250326 Dualpipe Understanding
这里的Dualpipe可能作为解决上述Challenges 3中流水线停顿问题的算法层面解决方案。
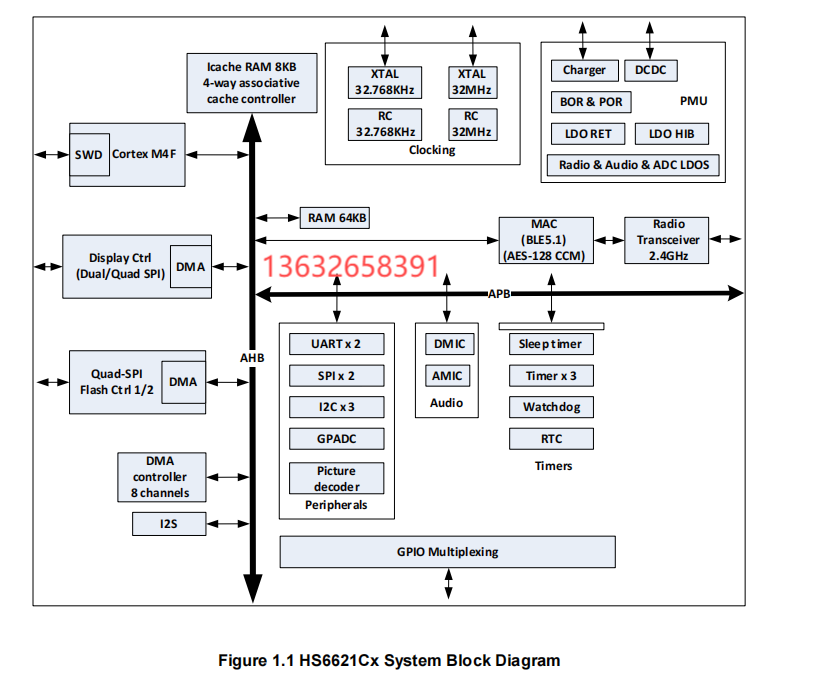
图4展示了如何重新排列这些组件,调整GPU SM用于通信和计算的比例,使得all-to-all和PP通信都能被隐藏

