,此时需要按分类统计,按品牌统计,这时需要定义多个桶,如下:
GET /items/_search
{"size": 0, "aggs": {"category_agg": {"terms": { "field": "category", "size": 20 }},"brand_agg":{"terms": { "field": "brand", "size": 20 }}}
}
现在需要统计同一分类下的不同品牌的商品数量,这时就需要对桶内的商品二次聚合,如下:
GET /items/_search
{"aggs" : {"category_agg" : {"aggs" : {"brand_agg" : {"terms" : { "field" : "brand", "size" : 20 }}},"terms" : { "field" : "category", "size" : 20 }}},"size" : 0
}
5.3 带条件聚合
默认情况下,Bucket 聚合是对索引库的所有文档做聚合,例如我们统计商品中所有的品牌,结果如下:
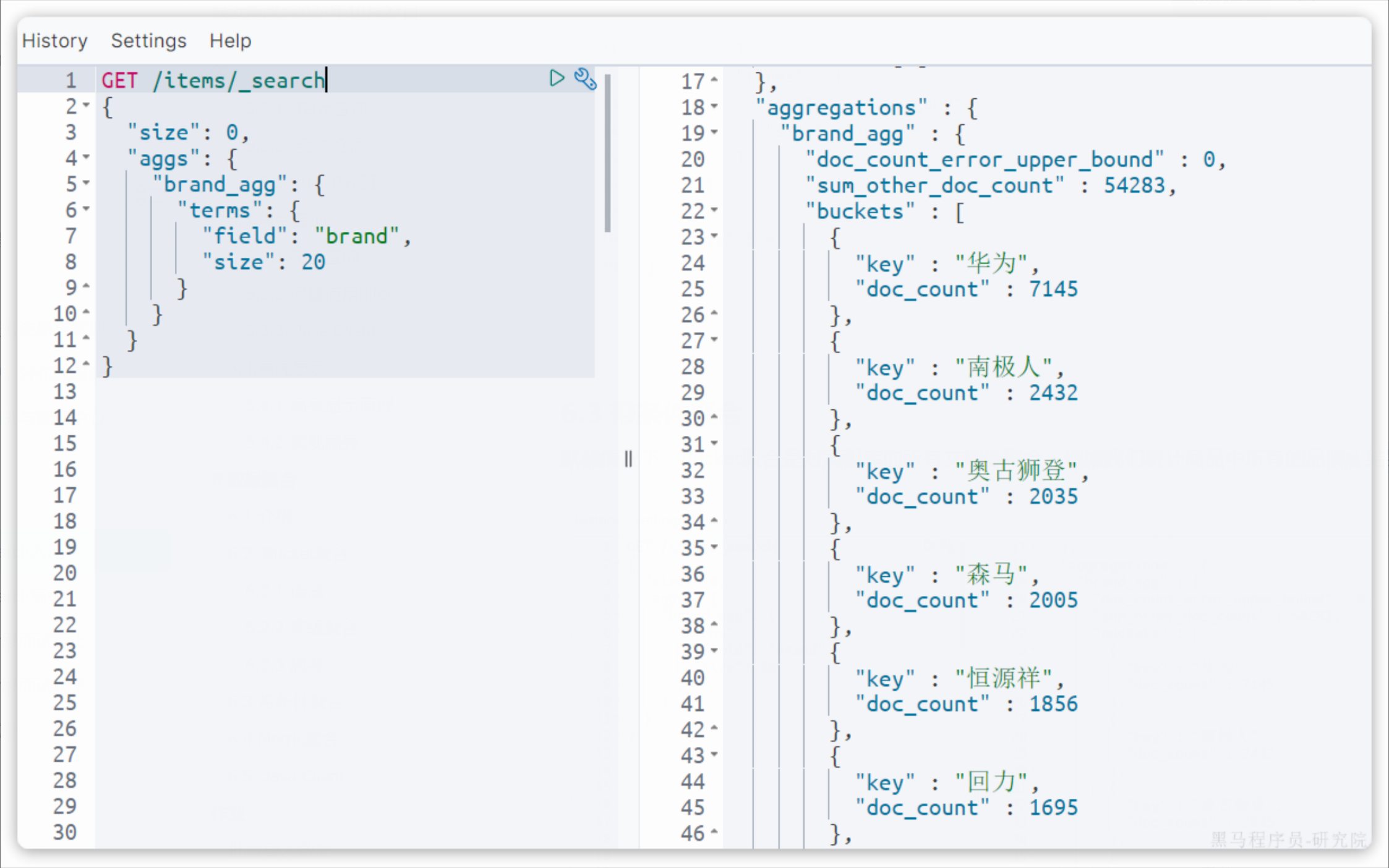
可以看到统计出的品牌非常多。
但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
例如,我想知道价格高于 3000 元的手机品牌有哪些,该怎么统计呢?
语法如下:
增加 "query" 标签。
GET /items/_search
{"query": {"bool": {"filter": [{ "term": { "category": "手机" } },{ "range": { "price": { "gte": 300000 } } }]}}, "size": 0, "aggs": { "brand_agg": { "terms": { "field": "brand", "size": 20 } } }
}
5.4 Metric 聚合
统计了价格高于 3000 的手机品牌,形成了一个个桶。现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
语法:
GET /items/_search
{"query": {"bool": {"filter": [{ "term": { "category": "手机" } },{ "range": { "price": { "gte": 300000 } } }]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20,"order": { "stats_metric.avg": "desc" }},"aggs": { "stats_metric": { "stats": { "field": "price" } } }}}
}
属性说明:
stats_meric:聚合名称,自定义名称
stats:聚合类型,stats 是metric聚合的一种field:聚合字段,这里选择price,统计价格
另外,我们还可以让聚合按照每个品牌的价格平均值排序:
5.5 Java Client
参考 DSL 语句编写 Java Client 代码
@Test
void testAggs() throws Exception {//构建请求SearchRequest.Builder builder = new SearchRequest.Builder();//设置索引名builder.index("items");//设置查询条件builder.query(q -> q.bool(b -> b.filter(f -> f.term(t -> t.field("category").value("手机"))).filter(f -> f.range(r -> r.field("price").gte(JsonData.of(3000))))));//设置返回数量builder.size(0);//设置聚合builder.aggregations("brand_agg", a -> a.terms(t -> t.field("brand").size(10).order(NamedValue.of("stats_metric.avg", SortOrder.Desc))).aggregations("stats_metric", a1 -> a1.stats(s -> s.field("price"))));SearchRequest build = builder.build();//执行请求SearchResponse<ItemDoc> searchResponse = esClient.search(build, ItemDoc.class);//解析出聚合结果Aggregate brandAgg = searchResponse.aggregations().get("brand_agg");brandAgg.sterms().buckets().array().forEach(bucket -> {String key = bucket.key().stringValue();Long docCount = bucket.docCount();StatsAggregate statsMetric = bucket.aggregations().get("stats_metric").stats();//平均价格Double avg = statsMetric.avg();//最大价格Double max = statsMetric.max();//最小价格Double min = statsMetric.min();log.info("品牌:{},商品数量:{},平均价格:{},最大价格:{},最小价格:{}", key, docCount, avg, max, min);});
}