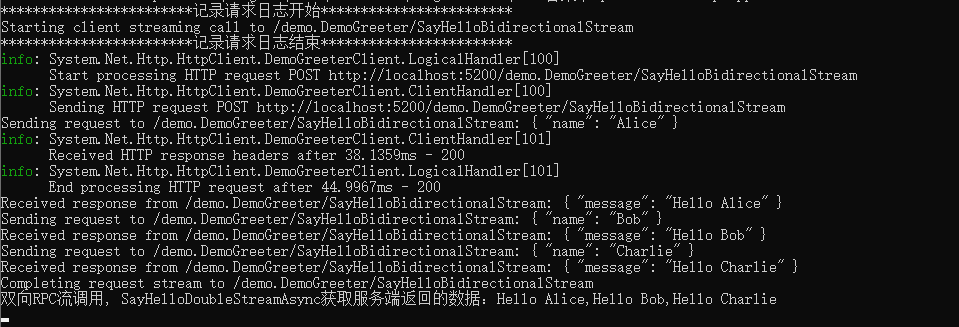
1. lambda函数
用于创建匿名函数,可以作为排序函数中的自定义排序规则,或者作为高阶函数的参数
例如:
按照元组的第二个元素进行排序
numbers=[(1,2),(3,1),(5,4)]
numbers.sort(key=lambda x:x[1])
和map函数一起使用,实现对可迭代对象的操作
numbers=[1,2,3,4,5]
sq=list(map(lambda x:x**2,numbers))
2. 函数装饰器
通过装饰器可以扩展或者修改函数的行为
例如:
def log(func):def wrapper(*args, **kwargs):print(f"调用 {func.__name__} 函数")result = func(*args, **kwargs)print(f"{func.__name__} 函数执行完毕")return resultreturn wrapper@log
def add(x, y):print x + yreturn x + yresult = add(3, 5)
该代码实现了一个用于记录函数的调用和执行情况的装饰器
其中log是一个装饰器函数,接受一个函数func作为参数
直观上理解,在后续定义函数add时,在声明语句前有一个@log,表明log时一个装饰器同时add作为log的函数参数
在装饰器内部定义了一个wrapper函数,具体实现了打印被装饰函数执行前后的日志信息
执行该代码,将会输出
调用 add 函数
8
add 函数执行完毕
注意到wrapper函数中有两个参数*args和**kwargs
这两个参数是通过被修饰函数(如这里的add)传入的参数自动捕获的,作用是接受被修饰参数函数的所有参数,并原样传递给原函数(func)
在上面这个例子中3和5是位置参数,因此args=(3,5),而kwargs={},因为没有关键字参数
3. python函数的参数
python函数的参数可以分为
| 参数类型 | 语法 | 作用 |
|---|---|---|
| 位置参数 | def f(a,b) | 按顺序传递,且传入顺序固定 |
| 默认参数 | def f(a=1) | 调用时可省略 |
| 可变位置参数 | *args | 接受任意数量的位置参数,打包为元组 |
| 可变关键字参数 | **kwargs | 接受任意数量的关键字参数,打包为字典 |
| 仅关键字参数 | *,a | 要求a必须以关键字形式传递 |
可变位置参数和可变关键字参数使得函数编写时的灵活性更强,例如前一小节中的装饰器函数中复制参数并原样传递给原函数
同时*和**还可以用作参数解构
具体来说
*解构可迭代对象为位置参数,例如列表、元组、字符串等,然后将序列元素逐个传给函数
例如
def add(a, b, c):return a + b + cnumbers = [1, 2, 3]
result = add(*numbers) # 等价于 add(1, 2, 3)
print(result) # 输出: 6
def greet(first, second):print(f"Hello, {first} and {second}!")names = "Alice,Bob"
greet(*names.split(',')) # 等价于 greet("Alice", "Bob")