图5展示了DualPipe的完整调度,采用了双向流水线调度,同时从管道两端输入微批次,并行执行,显著减少了通信的延迟。

For DeepSeek-V3, the communication overhead introduced by cross-node expert parallelism results in an inefficient computation-to-communication ratio of approximately 1:1. To tackle this challenge, we design an innovative pipeline parallelism algorithm called DualPipe, which not only accelerates model training by effectively overlapping forward and backward computationcommunication phases, but also reduces the pipeline bubbles. The key idea of DualPipe is to overlap the computation and communication within a pair of individual forward and backward chunks. To be specific, we divide each chunk into four components: attention, all-to-all dispatch, MLP, and all-to-all combine. Specially, for a backward chunk, both attention and MLP are further split into two parts, backward for input and backward for weights, like in ZeroBubble (Qi et al., 2023b). In addition, we have a PP communication component. As illustrated in Figure 4, for a pair of forward and backward chunks, we rearrange these components and manually adjust the ratio of GPU SMs dedicated to communication versus computation. In this overlapping strategy, we can ensure that both all-to-all and PP communication can be fully hidden during execution. Given the efficient overlapping strategy, the full DualPipe scheduling is illustrated in Figure 5. It employs a bidirectional pipeline scheduling, which feeds micro-batches from both ends of the pipeline simultaneously and a significant portion of communications can be fully overlapped. This overlap also ensures that, as the model further scales up, as long as we maintain a constant computation-to-communication ratio, we can still employ fine-grained experts across nodes while achieving a near-zero all-to-all communication overhead.
Example by deepseek
以下通过传统流水线并行与DualPipe策略的对比示例,结合图4的组件分解,说明其优化特点:
场景假设
假设有4个设备(Device 0-3),处理一个微批次(Micro-batch)的前向和反向传播,涉及以下操作:
- 计算:注意力(ATTN)、MLP(基于权重W)
- 通信:All-to-all分发(Dispatch)、All-to-all聚合(Combine)、流水线通信(PP)
- 反向传播拆分为两部分:输入梯度(绿色)、权重梯度(蓝色)
传统流水线并行流程(非DualPipe)
传统方法中,前向和反向阶段严格串行执行,且通信与计算无法重叠,导致显著的空闲时间(红色屏障)。以下是分步流程:
- 前向阶段
-
Device 0
- 计算:ATTN(F) → MLP(W)
- 通信:Dispatch(将数据分发给其他设备)
- 空闲:等待Device 1完成后续前向计算(红色屏障)
-
Device 1
- 计算:ATTN(F) → MLP(W)
- 通信:Dispatch
- 空闲:等待Device 2完成计算
-
Device 2
- 计算:ATTN(F) → MLP(W)
- 通信:Dispatch
- 空闲:等待Device 3完成计算
-
Device 3
- 计算:ATTN(F) → MLP(W)
- 通信:Combine(聚合所有设备数据)
- 空闲:等待反向传播开始
- 反向阶段
-
Device 3
- 计算:ATTN(B_input) → MLP(B_input)
- 通信:Dispatch(发送梯度)
- 空闲:等待Device 2完成反向计算
-
Device 2
- 计算:ATTN(B_input) → MLP(B_input)
- 通信:Dispatch
- 空闲:等待Device 1完成计算
-
Device 1
- 计算:ATTN(B_input) → MLP(B_input)
- 通信:Dispatch
- 空闲:等待Device 0完成计算
-
Device 0
- 计算:ATTN(B_input) → MLP(B_input)
- 通信:Combine(聚合梯度)
- 空闲:等待下一次微批次
关键问题
- 计算与通信完全串行,设备空闲时间(红色屏障)占比高。
- All-to-all和PP通信未隐藏,占据总时间的50%以上。
DualPipe优化策略(基于图4)
DualPipe通过细粒度组件拆分与双向调度,实现计算与通信的完全重叠。以下是同一场景的优化流程:
前向与反向阶段重叠执行
-
Device 0(前向)
- 计算:ATTN(F)
- 并行操作:
- 通信:Dispatch(分发数据给Device 1)
- 计算:MLP(W)(利用剩余GPU SMs)
- 通信:Combine(与Device 1的PP通信重叠)
-
Device 1(反向)
- 计算:ATTN(B_input)(与Device 0的MLP计算重叠)
- 并行操作:
- 通信:Dispatch(发送梯度给Device 0)
- 计算:MLP(B_weights)(利用剩余SMs)
- 通信:Combine(聚合梯度)
-
Device 2 & 3(镜像对称操作)
- 类似Device 0 & 1,但反向微批次从流水线另一端注入。
关键优化
-
消除红色屏障
- 前向的Combine操作(紫色)与反向的ATTN(B_input)(绿色)同时执行(见图4的Device 0与1对齐列)。
- 例如:Device 0的MLP(W)(橙色)与Device 1的ATTN(B_input)(绿色)共享时间窗口。
-
通信完全隐藏
- All-to-all(Dispatch/Combine)和PP通信(紫色)被计算覆盖(见图4中紫色块嵌入橙色/绿色块之间)。
-
双向流水线
- 前向微批次从Device 0向Device 3流动,反向微批次从Device 3向Device 0流动,形成对称调度(图5的黑框重叠区域)。
对比总结
| 维度 | 传统流水线 | DualPipe |
|---|---|---|
| 执行顺序 | 前向→反向严格串行 | 前向与反向双向重叠 |
| 空闲时间 | 高(红色屏障频繁) | 零(通过组件拆分消除屏障) |
| 通信隐藏 | 无法隐藏,占50%时间 | 完全隐藏(与计算重叠) |
| 资源利用率 | 低(GPU SMs闲置) | 高(手动分配SMs,通信与计算并行) |
| 适用场景 | 小规模模型 | 大规模MoE模型(跨节点专家并行) |
直观示例
假设每个操作耗时1单位时间:
- 传统流程总耗时:
4(前向) + 4(反向) = 8单位,其中4单位为空闲。 - DualPipe总耗时:
4单位(前向与反向完全重叠),空闲时间为0。
通过这种重叠策略,DualPipe在相同硬件下实现2倍加速,同时支持更大规模的模型扩展。





![[PNPM Workspace] 搭建Monorepo工程](https://xiejie-typora.oss-cn-chengdu.aliyuncs.com/2024-08-19-074923.jpg)