# 输出: Hello, Alice and Bob!
类似的,**可以解构字典作为关键字参数
如
def person_info(name, age, city):print(f"{name}, {age}岁, 来自{city}")data = {"name": "Alice", "age": 25, "city": "北京"}
person_info(**data) # 等价于 person_info(name="Alice", age=25, city="北京")
# 输出: Alice, 25岁, 来自北京
4. 闭包
def outer_function(x):def inner_function(y):return x + yreturn inner_functionclosure = outer_function(10) # x=10 被闭包记住
result = closure(5)
print(result) # 输出:15
闭包(Closure)是指一个函数(内部函数)可以访问并记住其外部函数(enclosing function)的变量,即使外部函数已经执行完毕。
闭包的两个关键特点:
- 内部函数引用外部函数的变量(inner_function 使用了 outer_function 的 x)。
- 外部函数返回内部函数(outer_function 返回 inner_function)。
闭包实现的原理是__closure__属性,换言之,如果如果函数是闭包,func.__closure__ 会自动返回一个包含 cell 对象的元组,每个 cell 存储了外部变量的值。
根据闭包的形式,可以发现我们上面提到的装饰器实际上也是闭包的一种特殊应用
闭包的关键特点同时也是Python如何识别闭包的方式,也就是当函数满足
- 嵌套函数:外部函数 (outer_function) 内部定义了另一个函数 (inner_function)。
- 内部函数引用外部变量:inner_function 使用了 outer_function 的变量(如 x)。
- 外部函数返回内部函数:outer_function 返回 inner_function,使得内部函数可以在外部作用域被调用。
函数被识别为闭包
同时一定程度上,可以理解为把外部函数的调用赋给一个变量时,这个变量相当于是存储了外部函数参数的内部函数实例,下次再调用这个变量的时候就相当于调用了内部函数
于是闭包可以用于实现函数工厂(动态生成函数)
def make_multiplier(n):def multiplier(x):return x * nreturn multiplierdouble = make_multiplier(2)
triple = make_multiplier(3)print(double(5)) # 输出: 10
print(triple(5)) # 输出: 15
但是在循环中创建闭包时,所有闭包可能共享同一个变量(这时需用默认参数或 lambda 绑定当前值)
# 错误示例:所有闭包共享最终的 i
functions = []
for i in range(3):def func():return ifunctions.append(func)
print([f() for f in functions]) # 输出: [2, 2, 2]# 正确做法:用默认参数绑定当前值
functions = []
for i in range(3):def func(i=i): # 绑定当前 ireturn ifunctions.append(func)
print([f() for f in functions]) # 输出: [0, 1, 2]
5. 生成器
生成器是一种特殊的迭代器,通过 yield 关键字实现逐步生成值,而不是一次性计算所有值
这在处理大数据流或无限序列(如斐波那契数列)时非常高效,因为可以仅在需要的时候进行调用
核心特点:
- 每次只在调用next()时才会执行yield后的语句(这个特征也可以记作是惰性计算)
- 生成器会记住上次执行的位置和局部变量状态
例如:
def fibonacci():a, b = 0, 1 # 初始化前两个斐波那契数while True: # 无限循环,生成无限长的序列yield a # 生成当前值 a,并暂停执行a, b = b, a + b # 更新 a 和 b 为下一个斐波那契数# 创建生成器对象
fib = fibonacci()# 打印前10个斐波那契数
for _ in range(10):print(next(fib)) # 输出: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34
每次调用next()语句(或者初次执行时),函数都会从之前停止的地方继续运行,直到再次遇到yield语句,执行完yield语句后,代码停止,等待下次触发
除了next()外,也可以用send()进行触发,不同的是send还会想生成器发送值x,将作为yield表达式返回值,也就是可以用一个左值来接受,如
def interactive_gen():print("Start")x = yield "Please send a value" # 第一次 yield 返回提示,等待 sendprint(f"Received: {x}")yield f"You sent: {x}"gen = interactive_gen()
print(next(gen)) # 输出: "Please send a value"(执行到第一个 yield)
print(gen.send(42)) # 输出: "Received: 42" → "You sent: 42"
不过注意第一次调用时,必须用 next() 或 send(None)(因为首次没有 yield 可以接收值)
对于要使用send()的函数来说yield 既是返回点,也是接收点
通过传输消息,可以实现一般代码所不具有的交互性
例如
协程(通过 send() 实现双向通信)
def coroutine():while True:received = yield # 接收外部发送的值print(f"Received: {received}")c = coroutine()
next(c) # 启动协程(执行到第一个 yield)
c.send("Hello") # 输出: "Received: Hello"
委托生成器(yield from)
def sub_gen():yield 1yield 2def main_gen():yield from sub_gen() # 委托给 sub_genyield 3for num in main_gen():print(num) # 输出: 1, 2, 3
通过yield的惰性计算,可以实现对大数据、无限序列等的读取,因为不会因为一直执行而导致死循环或者直接耗尽内存
例如用生成器读取超大文件:
def read_large_file(file_path):with open(file_path, 'r') as file:for line in file:yield line.strip() # 逐行生成,避免内存溢出# 使用示例
for line in read_large_file("huge_file.txt"):process(line) # 每次处理一行
yield 本质上实现了一种交互式、分步执行的程序控制方
6.函数式编程
高阶函数
高阶函数是可以将其他函数作为自身函数参数或者返回的函数
例如:
def apply(func, x):return func(x)def square(x):return x ** 2result = apply(square, 5)
map函数
map函数可以将函数应用于可迭代对象的每个元素,并返回结果
例如:
numbers = [1, 2, 3, 4, 5]
squared = map(lambda x: x ** 2, numbers)
reduce函数
一定程度上和map比较相似,都是用于可迭代对象的,但是reduce函数是逐步迭代合并结果,例如实现累加
from functools import reducenumbers = [1, 2, 3, 4]
sum_result = reduce(lambda x, y: x + y, numbers)
print(sum_result) # 输出: 10
numbers = [1, 2, 3]
sum_with_init = reduce(lambda x, y: x + y, numbers, 10) # 初始值为10
print(sum_with_init) # 输出: 16 (10 + 1 + 2 + 3)
可以理解为从可迭代对象中依次取出元素,通过指定的二元函数不断更新累积值,最终返回最后一次计算的结果,也就是y从numbers中取出,然后每次更新x=x+y,最后输出x
累加等功能大部分时候都是使用内置函数更为方便,大家如果想要自定义累加逻辑,例如加权和时,可以考虑使用reduce
例如:
data = [(1, 0.5), (2, 1.5), (3, 2.5)]
total = reduce(lambda acc, (val, weight): acc + val * weight, data, 0)
print(total) # 输出: 1*0.5 + 2*1.5 + 3*2.5 = 11.0